第二阶段:JavaAPI总复习一一一之一一一02

一、Java异常
1、java的异常
异常的继承结构————>异常层次结构中的根是Throwable
(1)Error表示系统错误,通常是不能在程序运行期间被解决的错误
(2)Exception表示程序级别的错误,通常是由于逻辑等导致的问题,可以在程序运行期间被解决
编译异常:未运行代码就报错了,强制要求处理
运行时异常RunTimeException:运行代码才报错,可以通过编译,不强制要求处理
(2)异常的解决方案
(3)捕获处理try-catch–自己解决
语法格式:
try{
可能会出现异常的代码
}catch(预测的异常类型 异常的名字){
预先设计的,捕获到异常的处理方案
}finally{
异常处理结构中一定会被执行到的代码块,常用来关流
}
(4)向上抛出throws–交给别人解决,在方法定义的两个小括号之间throws,可抛出多个异常,用逗号隔开
(5)不能直接把异常抛给main(),因为调用main()是JVM,没人解决了
注意:是否抛出异常取决于自己的业务,比如暂时不处理或者处理不了需要交给别人处理
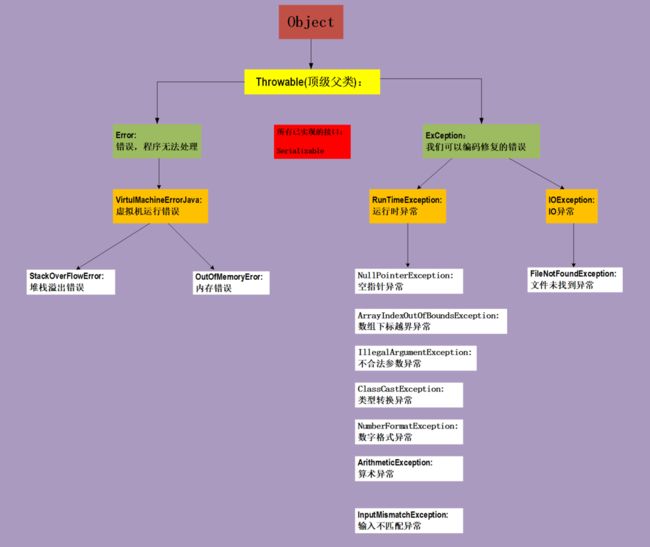
在Java中定义了两种类型的异常和1种错误。
1)JVM(Java虚拟机:运行时异常) 异常:由 JVM 抛出的异常或错误。例如:NullPointerException 类,
ArrayIndexOutOfBoundsException 类,ClassCastException 类。
2)程序级异常(非运行异常):由程序或者API程序抛出的异常。例如 IllegalArgumentException 类,
IllegalStateException 类。
01.Java异常处理是如何工作的?
你需要掌握以下2种类型的异常 和 1种错误:
- ①运行时异常(RunTimeException):——————>非检测异常
运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略。 - ②非运行时异常(也叫其他异常:IoException):——>可检测异常
最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。 - ③错误: 错误不是异常,而是脱离程序员控制的问题。错误在代码中通常被忽略。例如,当栈溢出时,一个错误就发生了,它们在编译也检查不到的。
02.异常处理:java异常处理机制
java中所有错误的超类为:Throwable。其下有两个子类:Error和Exception
- Error的子类描述的都是系统错误,比如虚拟机内存溢出等。
- Exception的子类描述的都是程序错误,比如空指针,下表越界等。
- 通常我们程序中处理的异常都是Exception。
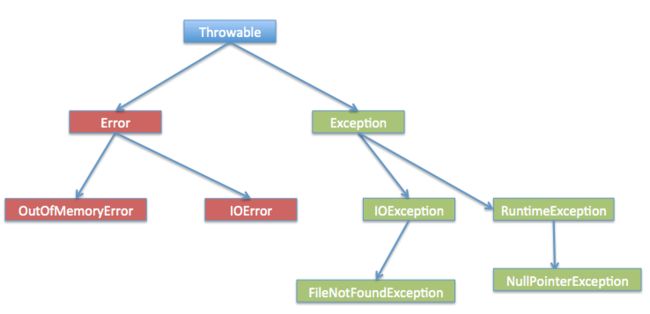
Exception 类的层次-----------------------所有的异常类是从 java.lang.Exception 类继承的子类。
Exception 类是 Throwable 类的子类。除了Exception类外,Throwable还有一个子类Error 。
Error和Exception区分:
Error 用来指示运行时环境发生的错误。
例如,JVM 内存溢出。一般地,程序不会从错误中恢复。
Error是编译时错误和系统错误,系统错误在除特殊情况下,都不需要你来关心,基本不会出现。
而编译时错误,如果你使用了编译器,那么编译器会提示。
Exception则是可以被抛出的基本类型,我们需要主要关心的也是这个类。
Exception又分为两个子类:
(1)运行时异常【RunTimeException)】
(2)非运行时异常:【其他异常(IoException)】。
03.Java异常(可检测异常,非检测异常):
- 可检测异常:可检测异常经编译器验证,对于声明抛出异常的任何方法,编译器将强制执行处理或声明规则,不捕捉这个异常,编译器就通不过,不允许编译
和
- 非检测异常:非检测异常不遵循处理或者声明规则。在产生此类异常时,不一定非要采取任何适当操作,编译器不会检查是否已经解决了这样一个异常
- RuntimeException 类属于非检测异常,因为普通JVM操作引起的运行时异常随时可能发生,此类异常一般是由特定操作引发。但这些操作在java应用程序中会频繁出现。因此它们不受编译器检查与处理或声明规则的限制。
04.常见的RuntimeException子类
- IllegalArgumentException:抛出的异常表明向方法传递了一个不合法或不正确的参数
- NullPointerException:当应用程序试图在需要对象的地方使用 null 时,抛出该异常
- ArrayIndexOutOfBoundsException:当使用的数组下标超出数组允许范围时,抛出该异常
- ClassCastException:当试图将对象强制转换为不是实例的子类时,抛出该异常
- NumberFormatException:当应用程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出该异常。
05.异常处理机制总结:
- 异常处理机制是用来处理那些可能存在的异常,但是无法通过修改逻辑完全规避的场景。
- 而如果通过修改逻辑可以规避的异常是bug,不应当用异常处理机制在运行期间解决!应当在编码时及时修正
06.Java常见14种异常:
(1)Java.io.NullPointerException
- null 空的,不存在的
- NullPointer 空指针
空指针异常,该异常出现在我们操作某个对象的属性或方法时,如果该对象是null时引发。
String str = null;
str.length();//空指针异常
上述代码中引用类型变量str的值为null,此时不能通过它调用字符串的方法或引用属性,否则就会引发空指针异常。
解决办法:
找到为什么赋值为null,确保该对象的值不能为null再操作属性或方法即可。
(2)java.lang.NumberFormatException: For input string: “xxxxx”
- Number 数字
- Format 格式
数字格式异常,该异常通常出现在我们使用包装类将一个字符串解析为对应的基本类型时引发。
String line = "123.123";//小数不能转换为整数!
int d = Integer.parseInt(line);//抛出异常NumberFormatException
System.out.println(d);
上述代码中由于line的字符串内容是"123.123".而这个数字是不能通过包装类Integer解析为一个整数因此出现该异常。注:非数字的字符出在解析时也会出现该异常。
解决办法:
确保解析的字符串正确表达了基本类型可以保存的值
(3)java.lang.StringIndexOutOfBoundsException
- index 索引,下标
- Bounds 边界
- OutOfBounds 超出了边界
字符串下标越界异常。该异常通常出现在String对应的方法中,当我们指定的下标小于0或者大于等于字符串的长度时会抛出该异常。
String str = "thinking in java";
char c = str.charAt(20);//出现异常
System.out.println(c);
解决办法:
指定下标时的范围应当在>=0并且<=字符串的长度。
(4)java.io.InvalidClassException
- Invalid 无效的
- Class 类
无效的类异常,该异常出现在使用java.io.ObjectInputStream在进行对象反序列化时在readObject()方法中抛出。这通常是因为反序列化的对象版本号与该对象所属类现有的版本号不一致导致的。
可以通过在类上使用常量:
static final long serialVersionUID = 1L;
————>来固定版本号,这样序列化的对象就可以进行反序列化了。
JAVA建议我们实现Serializable接口的类主动定义序列化版本号,若不定义编译器会在编译时
根据当前类结构生成版本号,但弊端是只要这个类内容发生了改变,那么再次编译时版本号就会改变,
直接的后果就是之前序列化的对象都无法再进行反序列化.
如果自行定义版本号,那么可以在改变类内容的同时不改变版本号,这样一来,反序列化以前的
对象时对象输入流会采取兼容模式,即:当前类的属性在反序列化的对象中还存在的则直接还原,
不存在的就是用该属性的默认值
出现该异常的解决办法:
1. 首先使用上述常量固定版本号
2. 重新序列化对象(将对象通过ObjectOutputStream重新序列化并写出)
3. 再进行反序列化即可
需要注意,之前没有定义序列化版本号时序列化后的对象都无法再反序列化回来,所以若写入了文件,可将之前的那些文件都删除,避免读取即可。
(5)java.io.NotSerializableException
- NotSerializable 不能序列化
不能序列化异常,该异常通常出现在我们使用java.io.ObjectOutputStream进行对象序列化
(调用writeObject)时。原因时序列化的对象所属的类没有实现java.io.Serializable接口导致
出现该异常的解决办法:
将序列化的类实现该接口即可
(6)java.io.UnsupportedEncodingException
- Unsupported 不支持的
- Encoding字符集
不支持的字符集异常,该异常通常出现在使用字符串形式指定字符集名字时,犹豫字符集名字拼写错误导致。
例如:
PrintWriter pw = new PrintWriter("pw.txt", "UFT-8");
上述代码中,字符集拼写成"UFT-8"就是拼写错误。
常见的字符集名字:
- GBK:我国的国标编码,其中英文1个字节,中文2字节
- UTF-8:unicode的传输编码,也称为万国码。其中英文1字节,中文3字节。
- ISO8859-1:欧中的字符集,不支持中文。
(7)java.io.FileNotFoundException
- File 文件
- NotFound 没有找到
文件没有找到异常,该异常通常出现在我们使用文件输入流读取指定路径对应的文件时出现
FileInputStream fis = new FileInputStream("f1os.dat");
上述代码如果指定的文件f1os.dat文件不在当前目录下,就会引发该异常:
java.io.FileNotFoundException: f1os.dat (系统找不到指定的文件。)
注1:抽象路径"f1os.dat"等同于"./f1os.dat"。因此该路径表示当前目录下应当有一个名为f1os.dat的文件。
注2:还经常出现在文件输出流写出文件时,指定的路径无法将该文件创建出来时出现
FileOutputStream fos = new FileOutputStream("./a/fos.dat");
上述代码中,如果当前目录下没有a目录,那么就无法在该目录下自动创建文件fos.dat,此时也会引发这个异常。
其他API上出现该异常通常也是上述类似的原因导致的。
解决办法:
在读取文件时,确保指定的路径正确,且文件名拼写正确。
在写出文件时,确保指定的文件所在的目录存在。
(8)java.net.ConnectException: Connection refused: connect
- connection 连接
- refused 拒绝
连接异常,连接被拒绝了.这通常是客户端在使用Socket与远端计算机建立连接时由于指定的地址或端口无效导致无法连接服务端引起的.
System.out.println("正在连接服务端...");
Socket socket = new Socket("localhost",8088);//这里可能引发异常
System.out.println("与服务端建立连接!");
解决办法:
- 检查客户端实例化Socket时指定的地址和端口是否正常
- 客户端连接前,服务端是否已经启动了
(9)java.net.BindException: Address already in use
- bind 绑定
- address 地址
- already 已经
- Address already in use 地址已经被使用了
绑定异常,该异常通常是在创建ServerSocket时指定的服务端口已经被系统其他程序占用导致的.
System.out.println("正在启动服务端...");
ServerSocket serverSocket = new ServerSocket(8088);//这里可能引发异常
System.out.println("服务端启动完毕");
解决办法:
- 有可能是重复启动了服务端导致的,先将之前启动的服务端关闭
- 找到该端口被占用的程序,将其进程结束
- 重新指定一个新的服务端口在重新启动服务端
(10)java.net.SocketException: Connection reset
- socket 套接字
- net 网络
- reset 重置
套接字异常,链接重置。这个异常通常出现在Socket进行的TCP链接时,由于远端计算机异常断开(在没有调用socket.close()的之前直接结束了程序)导致的。
解决办法:
- 无论是客户端还是服务端当希望与另一端断开连接时,应当调用socket.close()方法,
此时会进行TCP的挥手断开动作。
- 这个异常是无法完全避免的,因为无法保证程序在没有调用socket.close()前不被强制杀死。
(11)java.lang.InterruptedException
- interrupt 中断
中断异常.这个异常通常在一个线程调用了会产生阻塞的方法处于阻塞的过程中,此时该线程的interrupt()方法被调用.那么阻塞方法会立即抛出中断异常并停止线程的阻塞使其继续运行.
例如:
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
如果线程t1调用Thread.sleep(1000)处于阻塞的过程中,其他线程调用了t1线程的inerrupt()方法,那么t1调用的sleep()方法就会立即抛出中断异常InterruptedException并停止阻塞.
(12)java.util.NoSuchElementException
- such 这个
- Element 元素
没有这个元素的异常.该异常通常发生在使用迭代器Iterator遍历集合元素时由于没有先通过
hasNext()方法判断存在下一个元素而贸然通过next()获取下一个元素时产生(当集合所有元素都
经过迭代器遍历一遍后还使用next获取).
while(it.hasNext()){
String str = (String)it.next();
//这里就可能产生NoSuchException异常
System.out.println(it.next());
}
上述代码中循环遍历时,每次调用hasNext()确定存在下一个元素时,循环里面连续调用过两次
next()方法,这意味着第二次调用next()方法时并没有判断是否还存在.所以在最后会出现异常.
解决办法:
保证每次调用next()方法前都确定hasNext()为true才进行即可.
(13)java.util.ConcurrentModificationException
- Concurrent 并发
- Modification 修改
并发修改异常.这个异常也经常出现在使用迭代器遍历集合时产生.
当我们使用一个迭代器遍历集合的过程中,通过集合的方法增删元素时,迭代器会抛出该异常.
while(it.hasNext()){
//出现ConcurrentModificationException
String str = (String)it.next();
if("#".equals(str)){
c.remove(str);//遍历过程中不要通过集合方法增或删元素
}
System.out.println(str);
}
解决办法:
使用迭代器提供的remove()方法可以删除通过next()获取的元素.
while(it.hasNext()){
String str = (String)it.next();
if("#".equals(str)){
// c.remove(str);
it.remove();
}
System.out.println(str);
}
(14)java.lang.UnsupportedOperationException
- support 支持
- unsupported 不支持的
- operation 操作
不支持的操作异常.该异常出现在很多的API中.
例如:常出现在我们对数组转换的集合进行增删元素操作时抛出.
String[] array = {"one","two","three","four","five"};
System.out.println("array:"+ Arrays.toString(array));
List<String> list = Arrays.asList(array);//将数组转换为一个List集合
System.out.println("list:"+list);
list.set(0,"six");
System.out.println("list:"+list);
//对该集合的操作就是对原数组的操作
System.out.println("array:"+ Arrays.toString(array));
//由于数组是定长的,因此任何会改变数组长度的操作都是不支持的!
list.add("seven");//UnsupportedOperationException
2、异常处理机制:try-catch块:
java异常处理机制:
java中所有错误的超类为:Throwable。其下有两个子类:Error和Exception
Error的子类描述的都是系统错误,比如虚拟机内存溢出等。
Exception的子类描述的都是程序错误,比如空指针,下表越界等。
通常我们程序中处理的异常都是Exception。
java的异常处理机制:
------java中所有异常的超类为Throwable,其下两个派生类:Error和Exception
(1)Error表示系统错误,通常是不能在程序运行期间被解决的错误
(2)Exception表示程序级别的错误,通常是由于逻辑等导致的问题,可以在程序运行期间被解决
1、异常处理机制中的try-catch:——————>try语句块不能独立存在,后面必须跟catch或finally。
**(1)catch只能用于逻辑错误的异常,不能捕获运行时异常RuntimeException,
因为RuntimeException属于非检测异常,是一些bug级别的!
01.语法:
try{
//可能出现异常的代码
}catch(预测的异常类型:XXXXException 异常的名字:e){
//----------当try中出现XXXException后的解决办法
}
02.注意事项:
(1)问:为什么不加try-catch就报异常?
答:JVM执行到这里时若发生了异常就会实例化一个对应的异常实例(NullPointerException),并将程序执行过程设置进去,然后将异常抛出。
(2)注0:——————————>try语句块中出错代码以下的代码均不执行!
(3)注1:——————————>当多个异常的解决办法相同时,可以合并到一个catch来捕获并处理:
(4)注2:——————————>可以在最后一个catch处捕获Exception,避免因未捕获的异常导致程序中断
练习题:
package apiday.day06.exception;
/**
* java的异常处理机制:
* ------java中所有异常的超类为Throwable,其下两个派生类:Error和Exception
* (1)Error表示系统错误,通常是不能在程序运行期间被解决的错误
* (2)Exception表示程序级别的错误,通常是由于逻辑等导致的问题,可以在程序运行期间被解决
*
* 1、异常处理机制中的try-catch:——————>try语句块不能独立存在,后面必须跟catch或finally。
* 01.语法:
* try{
* //可能出现异常的代码
* }catch(预测的异常类型:NullPointerException 异常的名字:e){
* //----------当try中出现XXXException后的解决办法
* }catch(StringIndexOutOfBoundsException e){
* //System.out.println("出现了字符串下标越界了!并在这里得到解决!");
* }catch(Exception e){
* //Exception是NullPointerException和StringIndexOutOfBoundsException两个类的父类
* //编写多重catch块时要先子类后父类,如上面的代码,Exception要写在最后。;若子类超类写反了,则编译错误!
*
* 02.注意事项:
* (1)问:为什么不加try-catch就报异常?
* 答:JVM执行到这里时若发生了异常就会实例化一个对应的异常实例(NullPointerException),并将程序执行过程设置进去,然后将异常抛出。
* (2)注0:——————————>try语句块中出错代码以下的代码均不执行!
* (3)注1:——————————>当多个异常的解决办法相同时,可以合并到一个catch来捕获并处理:
* (4)注2:——————————>可以在最后一个catch处捕获Exception,避免因未捕获的异常导致程序中断
*/
public class TryCatchDemo {
public static void main(String[] args) {
/*
例1:会报空指针异常:
System.out.println("程序开始了");
String line = null;
//问:为什么会报空指针异常?
//答:JVM执行到这里时若发生了异常就会实例化一个对应的异常实例(NullPointerException),
并将程序执行过程设置进去,然后将异常抛出。
System.out.println(line.length());
System.out.println("结束开始了。。。");
*/
/** 例2:加上try-catch不会报异常: */
System.out.println("程序开始了");
try {
//1.(1)因为null为空,所以JVM会实例化一个对应异常实例并将异常抛出。
// String line = null;
//1.(2)因为字符串为空,输出第1字下标的内容会报下标越界异常
// String line = "";
//不会报异常:会打印:【2 a】
String line = "aa";
/*
JVM执行到这里时若发生了异常就会实例化一个对应的异常实例,
并将程序执行过程设置进去,然后将异常抛出。
*/
System.out.println(line.length());//1.(1) ; 1.(2)
System.out.println(line.charAt(0));
System.out.println(Integer.parseInt(line));
//注0:——————————>try语句块中出错代码以下的代码均不执行!
System.out.println("!!!!!");
//例:下面的代码可以被合并:
// } catch (NullPointerException e) {
// //1.(1)当try中出现空指针异常后的解决办法:
// System.out.println("出现了空指针异常");
// }catch (StringIndexOutOfBoundsException e){
// //1.(2)当try中出现下标越界异常后的解决办法:
// System.out.println("出现了下标越界异常");
// }
//和上面代码意思相同,即合并来写:
//注1:————————————>当多个异常的解决办法相同时,可以合并到一个catch来捕获并处理:
}catch(NullPointerException | StringIndexOutOfBoundsException e){
System.out.println("两种异常统一的解决办法:出现了空指针异常或下标越界的处理!");
//注2:——————————>可以最后一个catch处捕获Exception,避免因未捕获的异常导致程序中断
}catch(Exception e){
System.out.println("通用错误的解决办法:未知错误!");
}
System.out.println("程序结束了。。。");
}
}
3、异常处理机制:finally块:
- finally块定义在异常处理机制中的最后一块。它可以直接跟在try之后,或者最后一个catch之后。
- finally可以保证只要程序执行到了try语句块中,无论try语句块中的代码是否出现异常,最终finally都必定执行。
- finally通常用来做释放资源这类操作。
2、异常处理机制:finally块:
用try-catch语句块处理完异常还需进行一些善后工作,比如关闭连接或关闭打开的一些文件,则用finally语句块进行善后工作
(1)finally块是异常处理机制的最后一块,可以跟在try之后或者最后一个catch后。
(2)finally块可以保证只要程序执行到try语句块中,无论try中是否出现异常,finally最终都会必定执行!
(3)通常我们将释放资源这类操作放在finally中确保运行,例如IO操作后最终的.close()调用
(4)finally的强制性!—————>只要程序可以执行到try语句块中,无论是否出现异常,最终都要执行finally块的代码。
01.语法:
try{
//可能出现异常的代码
}catch(预测的异常类型:XXXXException 异常的名字:e){
//----------当try中出现XXXException后的解决办法
}finally{
异常处理结构中一定会被执行到的代码块,常用来关流
}
02.异常处理机制finally在IO操作时的应用案例:Demo2
03.JDK7之后,java推出了自动关闭特性————>可以在异常处理机制中用更简洁的写法完成IO的关闭操作
AutoCloseable:自动关闭
(1)只有实现了java.io.AutoCloseable接口的类才可以在这里定义并初始化。
并且编译器在编译时会将在这里定义的变量在finally中调用close将其关闭。
注:最终编译器(编译器认可的,而不是虚拟机)会将当前代码改为FinallyDemo2的样子。
04.注意事项:
(1)注1:——————>try语句块中出错代码以下的代码均不执行!
练习题:
package apiday.day06.exception_Finally;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 2、异常处理机制:finally块:
* 用try-catch语句块处理完异常还需进行一些善后工作,比如关闭连接或关闭打开的一些文件,则用finally语句块进行善后工作
* (1)finally块是异常处理机制的最后一块,可以跟在try之后或者最后一个catch后。
* (2)finally块可以保证只要程序执行到try语句块中,无论try中是否出现异常,finally最终都会必定执行!
* (3)通常我们将释放资源这类操作放在finally中确保运行,例如IO操作后最终的.close()调用
* (4)finally的强制性!—————>只要程序可以执行到try语句块中,无论是否出现异常,最终都要执行finally块的代码。
*
* 01.语法:
* try{
* //可能出现异常的代码
* }catch(预测的异常类型:XXXXException 异常的名字:e){
* //----------当try中出现XXXException后的解决办法
* }finally{
* 异常处理结构中一定会被执行到的代码块,常用来关流
* }
*
* 02.异常处理机制finally在IO操作时的应用案例:Demo2
*
* 03.JDK7之后,java推出了自动关闭特性————>可以在异常处理机制中用更简洁的写法完成IO的关闭操作
* AutoCloseable:自动关闭
* (1)只有实现了java.io.AutoCloseable接口的类才可以在这里定义并初始化。
* 并且编译器在编译时会将在这里定义的变量在finally中调用close将其关闭。
* 注:最终编译器(编译器认可的,而不是虚拟机)会将当前代码改为FinallyDemo2的样子。
*
* 04.注意事项:
* (1)注1:——————>try语句块中出错代码以下的代码均不执行!
*
*/
public class FinallyDemo12___AutoCloseable {
public static void main(String[] args) {
/** 2、异常处理机制中的finally块:Demo1 */
System.out.println("程序开始");
try{
//注2:将字符串换为null再来测试,还是发现finally块一定会执行!
String line = "abc";
System.out.println(line.length());
//注1:——————>try语句块中出错代码以下的代码均不执行!
System.out.println("!!!");
return;
}catch (Exception e){
System.out.println("出错了");
//用try-catch语句块处理完异常还需进行一些善后工作,比如关闭连接或关闭打开的一些文件,则用finally语句块进行善后工作
}finally {
System.out.println("finally中的代码执行了");
}
System.out.println("程序结束了");
/** 02.异常处理机制finally在IO操作时的应用案例:Demo2 */
FileOutputStream fos = null;//需要先初始化下面路径的代码才不会编译错误!
try {
fos = new FileOutputStream("./a/test/fos.dat");
fos.write(1);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fos!=null){
fos.close();
}
} catch (IOException e) {
/*
catch(Exception e){
e.printStackTrace() ;//向控制台输出当前异常的错误信息
}
当try语句中出现异常是时,会执行catch中的语句,java运行时系统会自动将
catch括号中的Exception e 初始化,也就是实例化Exception类型的对象。
e是此对象引用名称。然后e(引用)会自动调用Exception类中指定的方法,
也就出现了e.printStackTrace() ;
printStackTrace()方法的意思是:在命令行打印异常信息在程序中出错的位置及原因。
*/
e.printStackTrace();
}
}
/** 03.JDK7之后,java推出了自动关闭特性。 */
try (
/*
只有实现了java.io.AutoCloseable接口的类才可以在这里定义并初始化。
并且编译器在编译时会将在这里定义的变量在finally中调用close将其关闭。
注:最终编译器会将当前代码改为FinallyDemo2的样子。
*/
FileOutputStream fos1 = new FileOutputStream("./test/fos.dat");
){
fos1.write(1);
} catch (IOException e) {
e.printStackTrace();//向控制台输出当前异常的错误信息
}
}
}
01.JDK7之后,java推出了自动关闭特性————>可以在异常处理机制中用更简洁的写法完成IO的关闭操作
JDK7之后,java提供了一个新的特性:自动关闭。旨在IO操作中可以更简洁的使用异常处理机制完成最后的close操作。
语法:
try(
-----//定义需要在finally中调用close()方法关闭的对象.
){
-----//IO操作
}catch(XXXException e){
...
}
上述语法中可在try的"()"中定义的并初始化的对象必须实现了java.io.AutoCloseable接口,否则编译不通过.
public class AutocloseableDemo {
public static void main(String[] args) {
try(
FileOutputStream fos = new FileOutputStream("fos.dat");
){
fos.write(1);
} catch (IOException e) {
e.printStackTrace();//向控制台输出当前异常的错误信息
}
}
}
上述代码是编译器认可的,而不是虚拟机。编译器在编译上述代码后会在编译后的class文件中改回成FinallyDemo2案例的代码样子(上次课最后的案例)。
03.JDK7之后,java推出了自动关闭特性————>可以在异常处理机制中用更简洁的写法完成IO的关闭操作
AutoCloseable:自动关闭
(1)只有实现了java.io.AutoCloseable接口的类才可以在这里定义并初始化。
并且编译器在编译时会将在这里定义的变量在finally中调用close将其关闭。
注:最终编译器(编译器认可的,而不是虚拟机)会将当前代码改为FinallyDemo2的样子。
练习题:
public class FinallyDemo12___AutoCloseable {
public static void main(String[] args) {
try (
/*
只有实现了java.io.AutoCloseable接口的类才可以在这里定义并初始化。
并且编译器在编译时会将在这里定义的变量在finally中调用close将其关闭。
注:最终编译器会将当前代码改为FinallyDemo2的样子。
*/
FileOutputStream fos1 = new FileOutputStream("./test/fos.dat");
){
fos1.write(1);
} catch (IOException e) {
e.printStackTrace();//向控制台输出当前异常的错误信息
}
}
}
4、throw 和 throws关键字
01.throw关键字
1、throw关键字:——————>可以主动对外抛出一个异常
通常下面两种情况我们主动对外抛出异常:
(1)当程序遇到一个满足语法,但是不满足业务要求时,可以抛出一个异常告知调用者。
(2)程序执行遇到一个异常,但是该异常不应当在当前代码片段被解决时可以抛出给调用者。
2、throw注意事项:
(1)①当我们在方法中使用throw主动对外抛出一个异常时,除了RuntimeException之外; 其他异常抛出时必须在方法上使用throws声明该异常的抛出
throw关键字:——————>可以主动对外抛出一个异常
01.通常下面两种情况我们主动对外抛出异常:
(1)程序出现了异常,但是该异常不应当在当前代码块中被解决时,可以主动将其抛出去
(2)程序可以运行,但是不满足业务场景要求时可以当做异常抛出去
02.throw注意事项:
***(1)①当我们在方法中使用throw主动对外抛出一个异常时,除了RuntimeException之外;
其他异常抛出时必须在方法上使用throws声明该异常的抛出
②当我们调用一个含有throws声明异常抛出的方法时,编译器要求我们必须处理这个异常,否则编译不通过
处理方式有两种:
(1)使用try-catch主动捕获并处理这个异常
(2)使用throws继续将该异常声明抛出
注意:永远不应当在main方法上使用throws!!!但可以使用try-catch!!
↑关于(2)的说明:在方法中写一个异常时,若有其他引用(即对象)调用该方法:
那么在调用该方法的对象的方法上也必须抛出该异常:【throws Exception】
否则调用该方法会编译错误!
*(3)注意:永远不应当在main方法上使用throws!!!但可以使用try-catch!!
练习题:
package apiday.day06.throw_throws;
/**
* throw关键字:——————>可以主动对外抛出一个异常
* 01.通常下面两种情况我们主动对外抛出异常:
* (1)程序出现了异常,但是该异常不应当在当前代码块中被解决时,可以主动将其抛出去
* (2)程序可以运行,但是不满足业务场景要求时可以当做异常抛出去
*
* 02.throw注意事项:
* (1)当我们在方法中使用throw主动对外抛出一个异常时,除了RuntimeException之外;
* 其他异常抛出时必须在方法上使用throws声明该异常的抛出
* (2)当我们调用一个含有throws声明异常抛出的方法时,编译器要求我们必须处理这个异常,否则编译不通过
* 处理方式有两种:
* (1)使用try-catch主动捕获并处理这个异常
* (2)使用throws继续将该异常声明抛出
* 注意:永远不应当在main方法上使用throws!!!但可以使用try-catch!!
*
* ↑关于(2)的说明:在方法中写一个异常时,若有其他引用(即对象)调用该方法:
* 那么在调用该方法的对象的方法上也必须抛出该异常:【throws Exception】
* 否则调用该方法会编译错误!
* 注意:永远不应当在main方法上使用throws!!!但可以使用try-catch!!
*/
public class Throw_PersonDemo {
public static void main(String[] args) {
System.out.println("程序开始了");
Person p = new Person();
//满足语法但是不满足业务场景:例:年龄不能设为1000岁
try {
/*
当我们调用一个含有throws声明异常抛出的方法时,编译器要求我们必须处理这个异常,否则编译不通过
处理方式有两种:
(1)使用try-catch主动捕获并处理这个异常
或
(2)使用throws继续将该异常声明抛出
*/
p.setAge(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("此人年龄:"+p.getAge());
System.out.println("程序结束了");
}
}
/** 使用当前类测试异常的抛出: */
class Person {
private int age;
public int getAge() { return age; }
public void setAge(int age) throws Exception{
if(age<0 | age>100){
//这一句可以在控制台显示异常:
// throw new RuntimeException("年龄不合法异常");
/*
当我们在方法中使用throw主动对外抛出一个异常时,除了RuntimeException之外;
其他异常抛出时必须在方法上使用throws声明该异常的抛出()
*/
throw new Exception("年龄不合法异常");
}
this.age = age;
}
}
02.throws关键字:-----throws的重写规则:
当我们调用一个含有throws声明异常抛出的方法时,编译器要求我们必须处理这个异常,否则编译不通过。 处理手段有两种:
-
使用try-catch捕获并处理这个异常 -
在当前方法(本案例就是main方法)上继续使用throws声明该异常的抛出给调用者解决。 具体选取那种取决于异常处理的责任问题。
注意:永远不应当在main方法上使用throws!!!但可以使用try-catch!!
↑关于(2)的说明:在方法中写一个异常时,若有其他引用(即对象)调用该方法:
那么在调用该方法的对象的方法上也必须抛出该异常:【throws Exception】
否则调用该方法会编译错误!*(3)注意:永远不应当在main方法上使用throws!!!但可以使用try-catch!!
throws关键字:
throws的重写规则:——————>在派生类中重写超类含有throws声明抛出异常的方法时:
<<4个允许+2个不允许>>:
(1)允许派生类可以重写超类方法
(2)允许仅抛出部分异常
(3)允许不再抛出任何异常
(4)允许抛出超类方法抛出异常的子类型异常
——————————————————————————————————————————————————————————————————————
(5)不允许抛出额外异常(超类方法没有声明抛出的,或和超类声明抛出的异常没有继承关系的)
(6)不允许抛出超类方法抛出异常的超类型异常 即抛出超类方法的异常不能为超类的超类
练习题:含有throws的方法被子类重写时的规则:
package exception;
import java.awt.*;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.sql.SQLException;
public class ThrowsDemo {
public void dosome()throws IOException, AWTException {}
}
class SubClass extends ThrowsDemo{
// public void dosome()throws IOException,AWTException{}
//1、允许仅抛出部分异常
// public void dosome()throws IOException{}
//2、允许不再抛出任何异常
// public void dosome(){}
//3、允许抛出超类方法抛出异常的子类型异常
// public void dosome()throws FileNotFoundException {}
//4、不允许抛出额外异常(超类方法没有声明抛出的,或和超类声明抛出的异常没有继承关系的)
//即SQLException不继承于:IOException和AWTException
// public void dosome()throws SQLException{}
//5、不允许抛出超类方法抛出异常的超类型异常 即抛出超类方法的异常不能为超类的超类
// public void dosome()throws Exception{}
}
03.throw 与 throws 的区别
throw:
用在方法的内部,其后跟着的是异常对象的名字
表示此处抛出异常,由方法体内的语句处理
注意:执行throw一定抛出了某种异常
throws:
用在方法声明处,其后跟着的是异常类的名字
表示此方法会抛出异常,需要由本方法的调用者来处理这些异常
但是注意:这只是一种可能性,异常不一定会发生
5、异常中的常用API:
异常中的常用API:
(1).printStackTrace():用来在控制台输出输出异常的堆栈信息,便于程序员debug:
(2).getMessage():获取错误信息,一般用于提示给客户或者记录日志的时候使用
练习题:
package apiday.day06.exceptionApi;
/**
* 异常中的常用API:
* (1).printStackTrace():用来在控制台输出输出异常的堆栈信息,便于程序员debug:
* (2).getMessage():获取错误信息,一般用于提示给客户或者记录日志的时候使用
*/
public class ExceptionApiDemo {
public static void main(String[] args) {
System.out.println("程序开始了");
try {
String str = "abc";
System.out.println(Integer.parseInt(str));
} catch (Exception e) {
System.out.println("出错了,正在解决。。。");
//(1).printStackTrace():用来在控制台输出错误信息,便于程序员debug:
// e.printStackTrace();//java.lang.NumberFormatException
//(2).getMessage():获取错误信息,一般用于提示给客户或者记录日志的时候使用
String message = e.getMessage();
System.out.println(message);
}
System.out.println("程序结束了");
}
}
6、自定义异常
声明自定义异常:在 Java 中你可以自定义异常。编写自己的异常类时需要记住下面的几点。
- 所有异常都必须是 Throwable 的子类。
- 如果希望写一个检查性异常类,则需要继承 Exception 类。
- 如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
- 可以像下面这样定义自己的异常类:class MyException extends Exception{ }
只继承Exception 类来创建的异常类是检查性异常类。一个异常类和其它任何类一样,包含有变量和方法。
自定义异常应当做到以下几点:
1:类名要见名知意。
2:需要继承Exception(直接或间接继承均可)
3:提供超类中所有的构造器
《IllegalAgeException.java》:
package exception;
/**
* 自定义异常:——————>通常使用自定义异常用来表达业务错误
* 自定义异常应当做到以下几点:
* 1:类名要见名知意。
* 2:需要继承Exception(直接或间接继承均可)
* 3:提供超类中所有的构造器
*
* Illegal:非法的
*/
public class IllegalAgeException extends Exception{//alt+insert调用Constructor(构造器)所有的超类出现以下:
public IllegalAgeException() {
}
public IllegalAgeException(String message) {
super(message);
}
public IllegalAgeException(String message, Throwable cause) {
super(message, cause);
}
public IllegalAgeException(Throwable cause) {
super(cause);
}
public IllegalAgeException(String message, Throwable cause, boolean enableSuppression, boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
}
/**
* 在《Person.java》中:
* (1)将setAge()方法抛出异常:【throws IllegalAgeException】
* (2)在if()————>括号里将【throw new Exception("年龄不合法异常");】
* 改为:【throw new IllegalAgeException("年龄不合法异常");】
* 使用当前类测试异常的抛出:
*/
package exception;
/**
* 使用当前类测试异常的抛出
*/
public class Person {
private int age;
public int getAge() {
return age;
}
public void setAge(int age) throws IllegalAgeException {//添加throws IllegalAgeException解决下面异常问题
if(age<0 || age>100){
//使用throw对外抛出一个异常:
//throw new RuntimeException("年龄不合法!");
/*
注意:
除了RuntimeException之外,抛出什么异常就要在方法上声明throws什么异常
//PS(附言/备注):虽然使用try-catch也能保证不报错,但是这里没意义!
*/
//throw new Exception("年龄不合法!");
//抛出自定义异常:
throw new IllegalAgeException("年龄超过了范围:"+age);
}
this.age = age;
}
}
/**
* 在《Throw_PersonDemo.java》的catch()括号里将异常改为:IllegalAgeException 测试即可
* p.setAge(1000);
* } catch (IllegalAgeException e) {
* e.printStackTrace();
* }
*/
package exception;
/**
* 异常的抛出
*/
public class ThrowDemo {
public static void main(String[] args){
System.out.println("程序开始了...");
try {
Person p = new Person();
/*
当我们调用一个含有throws声明异常抛出的方法时,编译器要求
我们必须添加处理异常的手段,否则编译不通过.而处理手段有两种
1:使用try-catch捕获并处理异常
2:在当前方法上继续使用throws声明该异常的抛出
------具体用哪种取决于异常处理的责任问题
*/
p.setAge(100000);//典型的符合语法,但是不符合业务逻辑要求
System.out.println("此人年龄:"+p.getAge()+"岁");
} catch (IllegalAgeException e) {
e.printStackTrace();
}
System.out.println("程序结束了...");
}
}
二、线程:
1、关于进程和线程的介绍:
01.什么是进程(内存开销大)?
1、关于进程和线程的介绍:
01.什么是进程(内存开销大)?
(1)操作系统中运行的一个任务(一个应用程序运行在一个进程中)
(2)是一块包含了某些资源的内存区域。操作系统利用进程把他的工作划分为一些功能单元。
(3)进程中包含的一个或多个执行单元称为线程(thread)。进程还拥有一个私有的虚拟地址空间,该空间仅能被他所包含的线程访问。
总结:①当一个程序开始运行时,它就是一个进程,进程包括运行中的程序和程序所使用到的内存和系统资源。
②而【一个进程又是由多个线程所组成的】
——————————————————————————————————————————————————————
(4)程序:数据与指令的集合,而且程序是静态的
(5)进程:运行中的程序,给程序加入了时间的概念,不同时间进程有不同的状态,进程是动态的,代表OS中正在运行的程序;
进程有独立性,动态性,并发性
(6)并行:相对来说资源比较充足,多个CPU同时并发处理多个不同的进程
(7)串行:相对来说资源不太充足,多个资源同时抢占公共资源,比如CPU
02.什么是线程(内存开销小)?线程5种状态
02.什么是线程(内存开销小)?————>线程分为:线程和多线程
(1)线程: 一个顺序的单一的程序执行流程就是一个线程。通俗说———>代码一句一句的有先后顺序的执行。
①线程是OS能够进行运算调度的最小单位;
②一个进程可以拥有多个线程,当然,也可以只拥有一个线程,只有一个线程的进程称作单线程程序
③注意:每个线程也有自己独立的内存空间,当然也有一部分共享区域用来保存共享的数据
(2)多线程: 多个单一顺序执行的流程并发运行。造成"感官上同时运行"的效果。
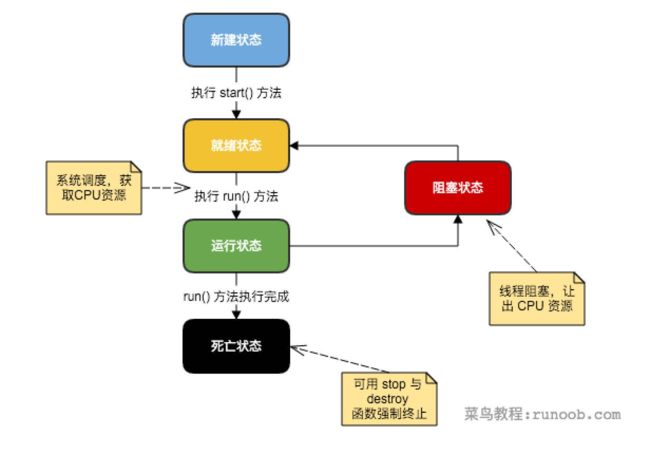
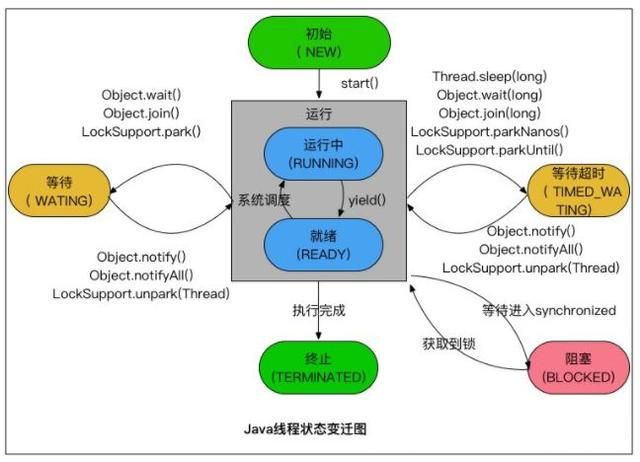
03.线程的5种状态:
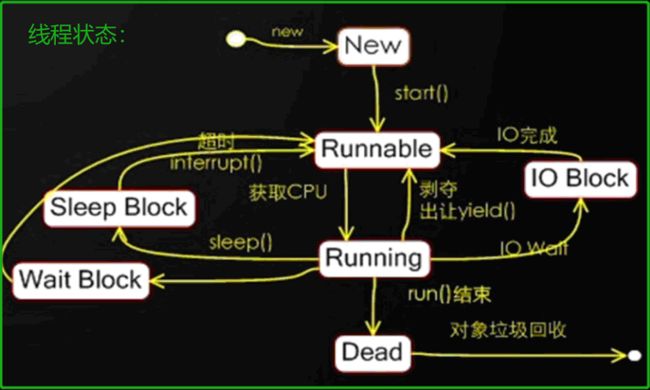
03.一个线程完整的生命周期有5种状态:——————>线程是一个动态执行的过程,它也有一个从产生到死亡的过程。
①新建状态: 使用new关键字和Thread类或其子类建立一个线程对象后,该线程对象就处于新建状态。
它保持这个状态直到程序启动(start)这个线程。
②就绪状态: Runnable。当线程对象调用了start()方法之后,该线程就进入就绪状态。就绪状态的
线程处于就绪队列中,要等待JVM里线程调度器的调度。
③运行状态: Running。如果就绪状态的线程获取 CPU 资源,就可以执行run(),此时线程便处于运行状态。
处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
④阻塞状态: Blocked。——————处于Runnable状态和Running状态之间。
如果一个线程执行了sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,
该线程就从运行状态进入阻塞状态。在睡眠时间已到或者获得设备资源后可以重新进入就绪状态。可以分为三种:
1)等待阻塞:运行状态(Running)中的线程执行 wait() 方法,
JVM会把该线程放入等待队列(waitting queue)中。
使线程进入到等待阻塞状态。
2)同步阻塞:运行(running)的线程在获取对象的同步锁(synchronized)时,
若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
3)其他阻塞: 运行(running)的线程执行Thread.sleep(long ms)或t.join()
方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。
当sleep()状态超时、join()等待线程终止或者超时、或者I/O处
理完毕时,线程重新转入就绪(Runnable)状态。
⑤死亡状态:Dead。一个运行状态的线程完成run()任务或者其他终止条件发生时,则该线程结束生命周期。
死亡的线程不可再次复生。会切换到终止状态,进行对象垃圾回收。
2、多线程——>造成"感官上同时运行"的效果
01.多线程的:特点/用途/优缺点
2、多线程: 多个单一顺序执行的流程并发运行。造成"感官上同时运行"的效果。
01.特点:多线程是[并发执行]的。 例如:程序中有两个子系统需要并发执行,这时候就需要利用多线程编程。
(1)并发:多个线程实际运行是走走停停的。线程调度程序会将CPU运行时间划分为若干个时间
片段并尽可能均匀的分配给每个线程,拿到时间片的线程被CPU执行这段时间。
当超时后线程调度程序会再次分配一个时间片段给一个线程使得CPU执行它。
如此反复。由于CPU执行时间在纳秒级别,我们感觉不到切换线程运行的过程。
所以微观上走走停停,宏观上感觉一起运行的现象成为并发运行!
02.多线程何时用:————用途:
(1)当出现多个代码片段执行顺序有冲突时,希望它们各干各的时就应当放在不同线程上"同时"运行
(2)一个线程可以运行,但是多个线程可以更快时,可以使用多线程运行
03.多线程的优点:——————>可以提高CPU的利用率。
:在多线程程序中,一个线程必须等待的时候,CPU可以运行其它的线程而不是等待,这样就大大提高了程序的效率。
04.多线程的缺点:
(1)线程也是程序,所以线程需要占用内存,线程越多占用内存也越多;
(2)多线程需要协调和管理,所以需要CPU时间跟踪线程;
(3)线程之间对共享资源的访问会相互影响,必须解决竞用共享资源的问题;
(4)线程太多会导致控制太复杂,最终可能造成很多Bug;
02.创建线程三种方式 和 匿名内部类方式创建线程
02.创建线程有两种方式:————>01.继承Thread并重写run方法/02.implements Runnable接口单独定义线程任务的形式:
(1)第一种:继承Thread并重写run方法——————————>例:Demo1
1)步骤:①继承Thread并重写run方法 ②实例化线程 ③启动线程
定义一个线程类,重写run方法,在其中定义线程要执行的任务(希望和其他线程并发执行的任务)。
注:启动该线程要调用该线程的start方法,而不是run方法!!!
2)优缺点:
优点:结构简单,利于匿名内部类创建
缺点:①由于java是单继承,直接继承Thread,会导致不能在继承其他类去复用方法,这在实际开发中是非常不便的。
②定义线程的同时重写了run方法,会导致线程与线程任务绑定在了一起,不利于线程的重用。
(2)第二种:实现Runnable接口单独定义线程任务:—————>例:Demo2
具体步骤:0)implements Runnable 1)创建线程任务 2)创建两条线程分别执行任务 3)启动线程
(3)第三种:实现Callable接口,
这种方式实现的线程可以获取线程的返回值(JDK8新特性),一般常规的两种方式是无法获取线程返回
值的,因为run()返回值是void的。
优点:可以获取到线程的结果
缺点:效率比较低,在获取t线程结果时,当前线程受阻塞,效率低!
(3)使用匿名内部类的创建方式完成线程的两种创建:————>例:Demo3
注意:1)启动线程调用的是线程的start方法,不能直接调用run方法!
2)start方法调用后线程会被纳入到线程调度器中被统一管理。
3)当它第一次获取了调度器分配给它的CPU时间片后就会开始执行run方法。
(1)第一种:继承Thread并重写run方法
定义一个线程类,重写run方法,在其中定义线程要执行的任务(希望和其他线程并发执行的任务)。- 注:
启动该线程要调用该线程的start()方法,而不是run方法!!!
多线程编程实现方案一:extends Thread继承方式
1)自定义一个多线程类用来继承Thread类
2)重写run()里的业务【这个业务是自定义的】
3)创建线程对象【子类对象】
4)通过刚刚创建好的自定义线程类对象调用start()
注1:不能调用run(),因为这样调用只会把run()看作一个普通的方法,并不会以多线程的方式启动程序
而且调用start()时,底层JVM会自动调用run(),执行我们自定义的业务
注2:我们除了可以调用默认的父类无参构造以外,还可以调用Thread(String name),给自定义
的线程对象起名字,相当于super(name);
/** 02.(1)创建线程有两种方式:————>第一种:继承Thread并重写run方法 */
public class ThreadDemo1 {
public static void main(String[] args) {
//(1)创建线程任务
Thread t1 = new MyThread1();
Thread t2 = new MyThread2();
//(2)启动线程
t1.start();
t2.start();
}
}
class MyThread1 extends Thread{
public void run(){
for(int i=0;i<1000;i++){
System.out.println("你是谁啊?");
}
}
}
class MyThread2 extends Thread{
public void run(){
for(int i=0;i<1000;i++){
System.out.println("我是查水表的!");
}
}
}
(2)第二种:实现Runnable接口单独定义线程任务:
为了实现 Runnable,一个类只需执行一个方法调用run(),声明如下:
- public void run()
- 你可以重写该方法,重要的是理解的run()可以调用其他方法,使用其他类,并声明变量,就像主线程一样。
- 在创建一个实现 Runnable 接口的类之后,你可以在类中实例化一个线程对象。
多线程编程实现方案二:implements Runnable 实现方式
1)自定义一个类实现接口Runnable
2) 实现接口中唯一一个抽象方法run()
3) 创建接口实现类的对象,这个对象是作为我们的目标业务对象【因为这个自定义类中包含了我们的业务】
4)创建Thread类线程对象,调用的构造函数是Thread(Runnable target)
5)通过创建好的Thread类线程对象调用start(),以多线程的方式启动同一个业务target
注意1:由于Runnable是一个接口,无法创建对象,所以我们传入的目标业务类,也就是接口实现类的对象
注意2:只有调用start()才能把线程对象加入到就绪队列中,以多线程的方式启动,但是:
接口实现类与接口都没有这个start(),所以我们需要创建Thread类的对象来调用start(),并把接口实现类对象交给Thread(target);
大家可以理解成“抱大腿”,创建的是Thread类的线程对象,我们只需要把业务告诉Thread类的对象就好啦
使用实现Runnable接口的优势:
1)耦合性不强,没有继承,后续仍然可以继承别的类
2)采用的是实现接口的方式,后续仍然可以实现别的接口
3)可以给所有的线程对象统一业务,业务是保持一致的
4)面向接口编程,有利于我们写出更加优雅的代码
package apiday.day07.thread;
/**
* 02.创建线程有两种方式:————>第二种:实现Runnable接口单独定义线程任务
* (2)第二种:实现Runnable接口单独定义线程任务:
* 步骤:0)implements Runnable 1)创建线程任务 2)创建两条线程分别执行任务 3)启动线程
*/
public class ThreadDemo2 {
public static void main(String[] args) {
//(1)创建线程任务
Runnable r1 = new MyRunnable1();
Runnable r2 = new MyRunnable1();
//(2)创建两条线程分别执行任务
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r1);
//(3)启动线程
t1.start();
t2.start();
}
}
class MyRunnable1 implements Runnable {
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println("你是谁啊?");
}
}
}
(3)第三种:实现Callable接口,可获取线程返回值
(3)第三种:实现Callable接口,
这种方式实现的线程可以获取线程的返回值(JDK8新特性),一般常规的两种方式是无法获取线程返回
值的,因为run()返回值是void的。
优点:可以获取到线程的结果
缺点:效率比较低,在获取t线程结果时,当前线程受阻塞,效率低!
package apiday.thread.thread_demo;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 02.创建线程有三种方式:————>第三种:实现Callable接口
* 第三种:实现Callable接口,
* 这种方式实现的线程可以获取线程的返回值(JDK8新特性),一般常规的两种方式是无法获取线程返回
* 值的,因为run()返回值是void的。
* 优点:可以获取到线程的结果
* 缺点:效率比较低,在获取t线程结果时,当前线程受阻塞,效率低!
*/
public class ThreadDemo3 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//第一步:创建一个“未来任务类”对象
//参数非常重要,需要给一个Callable接口实现类对象
FutureTask task = new FutureTask(new Callable() {
@Override
public Object call() throws Exception {//cal()方法相当于run方法,只不过这个有返回值
//线程执行一个任务,执行之后可能会有一个执行结果
//模拟执行:
System.out.println("call method begin");
Thread.sleep(1000*10);
System.out.println("call method end");
int a = 100;
int b = 200;
return a+b;
}
});
//创建线程对象:
Thread t = new Thread(task);
t.start();
Object obj = task.get();
System.out.println("执行结果为:"+obj);
//返回线程的结果,这里main想要执行必须等待get()方法结束,main被阻塞
}
}
(4)使用匿名内部类的创建方式完成线程的两种创建:
注意:
- 1)
启动线程调用的是线程的start方法,不能直接调用run方法! - 2)
start方法调用后线程会被纳入到线程调度器中被统一管理。 - 3)
当它第一次获取了调度器分配给它的CPU时间片后就会开始执行run方法。
package apiday.day07.thread;
/**
* (3)使用匿名内部类的创建方式完成线程的两种创建:
* 注意:(1)启动线程调用的是线程的start方法,不能直接调用run方法!
* (2)start方法调用后线程会被纳入到线程调度器中被统一管理。
* (3)当它第一次获取了调度器分配给它的CPU时间片后就会开始执行run方法。
*/
public class ThreadDemo3 {
public static void main(String[] args) {
/* 第一种:继承Thread重写run()的形式:*/
Thread t1 = new Thread(){
public void run() {
for(int i=0;i<1000;i++){
System.out.println("你是谁啊?");
}
}
};
//(1)启动线程调用的是线程的start方法,不能直接调用run方法!
//(2)start方法调用后线程会被纳入到线程调度器中被统一管理。
//(3)当它第一次获取了调度器分配给它的CPU时间片后就会开始执行run方法。
t1.start();
/* 第二种:implements Runnable接口单独定义线程任务的形式:*/
Runnable r2 = new Runnable(){
public void run(){
for(int i=0;i<1000;i++){
System.out.println("我是查水表的!");
}
}
};
Thread t2 = new Thread(r2);
t2.start();
}
}
3、线程API
01.获取运行当前这个方法的线程名字-----static Thread currentThread()
(1)Java中的代码都是靠线程运行的,执行main方法的线程称为"主线程"。
- Thread提供了一个方法:该方法可以获取运行这个方法的线程:
- static Thread currentThread()
/**
package apiday.day07.thread;
/**
* java中所有的代码都是靠线程执行的,main方法也不例外。JVM启动后会创建一条线程来执行main
* 方法,该线程的名字叫做"main",所以通常称它为"主线程"。
* 我们自己定义的线程在不指定名字的情况下系统会分配一个名字,格式为"thread-x"(x是一个数)。
*
* Thread提供了一个静态方法:
* static Thread currentThread()
* 获取执行该方法的线程。
*
*/
public class CurrentThreadDemo {//CurrentThread:当前线程
public static void main(String[] args) {
//用于获取执行当前方法的线程的名字:
Thread main = Thread.currentThread();
System.out.println("主线程:"+main);//主线程:Thread[main,5,main]
//主线程调用dosome()方法:
dosome();
}
public static void dosome(){
//用于获取执行当前方法的线程的名字:
Thread t = Thread.currentThread();
System.out.println("执行dosome()方法是线程是:"+t);//执行dosome()方法是线程是:Thread[main,5,main]
}
}
02.获取线程相关信息的方法:
1、线程提供了一套获取相关信息的方法:
(1)获取运行的方法当前线程的名字:———————>currentThread()
(2)获取线程的名字:——————————————————>getName()
(3)获取线程的唯一标识:———————————————>getId()
(4)获取线程的优先级(priority):———————>getPriority()
(5)检测当前线程是否被中断了:——————————>isInterrupted()
(6)检测是否为守护线程:———————————————>isDaemon()
(7)检测是否活着:————————————————————>isAlive()
练习题:
package apiday.thread.thread_api;
/**
* 1、线程提供了一套获取相关信息的方法:
* (1)获取运行的方法当前线程的名字:———————>currentThread()
* (2)获取线程的名字:——————————————————>getName()
* (3)获取线程的唯一标识:———————————————>getId()
* (4)获取线程的优先级(priority):———————>getPriority()
* (5)检测当前线程是否被中断了:——————————>isInterrupted()
* (6)检测是否为守护线程:———————————————>isDaemon()
* (7)检测是否活着:————————————————————>isAlive()
*/
public class Thread_Information {
public static void main(String[] args) {
//获取主线程的名字进行查看:
Thread main = Thread.currentThread();
System.out.println(main);//Thread[main,5,main]
//获取线程的名字:
String name = main.getName();
System.out.println(name);//main
//获取线程的唯一标识
long id = main.getId();
System.out.println(id);//1
//获取线程的优先级(priority):
int priority = main.getPriority();
System.out.println(priority);//5
//当前线程是否被中断了:
boolean isInterrupted = main.isInterrupted();
System.out.println("是否被中断:"+isInterrupted);//是否被中断:false
//是否为守护线程:
boolean isDaemon = main.isDaemon();
System.out.println("是否为守护线程:"+isDaemon);//是否为守护线程:false
//是否活着:
boolean isAlive = main.isAlive();
System.out.println("是否活着:"+isAlive);//是否活着:true
}
}
03.线程的优先级(1-10 5为默认值)
线程start后会纳入到线程调度器中统一管理,线程只能被动的被分配时间片并发运行,而无法主动索取时间片.线程调度器尽可能均匀的将时间片分配给每个线程。
Java 线程线程有10个优先级,使用整数1-10表示:
1(Thread.MIN_PRIORITY)-------1为最小优先级
10(Thread.MAX_PRIORITY)----10为最高优先级NORM_PRIORITY(5)--------------5为默认值
调整线程的优先级可以最大程度的干涉获取时间片的几率.优先级越高的线程获取时间片的次数越多,反之则越少.
线程的优先级(Priority):
——————>共10个优先级,分别对应整数1-10 其中1为最低优先级,10为最高优先级。5为默认值。
(1)线程start方法调用后便纳入到了线程调度器中统一管理,此时线程只能被动被分配时间片来并发运行而不能主动获取时间片。
(2)调度器会尽可能均匀的将时间片分配给每一个线程。
(3)修改线程的优先级可以最大程度改善获取时间片的次数。
(4)优先级越高的线程获取时间片的次数越多。但要注意:线程是并发运行的,不是说谁先调用start()谁就先执行
练习题:
package apiday.thread.thread_priority;
/**
* 线程的优先级(Priority):
* ——————>共10个优先级,分别对应整数1-10 其中1为最低优先级,10为最高优先级。5为默认值。
* (1)线程start方法调用后便纳入到了线程调度器中统一管理,此时线程只能被动被分配时间片来并发运行而不能主动获取时间片。
* (2)调度器会尽可能均匀的将时间片分配给每一个线程。
* (3)修改线程的优先级可以最大程度改善获取时间片的次数。
* (4)优先级越高的线程获取时间片的次数越多。但要注意:线程是并发运行的,不是说谁先调用start()谁就先执行
*/
public class PriorityDemo {
public static void main(String[] args) {
Thread min = new Thread(){
public void run(){
for(int i=0;i<10000;i++){
System.out.println("min");
}
}
};
Thread norm = new Thread(){
public void run(){
for(int i=0;i<10000;i++){
System.out.println("norm");
}
}
};
Thread max = new Thread(){
public void run(){
for(int i=0;i<10000;i++){
System.out.println("max");
}
}
};
//修改线程的优先级可以最大程度改善获取时间片的次数:此处设置优先级为1:
//min.setPriority(1);
//设置为1/5/10三个优先级:——————优先级越高的线程获取时间片的次数越多。
//但要注意:线程是并发运行的,不是说谁先调用start()谁就先执行
min.setPriority(Thread.MIN_PRIORITY);
norm.setPriority(Thread.NORM_PRIORITY);
max.setPriority(Thread.MAX_PRIORITY);
//调用start()启动线程:
min.start();
norm.start();
max.start();
}
}
04.线程状态之----------sleep阻塞
线程提供了一个静态方法:
- static void sleep(long ms)
- 使运行该方法的线程进入阻塞状态指定的毫秒,超时后线程会自动回到RUNNABLE状态等待再次获取时间片并发运行。
(1)sleep阻塞01:-------------倒计时小程序:
1、sleep阻塞:
Thread提供了一个静态方法:————>static void sleep():
可以使运行该方法的线程阻塞指定毫秒;
;超时后线程会自动回到RUNNABLE状态等待再次获取时间片继续并发运行
(1)程序阻塞5秒钟练习题:
01.倒计时程序:2种写法:
要求:输入一个数字,然后从该数字开始每秒递减,到0时输出时间到
练习题:
package apiday.thread.thread_api;
import java.util.Scanner;
/**
* 1、sleep阻塞:
* Thread提供了一个静态方法:————>static void sleep():可以使运行该方法的线程阻塞指定毫秒。
* 超时后线程会自动回到RUNNABLE状态等待再次获取时间片继续并发运行
* 程序阻塞5秒钟练习题:
*
* 01.倒计时程序:2种写法:————>要求:输入一个数字,然后从该数字开始每秒递减,到0时输出时间到
*
*/
public class Thread_Sleep {
public static void main(String[] args) {
/** (1)程序阻塞5秒钟:*/
// System.out.println("程序开始");
// try {
// //
// Thread.sleep(5000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// System.out.println("程序结束了");
/** 1、01.倒计时程序: */
//要求:输入一个数字,然后从该数字开始每秒递减,到0时输出时间到
/*
//第一种写法:try写在for外面
try {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个数字:");
for (int num = scanner.nextInt(); num > 0; num--) { //每秒递减
System.out.println(num);
Thread.sleep(1000);
}
System.out.println("时间到!");
} catch (InterruptedException e) {
e.printStackTrace();
}
*/
//第2种写法:try在for里面
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个数字:");
for(int num = scanner.nextInt();num>0;num--) {
System.out.println(num);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("时间到!程序结束了...");
}
}
(2)sleep阻塞02:-----sleep方法必处理中断异常
sleep方法要求必须处理中断异常:InterruptedException:
当一个线程调用sleep方法处于睡眠阻塞的过程中,此时该线程的interrupt()方法被调用时会立即中断该睡眠阻塞,并抛出中断异常(InterruptedException)。- //林的睡眠时间>黄的敲锤时间才会报中断异常(干嘛呢!干嘛呢!都破相了!)
- //林的睡眠时间<黄的敲锤时间会被中断唤醒不会报中断异常(即不输出:干嘛呢!干嘛呢!都破相了!)
02.sleep方法要求必须处理中断异常(InterruptedException):
:当一个线程调用sleep方法处于睡眠阻塞的过程中,此时该线程的interrupt()方法被
调用时会立即中断该睡眠阻塞,并且sleep()方法会抛出中断异常。
(1)interrupt():打断,中断。用于立即中断一个处于调用sleep()睡眠的线程,
并且此时sleep()方法会抛出中断异常(InterruptedException)。
练习题:
package apiday.thread.thread_api;
import java.util.Scanner;
/**
* 1、sleep阻塞:
* 02.sleep方法要求必须处理中断异常(InterruptedException):
* :当一个线程调用sleep方法处于睡眠阻塞的过程中,此时该线程的interrupt()方法被
* 调用时会立即中断该睡眠阻塞,并且sleep()方法会抛出中断异常。
* (1)interrupt():打断,中断。用于立即中断一个处于调用sleep()睡眠的线程,
* 并且此时sleep()方法会抛出中断异常(InterruptedException)。
*/
public class Thread_Sleep {
public static void main(String[] args) {
/** 1、02.sleep方法要求必须处理中断异常:*/
/*
当一个线程调用sleep方法处于睡眠阻塞的过程中,
此时该线程的interrupt()方法被调用时会立即中
断该睡眠阻塞,并且sleep()方法会抛出中断异常。
*/
Thread lin = new Thread() {
public void run() {
System.out.println("林:刚美完容,去睡一会~");
try {
//林的睡眠时间>黄的敲锤时间才会报中断异常(干嘛呢!干嘛呢!都破相了!)
//林的睡眠时间<黄的敲锤时间会被中断唤醒不会报中断异常(即不输出:干嘛呢!干嘛呢!都破相了!)
Thread.sleep(5000000);
} catch (InterruptedException e) {
System.out.println("干嘛呢,干嘛呢");
}
System.out.println("吵醒我了!");
}
};
Thread huang = new Thread() {
public void run() {
System.out.println("黄:大锤80,小锤40,开始砸墙!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
//e.printStackTrace();
}
System.out.println("咣当!");
System.out.println("黄:大哥!搞定了!");
lin.interrupt();//中断lin线程的睡眠阻塞,强制唤醒
}
};
lin.start();
huang.start();
}
}
05.线程插队join()-----可以协调线程的同步运行
join() 定义在Thread.java中。
join会阻塞线程仅仅是一个表现,而非目的。其目的是等待当前线程执行完毕后,”计算单元”与主线程汇合。即主线程与子线程汇合之意。
- 该方法允许调用这个方法的线程在该方法所属线程上等待(阻塞),直到该方法所属线程结束后才会解除等待继续后续的工作.所以join方法可以用来协调线程的同步运行。
- 同步运行:多个线程执行过程存在先后顺序进行。
- 异步运行:多个线程各干各的.线程本来就是异步运行的。
Thread中,join()方法的作用:
进行线程插队,
是调用线程等待该线程执行完成后,才能继续用下运行。
如果要join正常生效,调用join方法的对象必须已经调用了start()方法且并未进入终止状态。
(调用download.join()的线程进入等待池并等待 download线程 执行完毕后才会被唤醒。
并不影响同一时刻处在运行状态的其他线程。)
练习题:
《joinDemo.java》:
//将show线程阻塞,直到download执行完毕(图片下载完毕)
//若没有download.joi()方法,则会抛出异常:throw new RuntimeException("图片加载失败!");
若调用download.join()的线程进入等待池并等待 download线程 执行完毕后才会被唤醒。
并不影响同一时刻处在运行状态的其他线程。)
package thread;
/**
* 线程提供的方法:join可以协调线程的同步运行
* 多线程是并发运行,本身是一种异步运行的状态。
* 同步运行:多个线程执行是存在了先后顺序。
* 异步运行:各自执行各自的
*
* join:加入
* finish:完成
*/
public class JoinDemo {
static boolean isFinish = false;//Finish:完成。表示图片是否下载完成
public static void main(String[] args) {//两个线程:download、show
Thread download = new Thread(){
public void run(){
System.out.println("down:开始下载图片...");
for(int i=0;i<=100;i++){
System.out.println("down:"+i+"%");
try{
Thread.sleep(50);
}catch(InterruptedException e){
e.printStackTrace();
}
}
System.out.println("down:图片下载完成!");
isFinish = true;
}
};
Thread show = new Thread(){
public void run(){
System.out.println("show:开始显示文字");
try{
Thread.sleep(2000);
}catch(InterruptedException e){
}
System.out.println("show:显示文字完毕!");
//将show线程阻塞,直到download执行完毕(图片下载完毕)
/*Thread.sleep(?);//会报错,无法准确预估download结束时间*/
try {
/*
当show线程调用download.join()后便进入了阻塞状态。
直到download线程执行完毕后才会解除阻塞。
*/
download.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("show:开始显示图片...");
if(!isFinish){
throw new RuntimeException("图片加载失败!");//抛出新的异常
}
System.out.println("图片显示完毕");
}
};
download.start();
show.start();
}
}
4、守护线程(Daemon)------setDaemon(true)
-
(1)守护线程也称为:后台线程
- 守护线程是通过普通线程调用
setDaemon(boolean on)方法设置而来的,因此创建上与普通线程无异. - 守护线程的结束时机上有一点与普通线程不同, 即进程的结束.
- 进程结束:当一个进程中的所有普通线程都结束时,进程就会结束,此时会杀掉所有正在运行的守护线程.
- 守护线程是通过普通线程调用
-
(2)建议哪种线程设置为守护线程?
- 通常当我们不关心某个线程的任务什么时候停下来,它可以一直运行,但是程序主要的工作都结束时它应当跟着结束时,这样的任务就适合放在守护线程上执行.比如GC就是在守护线程上运行的.
1、Java有两种Thread:——————>【用户线程(User):前台线程】 和 【守护线程(Daemon):后台线程】。
:任何线程都可以是以上两种。他们在几乎每个方面都是相同的。唯一的不同之处就在于虚拟机的离开。
(1)用户线程(User):日常开发中编写的业务逻辑代码,运行起来都是一个个用户线程。
(2)守护线程(Daemon):
①守护线程则是用来服务用户线程的,若没有其他用户线程在运行,他也没作用了。也就没有理由继续下去。
②守护线程是是运行在后台的一种特殊进程,它并不属于程序本体。
***2、守护线程:——————>是通过普通线程调用setDaemon(true)方法设置而来的。
注意:设置守护线程的工作必须在start()之前完成
(1)setDaemon(true):true为Daemon模式,false为User模式。
(2)setDaemon(boole on) :将此线程标记为守护线程或用户线程。当唯一运行的线程都是守护线程时,
Java 虚拟机退出。此方法必须在线程启动之前调用。
01.守护线程和普通线程的区别?
体现在一个结束时机上的不同:当进程结束时,进程会强制杀死所有正在运行的守护线程并最终停止。
02.那Java的守护线程是什么样子的呢?
当JVM中所有的线程都是守护线程的时候,JVM就可以退出了;如果还有一个或以上的非守护线程则JVM不会退出。
03.进程的结束:当java进程中所有的普通线程都结束时,进程就会结束。
04.典型守护线程的例子:————>JVM垃圾回收
守护线程在没有用户线程可服务时自动离开,用于为系统中的其它对象和线程提供服务:
典型的守护线程例子是JVM中的系统资源自动回收线程,我们所熟悉的Java垃圾回收线程就是一个典型的守护线程,
当我们的程序中不再有任何运行中的Thread,程序就不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收
线程是Java虚拟机上仅剩的线程时,Java虚拟机会自动离开。
05.如下jack就是守护线程,守护着最后一个用户线程,如果没有用户线程了,他也没作用了。不退出等什么?
练习题:
package apiday.thread.thread_daemon;
/**
* 1、Java有两种Thread:——————>【用户线程(User):前台线程】 和 【守护线程(Daemon):后台线程】。
* :任何线程都可以是以上两种。他们在几乎每个方面都是相同的。唯一的不同之处就在于虚拟机的离开。
* (1)用户线程(User):日常开发中编写的业务逻辑代码,运行起来都是一个个用户线程。
* (2)守护线程(Daemon):
* ①守护线程则是用来服务用户线程的,若没有其他用户线程在运行,他也没作用了。也就没有理由继续下去。
* ②守护线程是是运行在后台的一种特殊进程,它并不属于程序本体。
*
* 2、守护线程:—————————>是通过普通线程调用setDaemon(true)方法设置而来的。
* 注意:设置守护线程的工作必须在start()之前完成
* (1)setDaemon(true):true为Daemon模式,false为User模式。
* (2)setDaemon(boole on) :将此线程标记为守护线程或用户线程。当唯一运行的线程都是守护线程时,
* Java 虚拟机退出。此方法必须在线程启动之前调用。
* 01.守护线程和普通线程的区别?
* 体现在一个结束时机上的不同:当进程结束时,进程会强制杀死所有正在运行的守护线程并最终停止。
*
* 02.那Java的守护线程是什么样子的呢?
* 当JVM中所有的线程都是守护线程的时候,JVM就可以退出了;如果还有一个或以上的非守护线程则JVM不会退出。
*
* 03.进程的结束:当java进程中所有的普通线程都结束时,进程就会结束。
*
* 04.典型守护线程的例子:————>JVM垃圾回收
* 守护线程在没有用户线程可服务时自动离开,用于为系统中的其它对象和线程提供服务:
* 典型的守护线程例子是JVM中的系统资源自动回收线程,我们所熟悉的Java垃圾回收线程就是一个典型的守护线程,
* 当我们的程序中不再有任何运行中的Thread,程序就不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收
* 线程是Java虚拟机上仅剩的线程时,Java虚拟机会自动离开。
*
* 05.如下jack就是守护线程,守护着最后一个用户线程,如果没有用户线程了,他也没作用了。不退出等什么?
*
*/
public class DaemonThread {
public static void main(String[] args) {
Thread rose = new Thread(){//rose和jack没有必然关系
public void run(){
for(int i=0;i<5;i++){
System.out.println("rose:let me go!");//让我走
try{
Thread.sleep(1000);//设计间隔时间为1秒
}catch(InterruptedException e){ //中断异常
//e.printStackTrace();//在控制台显示异常的信息
}
}
System.out.println("rose:啊啊啊啊啊AAAAAAAaaaaa......");
System.out.println("噗通!");
}
};
Thread jack = new Thread(){
public void run(){
while(true){
System.out.println("jack:you jump! i jump!");//你跳!我也跳!
try{
Thread.sleep(1000);
}catch(InterruptedException e){
}
}
}
};
rose.start();
//设置守护线程的工作必须在start()之前完成
//将此线程标记为守护线程或用户线程。当唯一运行的线程都是守护线程时,
// Java 虚拟机退出。此方法必须在线程启动之前调用。
jack.setDaemon(true);//setDaemon:守护线程
jack.start();
//当主线程不会结束时,进程就不会结束(因为主线程也是普通线程)
//输出下面代码时,其余线程结束了,jack也会一直执行(you jump! i jump!)
while(true);
}
}
5、多线程并发安全问题-----线程同步:synchronized同步
01.多线程并发安全问题:控制台有极低几率显示报错(RuntimeException: 没有豆子了!):
当多个线程并发操作同一临界资源,由于线程切换实际不如确定,会导致操作顺序出现混乱而引起各种逻辑错误,严重时可能导致系统瘫痪。临界资源:操作该资源的完整过程同一时刻只能由单线程进行。
一、多线程并发安全问题:-----------------线程同步:synchronized
(1)当多个线程并发操作同一临界资源,由于线程切换时机不确定,导致操作顺序出现了混乱,产生不正常后果。
(2)临界资源:操作该资源的完整过程同一时刻只能有单个线程进行的
1、
01.例1:演示多线程并发安全问题:控制台有极低几率显示报错(RuntimeException: 没有豆子了!):
*(1)static void yield():线程提供的这个静态方法作用是让执行该方法的线程主动放弃本次时间片。
这里使用它的目的是模拟执行到这里CPU没有时间了,发生线程切换,来看并发安全问题的产生。
(补充):
(1)java 中的三种变量,哪种存在线程安全问题?
1)局部变量永远都不会存在线程安全问题,因为局部变量是不共享的(一个线程一一个栈);
2)实例变量在堆中,堆只有1个,所以堆是多线程共享的,导致实例变量可能会存在线程安全问题;
3)静态变量在方法区中,方法区只有1个,所以方法区是多线程共享的,导致静态变量可能会存在线程安全问题;
(2)怎么解决线程安全问题?
线程同步机制----------------程序排队执行,会牺牲一部分效率;
1)异步编程模型:线程t1和线程t2,各自执行各自的,其实就是多线程并发(效率较高)
2)同步编程模型:当一个线程正在执行时,其他线程必须等此线程执行完毕才能执行,线程排队执行(效率较低);
练习题:
package apiday.thread.thread_synchronized;
/**
* 一、多线程并发安全问题:-----------------线程同步:synchronized
* (1)当多个线程并发操作同一临界资源,由于线程切换时机不确定,导致操作顺序出现了混乱,产生不正常后果。
* (2)临界资源:操作该资源的完整过程同一时刻只能有单个线程进行的
*
* 1、
* 01.例1:演示多线程并发安全问题:控制台有极低几率显示报错(RuntimeException: 没有豆子了!):
* (1)static void yield():线程提供的这个静态方法作用是让执行该方法的线程主动放弃本次时间片。
* 这里使用它的目的是模拟执行到这里CPU没有时间了,发生线程切换,来看并发安全问题的产生。
*/
public class SyncDemo1 {
public static void main(String[] args) {
/** 1、01.例1:多线程并发安全问题:控制台有极低几率显示报错(RuntimeException: 没有豆子了!): */
Table table = new Table();
Thread t1 = new Thread(){
public void run() {
//写一个死循环:
while(true){
int bean = table.getBeans();//从桌子上取一个豆子
/*
* (1):static void yield():yield:让出
* 线程提供的这个静态方法作用是让执行该方法的线程主动放弃本次时间片。
* 这里使用它的目的是模拟执行到这里CPU没有时间了,发生线程切换,来看并发安全问题的产生。
*/
Thread.yield();
System.out.println(getName()+":"+bean);
}
}
};
Thread t2 = new Thread(){
public void run() {
//写一个死循环:
while(true){
int bean = table.getBeans();//从桌子上取一个豆子
Thread.yield();
System.out.println(getName()+":"+bean);
}
}
};
t1.start();
t2.start();
}
}
class Table{
private int beans = 20;//桌子上有20个豆子
public int getBean(){
if(beans==0){
throw new RuntimeException("没有豆子了!");
}
Thread.yield();
return beans--;
}
}
02.synchronized两种使用方式之——>①同步方法
- 当一个方法使用synchronized修饰后,这个方法称为"同步方法",即:多个线程不能同时
在方法内部执行.只能有先后顺序的一个一个进行. 将并发操作同一临界资源的过程改为同步执行就可以有效的解决并发安全问题.
02.↑↑↑为了解决例1多线程并发安全问题:————>使用synchronized(同步)修饰该方法
(2):当一个方法使用synchronized修饰后,这个方法称为【同步方法】,多个线程不能同时执行该方法。
【将多个线程并发操作临界资源的过程改为[同步操作]】就可以有效的解决多线程并发安全问题。
相当于让多个线程从原来的抢着操作改为排队操作。
2、synchronized 的2种使用方式:
(1)在方法上修饰,此时该方法变为一个同步方法
例:public synchronized int getBeans(){。。。}
(2)同步块,可以更准确的锁定需要排队的代码片段
例:synchronized(){。。。}
练习题:
package apiday.thread.thread_synchronized;
/**
* 一、多线程并发安全问题:-----------------线程同步:synchronized
* (1)当多个线程并发操作同一临界资源,由于线程切换时机不确定,导致操作顺序出现了混乱,产生不正常后果。
* (2)临界资源:操作该资源的完整过程同一时刻只能有单个线程进行的
*
* 1、
* 01.例1:演示多线程并发安全问题:控制台有极低几率显示报错(RuntimeException: 没有豆子了!):
* (1)static void yield():线程提供的这个静态方法作用是让执行该方法的线程主动放弃本次时间片。
* 这里使用它的目的是模拟执行到这里CPU没有时间了,发生线程切换,来看并发安全问题的产生。
*
* 02.↑↑↑为了解决例1多线程并发安全问题:————>使用synchronized(同步)修饰该方法
* (2):当一个方法使用synchronized修饰后,这个方法称为【同步方法】,多个线程不能同时执行该方法。
* 【将多个线程并发操作临界资源的过程改为[同步操作]】就可以有效的解决多线程并发安全问题。
* 相当于让多个线程从原来的抢着操作改为排队操作。
* 2、synchronized 的2种使用方式:
* (1)在方法上修饰,此时该方法变为一个同步方法
* 例:public synchronized int getBeans(){。。。}
* (2)同步块,可以更准确的锁定需要排队的代码片段
* 例:synchronized(){。。。}
*/
public class SyncDemo1 {
public static void main(String[] args) {
/** 1、01.例1:多线程并发安全问题:控制台有极低几率显示报错(RuntimeException: 没有豆子了!): */
Table table = new Table();
Thread t1 = new Thread(){
public void run() {
//写一个死循环:
while(true){
int bean = table.getBeans();//从桌子上取一个豆子
/*
* (1):static void yield():yield:让出
* 线程提供的这个静态方法作用是让执行该方法的线程主动放弃本次时间片。
* 这里使用它的目的是模拟执行到这里CPU没有时间了,发生线程切换,来看并发安全问题的产生。
*/
Thread.yield();
System.out.println(getName()+":"+bean);
}
}
};
Thread t2 = new Thread(){
public void run() {
//写一个死循环:
while(true){
int bean = table.getBeans();//从桌子上取一个豆子
Thread.yield();
System.out.println(getName()+":"+bean);
}
}
};
t1.start();
t2.start();
}
}
class Table{
private int beans = 20;//桌子上有20个豆子
/** 1、02.↑↑↑为了解决例1多线程并发安全问题:————>使用synchronized(同步)修饰该方法 */
/*
* (2):
* 当一个方法使用synchronized修饰后,这个方法称为同步方法,多个线程不能同时执行该方法。
* 将多个线程并发操作临界资源的过程改为同步操作就可以有效的解决多线程并发安全问题。
* 相当于让多个线程从原来的抢着操作改为排队操作。
*
* (3)synchronized 的2种使用方式之一:
* ①在方法上修饰,此时该方法变为一个同步方法
*/
public synchronized int getBeans(){//———————>变为同步方法
if(beans==0){
throw new RuntimeException("没有豆子了!");
}
Thread.yield();//让线程主动放弃本次时间片,用来模拟执行到这里时CPU就没有时间了
return beans--;
}
}
03.synchronized两种使用方式之——>②同步块
(1)同步块:------------用sychronized修饰的方法 或者 语句块在代码执行完之后锁会自动释放
有效的缩小同步范围可以在保证并发安全的前提下尽可能的提高并发效率.同步块可以更准确的控制需要多个线程排队执行的代码片段.
1)语法:
同步执行:多个线程执行时有先后顺序
synchronized(同步监视器/对象上锁的对象){
//需要多个线程同步执行的代码片段(也就是可能出现问题的操作共享数据的多条语句)
}
(补充):
当两个并发线程访问同一个对象object中的这个加锁同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。然而,当一个线程访问object的一个加锁代码块时,另一个线程仍可以访问该object中的非加锁代码块。
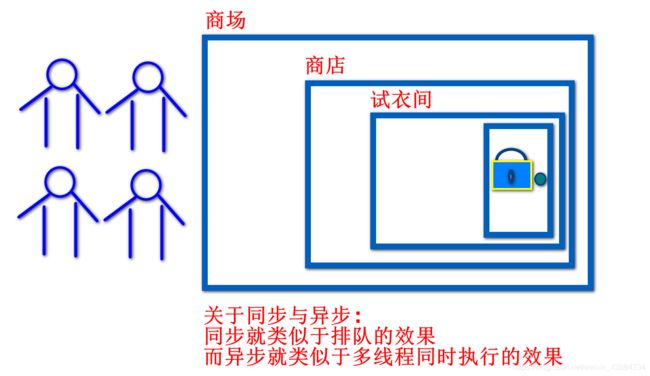
同步监视器对象即上锁的对象,要想保证同步块中的代码被多个线程同步运行,则要求多个线程看到的同步监视器对象是同一个。
2、synchronized 的2种使用方式:
(1)在方法上修饰时,同步监视器对象就是当前方法的实例。即:this! 没得选!此时该方法变为一个同步方法
例:public synchronized int getBeans(){。。。}
(2)同步块可以更准确的锁定需要排队的代码片段 例:synchronized(){。。。}
01.同步块:
(1)优点:有效的缩小同步范围可以在保证并发安全的前提下尽可能的提高【并发效率】;
同步块可以更准确的控制需要多个线程排队执行的代码片段.
缺点:会【降低程序的执行效率】,但我们为了保证线程的安全,有些性能是必须要牺牲的
(2)语法:————————>同步执行:多个线程执行时有先后顺序
synchronized(同步监视器/对象上锁的对象){
//需要多个线程同步执行的代码片段(也就是可能出现问题的操作共享数据的多条语句)
}
(3)使用同步块效果的两个前提:
前提1:同步需要两个或者两个以上的线程(单线程无需考虑多线程安全问题)
前提2:多个线程间必须使用同一个锁(我上锁后其他人也能看到这个锁,不然我的锁锁不住其他人,就没有了上锁的效果)
(4)同步块synchronized特点:
①可以用来【修饰代码块,称为同步代码块】,使用的锁对象类型任意,但注意:必须唯一!
②可以用来【修饰方法,称为同步方法】
***③可以用来【修饰静态方法】,静态方法上使用同步块时,由于静态方法所属类,所以一定具有同步效果.
指定的锁对象为当前类的类对象(Class的实例).
③同步的缺点是会降低程序的执行效率,但我们为了保证线程的安全,有些性能是必须要牺牲的
④但是为了性能,加锁的范围需要控制好,比如我们不需要给整个商场加锁,试衣间加锁就可以了
02.(1)使用同步块注意的问题:——————>包含参数的"()"要指定同步监视器对象
①同步块在使用时需要在"()"中指定一个同步监视器对象,即:上锁的对象;
②该对象从语法的角度来讲可以是任意引用类型的实例,
③只要保证多个需要同步(排队)执行该代码块的线程看到的是同一个对象才可以!
(2)为什么同步块的锁对象可以是任意的同一个对象,但是同步方法使用的是this呢?
:因为同步块可以保证同一个时刻只有一个线程进入,
但同步方法不可以保证同一时刻只能有一个线程调用,所以使用本类代指对象this来确保同步。
(3)注意:!!同步块里若是new的一个对象,不对!无效!
例:synchronized (new Object())
练习题:
package apiday.thread.thread_synchronized;
/**
* 2、synchronized 的2种使用方式:
* (1)在方法上修饰时,同步监视器对象就是当前方法的实例。即:this! 没得选!此时该方法变为一个同步方法
* 例:public synchronized int getBeans(){。。。}
* (2)同步块可以更准确的锁定需要排队的代码片段 例:synchronized(){。。。}
*
* 01.同步块:
* (1)优点:有效的缩小同步范围可以在保证并发安全的前提下尽可能的提高【并发效率】;
* 同步块可以更准确的控制需要多个线程排队执行的代码片段.
* 缺点:会【降低程序的执行效率】,但我们为了保证线程的安全,有些性能是必须要牺牲的
*
* (2)语法:————————>同步执行:多个线程执行时有先后顺序
* synchronized(同步监视器/对象上锁的对象){
* //需要多个线程同步执行的代码片段(也就是可能出现问题的操作共享数据的多条语句)
* }
*
* (3)使用同步块效果的两个前提:
* 前提1:同步需要两个或者两个以上的线程(单线程无需考虑多线程安全问题)
* 前提2:多个线程间必须使用同一个锁(我上锁后其他人也能看到这个锁,不然我的锁锁不住其他人,就没有了上锁的效果)
*
* (4)同步块synchronized特点:
* ①可以用来【修饰代码块,称为同步代码块】,使用的锁对象类型任意,但注意:必须唯一!
* ②可以用来【修饰方法,称为同步方法】
* ***③可以用来【修饰静态方法】,静态方法上使用同步块时,由于静态方法所属类,所以一定具有同步效果.
* 指定的锁对象为当前类的类对象(Class的实例).
* ③同步的缺点是会降低程序的执行效率,但我们为了保证线程的安全,有些性能是必须要牺牲的
* ④但是为了性能,加锁的范围需要控制好,比如我们不需要给整个商场加锁,试衣间加锁就可以了
*
* 02.(1)使用同步块注意的问题:——————>包含参数的"()"要指定同步监视器对象
* ①同步块在使用时需要在"()"中指定一个同步监视器对象,即:上锁的对象;
* ②该对象从语法的角度来讲可以是任意引用类型的实例,
* ③只要保证多个需要同步(排队)执行该代码块的线程看到的是同一个对象才可以!
* (2)为什么同步块的锁对象可以是任意的同一个对象,但是同步方法使用的是this呢?
* :因为同步块可以保证同一个时刻只有一个线程进入,
* 但同步方法不可以保证同一时刻只能有一个线程调用,所以使用本类代指对象this来确保同步。
* (3)注意:!!同步块里若是new的一个对象,不对!无效!
* 例:synchronized (new Object())
*
*/
public class SyncDemo02 {
public static void main(String[] args) {
Shop shop = new Shop();
Thread t1 = new Thread(){
public void run(){
shop.buy();
}
};
Thread t2 = new Thread(){
public void run(){
shop.buy();
}
};
t1.start();
t2.start();
}
}
class Shop{
//在方法上使用synchronized时,同步监视器对象就是当前方法的所属对象,即:this
public synchronized void buy(){
// public void buy(){
try {
Thread t = Thread.currentThread();//获取运行buy()方法的线程
System.out.println(t.getName() + ":正在挑衣服...");
Thread.sleep(5000);
/*
同步块在使用时需要在"()"中指定一个同步监视器对象,即:上锁的对象;
该对象从语法的角度来讲可以是任意引用类型的实例,
只要保证多个需要同步(排队)执行该代码块的线程看到的是同一个对象才可以!
*/
synchronized (this) {
// synchronized (new Object()){//——————>无效!
System.out.println(t.getName() + ":正在试衣服...");
Thread.sleep(5000);
}
System.out.println(t.getName() + ":结账离开");
}catch(InterruptedException e){
}
}
}
04.synchronized:修饰静态方法 或 写在方法中
- 当在静态方法上使用synchronized后,该方法是一个同步方法.由于静态方法所属类,所以一定具有同步效果.
- 静态方法使用的同步监视器对象为当前类的类对象(Class的实例).
- 注:类对象会在后期反射知识点介绍.
03.同步块可以用来【修饰静态方法】:
(1)静态方法上如果使用synchronized,那么该方法一定是同步的。
由于静态方法所属类,所以一定具有同步效果。
(2)静态方法中指定的同步监视器对象(锁对象)为当前类的类对象。即:Class实例。
在JVM中,每个被加载的类都有且只有一个Class的实例与之对应。
练习题:
package apiday.thread.thread_synchronized;
/**
* 03.同步块可以用来【修饰静态方法】:
* (1)静态方法上如果使用synchronized,那么该方法一定是同步的。
* 由于静态方法所属类,所以一定具有同步效果。
*
* (2)静态方法中指定的同步监视器对象(锁对象)为当前类的类对象。即:Class实例。
* 在JVM中,每个被加载的类都有且只有一个Class的实例与之对应。
*/
public class SyncDemo3 {
public static void main(String[] args) {
Thread t1 = new Thread() {
public void run() {
Boo.dosome();
}
};
Thread t2 = new Thread() {
public void run() {
Boo.dosome();
}
};
t1.start();
t2.start();
}
}
class Boo {
//(1)静态方法上如果使用synchronized,那么该方法一定是同步的。由于静态方法所属类,所以一定具有同步效果。
// public synchronized static void dosome() {
//(2)在静态方法中使用同步块时,也可以指定类对象。方式为:类名.class:
public static void dosome() {
synchronized (Boo.class) {
try {
Thread t = Thread.currentThread();
System.out.println(t.getName() + ":正在执行dosome方法");
Thread.sleep(5000);
System.out.println(t.getName() + ":执行dosome方法完毕");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
6、互斥锁
-
(1)介绍:
synchronized修饰符实现的同步机制叫做互斥锁机制,它所获得的锁叫做互斥锁。
(每个对象都有一个monitor(锁标记),当线程拥有这个锁标记时才能访问这个资源,没有锁标记便进入锁池。任何一个对象系统都会为其创建一个互斥锁,这个锁是为了分配给线程的,防止打断原子操作。每个对象的锁只能分配给一个线程,因此叫做互斥锁。)
-
(2)
当多个线程执行不同的代码片段,但是这些代码片段之间不能同时运行时就要设置为互斥的。使用synchronized锁定多个代码片段,并且指定的同步监视器是同一个时,这些代码片段之间就是互斥的。
互斥锁: (1)当使用多个synchronized锁定多个代码片段,
(2)并且指定的锁对象都相同时,这些代码片段就是互斥的。
即:多个线程不能同时执行他们
概述:每个对象都有一个【锁标记】,当线程【拥有这个锁标记时】才能访问这个资源,
没有锁标记便进入锁池。【任何一个对象系统都会为其创建一个互斥锁】,这个锁是【为了分配给线程
以防止打断原子操作】。每个对象的锁只能分配给一个线程,因此叫做互斥锁。)
下面程序例子:(1)不加锁两个线程会同时执行!
(2)加了锁(前提是一个锁对象/同步监视器对象)则两个线程进行排队,执行完一个后再执行另一个!
总结:当启动线程后调用该线程相对应的方法时,给该方法打一个标记(即为上锁),此时需要排队执行。不会同时执行。
若有的方法没这个synchronized来上锁,则两个线程会同时执行,没有约束了,也就不存在互斥了。
练习题:
package apiday.thread.thread_synchronized.Mutex;
/**
* 互斥锁: (1)当使用多个synchronized锁定多个代码片段,
* (2)并且指定的锁对象都相同时,这些代码片段就是互斥的。
* 即:多个线程不能同时执行他们
* 概述:每个对象都有一个【锁标记】,当线程【拥有这个锁标记时】才能访问这个资源,
* 没有锁标记便进入锁池。【任何一个对象系统都会为其创建一个互斥锁】,这个锁是【为了分配给线程
* 以防止打断原子操作】。每个对象的锁只能分配给一个线程,因此叫做互斥锁。)
*
* 下面程序例子:(1)不加锁两个线程会同时执行!
* (2)加了锁(前提是一个锁对象/同步监视器对象)则两个线程进行排队,执行完一个后再执行另一个!
*
* 总结:当启动线程后调用该线程相对应的方法时,给该方法打一个标记(即为上锁),此时需要排队执行。不会同时执行。
* 若有的方法没这个synchronized来上锁,则两个线程会同时执行,没有约束了,也就不存在互斥了。
*/
public class SyncDemo4 {
public static void main(String[] args) {
Foo foo1 = new Foo();
Foo foo2 = new Foo();
Thread t1 = new Thread() {
public void run() {
foo1.methodA();
}
};
Thread t2 = new Thread() {
public void run() {
foo2.methodB();
}
};
t1.start();
t2.start();
}
}
class Foo {
/**
* 想要实现互斥锁的条件:
* (1)使用多个syncronized锁定多个代码片段
* (2)并且指定的锁对象都相同(此处默认都是this)
*/
public synchronized void methodA() {
try {
Thread t = Thread.currentThread();
System.out.println(t.getName() + ":正在执行A方法");
Thread.sleep(5000);
System.out.println(t.getName() + ":执行A方法完毕");
} catch (InterruptedException e) {
}
}
//(1)不加锁两个线程会同时执行!
// public void methodB(){
//(2)加了锁则两个线程进行排队,执行完一个后再执行另一个。——————>即为互斥!
// public synchronized void methodB(){
//(3)换为同步块后,锁对象为this和methodA()的this是同一个,所以仍具有互斥性
// public void methodB() {
// synchronized (this) {
//(4)在这里换为类对象后不具有互斥性!此处不合适
// 原因:若main中Foo类有两个对象,即使不用synchronized锁定代码片段,两个对象执行程序互不干扰,还是并发执行的
public void methodB(){
synchronized (Foo.class){
try {
Thread t = Thread.currentThread();
System.out.println(t.getName() + ":正在执行B方法");
Thread.sleep(5000);
System.out.println(t.getName() + ":执行B方法完毕");
} catch (InterruptedException e) {
}
}
}
}
7、死锁
- 死锁的产生:
- 两个线程各自持有一个锁对象的同时等待对方先释放锁对象,此时会出现僵持状态。这个现象就是死锁。
死锁:
以两个线程为例:
当两个线程各自持有一个上锁的对象的同时等待对方先释放锁时就会形成一种"僵持状态"
导致程序卡住且无法再继续后面的执行,这个现象称为"死锁"
01.死锁的写法:
02.解决死锁的写法:
(1)尽量避免在持有一个锁的同时去等待持有另一个锁(避免synchronized嵌套)
(2)当无法避免synchronized嵌套时,就必须保证多个线程锁对象的持有顺序必须一致。
即:A线程在持有锁1的过程中去持有锁2时,B线程也要以这样的持有顺序进行。
练习题:
package apiday.thread.thread_synchronized.deadlock;
/**
* 死锁:
* 以两个线程为例:
* 当两个线程各自持有一个上锁的对象的同时等待对方先释放锁时就会形成一种"僵持状态"
* 导致程序卡住且无法再继续后面的执行,这个现象称为"死锁"
*
* 01.死锁的写法:
*
* 02.解决死锁的写法:
* (1)尽量避免在持有一个锁的同时去等待持有另一个锁(避免synchronized嵌套)
* (2)当无法避免synchronized嵌套时,就必须保证多个线程锁对象的持有顺序必须一致。
* 即:A线程在持有锁1的过程中去持有锁2时,B线程也要以这样的持有顺序进行。
*
*/
public class DeadLock {
//筷子:
private static Object chopsticks = new Object();
//勺:
private static Object spoon = new Object();
public static void main(String[] args) {
/** 01.死锁的写法: */
// //北方人:
// Thread np = new Thread(){
// public void run(){
// try {
// System.out.println("北方人:开始吃饭");
// System.out.println("北方人去拿筷子...");
// synchronized (chopsticks) {
// System.out.println("北方人拿起了筷子,开始吃饭...");
// Thread.sleep(5000);
// System.out.println("北方人吃完了饭,去拿勺...");
// synchronized (spoon){
// System.out.println("北方人拿起了勺子,开始喝汤...");
// Thread.sleep(5000);
// }
// System.out.println("北方人喝完了汤,北方人放下了勺子");
// }
// System.out.println("北方人放下了筷子,吃饭完毕。");
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// }
// };
// //南方人:
// Thread sp = new Thread(){
// public void run(){
// try {
// System.out.println("南方人:开始吃饭");
// System.out.println("南方人去拿勺...");
// synchronized (spoon) {
// System.out.println("南方人拿起了勺,开始喝汤...");
// Thread.sleep(5000);
// System.out.println("南方人喝完了汤,去拿筷子...");
// synchronized (chopsticks){
// System.out.println("南方人拿起了筷子,开始吃饭...");
// Thread.sleep(5000);
// }
// System.out.println("南方人吃完了饭,南方人放下了筷子");
// }
// System.out.println("南方人放下了勺子,吃饭完毕。");
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// }
// };
// np.start();
// sp.start();
/** 02.没有死锁的写法: */
//北方人
Thread np = new Thread(){
public void run(){
try {
System.out.println("北方人:开始吃饭");
System.out.println("北方人去拿筷子...");
synchronized (chopsticks) {
System.out.println("北方人拿起了筷子,开始吃饭...");
Thread.sleep(5000);
}
System.out.println("北方人吃完了饭,放下了筷子");
System.out.println("北方人去拿勺子...");
synchronized (spoon){
System.out.println("北方人拿起了勺子,开始喝汤...");
Thread.sleep(5000);
}
System.out.println("北方人喝完了汤,北方人放下了勺子");
System.out.println("吃饭完毕。");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
//南方人
Thread sp = new Thread(){
public void run(){
try {
System.out.println("南方人:开始吃饭");
System.out.println("南方人去拿勺...");
synchronized (spoon) {
System.out.println("南方人拿起了勺,开始喝汤...");
Thread.sleep(5000);
}
System.out.println("南方人喝完了汤,放下勺子...");
System.out.println("南方人去拿筷子...");
synchronized (chopsticks){
System.out.println("南方人拿起了筷子,开始吃饭...");
Thread.sleep(5000);
}
System.out.println("南方人吃完了饭,南方人放下了筷子");
System.out.println("吃饭完毕。");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
np.start();
sp.start();
}
}
8、线程池
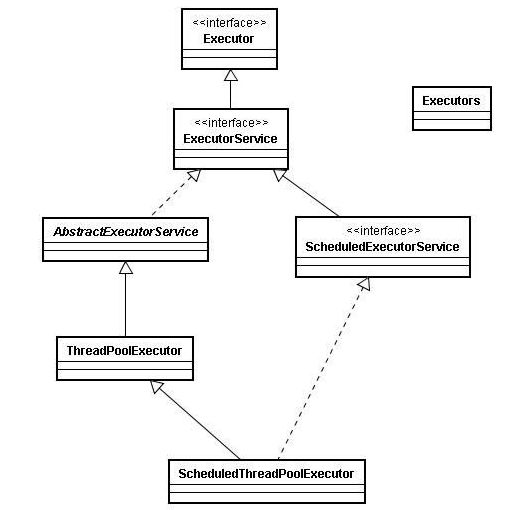
线程池:是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
(1)线程池线程都是后台线程。
(2)每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。
(3)如果某个线程在托管代码中空闲(如正在等待某个事件),则线程池将插入另一个辅助线程来使所有处理器保持繁忙。
(4)如果所有线程池线程都始终保持繁忙,但队列中包含挂起的工作,则线程池将在一段时间后创建另一个辅助线程但线程
的数目永远不会超过最大值。超过最大值的线程可以排队,但他们要等到其他线程完成后才启动。
1、Executor:线程池顶级接口,只有一个方法
2、ExecutorService:真正的线程池接口
(1) void execute(Runnable command) :执行任务/命令,没有返回值,一般用来执行Runnable
(2) <T> Future<T> submit(Callable<T> task):执行任务,有返回值,一般又来执行Callable
(3) void shutdown() :关闭线程池
3、AbstractExecutorService:基本实现了ExecutorService的所有方法
4、ThreadPoolExecutor:默认的线程池实现类
5、ScheduledThreadPoolExecutor:实现周期性任务调度的线程池
6、Executors:工具类、线程池的工厂类,用于创建并返回不同类型的线程池
(1) Executors.newCachedThreadPool():创建一个可根据需要创建新线程的线程池
(2) Executors.newFixedThreadPool(n); 创建一个可重用固定线程数的线程池
(3) Executors.newSingleThreadExecutor() :创建一个只有一个线程的线程池
(4) Executors.newScheduledThreadPool(n):创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
7、线程池ThreadPoolExecutor参数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {...}
(1)corePoolSize:核心池的大小
:默认情况下,创建了线程池后,线程数为0,当有任务来之后,就会创建一个线程去执行任务。
但是当线程池中线程数量达到corePoolSize,就会把到达的任务放到队列中等待。
(2)maximumPoolSize:最大线程数。
:corePoolSize和maximumPoolSize之间的线程数会自动释放,
小于等于corePoolSize的不会释放。
当大于了这个值就会将任务由一个丢弃处理机制来处理。
(3)keepAliveTime:线程没有任务时最多保持多长时间后会终止
:默认只限于corePoolSize和maximumPoolSize间的线程
(4)TimeUnit:keepAliveTime的时间单位
(5)BlockingQueue:存储等待执行的任务的阻塞队列,有多种选择,可以是顺序队列、链式队列等。
(6)ThreadFactory:线程工厂,默认是DefaultThreadFactory,Executors的静态内部类
(7)RejectedExecutionHandler:拒绝处理任务时的策略。
:如果线程池的线程已经饱和,并且任务队列也已满,对新的任务应该采取什么策略。
比如抛出异常、直接舍弃、丢弃队列中最旧任务等,默认是直接抛出异常。
1)CallerRunsPolicy:如果发现线程池还在运行,就直接运行这个线程
2)DiscardOldestPolicy:在线程池的等待队列中,将头取出一个抛弃,然后将当前线程放进去。
3)DiscardPolicy:什么也不做
4)AbortPolicy:java默认,抛出一个异常:
线程池(ThreadPool):————>是线程的管理机制,它主要解决两方面问题:1:复用线程 2:控制线程数量
(1)java的并发(concurrent)包:
①java.util.concurrent(简称JUC)
②里面都是与多线程相关的API。线程池就在这个包里。
1、线程 相关定义名词:
01.Executor:线程池顶级接口,只有一个方法:
(1)void execute(Runnable command)————>执行任务/命令,没有返回值,一般用来执行Runnable
:在将来的某个时间执行给定的命令。
根据 Executor 实现的判断,该命令可以在新线程、池线程或调用线程中执行。
注:command:命令
02.Executors:工具类、创建线程池的工厂类,用于创建并返回不同类型的线程池对象
03.ExecutorService:真正的线程池接口
2、线程池 API:
(1)newFixedThreadPool(int nThreads):创建一个线程池;参数是n条线程的意思。
(2)String getName():返回此线程的名称
(3)execute(Runnable command):在将来的某个时间执行给定的命令。
根据 Executor 实现的判断,该命令可以在新线程、池线程或调用线程中执行。
注:command:命令
(4)关闭线程的两个API:
①shutdown():该方法调用后,线程不再接收新任务,如果此时还调用execute()则会抛出异常,
并且线程池会继续将已经存在的任务全部执行完毕后才会关闭。
②shutdownNow():强制中断所有线程,来停止线程池
package apiday.thread.thread_pool;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 线程池(ThreadPool):————>是线程的管理机制,它主要解决两方面问题:1:复用线程 2:控制线程数量
* (1)java的并发(concurrent)包:
* ①java.util.concurrent(简称JUC)
* ②里面都是与多线程相关的API。线程池就在这个包里。
*
* 1、线程 相关定义名词:
* 01.Executor:线程池顶级接口,只有一个方法:
* (1)void execute(Runnable command)————>执行任务/命令,没有返回值,一般用来执行Runnable
* :在将来的某个时间执行给定的命令。
* 根据 Executor 实现的判断,该命令可以在新线程、池线程或调用线程中执行。
* 注:command:命令
*
* 02.Executors:工具类、创建线程池的工厂类,用于创建并返回不同类型的线程池对象
*
* 03.ExecutorService:真正的线程池接口
*
* 02.线程池 API:
* (1)newFixedThreadPool(int nThreads):创建一个线程池;参数是n条线程的意思。
* (2)String getName():返回此线程的名称
* (3)execute(Runnable command):在将来的某个时间执行给定的命令。
* 根据 Executor 实现的判断,该命令可以在新线程、池线程或调用线程中执行。
* 注:command:命令
* (4)关闭线程的两个API:
* ①shutdown():该方法调用后,线程不再接收新任务,如果此时还调用execute()则会抛出异常,
* 并且线程池会继续将已经存在的任务全部执行完毕后才会关闭。
* ②shutdownNow():强制中断所有线程,来停止线程池
*
*/
public class ThreadPoolDemo {
public static void main(String[] args) {
//创建一个固定大小的线程池,容量为2:
ExecutorService threadPool = Executors.newFixedThreadPool(2);
for(int i=0;i<5;i++){
//创建并指派任务:实现Runnable接口并重写run()方法
Runnable runnable = new Runnable() {
@Override
public void run() {
Thread t = new Thread();
System.out.println(t.getName()+":正在执行一个任务...");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
System.out.println(t.getName()+":执行完一个任务完毕了");
}
};
//指派任务:调用线程池方法pool.execute()
threadPool.execute(runnable);
System.out.println("交给线程池一个任务...");
}
/** 关闭线程的两个操作之:①shutdownNow() */
// threadPool.shutdownNow();
/*
控制台输出:
交给线程池一个任务...
交给线程池一个任务...
交给线程池一个任务...
交给线程池一个任务...
交给线程池一个任务...
线程池关闭了
Thread-0:正在执行一个任务...
Thread-1:正在执行一个任务...
Thread-1:执行完一个任务完毕了
Thread-0:执行完一个任务完毕了
*/
/** 关闭线程的两个操作之:②shutdown() */
threadPool.shutdown();
/*
控制台输出:
交给线程池一个任务...
交给线程池一个任务...
交给线程池一个任务...
交给线程池一个任务...
交给线程池一个任务...
线程池关闭了
Thread-0:正在执行一个任务...
Thread-1:正在执行一个任务...
Thread-1:执行完一个任务完毕了
Thread-0:执行完一个任务完毕了
Thread-2:正在执行一个任务...
Thread-3:正在执行一个任务...
Thread-2:执行完一个任务完毕了
Thread-3:执行完一个任务完毕了
Thread-4:正在执行一个任务...
Thread-4:执行完一个任务完毕了
*/
System.out.println("线程池关闭了");
}
}
三、 集合
1、集合基本概念
01.集合前言
Java语言的java.util包中提供了一些集合类,这些集合类又称之为容器。
提到容器不难想到数组,集合类与数组最主要的不同之处是:
- 数组的长度是固定的;集合的长度是可变的,
- 而数组的访问方式比较单一,插入/删除等操作比较繁琐;而集合的访问方式比较灵活
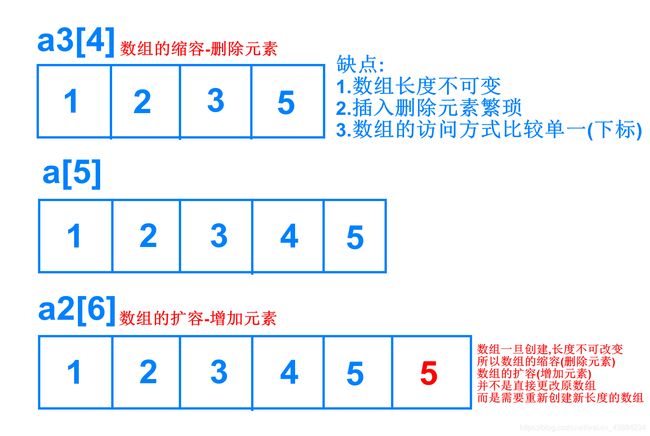
其中List集合与Set集合继承了Collection接口,各个接口还提供了不同的实现类.
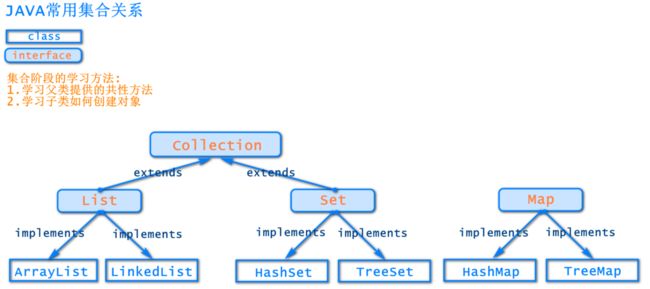
02.集合概念
集合与数组一样,可以保存一组元素,并且提供了操作元素的相关方法,使用更方便.
1.集合的英文名称是Collection,是用来存放对象的数据结构,而且长度可变,可以存放不同类型的对象。
2.并且还提供了一组操作成批对象的方法.Collection接口层次结构 中的根接口,接口不能直接使
用,但是该接口提供了添加元素/删除元素/管理元素的父接口公共方法.。
*3.由于List接口与Set接口都继承了Collection接口,因此这些方法对于List集合和Set集合是通用的.
03.集合的继承结构
Java 集合框架主要包括两种类型的容器:
Collection—————————> 和 <———————————Map
存储一个元素集合 Map:存储键/值对映射。
1、Collection 接口又有 3 种子接口:
(1)List接口——————————>数据有下标,有序,可重复
①ArrayList子类
②LinkedList子类
(2)Set接口——————————>数据无下标,无序,不可重复
①HashSet子类
(3)Queue接口(队列)————>不常见接口
2、Map接口-----键值对的方式存数据
(1)HashMap接口
04.集合学习的方法:——>***!!!
学习父级的公共方法,学习子类的创建方式,学习各种集合的特点:
//1. 关于List大多都是与下标有关的操作
//2. 关于Set通常都是去重的操作
//3. 关于map通常都是映射关系,也就是键值对
//4. API要常练习,方法互相之间没有任何关系,用哪个,查哪个
2、Collection接口:List和Set
由于List接口与Set接口都继承了Collection接口,因此这些方法对于List集合和Set集合是通用的
00.Collection<—和—>Collections关系:
Collection:
(1)Collection是:
①java.util下所有集合的顶级接口;
②下面有多种实现类,里面规定了所有集合都应当具备的相关操作。
(2)Collection提供了:
①有一个不常见接口:【Queue(队列)】
*②和其他有两个常见的子接口:————>提供了不同的实现类.
【java.util.List:可重复集且有序】和【java.util.Set:不可重复集】
注1:重复:————————>指的是元素是否允许存放重复元素 ;
重复的判定:———>是根据元素自身的equals方法决定的。
注2:这里可重复指的是集合中的元素是否可以重复,而判定重复元素的标准是依靠元素自身
equals比较的结果.为true就认为是重复元素.
*③由于List接口与Set接口都继承了Collection接口,因此这些方法对于List集合和Set集合是通用的.
(3)Collection的意义:————>在于为各种具体的集合提供最大化的统一操作方式。
————————————————————————————————————————————————————————————————
————————————————————————————————————————————————————————————————
Collections:
(1)Collections是:——————> 一个包装类
(2)Collections提供了:———>有关于集合操作的一系列静态方法,实现对各类集合的搜索/排序/线程安全化等操作。
01.Collection API-----单个集合操作:10几种方法:
①单个集合的操作:
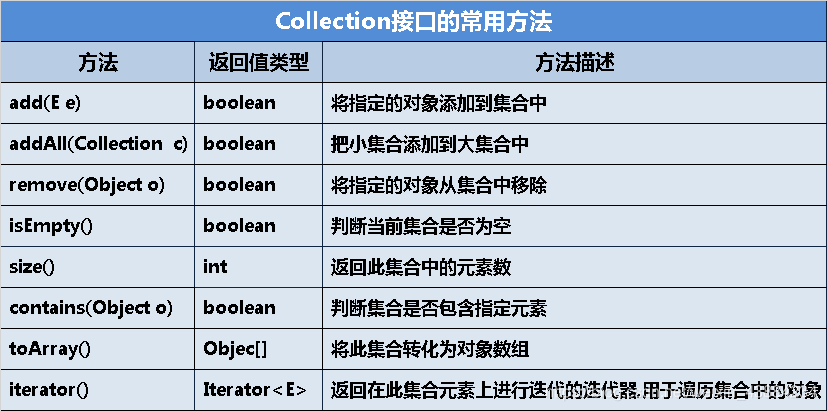
(1)boolean add(E e):向当前集合中添加一个元素,当元素成功添加则返回true,否则返回false
注:E: 泛型数据类型,用于设置objectName的数据类型,只能为引用数据类型。
(2)int size():返回当前集合的元素个数
(3)boolean isEmpty():判断当前集合是否为一个空集
(4)void clear():清空集合
(5)①hashCode():返回此集合的哈希码值。
虽然Collection接口没有对Object.hashCode方法的通用约定添加任何规定,但程序员应注意,
任何重写Object.equals方法的类也必须重写Object.hashCode方法以满足Object的通用约定.hashCode方法。
特别是:c1.equals(c2)意味着c1.hashCode()==c2.hashCode()。
②equals():比较指定对象与此集合是否相等
当一个集合与任何列表或集合进行比较时,若没有实现自定义 equals()时方法必须返回 false。
(6)重写了toString()方法后的格式为:[元素1.toString(),元素2.toString(),....]
若自己定义的类没有重写:使用的是Object的默认实现,打印的是对象的地址值(对象所属类的完全限定名@对象的哈希码的16进制表示);
1)为什么直接输出的是集合而不是地址?因为Collection重写toString()了吗?
:因为Collection是一个接口(里边没有重写任何方法);其实是ArrayList集合里重写的
toString(),所以输出的不是地址,是集合
(7)集合的某些操作会受元素equals方法影响。比如contains()和remove():
①boolean contains(Object o):判断当前集合是否包含给定元素。判断依据是:
该元素是否与集合现有元素存在equals()方法比较为true的情况,存在则认为包含。
②boolean remove(Object o):删除元素也是删除与给定元素equals比较为true的元素对于List而言,重复元素只会删除一次。
注意:自己定义的类要重写的equals()方法后,下面才会输出集合;否则是:对象所属类的完全限定名@对象的哈希码的16进制表示。
(8)boolean equals(Object o) 比较集合对象与参数对象o是否相等
(9)int hashCode() 返回本集合的哈希码值
(10)Object[] toArray() 将本集合转为数组
练习题:
用Point类进行测试:
再用CollectionDemo1类进行方法验证:
package apiday.gather.collection.list.arrayList.api;
/** 用Point类测试: */
import java.util.Objects;
/**
* Point:点
* 使用当前类作为集合元素,测试集合相关操作
*/
public class Point {
private int x;
private int y;
public Point(){}
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
public int getY() {
return y;
}
public void setY(int y) {
this.y = y;
}
@Override
public String toString() {
return "point{" +
"x=" + x +
", y=" + y +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Point point = (Point) o;
return x == point.x && y == point.y;
}
}
package apiday.gather.collection.list.arrayList.api;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
/**
*
* 01.collection API:
* (1)boolean add(E e):向当前集合中添加一个元素,当元素成功添加则返回true,否则返回false
* 注:E: 泛型数据类型,用于设置objectName的数据类型,只能为引用数据类型。
* (2)int size():返回当前集合的元素个数
* (3)boolean isEmpty():判断当前集合是否为一个空集
* (4)void clear():清空集合
* (5)①hashCode():返回此集合的哈希码值。
* 虽然Collection接口没有对Object.hashCode方法的通用约定添加任何规定,但程序员应注意,
* 任何重写Object.equals方法的类也必须重写Object.hashCode方法以满足Object的通用约定.hashCode
* 特别是:c1.equals(c2)意味着c1.hashCode()==c2.hashCode()。
* ②equals():比较指定对象与此集合是否相等
* 当一个集合与任何列表或集合进行比较时,若没有实现自定义 equals()时方法必须返回 false。
* (6)重写了toString()方法后的格式为:[元素1.toString(),元素2.toString(),....]
* 若自己定义的类没有重写:使用的是Object的默认实现,打印的是对象的地址值(对象所属类的完全限定名@对象的哈希码的16进制表示);
* (7)集合的某些操作会受元素equals方法影响。比如contains()和remove():
* ①boolean contains(Object o):判断当前集合是否包含给定元素。判断依据是:
* 该元素是否与集合现有元素存在equals()方法比较为true的情况,存在则认为包含。
* ②boolean remove(Object o):删除元素也是删除与给定元素equals比较为true的元素对于List而言,重复元素只
* 注意:自己定义的类要重写的equals()方法后,下面才会输出集合;否则是:对象所属类的完全限定名@对象的哈希码的16进制表示。
*/
public class CollectionDemo1 {
public static void main(String[] args) {
//集合只能存放引用类型
Collection c = new ArrayList();
/*
(1)添加元素
ArrayList类提供了很多有用的方法,添加元素到 ArrayList 可以使用add() 方法:
boolean add(E e) E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型。
向当前集合中添加一个元素,当元素成功添加则返回true,否则返回false
*/
c.add(new Point(1, 2));
c.add(new Point(3, 4));
c.add(new Point(5, 6));
c.add(new Point(7,8 ));
c.add(new Point(9,10 ));
System.out.println(c);//[one, two, three, four, five]
//(2)int size():返回当前集合的元素个数
int size = c.size();
System.out.println("当前集合元素个数是:"+size);//当前集合元素个数是:5
//(3)boolean isEmpty():判断当前集合是否为一个空集
boolean isEmpty = c.isEmpty();
System.out.println("当前集合是否为一个空集:"+isEmpty);//当前集合是否为一个空集:false
//(4)void clear():清空集合
c.clear();
//注意要重新调用集合的方法:
System.out.println(c);//[]
System.out.println("当前集合元素个数是:"+c.size());//当前集合元素个数是:0
System.out.println("当前集合是否为一个空集:"+c.isEmpty());//当前集合是否为一个空集:true
/** 以下代码————>重新添加元素后测试集合相关方法:*/
c.add(new Point(1, 2));
c.add(new Point(3, 4));
c.add(new Point(5, 6));
c.add(new Point(7,8 ));
c.add(new Point(9,10 ));
//刚才元素[1,2]已经被(3)删除了,所以再写一个用于(7)的验证操作
c.add(new Point(1,2 ));
/*
(5)①hashCode():返回此集合的哈希码值。
虽然Collection接口没有对Object.hashCode方法的通用约定添加任何规定,
但程序员应注意,任何重写Object.equals方法的类也必须重写Object.hashCode
方法以满足 Object 的通用约定.hashCode方法。
特别是:c1.equals(c2) 意味着 c1.hashCode()==c2.hashCode()。
*/
Collection c2 = new ArrayList();
c2.add(new Point(9,10));
System.out.println(c.hashCode()==c2.hashCode());//false
/*
(5)②equals():比较指定对象与此集合是否相等
当一个集合与任何列表或集合进行比较时,若没有实现自定义 equals()时方法必须返回 false。
*/
System.out.println(c.equals(c2));//false
/*
(6)
集合重写了toString()方法后的格式为:[元素1.toString(),元素2.toString(),....]
如果没有重写这个方法,使用的是Object的默认实现,打印的是对象的地址值(对象所属类的完全限定名@对象的哈希码的16进制表示);
如果重写以后,以重写的逻辑为准,比如String打印的是串的具体内容,比如ArrayList,打印的是[集合元素]
*/
//:[Point{x=1, y=2}, Point{x=3, y=4}, Point{x=5, y=6}, Point{x=7, y=8}, Point{x=9, y=10}, Point{x=1, y=2}]
System.out.println(c);
Point p = new Point(1, 2);
System.out.println(p);//Point{x=1, y=2}
/*
(7)①
boolean contains(Object o):判断当前集合是否包含给定元素。
判断依据是:
该元素是否与集合现有元素存在equals()方法比较为true的情况,存在则认为包含。
*/
boolean contains = c.contains(p);
System.out.println("包含:"+contains);//包含:true
/*
(7)②
remove():删除元素也是删除与给定元素equals比较为true的元素对于List而言,重复元素只会删除一次。
注意:自己定义的类要重写的equals()方法后,下面才会输出集合;否则是:对象所属类的完全限定名@对象的哈希码的16进制表示。
*/
//[point{x=1, y=2}, point{x=3, y=4}, point{x=5, y=6}, point{x=7, y=8}, point{x=9, y=10}, point{x=1, y=2}]
System.out.println("此时集合为:"+c);
c.remove(p);
System.out.println(c);//[point{x=3, y=4}, point{x=5, y=6}, point{x=7, y=8}, point{x=9, y=10}, point{x=1, y=2}]
}
}
02.Collection API-----集合间的操作:4几种方法:
(1)boolean addAll(Collection c):
将给定集合c中所有元素添加到当前集合中。添加后当前集合发生了改变则返回true
(2)boolean containsAll(Collection c):判断当前集合c1是否包含给定集合c3中的所有元素
(3)c2.retainAll(c3):取交集(仅保留当前集合中与给定集合的共有元素)
(4)c2.remove(c3):删除交集{将c2中与c3的共有元素删除(c3不受影响)}
练习题:
package apiday.gather.collection.list.arrayList;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
/**
* 集合间的操作:
* (1)boolean addAll(Collection c):
* 将给定集合c中所有元素添加到当前集合中。添加后当前集合发生了改变则返回true
* (2)boolean containsAll(Collection c):判断当前集合c1是否包含给定集合c3中的所有元素
* (3)c2.retainAll(c3):取交集(仅保留当前集合中与给定集合的共有元素)
* (4)c2.remove(c3):删除交集{将c2中与c3的共有元素删除(c3不受影响)}
*/
public class CollectionDemo3 {
public static void main(String[] args) {
Collection c1 = new ArrayList();
c1.add("java");
c1.add("c++");
c1.add(".net");
System.out.println("c1:"+c1);//c1:[java, c++, .net]
Collection c2 = new HashSet();
c1.add("android");
c1.add("ios");
System.out.println("c2:"+c2);//c2:[]
/*
(1)
boolean addAll(Collection c):
将给定集合c中所有元素添加到当前集合中。添加后当前集合发生了改变则返回true
*/
c2.addAll(c1);
System.out.println("c1:"+c1);//c1:[java, c++, .net, android, ios]
System.out.println("c2:"+c2);//c2:[c++, java, android, .net, ios]
Collection c3 = new ArrayList();
c3.add("java");
c3.add("ios");
c3.add("php");//因为c2中没有“php”,即没有包含所有元素,返回false
/*
(2)
boolean containsAll(Collection c):
判断当前集合是否包含给定集合中的[所有]元素,全部包含则返回[true]
*/
boolean contains = c2.containsAll(c3);
System.out.println("包含所有:"+contains);//包含所有:false
System.out.println("c2:"+c2);//c2:[c++, java, android, .net, ios]
System.out.println("c3:"+c3);//c3:[java, ios, php]
/*
(3)
c2.retainAll(c3):
取交集(仅保留当前集合中与给定集合的共有元素)
*/
c2.retainAll(c3);
System.out.println("c2:"+c2);//c2:[java, ios]
/*
(4)
c2.remove(c3):
删除交集{将c2中与c3的共有元素删除(c3不受影响)}
*/
c2.removeAll(c3);
System.out.println("c2:"+c2);//c2:[]
System.out.println("c3:"+c3);//c3:[java, ios, php]
}
}
03.Collection API------集合与数组转换(toArray)
(1)集合转换为数组:Collection提供了一个方法:toArray()
集合都可以转换为数组:
toArray():Collection定义了方法toArray可以将一个集合转换为一个数组
①toArray方法传入的数组长度实际没有长度要求,就功能而言如果给定的数组长度>=集合的size时,
就是用该数组(将集合元素存入到数组中)然后将其返回。
如果指定的数组长度不足时会根据该数组类型自行创建一个与集合size一致的数组并返回。
②如果此集合适合指定的数组并有剩余空间(即,数组的元素比此集合多),
则分配一个新数组:数组中紧跟集合末尾的元素设置为null。
补充:为什么直接输出的是集合而不是地址?因为Collection重写toString()了吗?
:因为Collection是一个接口(里边没有重写任何方法);其实是ArrayList集合里重写的
toString(),所以输出的不是地址,是集合
例:System.out.println(c);//[one, two, three, four, five]
package apiday.gather.collection;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
/**
* 集合都可以转换为数组
* toArray():Collection定义了方法toArray可以将一个集合转换为一个数组
* ①toArray方法传入的数组长度实际没有长度要求,就功能而言如果给定的数组长度>=集合的size时,
* 就是用该数组(将集合元素存入到数组中)然后将其返回。
* 如果指定的数组长度不足时会根据该数组类型自行创建一个与集合size一致的数组并返回。
* ②如果此集合适合指定的数组并有剩余空间(即,数组的元素比此集合多),
* 则分配一个新数组:数组中紧跟集合末尾的元素设置为null。
*/
public class CollectionToArray {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("one");
c.add("two");
c.add("three");
c.add("four");
c.add("five");
//为什么直接输出的是集合而不是地址?因为Collection重写toString()了吗?
//因为Collection是一个接口(里边没有重写任何方法);其实是ArrayList集合里重写的toString(),所以输出的不是地址,是集合
System.out.println(c);//[one, two, three, four, five]
// Object[] array = c.toArray();//不常用了
/* 将集合c中的所有元素放到String类型的数组array中:*/
/*
toArray方法传入的数组长度实际没有长度要求,就功能而言如果给定的数组长度>=集合的size时,
就是用该数组(将集合元素存入到数组中)然后将其返回。
如果指定的数组长度不足时会根据该数组类型自行创建一个与集合size一致的数组并返回。
*/
String[] array = c.toArray(new String[c.size()]);
System.out.println(Arrays.toString(array));//[one, two, three, four, five]
String[] array1 = c.toArray(new String[0]);
System.out.println(Arrays.toString(array1));//[one, two, three, four, five]
/*
toArray():返回一个包含此集合中所有元素的数组;
如果指定的数组长度不足时会根据该数组类型自行创建一个与集合size一致的数组并返回。
;否则,将使用指定数组的运行时类型和此集合的大小分配一个新数组:
如果此集合适合指定的数组并有剩余空间(即,数组的元素比此集合多),则数组中紧跟集合末尾的元素设置为null。
*/
String[] array2 = c.toArray(new String[10]);
System.out.println(Arrays.toString(array2));//[one, two, three, four, five, null, null, null, null, null]
}
}
04.Collection遍历------Iterator接口迭代器
(1)集合的迭代:
(0)Iterator iterator():———>获取一个用于遍历当前集合的迭代器实现类
(1)boolean hasNext():——————>使用迭代器询问是否还有下一个元素可以迭代。
注:迭代器默认开始的位置是集合第一个元素之前,因此第一次调用hasNext()就是判断集合是否有第一个元素。
(2)E next():——————————————>使迭代器向后移动并获取下一个元素
(3)/①使用迭代器遍历集合元素的过程中不要通过集合的add,remove这样的操作增删元素,
否则迭代器会抛出【并发修改异常】:java.util.ConcurrentModificationException
/②但是可以使用迭代器的remove()方法:————>删除迭代器当前位置的集合元素——>使用迭代器删除元素时,会把集合里的元素遍历一遍把想要删除的元素提取出来再删除。
集合的遍历:迭代器模式
01.迭代的由来?————>java中提供了很多个集合,它们在存储元素时,采用的存储方式不同。
我们要取出这些集合中的元素,可通过一种通用的获取方式来完成:
《Collection集合元素的通用获取方式》:
在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,
继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。
——————>这种(取出方式)`专业术语称为(迭代)。`
02.集合提供了统一的遍历方式:迭代器模式
(1)对应方法:Iterator iterator()————>该方法可以获取一个用于遍历当前集合的迭代器实现类
(2)Collection接口描述了一个抽象方法iterator方法,所有Collection子类都实现了这个方法,并且有自己的迭代形式。
(3)java.util.Iterator迭代器接口:
1)定义了迭代器遍历集合的相关操作.
2)不同的集合都实现了一个用于遍历自身元素的迭代器实现类,我们无需记住它们的名字,用多态的角度把他们看做为Iterator即可.
*3)迭代器遍历集合遵循的步骤:问->取->删。————>其中删除元素不是必要操作
(4)迭代器也支持泛型,指定时要与其遍历的集合指定的泛型一致
03.迭代器相关API;
(0)Iterator iterator():———>获取一个用于遍历当前集合的迭代器实现类
(1)boolean hasNext():——————>使用迭代器询问是否还有下一个元素可以迭代。
注:迭代器默认开始的位置是集合第一个元素之前,因此第一次调用hasNext()就是判断集合是否有第一个元素。
(2)E next():——————————————>使迭代器向后移动并获取下一个元素
(3)/①使用迭代器遍历集合元素的过程中不要通过集合的add,remove这样的操作增删元素,
否则迭代器会抛出【并发修改异常】:java.util.ConcurrentModificationException
/②但是可以使用迭代器的remove()方法:————>删除迭代器当前位置的集合元素——>使用迭代器删除元素时,会把集合里的元素遍历一遍把想要删除的元素提取出来再删除。
图解:
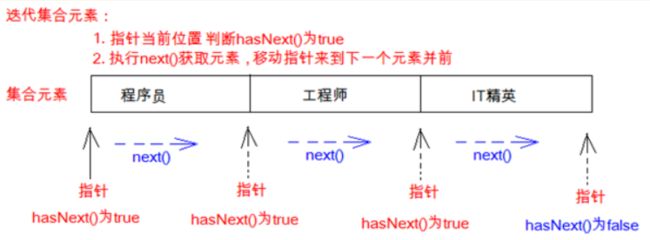
package apiday.gather.collection.list.arrayList;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* 集合的遍历:迭代器模式
* 01.迭代的由来?————>java中提供了很多个集合,它们在存储元素时,采用的存储方式不同。
* 我们要取出这些集合中的元素,可通过一种通用的获取方式来完成:
* 《Collection集合元素的通用获取方式》:
* 在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,
* 继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。
* ——————>这种(取出方式)`专业术语称为(迭代)。`
*
* 02.集合提供了统一的遍历方式:迭代器模式
* (1)对应方法:Iterator iterator()————>该方法可以获取一个用于遍历当前集合的迭代器实现类
* (2)Collection接口描述了一个抽象方法iterator方法,所有Collection子类都实现了这个方法,并且有自己的迭代形式。
* (3)java.util.Iterator迭代器接口:
* 1)定义了迭代器遍历集合的相关操作.
* 2)不同的集合都实现了一个用于遍历自身元素的迭代器实现类,我们无需记住它们的名字,用多态的角度把他们看做为Iterator即可.
* *3)迭代器遍历集合遵循的步骤:问->取->删。————>其中删除元素不是必要操作
* (4)迭代器也支持泛型,指定时要与其遍历的集合指定的泛型一致
*
* 03.迭代器相关API;
* (0)Iterator iterator():———>获取一个用于遍历当前集合的迭代器实现类
* (1)boolean hasNext():——————>使用迭代器询问是否还有下一个元素可以迭代。
* 注:迭代器默认开始的位置是集合第一个元素之前,因此第一次调用hasNext()就是判断集合是否有第一个元素。
* (2)E next():——————————————>使迭代器向后移动并获取下一个元素
* (3)使用迭代器遍历集合元素的过程中不要通过集合的add,remove这样的操作增删元素,
* 否则迭代器会抛出【并发修改异常】:java.util.ConcurrentModificationException
* (4)但是可以使用迭代器的remove()方法:————>删除迭代器当前位置的集合元素
*
*/
public class IteratorDemo {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add("one");
c.add("#");
c.add("two");
c.add("#");
c.add("three");
c.add("#");
c.add("four");
c.add("#");
c.add("five");
System.out.println(c);//[one, two, three, four, five]
/*
(0)
Iterator iterator():获取一个用于遍历当前集合的迭代器实现类
*/
Iterator it = c.iterator();
/*
(1)
boolean hasNext():
使用迭代器询问是否还有下一个元素可以迭代。
迭代器默认开始的位置是集合第一个元素之前,因此第一次调用hasNext()就是判断集合是否有第一个元素。
(2)
E next():
使迭代器向后移动并获取下一个元素
*/
while(it.hasNext()){ //———————————————————>问:是否还有下一个元素可以迭代
//注:当Iterator后没有用控制元素类型,就需要强转。
String e = (String) it.next(); //—————>取:使迭代器向后移动并获取下一个元素
System.out.println(e);
if("#".equals(e)){
/*
(3)
使用迭代器遍历集合元素的过程中不要通过集合的add,remove
这样的操作增删元素,否则迭代器会抛出【并发修改异常】:
java.util.ConcurrentModificationException
*/
// c.remove(e);
/*
(4)
迭代器提供了一个remove()方法:删除迭代器当前位置的集合元素
*/
it.remove();//————————————————————>删:
}
}
System.out.println(c);//[one, two, three, four, five]
}
}
(1)练习:Collection接口测试
创建包: cn.tedu.collection
创建类: TestCollection.java
package cn.tedu.collection;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.Iterator;
/**本类用于测试Collection接口*/
public class TestCollection {
public static void main(String[] args) {
//1.创建Collection相关的对象
//Collection c = new Collection();//报错,因为Collection是接口
//是泛型,用来约束集合中的数据类型,不能是基本类型,必须是引用类型
Collection<Integer> c = new ArrayList<>();
//2.1测试集合中的常用方法--单个集合间的操作
c.add(100);//向集合中添加元素 Ctrl+D快速向下复制
c.add(200);//向集合中添加元素
c.add(300);//向集合中添加元素
c.add(400);//向集合中添加元素
c.add(500);//向集合中添加元素
System.out.println(c);//直接打印集合,查看集合中的元素
// c.clear();//清空当前集合中的所有元素
// System.out.println(c);
System.out.println(c.hashCode());//获取集合对象的哈希码值
System.out.println(c.toString());//打印集合的具体元素
System.out.println(c.equals(200));//false,集合对象c与值200是否相等
System.out.println(c.contains(200));//true,c集合中是否包含指定元素200
System.out.println(c.isEmpty());//false,判断集合是否为空
System.out.println(c.remove(100));//true,移除集合中的指定元素,成功返回true
System.out.println(c);//[200, 300, 400, 500]
System.out.println(c.size());//4,返回集合的元素个数
Object[] array = c.toArray();//将指定的集合转为数组Object[]
System.out.println(Arrays.toString(array));//[200, 300, 400, 500]
//2.2测试多个集合间的操作
Collection<Integer> c2 = new ArrayList<>();//创建第2个集合
c2.add(2);//向c2集合添加元素
c2.add(4);//向c2集合添加元素
c2.add(5);//向c2集合添加元素
System.out.println(c2);//查看c2集合中的元素
c.addAll(c2);//把c2集合的所有元素添加到c集合当中
System.out.println(c);//c2集合的所有元素追加到了c集合末尾
System.out.println(c2);//c2集合本身没有任何改变
//当前集合c是否包含指定集合c2中的所有元素
System.out.println(c.containsAll(c2));
System.out.println(c.contains(200));//c是否包含单个指定元素200
System.out.println(c.removeAll(c2));//删除c集合中属于c2集合的所有元素
System.out.println(c);
System.out.println(c.add(5));
System.out.println(c);
System.out.println(c.retainAll(c2));//取c集合与c2集合的交集(公共元素)
System.out.println(c);//[5]
//3.迭代集合/遍历集合
/**迭代步骤:
* 1.获取集合的迭代器 c.iterator();
* 2.判断集合中是否有下一个可迭代的元素 it.hasNext()
* 3.获取当前迭代到的元素 it.next()*/
Iterator<Integer> it = c.iterator();
while(it.hasNext()){
Integer num = it.next();
System.out.println(num);
}
}
}
为了更好的理解集合,我们需要首先引入一个概念:泛型
05.JDK5之后的新特性:泛型 和 增强型for循环
(1)泛型概念
我们可以观察一下,下面的代码中有什么元素是我们之前没见过的呢?

其实就是< ? >的部分,它就是泛型
泛型是(Generics)JDK1.5 的一个新特性,
泛型通常与集合一起使用,用来约束集合中元素的类型
泛型方法 public static == < E > == void get(E[ ] e){ },两处位置都出现了泛型,缺一不可
泛型概念非常重要,它是程序的增强器,它是目前主流的开发方式
(2)泛型的作用
那泛型有什么作用呢?
我们可以把泛型理解成一个“语法糖”,本质上就是编译器为了提供更好的可读性而提供的一种小手段,小技巧,虚拟机层面是不存在所谓“泛型”的概念的。是不有点神奇,不知所云,别着急等我讲完你就清楚了。
我们可以通过泛型的语法定义<>,来约束集合中元素的类型,
编译器可以在编译期根据泛型约束提供一定的类型安全检查,这样可以避免:
- 程序运行时才暴露BUG,
- 代码的通用性也会更强
- 泛型可以提升程序代码的可读性,
但是它只是一个“语法糖”(编译后这样的部分会被删除,不出现在最终的源码中),所以不会影响JVM后续运行时的性能.
(3)泛型的声明——>【接口、类、方法上】
泛型可以在【接口、类、方法上】使用

在方法的返回值前声明了一个,表示后面出现的E是泛型,而不是普通的java变量
(4)常用名称

(5)练习题****1:非常重要————>【Jdk5后特性:增强for循环 和 泛型】:
1、JDK5之后推出了一个新的特性:增强型for循环.也称为新循环。是可以使用相同的语法遍历集合或数组。
01.概述:使用新循环遍历时,如果集合指定了泛型,那么接收元素时可以直接用对应的类型接收元素。
02.语法:
for(元素类型 变量名 : 集合/数组名){
//循环体...
}
03.增强for循环和老式的for循环有什么区别?
注意:新for循环必须有被遍历的目标。目标只能是Collection集合或者是数组。
建议:遍历数组时,如果仅为遍历,可以使用增强for循环。如果要对数组的元素进行操作,
使用老式for循环可以通过角标操作。
2、JDK5之后推出的另一个特性:泛型<E>
01.概述:(1)Collection<E>定义时,指定了一个泛型E。我们在实际使用集合时可以指定E的实际类型。
这样一来,编译器会检查我们使用泛型时的类型是否匹配。例如集合的方法:boolean add(E e):
编译器会检查我们调用add方法向集合中添加元素时,元素的类型是否为E指定的类型,不符合编译不通过。
(2)泛型也称为参数化类型,允许我们在使用一个类时指定它当中属性,方法参数或返回值的类型。使得我们使用这个类时更方便更灵活。
①泛型在集合中广泛使用,用于指定该集合中的元素类型。
02.写法注意:(1)E:泛型数据类型(用于设置objectName的数据类型,只能为引用数据类型)。
(2)编译器会检查传入的E对应的实参是否为E指定的实际类型
(3)使用新循环遍历时,如果集合指定了泛型,那么接收元素时可以直接用对应的类型接收元素。
(4)新循环遍历集合会改回成迭代器遍历:迭代器也支持泛型,指定时要与其遍历的集合指定的泛型一致
练习题:
package apiday.gather.collection.list.arrayList;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* 1、JDK5之后推出了一个新的特性:增强型for循环.也称为新循环。是可以使用相同的语法遍历集合或数组。
* 01.概述:使用新循环遍历时,如果集合指定了泛型,那么接收元素时可以直接用对应的类型接收元素。
* 02.语法:
* for(元素类型 变量名 : 集合/数组名){
* //循环体...
* }
*
* 03.增强for循环和老式的for循环有什么区别?
* 注意:新for循环必须有被遍历的目标。目标只能是Collection集合或者是数组。
* 建议:遍历数组时,如果仅为遍历,可以使用增强for循环。如果要对数组的元素进行操作,
* 使用老式for循环可以通过角标操作。
*
*
* 2、JDK5之后推出的另一个特性:泛型
* 01.概述:(1)Collection定义时,指定了一个泛型E。我们在实际使用集合时可以指定E的实际类型。
* 这样一来,编译器会检查我们使用泛型时的类型是否匹配。例如集合的方法:boolean add(E e):
* 编译器会检查我们调用add方法向集合中添加元素时,元素的类型是否为E指定的类型,不符合编译不通过。
* (2)泛型也称为参数化类型,允许我们在使用一个类时指定它当中属性,方法参数或返回值的类型。使得我们使用这个类时更方便更灵活。
* ①泛型在集合中广泛使用,用于指定该集合中的元素类型。
*
* 02.写法注意:(1)E:泛型数据类型(用于设置objectName的数据类型,只能为引用数据类型)。
* (2)编译器会检查传入的E对应的实参是否为E指定的实际类型
* (3)使用新循环遍历时,如果集合指定了泛型,那么接收元素时可以直接用对应的类型接收元素。
* (4)新循环遍历集合会改回成迭代器遍历:迭代器也支持泛型,指定时要与其遍历的集合指定的泛型一致
*
*
*/
public class NewForDemo {
public static void main(String[] args) {
/** 1、JDK5之后推出了一个新的特性:增强型for循环.也称为新循环。 */
/* (1)String类型的数组: */
//①传统for循环
String[] array = {"one","two","three","four","five"};
System.out.println(array.toString());
for(int i=0;i<array.length;i++){
String s = array[i];
System.out.println(s);
}
//②增强型for循环:
for(String e : array){ //冒号(:)后面是要遍历的数组
System.out.println(e);
}
/* (2)集合类型的数组: */
Collection c = new ArrayList();
c.add("one");
c.add("two");
c.add("three");
System.out.println(c);//[one, two, three]
for(Object o : c){
String s = (String) o;
System.out.println(s);
}
/** 2、JDK5之后推出的另一个特性:泛型 */
Collection<String> c2 = new ArrayList<>();
c2.add("one");
c2.add("two");
c2.add("three");
/* (0)编译器会检查传入的E对应的实参是否为E指定的实际类型 */
// c2.add(123);//当元素类型不符合E在这里的实际类型String,因此编译不通过。
System.out.println(c2);//[one, two, three]
/* (1)使用新循环遍历时,如果集合指定了泛型,那么接收元素时可以直接用对应的类型接收元素。 */
for(String s : c2){
System.out.println(s);
}
/* (2)新循环遍历集合会改回成迭代器遍历:*/
//迭代器也支持泛型,指定时要与其遍历的集合指定的泛型一致
Iterator<String> e = c.iterator();
while(e.hasNext()){
//当使用Iterator控制元素类型后,就不需要强转了。-
//-获取到的元素直接就是String类型
String str = e.next();
System.out.println(str);
}
}
}
(6)练习2:泛型测试2
创建包: cn.tedu. generic
创建类: TestGeneric2.java
package cn.tedu.generic;
/**本类用来测试泛型的优点2*/
public class TestGeneric2 {
public static void main(String[] args) {
//需求:打印指定数组中的所有元素
Integer[] a = {1,2,3,4,5,6,7,8,9,10};
print(a);
String[] b = {"大哥","二哥","三哥","四哥","五哥","六哥","小弟"};
print(b);
Double[] c = {6.0,6.6,6.66,6.666,6.6666};
print(c);
}
/**1.泛型可以实现通用代码的编写,使用E表示元素的类型是Element类型 -- 可以理解成神似多态*/
/**2.泛型的语法要求:如果在方法上使用泛型,必须两处同时出现,一个是传入参数的类型,一个是返回值前的泛型类型,表示这是一个泛型*/
private static <E> void print(E[] e) {
for(E d :e) {
System.out.println(d);
}
}
// public static void print(Double[] c) {
// for(Double d : c) {
// System.out.println(d);
// }
// }
//
// public static void print(String[] b) {
// for(String s : b) {
// System.out.println(s);
// }
// }
//
// public static void print(Integer[] a) {
// //使用普通循环遍历数组比较复杂,引入高效for循环
// //普通循环的好处是可以控制循环的步长(怎么变化)
// for (int i = 0; i < a.length; i=i+2) {
// System.out.println(a[i]);
// }
// /**
// * 高效for/foreach循环--如果只是单纯的从头到尾的遍历,使用增强for循环
// * 好处:比普通的for循环写法简便,而且效率高
// * 坏处:没有办法按照下标来操作值,只能从头到尾依次遍历
// * 语法:for(1 2 : 3){代码块} 3是要遍历的数据 1是遍历后得到的数据的类型 2是遍历起的数据名
// */
// for(Integer i : a) {
// System.out.print(i);
// }
// }
}
06.JDK8之后集合新特性:用forEach的lambda遍历
JDK8之后【集合】提供了支持使用lambda表达式遍历的操作:forEach()
①:用JDK5之后的新特性for新循环:遍历集合c中的每一个元素:
for(String s: c){
System.out.print(s+" ");//one two three four five
}
②:用JDK8之后的forEach的Lambda表达式遍历集合c中的每一个元素:
c.forEach(s -> System.out.println(s));
③:上边的②还可以简化为下边的代码
c.forEach(System.out::println);
package apiday.gather.map;
import java.util.ArrayList;
import java.util.Collection;
/**
* JDK8之后【集合】提供了支持使用lambda表达式遍历的操作:forEach()
* ①:用JDK5之后的新特性for新循环:遍历集合c中的每一个元素:
* ②:用JDK8之后的forEach的Lambda表达式遍历集合c中的每一个元素:————>c.forEach(s -> System.out.println(s));
* ③:上边的②还可以简化为下边的代码——————>c.forEach(System.out::println);
*/
public class Collection_forEach {
public static void main(String[] args) {
/* JDK8之后【集合】提供了支持使用lambda表达式遍历的操作:forEach() */
Collection<String> c = new ArrayList<>();
c.add("one");
c.add("two");
c.add("three");
c.add("four");
c.add("five");
System.out.println(c);//[one, two, three, four, five]
//①:用JDK5之后的新特性for新循环:遍历集合c中的每一个元素:
for(String s: c){
System.out.print(s+" ");//one two three four five
}
System.out.println("");
//②:用JDK8之后的forEach的Lambda表达式遍历集合c中的每一个元素:
c.forEach(s -> System.out.println(s));//one two three four five
//③:上边的②还可以简化为下边的代码
// c.forEach(System.out::println);
}
}
3、数组/集合工具类(Arrays/Collections)
01.数组工具类Arrays API:asList(数组转换为List集合)
数组的工具类Arrays提供了一个静态方法asList,可以将一个数组转换为一个List集合
数组转换为集合:
01.数组的工具类Arrays提供了一个静态方法asList():可以将一个数组转换为一个List集合
02.会改变数组长度的操作都是不支持的,因为数组是定长的。
会抛出【不支持的操作异常】:java.lang.UnsupportedOperationException
解决办法:(1):首先将其转为集合,再添加或删除元素
(2):所有的集合都支持一个参数为Collection的构造器,
作用是在创建当前集合的同时包含给定集合中的所有元素
package apiday.gather.list.api;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 数组转换为集合:
* 01.数组的工具类Arrays提供了一个静态方法asList():可以将一个数组转换为一个List集合
* 02.会改变数组长度的操作都是不支持的,因为数组是定长的。
* 会抛出【不支持的操作异常】:java.lang.UnsupportedOperationException
* 解决办法:(1):首先将其转为集合,再添加或删除元素
* (2):所有的集合都支持一个参数为Collection的构造器,
* 作用是在创建当前集合的同时包含给定集合中的所有元素
*/
public class ArrayToList {
public static void main(String[] args) {
String[] array = {"one","two","three","four","five"};
System.out.println("array:"+ Arrays.toString(array));//array:[one, two, three, four, five]
/** 01.静态方法asList():可以将一个数组转换为一个List集合 */
List<String> list = Arrays.asList(array);
System.out.println("list:" + list);//list:[one, two, three, four, five]
//对该集合的操作就是对原数组对应的操作:
list.set(1,"six");
System.out.println("list:" + list);//list:[one, six, three, four, five]
System.out.println("array:"+ Arrays.toString(array));//array:[one, six, three, four, five]
/**
* 02.会改变数组长度的操作都是不支持的,因为数组是定长的。
* 会抛出【不支持的操作异常】:java.lang.UnsupportedOperationException
*
* 例题:
*/
// list.add("seven");
// System.out.println("list:" + list);
// System.out.println("array:"+ Arrays.toString(array));
/* 解决办法:(1)或(2) */
/* (1):首先将其转为集合,再添加或删除元素:*/
// //①创建一个新集合list2
// List list2 = new ArrayList<>();
// //②将list里所有元素存入list2:
// list2.addAll(list);
/* (2):所有的集合都支持一个参数为Collection的构造器,作用是在创建当前集合的同时包含给定集合中的所有元素: */
//上边两个步骤可以简化为一句代码:————>但要注意:可能丢失数据!
List<String> list2 = new ArrayList<>(list);
System.out.println("list2:"+list2);//list2:[one, six, three, four, five]
list2.add("seven");
System.out.println("list2:"+list2);//list2:[one, six, three, four, five, seven]
}
}
02.集合工具类Collections API:
(1)①reverse():—————>集合工具类Collections提供了一个方法可以:颠倒数组中元素的顺序(翻转集合)
②shuffle():——————>可以对List集合进行乱序排序。
(2)①sort(list)—————————————————>集合的工具类java.util.Collections提供了一
个静态方法:只能对List集合进行自然排序。
②Collections.sort(List list)在排序List集合时要求集合元素必须实现了:
Comparable(比较)接口。
实现了该接口的类必须重写一个方法:compareTo(用于定义比较大小的规则,从而进行元素
间的比较后顺序。否则编译不通过。)
(6)int indexOf(Object o) :判断指定元素o在本集合中第一次出现的下标,如果不存在,返回-1
(7)int lastIndexOf(Object o) :判断指定元素o在本集合中最后一次出现的下标,如果不存在,返回-1
(1)Collections API之:reverse翻转集合
package apiday.gather.collection.collections_api;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* 翻转集合:
* Collections.reverse():集合工具类Collections提供了一个方法可以:颠倒数组中元素的顺序(翻转集合)
*/
public class ReverseCollection {
public static void main(String[] args) {
//以下这两个测试都可以;唯一区别:性能不一样!
List<String> list = new ArrayList<>();
// List list = new LinkedList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
System.out.println(list);//[one, two, three, four, five]
/*
(1)Collections.reverse():集合工具类Collections提供了一个方法可以:颠倒数组中元素的顺序(翻转集合)
*/
//将集合list反转:————————>第一种方式:
Collections.reverse(list);
System.out.println(list);//[five, four, three, six, one]
//将集合list反转:————————>第2种方式:①②③
for(int i=0;i<list.size()/2;i++){
//①获取正数位置上的元素
String e = list.get(i);
//②将正数位置上的元素放到倒数位置上并接收被替换的倒数位置元素
e = list.set(list.size()-1-i,e);
//③将倒数位置的元素放到正数位置上
list.set(i,e);
//以上三句还可以合并为这一句来写:
// list.set(i,list.set(list.size()-1-i,list.get(i)));
}
System.out.println(list);//[one, six, three, four, five]
}
}
(2)Collections API之:sort进行自然排序(默认小到大)
集合的工具类java.util.Collections提供了一个静态方法sort,**只能对List集合**进行自然排序。
集合的排序:
01.sort():集合的工具类java.util.Collections提供了一个静态方法sort,可以对List集合进行自然排序
02.shuffle():可以对List集合进行乱序排序。
03.(1)从小到大排:sort(List<T> list,Comparable<? super T> c):可以对List集合进行从小到大排序。
*03.(2)从大到小排:从大往小排(sort只能从小到大排):但是可以改变用来比较字符串值的顺序来完成
package apiday.gather.collection.collections_api;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
/**
* 集合的排序:
* 01.sort():集合的工具类java.util.Collections提供了一个静态方法sort,可以对List集合进行自然排序
* 02.shuffle():可以对List集合进行乱序排序。
* 03.(1)从小到大排:sort(List list,Comparable c):可以对List集合进行从小到大排序。
* *03.(2)从大到小排:从大往小排(sort只能从小到大排):但是可以改变用来比较字符串值的顺序来完成
*
*/
public class SortListDemo {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
Random random = new Random();
for(int i=0;i<10;i++){
list.add(random.nextInt(100));//输出100以内10个随机数
}
System.out.println(list);//[75, 64, 67, 88, 76, 25, 4, 71, 2, 82]
//01.sort():可以对List集合进行自然排序。
Collections.sort(list);
System.out.println(list);//[2, 4, 25, 64, 67, 71, 75, 76, 82, 88]
//02.shuffle():可以对List集合进行乱序排序。
Collections.shuffle(list);
System.out.println(list);//[25, 88, 4, 71, 75, 64, 67, 2, 76, 82]
//03.(1)从小到大排:
// Collections.sort(list,(i1,i2)->i1-i2);
// System.out.println(list);//[8, 30, 30, 31, 36, 56, 66, 75, 96, 98]
//03.(2)从大到小排:从大往小排(sort只能从小到大排):但是可以改变用来比较字符串值的顺序来完成
//sort(List list,Comparable c):可以对List集合进行从大到小排序。
Collections.sort(list,(i1,i2)->i2-i1);
System.out.println(list);//[98, 96, 75, 66, 56, 36, 31, 30, 30, 8]
}
}
(3)Collections API之:Comparator(比较)接口排序自定义类型元素
集合排序自定义类型元素:
1、
01.Collections.sort(List list):
在排序List集合时要求集合元素必须实现了Comparable(比较)接口。
实现了该接口的类必须重写一个compare()方法才可以进行比较:
compareTo(可比较接口):用于定义比较大小的规则,从而进行元素间的比较后顺序。否则编译不通过。
例:Collections.sort(list);//直接调用sort则编译不能通过
02.补充:
(1)侵入性:
当我们调用某个API时,其反过来要求我们为其修改其他额外的代码,这种现象就
成为侵入性。侵入性不利于程序后期的维护,尽可能避免。
(2)java的比较器有两类————>分别是:Comparable排序接口和Comparator比较器接口。
①首先来说Comparable排序接口:
在为对象数组进行排序时,让需要进行排序的对象实现Comparable接口,重写它的
compareTo(To)方法,在其中定义排序规则,那么就可以直接调用java.util.Arrays.sort()来排序对象数组.
——>实际开发中,我们并不会让我们自己定义的类(如果该类作为集合元素使用)去实现Comparable接口,
因为这对我们的程序有侵入性.
②Comparator是比较器接口:
当我们需要控制某个类的次序,而这个类是不支持排序的(因为没有实现comparable接口),那我们用比较器
来进行排序,这个比较器需要实现comparator接口(并重写compare()方法)。
简而言之就是:通过实现Comparator接口来建立一个比较器,从而通过比较器来对这个类进行排序.
03.解决办法:三种写法(1)-(3)
(0)定义一个类并实现Comparator接口接口(并重写compare()方法)——>不可以!因为有侵入性,可以写成匿名内部类,如(1)
(1)写成匿名内部类的形式创建一个比较器Comparator接口(并重写compare()方法)——>还可以进阶为没有侵入性的写法(2)
(2)没有侵入性的写法———>还可以变为Lambda表达式的写法(3)
*(3)没有侵入性的Lambda表达式的写法
package apiday.gather.collection.collections_api;
import apiday.gather.collection.collection_api.Point;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/**
* 集合排序自定义类型元素:
* 1、
* 01.Collections.sort(List list):
* 在排序List集合时要求集合元素必须实现了Comparable(比较)接口。
* 实现了该接口的类必须重写一个方法才可以进行比较:
* compareTo(可比较接口):用于定义比较大小的规则,从而进行元素间的比较后顺序。否则编译不通过。
* 例:Collections.sort(list);//编译不能通过
*
* 02.补充:
* (1)侵入性:
* 当我们调用某个API时,其反过来要求我们为其修改其他额外的代码,这种现象就
* 成为侵入性。侵入性不利于程序后期的维护,尽可能避免。
*
* (2)java的比较器有两类————>分别是:Comparable排序接口和Comparator比较器接口。
* ①首先来说Comparable排序接口:
* 在为对象数组进行排序时,让需要进行排序的对象实现Comparable接口,重写它的
* compareTo(To)方法,在其中定义排序规则,那么就可以直接调用java.util.Arrays.sort()来排序对象数组.
* ——>实际开发中,我们并不会让我们自己定义的类(如果该类作为集合元素使用)去实现Comparable接口,因为这对我们的程序有侵入性.
*
* ②Comparator是比较器接口:
* 当我们需要控制某个类的次序,而这个类是不支持排序的(因为没有实现comparable接口),那我们用比较器
* 来进行排序,这个比较器需要实现comparator接口(并重写compare()方法)。
* 简而言之就是:通过实现Comparator接口来建立一个比较器,从而通过比较器来对这个类进行排序.
*
* 03.解决办法:三种写法(1)-(3)
* (0)定义一个类并实现Comparator接口接口(并重写compare()方法)—————————————>不可以!因为有侵入性,可以写成匿名内部类,如(1)
* (1)写成匿名内部类的形式创建一个比较器Comparator接口(并重写compare()方法)——>还可以进阶为没有侵入性的写法(2)
* (2)没有侵入性的写法———>还可以变为Lambda表达式的写法(3)
* *(3)没有侵入性的Lambda表达式的写法
*
*/
public class SortListDemo2 {
public static void main(String[] args) {
List<Point> list = new ArrayList<>();
list.add(new Point(1,2));
list.add(new Point(15,8));
list.add(new Point(9,7));
list.add(new Point(5,3));
list.add(new Point(4,6));
System.out.println(list);//[point{x=1, y=2}, point{x=15, y=8}, point{x=9, y=7}, point{x=5, y=3}, point{x=4, y=6}]
/*
编译不通过:
原因:集合元素没有实现接口Comparable,只有实现了该接口的类才可以进行比
较(实现接口后就必须重写方法compareTo():用于定义两个元素间的比较大小规则)。
该操作对我们的代码具有侵入性,不建议这样做。
侵入性:当我们调用一个功能时,其要求我们为其修改其他额外的代码,这就是侵入性。
它不利于程序后期的维护与扩展,应当尽量避免。
解决办法:
(0)定义一个类并实现Comparator接口———————————————>不可以!因为有侵入性,可以写成匿名内部类,如(1)
(1)写成匿名内部类的形式创建一个比较器Comparator————>还可以进阶为没有侵入性的写法(2)
(2)没有侵入性的写法———>还可以进阶为Lambda表达式的写法(3)
(3)没有侵入性的Lambda表达式的写法
*/
//Collections.sort(list);//编译不通过
//解决办法:(0)new一个MyComparator对象并调用sort方法
// MyComparator c = new MyComparator();
// Collections.sort(list,c);
/* 解决办法:(1)匿名内部类写法 */
// Comparator c = new Comparator() {
// @Override
// //实现比较器接口后必须重写方法compare.
//该方法用来定义参数o1与参数o2的比较大小规则
//返回值用来表示o1与o2的大小关系
// public int compare(Point o1, Point o2) {//compare:比较
// int len1 = o1.getX()*o1.getX()+o1.getY()* o1.getY();
// int len2 = o2.getX()*o2.getX()+o2.getY()* o2.getY();
// return len1-len2;
// }
// };
// Collections.sort(list,c);//回调模式
/* 解决办法:(2)没有侵入性的写法 */
// Collections.sort(list,new Comparator() {
// @Override
// public int compare(Point o1, Point o2) {//compare:比较
// int len1 = o1.getX()*o1.getX()+o1.getY()* o1.getY();
// int len2 = o2.getX()*o2.getX()+o2.getY()* o2.getY();
// return len1-len2;
// }
// });
/* 解决办法:(3)没有侵入性的Lambda表达式的写法 */
Collections.sort(list,
(o1,o2)->
o1.getX()*o1.getX()+o1.getY()* o1.getY() -
o2.getX()*o2.getX()-o2.getY()* o2.getY()
);
System.out.println(list);//[point{x=1, y=2}, point{x=5, y=3}, point{x=4, y=6}, point{x=9, y=7}, point{x=15, y=8}]
}
}
/* 解决办法:(0)①定义一个类并实现Comparator比较器接口来进行排序 */
/* ②在main中new一个MyComparator对象并调用sort方法————————>不可以!因为有侵入性! */
//class MyComparator implements Comparator{
// @Override
// /**
// * 用来定义两个元素o1与o2的大小关系,返回值为:
// * 当返回值>0时:表示o1>o2的
// * 当返回值<0时:表示o1
// * 当返回值=0时:表示o1=o2
// */
// public int compare(Point o1, Point o2) {//compare:比较
// int len1 = o1.getX()*o1.getX()+o1.getY()* o1.getY();
// int len2 = o2.getX()*o2.getX()+o2.getY()* o2.getY();
// return len1-len2;
// }
//}
(4)Collections API之:用Lambda排序字符串:
java中提供的类,如:String、包装类都实现了Comparable接口并定义了比较规则,
但有时候这些比较规则不能满足我们的排序需求时,同样可以临时提供一种比较规则来进行排序。
第二种:用Lambda表达式来写:
例:Collections.sort(list,(o1,o2) -> o1.length() - o2.length());
java中提供的类,如:String、包装类都实现了Comparable接口并定义了比较规则,
但有时候这些比较规则不能满足我们的排序需求时,同样可以临时提供一种比较规则来进行排序。
1、排序字符串:
01.sort()默认从小到大排序:Collections.sort(List<T> list)
02.但是可以改变用来比较字符串值的顺序来完成
使用重载的sort方法,定义一个比较器,按照字数多少排序:
第(1)种写法:匿名内部类
第(1)种扩展:重载的Collections.sort(List list,Comparator c)方法
*第(2)种写法:①sort只能从小到大排————>Lambda表达式来写:
第(2)种扩展:②扩展:从大往小排(sort只能从小到大排):但是可以改变用来比较字符串值的顺序来完成
第(3)种写法: 注意:接口里边可以有方法!!
package apiday.gather.collection.collections_api;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/**
* 当元素本身实现了Comparable接口并定义了比较规则,但是按照该规则排序后不满足我们的排序
* 需求时,我们也可以自定义比较规则。
*
* 01.sort()默认从小到大排序:Collections.sort(List list)
*
* 02.但是可以改变用来比较字符串值的顺序来完成
* 使用重载的sort方法,定义一个比较器,按照字数多少排序:
* 第(1)种写法:匿名内部类
* *第(2)种写法:①sort只能从小到大排————>Lambda表达式来写:
* 第(2)种扩展:②扩展:从大往小排(sort只能从小到大排):但是可以改变用来比较字符串值的顺序来完成
* 第(3)种写法: 注意:接口里边可以有方法!!
*/
public class SortListDemo3 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// list.add("tom");
// list.add("jerry");
// list.add("jack");
// list.add("rose");
// list.add("jill");
// list.add("ada");
// list.add("Hanmeimei");
// list.add("Lilei");
list.add("苍老师");
list.add("传奇");
list.add("小泽老师");
System.out.println(list);//[苍老师, 传奇, 小泽老师]
/** 01.sort():默认从小到大排序 */
// Collections.sort(list);
// System.out.println(list);//[传奇, 小泽老师, 苍老师]
/** 02.使用重载的sort方法,定义一个比较器,按照字数多少排序 */
/*
//第(1)种写法:匿名内部类
Comparator com = new Comparator() {
@Override
//实现比较器接口后必须重写Compare()方法:
//该方法用来定义参数o1与参数o2的比较大小规则
//返回值(return)用来表示o1与o2的大小关系:
public int compare(String o1, String o2) {
if(o1.length() > o2.length()){
return 1;
}else if(o1.length() < o2.length()){
return -1;
}else{
return 0;
}
}
};
Collections.sort(list,com);//回调模式
System.out.println(list);//[传奇, 苍老师, 小泽老师]
*/
//第(2)种写法:①sort只能从小到大排————>Lambda表达式来写:
Collections.sort(list,(s1,s2)->s1.length()-s2.length());
System.out.println(list);//[传奇, 苍老师, 小泽老师]
//第(2)种扩展:②扩展:从大往小排(sort只能从小到大排):但是可以改变用来比较字符串值的顺序来完成
// Collections.sort(list,(o1,o2)->o2.length()-o1.length());
// System.out.println(list);//[小泽老师, 苍老师, 传奇]
//第(3)种写法: 注意:接口里边可以有方法!!
// Collections.sort(list,Comparator.comparingInt(String::length));//两个(::)的意思是:方法引用
// System.out.println(list);//[传奇, 苍老师, 小泽老师]
}
}
4、List接口——>下标、有序、可重复
————>List集合是可重复集,并且有序,提供了一套可以通过下标操作元素的方法。
4.1.List接口的特有API:(1)①②、(2)①②、(3)①
List集合
1、java.util.List:可重复集且有序。————>线性表
:List接口继承自Collection,是可以存放重复元素且有序的集合。
(1)概述:有两个常用实现类:
①java.util.ArrayList——————>(内部使用数组实现,查询性能更好。)
②java.util.LinkedList—————>(内部使用链表实现,增删性能更好,首尾增删性能最佳。)
注:对性能没有特别苛刻的要求下,通常使用ArrayList即可。
(2)特点:
①List集合是有下标的
②List集合是有顺序的
③List集合可以存放重复的元素
01.List API:————————>List独有的api:【(1)①②、(2)①②、(3)①】
(1)①E get(int index):——————————————>获取指定下标对应的元素
②E set(int index,E e):——————————>替换;将给定元素设置到指定位置上,返回值为该位置原来的元素
③Collections.reverse():—————————>集合工具类Collections提供了一个方法可以:颠倒数组中元素的顺序(翻转集合)
(2)List重载了一对add和remove方法:
①void add(int index,E e):————————>将给定元素插入到指定位置
②E remove(int index):————————————>删除并返回指定位置上的元素
(3)①List subList(int start,int end):——>获取指定范围内的子集
②.subList(2,8).clear():————————————>清除集合内指定下标之间的元素
练习题:
package apiday.gather.list.api;
import java.util.*;
/**
* List集合
* 1、java.util.List:可重复集且有序。————>线性表
* :List接口继承自Collection,是可以存放重复元素且有序的集合。
* (1)概述:有两个常用实现类:
* ①java.util.ArrayList——————>(内部使用数组实现,查询性能更好。)
* ②java.util.LinkedList—————>(内部使用链表实现,增删性能更好,首尾增删性能最佳。)
* 注:对性能没有特别苛刻的要求下,通常使用ArrayList即可。
* (2)特点:
* ①List集合是有下标的
* ②List集合是有顺序的
* ③List集合可以存放重复的元素
*
* 01.List API:————————>List独有的api:【(1)①②、(2)①②、(3)①】
* (1)①E get(int index):——————————————>获取指定下标对应的元素
* ②E set(int index,E e):——————————>替换;将给定元素设置到指定位置上,返回值为该位置原来的元素
* ③Collections.reverse():—————————>集合工具类Collections提供了一个方法可以:颠倒数组中元素的顺序(翻转集合)
* (2)List重载了一对add和remove方法:
* ①void add(int index,E e):————————>将给定元素插入到指定位置
* ②E remove(int index):————————————>删除并返回指定位置上的元素
* (3)①List subList(int start,int end):——>获取指定范围内的子集
* ②.subList(2,8).clear():————————————>清除集合内指定下标之间的元素
*
*/
public class ListDemo1 {
public static void main(String[] args) {
//以下这两个测试都可以;唯一区别:性能不一样!
List<String> list = new ArrayList<>();
// List list = new LinkedList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
System.out.println(list);//[one, two, three, four, five]
/*
(1)①E get(int index):获取指定下标对应的元素
*/
//获取集合中第三个元素:
String s = list.get(2);
System.out.println(s);//three
//遍历集合中每一个元素:
for(int i=0;i<list.size();i++){
s = list.get(i);//String s = array[i];
System.out.print(s+" ");//one two three four five
}
System.out.println("");
/*
(1)②E set(int index,E e):替换;将给定元素设置到指定位置上,返回值为该位置原来的元素
*/
System.out.println(list);//[one, two, three, four, five]
list.set(1,"six");
System.out.println(list);//[one, six, three, four, five]
/*
(1)③Collections.reverse():集合工具类Collections提供了一个方法可以:颠倒数组中元素的顺序(翻转集合)
*/
//将集合list反转:————————>第一种方式:
Collections.reverse(list);
System.out.println(list);//[five, four, three, six, one]
//将集合list反转:————————>第2种方式:①②③
for(int i=0;i<list.size()/2;i++){
//①获取正数位置上的元素
String e = list.get(i);
//②将正数位置上的元素放到倒数位置上并接收被替换的倒数位置元素
e = list.set(list.size()-1-i,e);
//③将倒数位置的元素放到正数位置上
list.set(i,e);
//以上三句还可以合并为这一句来写:
// list.set(i,list.set(list.size()-1-i,list.get(i)));
}
System.out.println(list);//[one, six, three, four, five]
/*
(2)List重载了一对add和remove方法:
①void add(int index,E e):将给定元素插入到指定位置
*/
list.add(1,"six");
System.out.println(list);//[one, six, six, three, four, five]
/*
(2)②E remove(int index):删除并返回指定位置上的元素
*/
String e = list.remove(4);
System.out.println(list);//[one, six, six, three, five]
System.out.println("被删除的元素是:"+e);//被删除的元素是:four
/*
(3)①List subList(int start,int end):获取指定范围内的子集 注意:含头不含尾
*/
//:泛型 智能指定引用型数据 不能为int(为基本数据类型) 所以写Integer
List<Integer> list2 = new ArrayList<>();
for(int i=0;i<10;i++){
list2.add(i);
}
System.out.println(list2);//[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
//获取指定下标范围3-8内的子集:
List<Integer> subList = list2.subList(3,8);
System.out.println(subList);//[3, 4, 5, 6, 7]
//将子集每个元素扩大10倍:
for(int i=0;i<subList.size();i++){
//第一种方法:
// int e = subList.get(i);
// e = e * 10;
// subList.set(i,e);
//第二种方法:
subList.set(i,subList.get(i)*10);
}
System.out.println(subList);//[30, 40, 50, 60, 70]
//:——————>对子集的操作就是对原集合对应元素的操作
System.out.println(list2);//[0, 1, 2, 30, 40, 50, 60, 70, 8, 9]
/*
(3)②.subList(2,8).clear():清除集合内指定下标之间的元素
*/
//删除集合中的2-8下标元素
list2.subList(2,9).clear();
System.out.println(list2);//[0, 1, 9]
}
}
(2)集合间的操作与集合的迭代:
(1)boolean addAll(int index, Collection<> c) 将参数集合c中的所有元素,插入到本集合中指定的下标index处
(2)ListIterator listIterator() 返回此列表元素的迭代器,这个是List自己的,不太常用,可以逆序迭代
以下4.2为补充内容:
4.2.List接口两个实现类----ArrayList/LinkedList
ArrayList的特点:----------java.util.ArrayList:内部使用数组实现,查询性能更好。
1)底层的数据结构是数组,内存空间是连续的
2)元素有下标,通常可以根据下标进行操作
3)增删操作比较 慢 ,查询操作比较快【数据量大时】
LinkedList的特点:----------java.util.LinkedList:内部使用链表实现,增删性能更好,首尾增删性能最佳。
1)底层的数据结构是链表,内存空间是不连续的
2)元素有下标,但是通常首尾节点操作比较多
3)增删操作比较 快 ,查询操作比较慢【数据量大时】
注意:LinkedList查询慢也不是都慢, 【首尾操作还是比较快的】
何时使用ArrayList 或 LinkedList:
1)以下情况使用 ArrayList :
①频繁访问列表中的某一个元素。
②只需要在列表末尾进行添加和删除元素操作。
2)以下情况使用 LinkedList :
①需要通过循环迭代来访问列表中的某些元素。
②需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
-----语言格式:
// 引入 LinkedList 类
import java.util.LinkedList;
LinkedList<E> list = new LinkedList<E>();//普通创建方法
或者
LinkedList<E> list = new LinkedList(Collection<? extends E> c);//使用集合创建链表
简单方法:
void addFirst(E e) 添加首元素
void addLast(E e) 添加尾元素
E removeFirst() 删除首元素
E removeLast() 删除尾元素
E getFirst() 获取首元素
E getLast() 获取尾元素
E element() 获取首元素
功能一致但是名字不太好记的方法:
boolean offer(E e) 添加尾元素
boolean offerFirst(E e) 添加首元素
boolean offerLast(E e) 添加尾元素
E peek() 获取首元素
E peekFirst() 获取首元素
E peekLast() 获取尾元素
E poll() 返回并移除头元素
E pollFirst() 返回并移除头元素
E pollLast() 返回并移除尾元素
01.ArrayList类(增算判删)-----add、size、isEmpty、clear
是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
-ArrayList 继承了 AbstractList ,并实现了 List 接口。
ArrayList 类位于 java.util 包中,使用前需要引入它,语法格式如下:
—import java.util.ArrayList; //引入 ArrayList 类
—ArrayList
E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型。
objectName: 对象名。
ArrayList 是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
-ArrayList类提供了很多有用的方法:
1:add()方法:添加元素
2:size()方法:如果要计算ArrayList中的元素数量
3:isEmpty()方法:判断当前集合是否为一个空集
4:clear()方法:删除Arraylist中的所有元素
《CollectionDemo.java》:
package collection;
import java.util.ArrayList;
import java.util.Collection;
/**
* JAVA集合框架
* 集合和数组一样,可以保存一组元素,但是集合将元素的操作都封装成了方法,操作简便。
* 并且集合提供了多种不同的实现供我们使用。
*
* java.util.Collection是所有集合的顶级接口,里面定义了所有集合都必须具备的功能方法
* 集合有两类常用的子类:
* java.util.List:可重复的集合,且有序。通常我们称它为"线性表"
* java.util.Set:不可重复的集合。
* 上述两个都是接口,而元素是否重复取决于元素自身的equals方法,即:Set集合中不会存在
* 两个元素equals比较为true的情况。
*
*/
public class CollectionDemo {
public static void main(String[] args) {
//集合只能存放引用类型:
Collection c = new ArrayList();
/*
1:添加元素
ArrayList类提供了很多有用的方法,添加元素到 ArrayList 可以使用add() 方法:
boolean add(E e) E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型。
向当前集合中添加一个元素,当元素成功添加则返回true,否则返回false
*/
c.add("one");//add:加
c.add("twe");
c.add("three");
c.add("four");
c.add("five");
System.out.println(c);
// c.add(123);//会触发自动装箱特性
/*
2:计算ArrayList中的元素数量可以使用size()方法:
int size()
返回当前集合的元素个数
*/
int size = c.size();//size:尺寸,大小
System.out.println("size:"+size);
/*
3:判断当前集合是否为一个空集
boolean isEmpty()
判断当前集合是否为一个空集(不含有任何元素),当size为0时,返回true
*/
boolean isEmpty = c.isEmpty();//empty:空的
System.out.println("是否为空集:"+isEmpty);
/*
4:删除Arraylist中的所有元素
void clear()
*/
System.out.println(c);
c.clear();
System.out.println(c);
System.out.println("size:"+c.size());//0
System.out.println("是否为空集:"+c.isEmpty());
}
}
02.ArrayList的操作-----addall添加元素、containsAll判断包含子集、retainAll/remove取删交集
(0)addall()方法:
①addAll() 方法将给定集合中的所有元素添加到 arraylist 中。
②语法:arraylist.addAll(int index, Collection c)
注:arraylist 是 ArrayList 类的一个对象。
③参数说明:
-index(可选参数):表示集合元素插入处的索引值
-c:要插入的集合元素
----------如果 index 没有传入实际参数,元素将追加至数组的最末尾。
④返回值:
如果成功插入元素,返回 true。
如果给定的集合为 null,则超出 NullPointerException 异常。
注意:如果 index 超出范围,则该方法抛出 IndexOutOfBoundsException 异常。
- 例:
c1.addAll(c2);//把c2的所有元素添加到c1中;因为该方法没有传入可选参数 index,所以元素将追加至数组的最末尾。
(1)判断包含子集:boolean containsAll(Collection c)
(2)取交集:c1.retainAll(c3);(仅保留c1中包含c3的元素)
(3)删除交集:c1.remove(c3);(将c1中与c3的共有元素删除(c3不受影响))
package collection;
import java.util.ArrayList;
import java.util.Collection;
/**
* 集合间的操作
*/
public class CollectionDemo04 {
public static void main(String[] args) {
Collection c1 = new ArrayList();
c1.add("java");
c1.add("c++");
c1.add(".net");
System.out.println("c1:"+c1);//c1:[java, c++, .net]
Collection c2 = new ArrayList();
c1.add("android");
c1.add("ios");
c1.add("java");
System.out.println("c2:"+c2);//c2:[]
/*
0、addAll()方法:将给定集合中(c2)的所有元素添加到 arraylist(c1) 中。
*/
c1.addAll(c2);
System.out.println("c1:"+c1);//c1:[java, c++, .net, android, ios, java]
System.out.println("c2:"+c2);//c2:[]
Collection c3 = new ArrayList();
c3.add("c++");
c3.add("ios");
// c3.add("php");
System.out.println("c3:"+c3);//c3:[c++, ios]
/*
1、判断当前集合c1是否包含给定集合c3中的所有元素:boolean containsAll(Collection c)
*/
boolean containsAll = c1.containsAll(c3);
System.out.println("包含所有:"+containsAll);//包含所有:true
/*
/2、取交集:c1.retainAll(c3);(仅保留c1中包含c3的元素)
*/
c1.retainAll(c3);
System.out.println("c1:"+c1);//c1:[c++, ios]
System.out.println("c3:"+c3);//c3:[c++, ios]
/*
3、删除交集:c1.remove(c3);将c1中与c3的共有元素删除(c3不受影响)
*/
c1.remove(c3);
System.out.println("c1:"+c1);//c1:[c++, ios]
System.out.println("c3:"+c3);//c3:[c++, ios]
}
}
03.LinkedList(链表)------继承于List
(2)语法格式:
①引入LinkedList类:import java.util.LinkedList;//
②普通创建方法:LinkedList<E> list = new LinkedList<E>();
或
②使用集合创建链表:LinkedList<E> list = new LinkedList(Collection<? extends E> c);
(1)链表(Linked list):
是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是**在每一个节点里存到下一个节点的地址**。
(2)链表可分为单向链表和双向链表:
①一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接。

②一个双向链表有三个整数值: 数值、向后的节点链接、向前的节点链接。

-Java LinkedList(链表) 类似于 ArrayList,是一种常用的数据容器。
-与 ArrayList 相比,LinkedList 的增加和删除的操作效率更高,而查找和修改的操作效率较低。
04.LinkedList 继承了什么?
LinkedList 继承了 AbstractSequentialList 类。
LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 List 接口,可进行列表的相关操作。
LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。
LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
05.练习:LinkedList测试
创建包: cn.tedu.collection
创建类: TestLinkedList.java
package cn.tedu.colletion;
import java.util.LinkedList;
/**本类用于测试LinkedList的相关测试*/
public class TestLinkedList {
public static void main(String[] args) {
//1.创建对象
LinkedList<String> list = new LinkedList();
//2.添加数据
list.add("孙悟空");
list.add("猪八戒");
list.add("唐三藏");
list.add("沙师弟");
list.add("白龙马");
System.out.println(list);
//3.1自行测试从collection继承过来的共性方法测试
//3.2 LinkedList特有方法测试
list.addFirst("蜘蛛精");//添加首元素
list.addLast("玉兔精");//添加尾元素
System.out.println(list);
System.out.println(list.getFirst());//获取首元素
System.out.println(list.getLast());//获取尾元素
System.out.println(list.removeFirst());//移除首元素,成功移除会返回移除的数据
System.out.println(list);
System.out.println(list.removeLast());//移除尾元素,成功移除会返回移除的数据
System.out.println(list);
//4.其他测试
//4.1创建对象
LinkedList<String> list2 = new LinkedList();
//4.2添加数据
list2.add("水浒传");
list2.add("三国演义");
list2.add("西游记");
list2.add("红楼梦");
System.out.println(list2);
System.out.println(list2.element());//获取但不移除此列表的首元素(第一个元素)
/**别名:查询系列*/
System.out.println(list2.peek());//获取但不移除此列表的首元素(第一个元素)
System.out.println(list2.peekFirst());//获取但不移除此列表的首元素(第一个元素)
System.out.println(list2.peekLast());//获取但不移除此列表的尾元素(最后一个元素)
/**别名:新增系列*/
System.out.println(list2.offer("遮天"));//将指定元素添加到列表末尾
System.out.println(list2.offerFirst("斗罗大陆"));//将指定元素插入列表开头
System.out.println(list2.offerLast("斗破苍穹"));//将指定元素插入列表末尾
System.out.println(list2);
/**别名:移除系列*/
System.out.println(list2.poll());//获取并且移除此列表的首元素(第一个元素),成功移除,返回移除元素
System.out.println(list2.pollFirst());//获取并且移除此列表的首元素(第一个元素),成功移除,返回移除元素,如果此列表为空,则返回null
System.out.println(list2.pollLast());//获取并且移除此列表的尾元素(最后一个元素),成功移除,返回移除元素,如果此列表为空,则返回null
System.out.println(list2);
}
}
5、Set接口————>hashSet 和 SortedSet
java.util.Set:不可重复集
(1)概述:有两个实现类:
①【hashSet(访问效率高)】————————>底层维护的是哈希表
②【SortedSet(有序)】
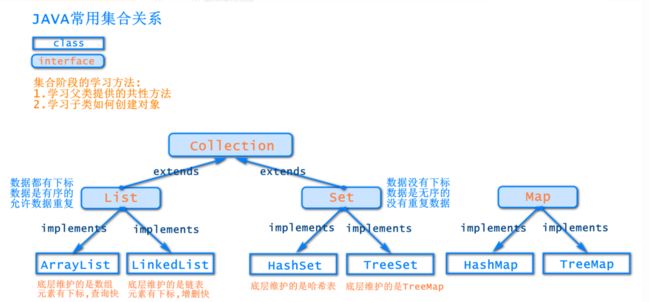
01.set概述和特点
1.Set是一个不包含重复数据的Collection
2.Set集合中的数据是无序的(因为Set集合没有下标)
3.set集合可以存null值,并且null最多有一个
4.Set集合中的元素不可以重复 – 常用来给数据去重(需要在自定义类中添加重写的equals()与hashCode())
02.set集合中的特点:
1.数据无序且数据不允许重复
2.HashSet : 底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K,存入内部的HashMap中。当然K仍然不许重复。
3.TreeSet : 底层是TreeMap,也是红黑树的形式,便于查找数据
03.常用方法-----学习Collection接口中的方法即可
(1)常用方法:
1.创建对应的集合对象:Set<String> set = new HashSet<>();
2.存入集合数据:add()
3.判断是否包含指定元素:contains("唐僧")
4.判断是否为空:set.isEmpty()
5.移除指定的元素:remove(null)
6.获取集合中元素的个数:size()
7.将集合转为数组:Arrays.toString(set.toArray())
8.将set2集合的所有元素添加到set集合中:set.addAll(set2)
9.判断set2集合的所有元素是否都在set集合中:set.containsAll(set2)
10.删除set集合中属于set2集合的所有元素:set.removeAll(set2)
11.只保留set集合中属于set和set2集合的公共元素:set.retainAll(set2)
12.集合的迭代----获取集合的迭代器:set2.iterator()
13.集合的迭代----判断集合是否有下个元素:hasNext()
(2)练习1 和 来练习2
练习1:Set相关测试
创建包: cn.tedu.collection
创建类: TestSet.java
package cn.tedu.collection;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
/*本类用于测试Set*/
public class TestSet {
public static void main(String[] args) {
//1.创建对应的集合对象
Set<String> set = new HashSet<>();
//2.存入数据
set.add("紫霞仙子");
set.add("至尊宝");
set.add("蜘蛛精");
set.add("紫霞仙子");
set.add(null);
/*1.set集合中的元素都是没有顺序的
* 2.set集合中的元素不能重复
* 3.set集合可以存null值,但是最多只有一个*/
System.out.println(set);//[蜘蛛精, null, 至尊宝, 紫霞仙子]
//3.常用方法测试
System.out.println(set.contains("唐僧"));//false,判断是否包含指定元素
System.out.println(set.isEmpty());//false,判断是否为空
System.out.println(set.remove(null));//true,移除指定的元素
System.out.println(set);//[蜘蛛精, 至尊宝, 紫霞仙子]
System.out.println(set.size());//3,获取集合中元素的个数
System.out.println(Arrays.toString(set.toArray()));//[蜘蛛精, 至尊宝, 紫霞仙子],将集合转为数组
//4.1创建set2集合,并向集合中存入数据
Set<String> set2 = new HashSet<>();
set2.add("小兔纸");
set2.add("小脑斧");
set2.add("小海疼");
set2.add("小牛犊");
System.out.println(set2);//[小兔纸, 小海疼, 小牛犊, 小脑斧]
System.out.println(set.addAll(set2));//将set2集合的所有元素添加到set集合中
System.out.println(set);//[蜘蛛精, 小兔纸, 小海疼, 至尊宝, 小牛犊, 小脑斧, 紫霞仙子]
System.out.println(set.containsAll(set2));//判断set2集合的所有元素是否都在set集合中
System.out.println(set.removeAll(set2));//删除set集合中属于set2集合的所有元素
System.out.println(set);//[蜘蛛精, 至尊宝, 紫霞仙子]
System.out.println(set.retainAll(set2));//只保留set集合中属于set和set2集合的公共元素
System.out.println(set);//[]
//5.集合的迭代
Iterator<String> it = set2.iterator();//5.1获取集合的迭代器
while(it.hasNext()) {//5.2判断集合是否有下个元素
String s = it.next();//5.3如果有,进循环获取当前遍历到的元素
System.out.println(s);
}
}
}
练习2:Set相关测试2
1):
创建包: cn.tedu.collection
创建类: Student.java
2):
创建包: cn.tedu.collection
创建类: TestSet2.java
package cn.tedu.collection;
import java.util.Objects;
//1.创建自定义引用类型Student
public class Student {
//2.创建属性
String name;//姓名
int id;//学号
//3.提供本类的全参构造
public Student(String name, int id) {
this.name = name;
this.id = id;
}
//3.2提供学生类的toString()
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
//3.3添加学生类重写的equals()与hashCode()
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id == student.id && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
}
package cn.tedu.collection;
import java.util.HashSet;
import java.util.Set;
/*本类用于进一步测试set*/
public class TestSet2 {
public static void main(String[] args) {
//4.创建集合对象set
Set<Student> set = new HashSet<>();
//5.创建自定义类Student的对象
Student s1 = new Student("张三",3);
Student s2 = new Student("李四",4);
Student s3 = new Student("李四",4);
//6.将创建好的学生对象存入set集合中
set.add(s1);
set.add(s2);
set.add(s3);
/*如果set中存放的是我们自定义的类型
* 需要给自定义类中添加重写的equals()与hashCode(),才会去重
* 不然会认为s2和s3的地址值不同,是两个不同的对象,不会去重*/
System.out.println(set);
}
}
5.1、HashSet:
(1) 概述
底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K存入内部的HashMap中,其中K不允许重复,允许使用null.
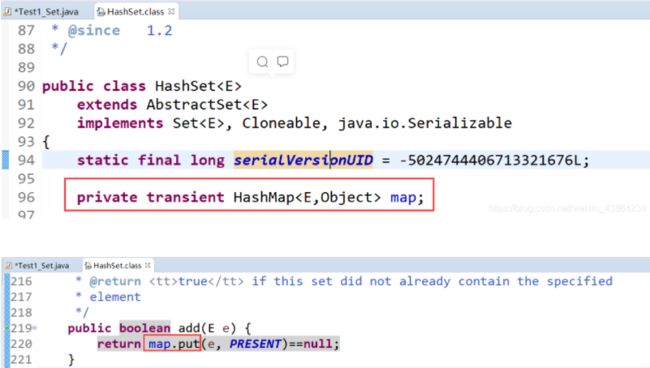
6、Map接口:当今查询速度最快的数据结构

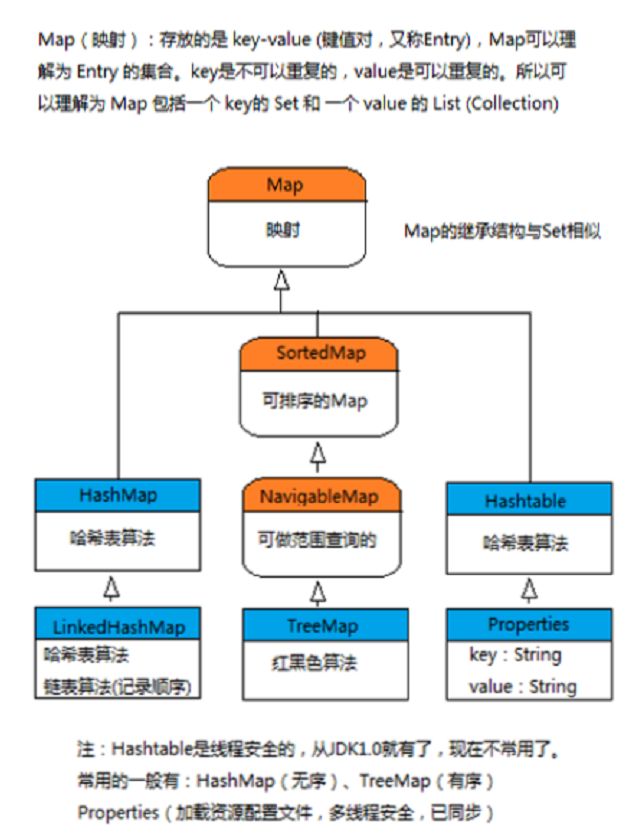
01.Map API:——>当今查询速度最快的数据结构
Map——————>当今查询速度最快的数据结构
一、java.util.Map 接口
(1)概述:①Map称为查找表,体现的结构是一个多行两列的表格。存放的是左列key,右列value(key-value:键值对)。
②Map总是根据key(不可以重复)获取对应的value(可重复)。【如果key重复,对应的value会被覆盖】
③map集合的结构:是键值对、KEY与VALUE、Map.Entry<K,V>的映射关系
④map中的映射关系:是无序的,存放的都是无序的数据
⑤map没有自己的迭代器,所以迭代时通常需要转成set集合来迭代
(2)常用实现类:
①java.util.HashMap(无序):称为(散列表/哈希表)。是使用散列算法实现的Map,当今查询速度最快的数据结构。
②java.util.TreeMap(有序):使用(二叉树算法)实现的Map
*(3)map的方法:
(1)创建Map类型的集合:Map的key和value可以分别指定不同的类型.
(2)v put(K k,V v):将一组键值(key-value)对存入Map中。(键值对:注:Map的key不可重复)
注1:如果put()方法存入的键值对中:key不存在时,则直接将此key-value存入,返回值为null
注2:如果映射先前包含键的映射,则旧值将替换为指定值。
注3:如果key存在,则是替换value操作,此时返回值为被替换的value
(3)V get(Object k):根据给定的key获取对应的value,如果给定的key不存在,则返回值为null
(4)int size():获得该集合的元素个数
(5)boolean containsKey() / containsValue():可判断Map是否包含给定的key或value
(6)v remove():从map中删除给定的key对应的这一组键值对。返回值v是该key对应的value
01.java.util.HashMap:
(1)概述:①是一个散列表,它存储的内容是键值对(key-value)映射。
②Map体现的结构是一个多行两列的表格,其中左列称为“Key”,优列称为“value”
③key与value类型可以相同也可以不同,可以是字符串(String)类型的key和value,
也可以是整型(Integer)的key和字符串(String)类型的value。
(2)HashMap特点:
①实现了Map接口,根据键(Key)的HashCode值存储数据,具有很快的访问速度,最多允许一条记录的键为null,不支持线程同步。
②是无序的,即不会记录插入的顺序。
③继承于AbstractMap,实现了(Map、Cloneable、java.io.Serializable)接口。
(3)hashmap的底层实现?————>数组实现的
注:先根据key调用hashcode方法得到一个整数,再对该整数使用散列算法,生成的整数值为保存在数组(哈希桶)中下标,
键值对数据会存入该位置,存入之前会先判断是否有值:
①若该数组位置没有值,则直接将键值对数据存入数组;
②若有值,则对key使用equlas进行判断,判断key是否相等:
-----若相等,此时将新的value覆盖旧的value;
-----若不相等,此时在数组这个位置形成链表,将新的键值对数据保存到链表上,
从JDK1.8开始,若链表的长度大于8,此时形成红黑树
02.java.util.TreeMap:
package apiday.gather.map;
import java.util.HashMap;
import java.util.Map;
/**
* Map——————>当今查询速度最快的数据结构
* 一、java.util.Map 接口
* (1)概述:①Map称为查找表,体现的结构是一个多行两列的表格。存放的是左列key,右列value(key-value:键值对)。
* ②Map总是根据key(不可以重复)获取对应的value(可重复)。【如果key重复,对应的value会被覆盖】
* ③map集合的结构:是键值对、KEY与VALUE、Map.Entry的映射关系
* ④map中的映射关系:是无序的,存放的都是无序的数据
* ⑤map没有自己的迭代器,所以迭代时通常需要转成set集合来迭代
*
* (2)常用实现类:
* ①java.util.HashMap(无序):称为(散列表/哈希表)。是使用散列算法实现的Map,当今查询速度最快的数据结构。
* ②java.util.TreeMap(有序):使用(二叉树算法)实现的Map
*
* *(3)map的方法:
* (1)创建Map类型的集合:Map的key和value可以分别指定不同的类型.
* (2)v put(K k,V v):将一组键值(key-value)对存入Map中。(键值对:注:Map的key不可重复)
* 注1:如果put()方法存入的键值对中:key不存在时,则直接将此key-value存入,返回值为null
* 注2:如果映射先前包含键的映射,则旧值将替换为指定值。
* 注3:如果key存在,则是替换value操作,此时返回值为被替换的value
* (3)V get(Object k):根据给定的key获取对应的value,如果给定的key不存在,则返回值为null
* (4)int size():获得该集合的元素个数
* (5)boolean containsValue():可判断Map是否包含给定的key或value
* (6)v remove():从map中删除给定的key对应的这一组键值对。返回值v是该key对应的value
*
*
* 01.java.util.HashMap:
* (1)概述:①是一个散列表,它存储的内容是键值对(key-value)映射。
* ②Map体现的结构是一个多行两列的表格,其中左列称为“Key”,优列称为“value”
* ③key与value类型可以相同也可以不同,可以是字符串(String)类型的key和value,
* 也可以是整型(Integer)的key和字符串(String)类型的value。
*
* (2)HashMap特点:
* ①实现了Map接口,根据键(Key)的HashCode值存储数据,具有很快的访问速度,最多允许一条记录的键为null,不支持线程同步。
* ②是无序的,即不会记录插入的顺序。
* ③继承于AbstractMap,实现了(Map、Cloneable、java.io.Serializable)接口。
*
* (3)hashmap的底层实现?————>数组实现的
* 注:先根据key调用hashcode方法得到一个整数,再对该整数使用散列算法,生成的整数值为保存在数组(哈希桶)中下标,
* 键值对数据会存入该位置,存入之前会先判断是否有值:
* ①若该数组位置没有值,则直接将键值对数据存入数组;
* ②若有值,则对key使用equlas进行判断,判断key是否相等:
* -----若相等,此时将新的value覆盖旧的value;
* -----若不相等,此时在数组这个位置形成链表,将新的键值对数据保存到链表上,从JDK1.8开始,若链表的长度大于8,此时形成红黑树
*
* 02.java.util.TreeMap:
*
*
*/
public class Map_Api {
public static void main(String[] args) {
/* (1)创建Map类型的集合:Map的key和value可以分别指定不同的类型. */
Map<String,Integer> map = new HashMap<>();
/* (2)v put(K k,V v):将一组键值(key-value)对存入Map中。(键值对:注:Map的key不可重复) */
//注1:如果put()方法存入的键值对中:key不存在时,则直接将此key-value存入,返回值为null
Integer value = map.put("语文",99);
System.out.println(value);//null
System.out.println(map);//{语文=99}
//注2:如果映射先前包含键的映射,则旧值将替换为指定值。
map.put("数学",98);
map.put("英语",97);
map.put("物理",96);
map.put("化学",99);
value = map.put("语文",100);
System.out.println(value);//99
value = map.put("语文",101);
System.out.println(value);//100
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=101, 英语=97}
//注3:如果key存在,则是替换value操作,此时返回值为被替换的value
map.put("语文",102);
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=102, 英语=97}
/* (3)V get(Object k):根据给定的key获取对应的value,如果给定的key不存在,则返回值为null */
value = map.get("化学");
System.out.println(value);//99
value = map.get("体育");
System.out.println(value);//null
/* (4)int size():获得该集合的元素个数 */
int size = map.size();
System.out.println("map的元素个数是:"+size);//map的元素个数是:5
/* (5)boolean containsValue():可判断Map是否包含给定的key或value */
boolean cv = map.containsValue(99);
System.out.println("包含该value吗?:"+cv);//包含该value吗?:true
cv = map.containsValue(66);
System.out.println("包含该value吗?:"+cv);//包含该value吗?:false
/* (6)v remove():从map中删除给定的key对应的这一组键值对。返回值v是该key对应的value */
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=102, 英语=97}
value = map.remove("语文");
System.out.println(value);//102
System.out.println(map);//{物理=96, 数学=98, 化学=99, 英语=97}
}
}
02.Map的3种遍历方式 和 1种forEach的Lambda遍历
(1)Map的3种遍历方式:
Map的3种遍历方式 和 1种forEach的Lambda遍历
01.3种遍历方式:
(1)Set kaySet():遍历key(将当前Map中所有的key以一个Set集合形式返回,遍历该集合等同与遍历所有的key)
(2)Set<Map.Entry<K,V>> entrySet():
:遍历每一组键值对(将当前Map中每一组键值对(kv)以一个Entry实例取出放入一个Set集合中并返回这个Set集合)
java.util.Map.Entry的每一个实例用于表示Map中的一组键值对,其中方法:
①K getKey():获取对应的key
②V getValue():获取对应的value
(3)Collection values():遍历value(将当前Map中所有的value以一个集合形式返回)
02.JDK8之后集合和Map都提供了支持使用lambda表达式遍历的操作:forEach()
(1)JDK8之后【集合】提供了支持使用lambda表达式遍历的操作:forEach()
①:用JDK5之后的新特性for新循环:遍历集合c中的每一个元素:
②:用JDK8之后的forEach的Lambda表达式遍历集合c中的每一个元素:
③:上边的②还可以简化为下边的代码
(2)JDK8之后【Map】也提供了支持使用lambda表达式遍历的操作:forEach()
01.(2):
package apiday.gather.map;
import java.util.*;
/**
* Map的3种遍历方式 和 1种forEach的Lambda遍历
* 01.3种遍历方式:
* (1)Set kaySet():遍历key(将当前Map中所有的key以一个Set集合形式返回,遍历该集合等同与遍历所有的key)
*
* (2)Set> entrySet():
* :遍历每一组键值对(将当前Map中每一组键值对(kv)以一个Entry实例取出放入一个Set集合中并返回这个Set集合)
* java.util.Map.Entry的每一个实例用于表示Map中的一组键值对,其中方法:
* ①K getKey():获取对应的key
* ②V getValue():获取对应的value
*
* (3)Collection values():遍历value(将当前Map中所有的value以一个集合形式返回)
*
*/
public class MapDemo {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("语文",99);
map.put("数学",98);
map.put("英语",97);
map.put("物理",96);
map.put("化学",99);
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=99, 英语=97}
/* (1)Set keySet():将当前Map中所有的key以一个Set集合形式返回,遍历该集合等同与遍历所有的key */
Set<String> keySet = map.keySet();
for(String key : keySet){
System.out.print("key:"+key+" ");//key:物理 key:数学 key:化学 key:语文 key:英语
}
System.out.println("");
/*
(2)Set entrySet():将当前Map中每一组键值对以一个Entry实例形式表示,并存入Set集合后返回
java.util.Map.Entry的每一个实例用于表示Map中的一组键值对,其中方法:
①K getKey():获取对应的key
②V getValue():获取对应的value
*/
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
for(Map.Entry<String,Integer> e : entrySet){
String key = e.getKey();
Integer value = e.getValue();
System.out.print(key+":"+value+" ");//物理:96 数学:98 化学:99 语文:99 英语:97
}
System.out.println("");
/* (3)Collection values():将当前Map中所有的value以一个集合形式返回 */
Collection<Integer> values = map.values();
for(Integer value : values){
System.out.print("value:"+value+" ");//value:96 value:98 value:99 value:99 value:97
}
}
}
(2)Map在JDK8之后新特性:1种forEach的Lambda遍历的
02.JDK8之后集合和Map都提供了支持使用lambda表达式遍历的操作:forEach()
(1)JDK8之后【集合】提供了支持使用lambda表达式遍历的操作:forEach()
①:用JDK5之后的新特性for新循环:遍历集合c中的每一个元素:
②:用JDK8之后的forEach的Lambda表达式遍历集合c中的每一个元素:
③:上边的②还可以简化为下边的代码
(2)JDK8之后【Map】也提供了支持使用lambda表达式遍历的操作:forEach()
最终代码————> map.forEach((k,v)-> System.out.println(k+":"+v));
注:以下分四步迭代了↑↑↑上面这个 forEach的最终代码。
package apiday.gather.map;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/**
* 02.JDK8之后集合和Map都提供了支持使用lambda表达式遍历的操作:forEach()
*
* (1)JDK8之后【集合】提供了支持使用lambda表达式遍历的操作:forEach()
* ①:用JDK5之后的新特性for新循环:遍历集合c中的每一个元素:
* ②:用JDK8之后的forEach的Lambda表达式遍历集合c中的每一个元素:
* ③:上边的②还可以简化为下边的代码
*
* (2)JDK8之后【Map】也提供了支持使用lambda表达式遍历的操作:forEach()
* 最终代码————> map.forEach((k,v)-> System.out.println(k+":"+v));
* 注:以下分四步迭代了↑↑↑上面这个 forEach的最终代码。
*
*/
public class MapDemo2_forEach {
public static void main(String[] args) {
/** JDK8之后集合和Map都提供了支持使用lambda表达式遍历的操作:forEach(): */
/* (1)JDK8之后【集合】提供了支持使用lambda表达式遍历的操作:forEach() */
Collection<String> c = new ArrayList<>();
c.add("one");
c.add("two");
c.add("three");
c.add("four");
c.add("five");
System.out.println(c);//[one, two, three, four, five]
//①:用JDK5之后的新特性for新循环:遍历集合c中的每一个元素:
for(String s: c){
System.out.print(s+" ");//one two three four five
}
System.out.println("");
//②:用JDK8之后的forEach的Lambda表达式遍历集合c中的每一个元素:
c.forEach(s -> System.out.println(s));//one two three four five
//③:上边的②还可以简化为下边的代码
// c.forEach(System.out::println);
/* (2)JDK8之后【Map】也提供了支持使用lambda表达式遍历的操作:forEach() */
Map<String,Integer> map = new HashMap<>();
map.put("语文",99);
map.put("数学",98);
map.put("英语",97);
map.put("物理",96);
map.put("化学",99);
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=99, 英语=97}
map.forEach((k,v)-> System.out.println(k+":"+v));
//以下分四步迭代了↑↑↑上面这个 forEach的最终代码:
//1完整代码:
// BiConsumer action = new BiConsumer() {
// public void accept(String k, Integer v) {
// System.out.println(k+":"+v);
// }
// };
// Set> entrySet = map.entrySet();
// for(Map.Entry e : entrySet) {
// String k = e.getKey();
// Integer v = e.getValue();
// action.accept(k,v);
// }
//2Map的forEache方法的回调写法:
// BiConsumer action = new BiConsumer() {
// public void accept(String k, Integer v) {
// System.out.println(k+":"+v);
// }
// };
// map.forEach(action);//这个等效上面59-64行(可参考forEach源代码)
//3使用lambda表达式形式创建:
// BiConsumer action =(k,v)->System.out.println(k+":"+v);
// map.forEach(action);
//4最终写法:
// map.forEach((k,v)-> System.out.println(k+":"+v));
}
}
以下6.1位补充内容:
6.1、HashMap :
- 是一个
散列表,它存储的内容是键值对(key-value)映射。 Map体现的结构是一个多行两列的表格,其中左列称为“Key”,优列称为“value”
(1)hashmap的底层实现是什么样的?
先根据key调用hashcode方法得到一个整数,再对该整数使用散列算法,生成的整数值为保存在数组(哈希桶)中下标,键值对数据会存入该位置,存入之前会先判断是否有值:
-1)若该数组位置没有值,则直接将键值对数据存入数组;
-2)若有值,则对key使用equlas进行判断,判断key是否相等:
----------若相等,此时将新的value覆盖旧的value;
----------若不相等,此时在数组这个位置形成链表,将新的键值对数据保存到链表上,从JDK1.8开始,若链表的长度大于8,此时形成红黑树
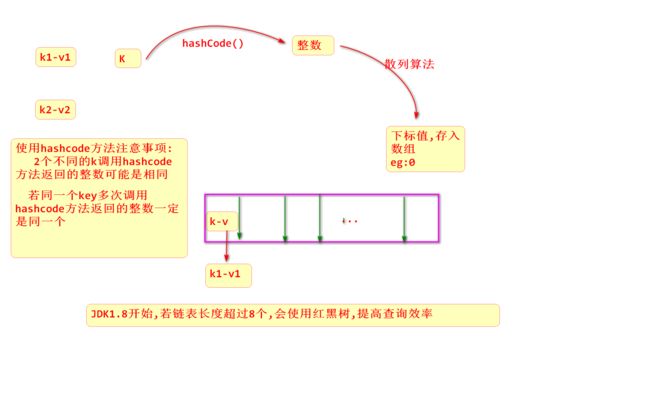
01.HashMap的存储过程:
1.HashMap的结构是数组+链表 或者 数组+红黑树 的形式
2.HashMap底层的Entry[ ]数组,初始容量为16,加载因子是0.75f,扩容按约为2倍扩容
3.当存放数据时,会根据hash(key)%n算法来计算数据的存放位置,n就是数组的长度,其实也就是集合的容量
4.当计算到的位置之前没有存过数据的时候,会直接存放数据
5.当计算的位置,有数据时,会发生hash冲突/hash碰撞:
解决的办法就是采用链表的结构,在数组中指定位置处以后元素之后插入新的元素也就是说数组中的元素都是最早加入的节点
6.如果链表的长度>8并且数组长度>64时,链表会转为红黑树,当链表的长度<6时,会重新恢复成链表
02.练习获取HashMap的数据
创建包: cn.tedu.map
创建类: TestHashMap.java
package cn.tedu.collection;
import java.util.HashMap;
/**本类用于HashMap的练习*/
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap对象
HashMap<Integer,String> map = new HashMap();
/**
* 源码摘抄:
* static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
* 初始容量为1<<4,相当于1*(2^4)=16
* static final float DEFAULT_LOAD_FACTOR = 0.75f;
* 默认的加载因子是0.75,也就是说存到75%开始扩容,按照2的次幂进行扩容
*/
/*
* 达到容量的加载因子后,就会重新开辟空间,重新计算所有对象的存储位置,也叫做rehash
* 设置初始容量与加载因子要讲求相对平衡,如果加载因子过低,则rehash过于频繁,影响性能
* 如果初始容量设置太高或者加载因子设置太高,影响查询效率
*/
}
}
03.练习:字符串中字符统计—charAt()、get()
- 获取本轮循环中遍历到的字符:
charAt(i);
创建包: cn.tedu.map
创建类: TestMap.java
package cn.tedu.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
/*本类用于练习map案例:统计字符串中字符的个数
* 需求效果:用户输入aabbbcc,输出:a=2,b=3,c=2*/
public class TestMap2 {
public static void main(String[] args) {
//1.接收用户输入的字符串
System.out.println("请您输入要统计的字符串:");
String input = new Scanner(System.in).nextLine();
//2.准备一个map集合,用来存放出现的字符Character与字符的个数Integer
//为什么字符类型Character作为map中的KEY?因为key不允许重复,而次数是可以重复的
Map<Character,Integer> map = new HashMap<>();
//3.准备要存入map中的数据:K和V
//3.1 遍历用户输入的字符串,统计每个字符
for (int i = 0; i < input.length(); i++) {
//3.2获取本轮循环中遍历到的字符
char key = input.charAt(i);
//System.out.println(key);//打印查看每轮循环获取到的字符,没有问题
//3.2根据获取到的key拿到对应的value
Integer value = map.get(key);//根据字符,获取map中这个字符保存的次数
if(value == null){//之前这个字符没有出现过,次数还是Integer的默认值null
map.put(key,1);//没有出现过,次数就设置为1
}else {//value不是null走else
map.put(key,value+1);//之前这个字符出现过,次数变为之前的次数+1
}
}
System.out.println("各个字符出现的次数为:"+map);
}
}
四、反射机制
1、反射(Reflection)概念:
(1)Reflection(反射) 是 Java 程序开发语言的特征之一,它允许运行中的 Java 程序对自身进行检查,或者说“自审”,也有称作“自省”。
(2)反射非常强大,它甚至能直接操作程序的私有属性。我们前面学习都有一个概念,被private封装的资源只能类内部访问,外部是不行的,但这个规定被反射赤裸裸的打破了。
(3)反射就像一面镜子,它可以在运行时获取一个类的所有信息,可以获取到任何定义的信息(包括成员变量,成员方法,构造器等),并且可以操纵类的字段、方法、构造器等部分。
在java中,只要给定类的名字,那么就可以通过反射机制来获得类的所有信息。
反射机制是在运行状态中,
对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
/*
* 反射是java中的动态机制,他允许我们在程序运行期间在确定对象的实例化,方法的调用,
* 属性的操作等。使得程序的灵活度大大提升,但同时也带来了更多的资源开销和较低的运行效率。
* 程序不能过度的依赖反射机制。
* /
(1)为什么需要反射?
如果想创建对象,我们直接new User(); 不是很方便嘛,为什么要去通过反射创建对象呢?
那我要先问你个问题了,你为什么要去餐馆吃饭呢?
例如:我们要吃个牛排大餐,如果我们自己创建,就什么都得管理。
好处是,每一步做什么我都很清晰,坏处是什么都得自己实现,那不是累死了。牛接生你管,吃什么你管,屠宰你管,运输你管,冷藏你管,烹饪你管,上桌你管。就拿做菜来说,你能有特级厨师做的好?
那怎么办呢?有句话说的好,专业的事情交给专业的人做,饲养交给农场主,屠宰交给刽子手,烹饪交给特级厨师。那我们干嘛呢?
我们翘起二郎腿直接拿过来吃就好了。
再者,饭店把东西做好,不能扔到地上,我们去捡着吃吧,那不是都成原始人了。那怎么办呢?很简单,把做好的东西放在一个容器中吧,如把牛排放在盘子里。
我们在后面的学习中,会学习框架,有一个框架Spring就是一个非常专业且功能强大的产品,它可以帮我们创建对象,管理对象。以后我无需手动new对象,直接从Spring提供的容器中的Beans获取即可。Beans底层其实就是一个Map
总结一句,类不是你创建的,是你同事或者直接是第三方公司,此时你要或得这个类的底层功能调用,就需要反射技术实现。有点抽象,别着急,我们做个案例,你就立马清晰。
————————————————
2、反射常用API方法:
反射操作的第一步就是获取要操作的类的类对象。
获取一个类的类对象方式有:
1:类名.class
例如:Class cls = String.class;
Class cls = int.class;
注:基本类型只能通过上述方式获取类对象
2:Class.forName(String className)-----使用Class的静态方法forName传入要加载的类的完全限定名(包名.类名)
例如:Class cls = Class.forName(“java.lang.String”)
3:类加载器ClassLoader形式
00.常用API:
0.获取字节码对象
(1)Class.forName(“类的完全限定名”);——>例:Class cls = Class.forName("java.lang.ArrayList")
(2)类名.class:获取该类的类对象
(3)对象.getClass();
1.获取包名 类名
(1)clazz.getName()//获取完整包名 例:获取完整包名 java.lang.String
(2)clazz.getSimpleName()//获取类名 例:获取简名 String
(3)clazz.getPackage().getName()//获取包名 例:获取包名 java.lang
2.获取方法定义信息
(1)getMethod(方法名,参数类型列表):返回一个 Method 对象,该对象反映此 Class 对象表示的类或接口的指定公共成员方法。
(2)getMethods()//获取当前类对象所表示的类的所有公开方法(包含继承的方法)
(3)getDeclaredMethod(方法名,int.class,String.class)
*(4)getDeclaredMethods()//获取当前类对象所表示的类自身定义的所有方法(包含私有方法,不含从超类继承的方法)
3.使用反射机制指定的(有参、无参)构造器进行实例化对象:
(1)clazz.newInstance();//执行无参构造创建对象
(2)clazz.newInstance(666,”海绵宝宝”);//执行含参构造创建对象
(3)clazz.getConstructor(String.class,int.class)//获取构造方法
4.获取构造方法定义信息
(1)getConstructors()//获取所有的公开的构造方法
(2)getConstructors();//不传任何参数时获取的仍然是无参构造器
getConstructor(String.class,int.class);//获取公开的构造方法
(3)getDeclaredConstructors()//获取所有的构造方法,包括私有
(4)getDeclaredConstructor(String.class,int.class)
5.反射调用成员变量
(1)clazz.getDeclaredField(变量名);//获取变量
(2)clazz.setAccessible(true);//使私有成员允许访问
(3)f.set(实例,值);//为指定实例的变量赋值,静态变量,第一参数给null
(4)f.get(实例);//访问指定实例变量的值,静态变量,第一参数给null
6.反射调用成员方法
Method m = Clazz.getDeclaredMethod(方法名,参数类型列表);
m.setAccessible(true);//使私有方法允许被调用
m.invoke(实例,参数数据);//让指定实例来执行该方法
7.获取成员变量定义信息
(1)getFields()//获得本类的所有的公共(public)的字段,包括父类中的字段
(2)getDeclaredFields()//获取本类定义的成员变量,包括私有,但不包括继承的变量
(3)getField(变量名)
(4)getDeclaredField(变量名)
01.通过forname()获取类的其他信息
0.forName(String className):使用Class的静态方法forName传入要加载的类的完全限定名(包名.类名)
例如:Class cls = Class.forName(“java.lang.String”)
练习题:
(1)首先通过调用forName()方法来获取任意类的方法信息
(2)再调用其他方法来打印自己想知道的信息
package apiday.reflect;
import java.lang.reflect.Method;
/**
* java反射机制:
* (1)概述:反射是java的动态机制,可以允许我们在程序[运行期间]再确定实例化,调用某个方法,操作某个属性。
* 反射机制大大的提高了代码的灵活度,但是会有更高的系统开销和较慢的运行效率。
*
* 1、反射 API:
* 步骤:
* (1)首先通过调用forName()方法来获取任意类的方法信息
* (2)再调用其他方法来打印自己想知道的信息
*
* 01.获取字节码对象:
* (1)Class.forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
* 例:Class cls = Class.forName(“java.lang.String”)
* (2)类名.class:获取该类的类对象
* (3)对象.getClass();
*
* 02.获取包名 类名:
* (1)String 引用(对象名).getName():获取当前类对象所表示的类的完全限定名
* (2)String 引用(对象名).getSimpleName():仅获取类名(不包含包名)
* (3)Package 引用(对象名).getPackage():获取当前类对象所表示的类的包,返回的Package的实例表示该包信息
*
* 03.获取方法定义信息
* (1)Method[] 引用(对象名).getMethods():获取当前类对象所表示的类中定义的所有公开方法(包含从超类继承下来的方法)
* (2)Method[] getDeclaredMethods():返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
* 包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
*/
public class ReflectDemo1 {
public static void main(String[] args) throws ClassNotFoundException {
/** 01.反射 API: */
/*
类对象 Class的实例
JVM在加载一个类的class文件时,就会同时创建一个Class的实例,使用该实例记录加载的
类的一切信息(类名,有哪些属性,哪些方法,哪些构造器等)。并且每个被JVM加载的类都有
且只有一个Class的实例与之对应。
反射的第一步就是获取要操作的类的类对象,以便程序在运行期间得知要操作的类的一切信息
然后对其进行响应的操作。
获取一个类的类对象的常见方式:
1:类名.class
例如:
Class cls = String.class;
Class cls = int.class;
注意:基本类型获取类对象只有这一种方式。
2:Class.forName(String className)
例如:
Class cls = Class.forName("java.lang.String");
这里传入的类名必须是类的完全限定名,即:包名.类名
3:还可以通过类加载器形式完成
*/
//①类名.class:获取该类的类对象:
//获取String的类对象
Class cls = String.class;
// Class cls = ArrayList.class;
// Class cls = Class.forName("java.lang.String");
//这段代码用于测试Person类:
// Scanner scanner = new Scanner(System.in);
// System.out.println("请输入类名:");
// String className = scanner.nextLine();
// /*
// 将下面Class cls = Class.forName(className);中的:
// className替换为下面的几种测试:
// java.util.ArrayList
// java.util.HashMap
// java.io.ObjectInputStream
// java.lang.String
// 注意:因为是字符串 所以加 双引号
// */
// Class cls = Class.forName(className);//注意:需要抛出异常
//②引用(对象名).getName():获取当前类对象所表示的类的完全限定名:
String name = cls.getName();
System.out.println(name);//java.lang.String
//③引用(对象名).getSimpleName():仅获取类名(不包含包名):
name = cls.getSimpleName();
System.out.println(name);//String
//④Package 引用(对象名).getPackage():获取当前类对象所表示的类的包,返回的Package的实例表示该包信息
Package pack = cls.getPackage();
System.out.println(pack);//package java.lang, Java Platform API Specification, version 1.8
//引用(对象名).getName():获取当前类对象所表示的类的完全限定名:
String packName = pack.getName();
System.out.println("包名:"+packName);//包名:java.lang
/*
java.lang.reflect.Method类:方法对象。该类的每一个实例用于表示某个类中定义的一个方法。
通过它可以获取其表示的方法中的相关信息(方法名,参数个数,参数类型,返回值类型等等,并且还可以调用这个方法)
⑤Method[] 引用(对象名).getMethods():获取当前类对象所表示的类中定义的所有公开方法(包含从超类继承下来的方法)
⑥Method[] getDeclaredMethods():
返回一个包含 Method 对象的数组,该对象反映了此 Class 对象表示的类或接口的所有声明方法,
包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)
*/
//获取String类的所有方法:
Method[] methods = cls.getMethods();
for(Method method : methods){
System.out.println(method.getName()+"()");
}
methods = cls.getMethods();
System.out.println(cls.getSimpleName()+":一共有"+methods.length+"个本类方法");//String:一共有76个本类方法
methods = cls.getDeclaredMethods();
System.out.println(cls.getSimpleName()+":一共有"+methods.length+"个本类方法");//String:一共有77个本类方法
}
}
02.使用反射机制指定的(有参、无参)构造器进行实例化对象:
package apiday.reflect;
/**
* 使用当前类测试反射机制
*/
public class Person {
private String name = "张三";
private int age = 18;
public Person(){}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public void sayHello(){
System.out.println(name+":hello!");
}
public void sayHi(){
System.out.println(name+":Hi!");
}
public void watchTV(){
System.out.println(name+":看电视");
}
public void sing(){
System.out.println(name+":唱歌");
}
public void doSomeThing(String something){
System.out.println(name+"正在做"+something);
}
public void doSomeThing(String something,int count){
for(int i=0;i<count;i++) {
System.out.println(name + "正在做" + something + i + "次");
}
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
package apiday.reflect;
import java.lang.reflect.Constructor;
/**
* 使用反射机制指定的(有参、无参)构造器进行实例化对象:
* (1)类对象提供了newInstance():可以调用无参【new Person();】且公开的构造器实例化
*
*/
public class ReflectDemo2 {
public static void main(String[] args) throws Exception {
/** 使用指定的(无参)构造器进行实例化对象 */
// Object p = new Person();
// System.out.println(p);//Person{name='张三', age=18}
//
// //1.先获取要实例化对象的类所对应的类对象
// //Class cls = Class.forName("apiday.reflect.Person");
// /*
// java.util.ArrayList
// java.util.HashMap
// java.util.Data(日期)
// */
// Scanner scanner = new Scanner(System.in);
// System.out.println("请输入类名:");
// String className = scanner.nextLine();
// Class cls = Class.forName(className);
//
// //2.类对象提供了方法newInstance()可以调用无参【new Person();】且公开的构造器实例化
// Object o = cls.newInstance();
// System.out.println(o);//Person{name='张三', age=18}
/** 使用指定的(有参)构造器进行实例化对象 */
Person p = new Person("李四",24);
System.out.println(p);//Person{name='李四', age=24}
Class cls = Class.forName("apiday.reflect.Person");
//获取Person的构造器Person(String,int):
//cls.getConstructors();//不传任何参数时获取的仍然是无参构造器
Constructor c = cls.getConstructor(String.class,int.class);
//new Person();
Object obj = c.newInstance("王五",55);//实例化时要传入构造器要求的实际参数
System.out.println(obj);//Person{name='王五', age=55}
}
}
补充测试题:
package apiday.reflect;
import java.lang.reflect.Constructor;
import java.util.ArrayList;
import java.util.List;
/**
* 使用反射机制实例化10个Person对象
* Person对象中的name顺序为:test1--test10
* age顺序为:21-30
* 并存入一个集合
*/
public class Test1 {
public static void main(String[] args) throws Exception{
List<Person> list = new ArrayList<>();
Class cls = Class.forName("apiday.reflect.Person");
//获取Person的构造器Person(String,int):
//cls.getConstructors();//不传任何参数时获取的仍然是无参构造器
Constructor c = cls.getConstructor(String.class,int.class);
//new Person();
for(int i=0;i<10;i++){
String a = "test"+(i+1);
int b = 21+i;
Object obj = c.newInstance(a,b);
System.out.println(obj);
list.add((Person)obj);
}
}
}
03.使用反射机制调用方法:
package apiday.reflect;
import java.lang.reflect.Method;
import java.util.Scanner;
/**
* 使用反射机制调用方法:
* (1)Object invoke(Object obj,Object... args)在具有指定参数的指定对象上调用此 Method 对象表示的基础方法
*/
public class ReflectDemo3 {
public static void main(String[] args) throws Exception {
Person p = new Person();
p.sayHello();//张三:hello!
/*
写死:只能改动forName中的包的完全限定名才能调用该类方法:
Class cls = Class.forName("apiday.reflect.Person");
*/
//1实例化
Class cls = Class.forName("apiday.reflect.Person");
//Object obj = new Person();
Object obj = cls.newInstance();
//2调用方法:
//2.1通过类对象获取要调用的方法
Method method = cls.getMethod("sayHello");//获取的是无参的sayHello方法
//2.2通过获取的方法对象来调用该方法
// obj.sayHello() 因为obj指向的是及一个Person对象,因此反射机制可以调用到它的sayHello()
method.invoke(obj);//张三:hello!
/*
写活:通过调用扫描仪在控制台输入一个:包的完全限定名即可
Class c = Class.forName(className);
*/
Scanner scanner = new Scanner(System.in);
System.out.println("请输入类名:");
String className = scanner.nextLine();//输入:apiday.reflect.Person
System.out.println("请输入方法名:");
String methodName = scanner.nextLine();//输入:sayHello
Class c = Class.forName(className);
Object o1 = c.newInstance();
//2调用方法
//2.1通过类对象获取要调用的方法 :仅传入方法名时,是获取该无参方法
Method m1 = cls.getMethod(methodName);//获取的是无参的sayHello方法
//2.2通过上边(2.1中)获取的方法对象来调用该方法
m1.invoke(o1);//张三:hello!
}
}
04.自动调用Person类中所有【无参 或 有参】且方法名中含有"***"的方法
package apiday.reflect;
import java.lang.reflect.Method;
/**
* 自动调用api.reflect.Person类中所有【无参 或 有参】且方法名中含有"***"的方法
*
* 01.自动调用api.reflect.Person类中所有【无参】且方法名中含有"say"的方法
* 提示:
* Method[] getDeclaredMethods():获取声明的方法
* int parameterCount():Method类上定义的方法:该方法可以返回当前Method对象表示的方法的参数个数
* 步骤:
* (1)先实例化
* (2)获取所有方法
*
* 02.自动调用api.reflect.Person类中所有【有参】且方法名中含有"doSomeThing"的方法
* 步骤:
* (1)先实例化
* (2)①获取Person类中 参数类型为String的 dosomeThing()方法
* ②获取Person类中 参数类型为String和int的 dosomeThing()方法
*/
public class Test2 {
public static void main(String[] args) throws Exception {
/** 01.自动调用api.reflect.Person类中所有【无参】且方法名中含有say的方法 */
/* 步骤:(1)先实例化 */
Class cls = Class.forName("apiday.reflect.Person");
Object obj = cls.newInstance();
/* (2)获取所有方法 */
//Method[] getDeclaredMethods():获取声明的方法
Method[] methods = cls.getDeclaredMethods();
for(Method m : methods){
//若方法名中含有“say” 且 当前方法对象表示的方法的参数个数为0(即无参)
if(m.getName().contains("say") && m.getParameterCount()==0){
System.out.println("自动调用方法:"+m.getName());
m.invoke(obj);
/*
控制台输出:
自动调用方法:sayHello
张三:hello!
自动调用方法:sayHi
张三:Hi!
*/
}
}
System.out.println("");
/** 01.自动调用api.reflect.Person类中所有【无参】且方法名中含有"doSomeThing"的方法 */
/* 步骤:(1)先实例化 */
Class cls2 = Class.forName("apiday.reflect.Person");
Object obj2 = cls2.newInstance();
/* (2)①获取Person类中 参数类型为String的 dosomeThing()方法 */
//dosomeThing(String)
Method method2 = cls2.getMethod("doSomeThing", String.class);
// Object invoke(Object obj,Object... args):在具有指定参数的指定对象上调用此 Method 对象表示的基础方法。
method2.invoke(obj2,"玩游戏");//p.dosomeThing("玩游戏");
/* 控制台输出:【张三正在做玩游戏】 */
/* (2)②获取Person类中 参数类型为String和int的 dosomeThing()方法 */
Method method3 = cls2.getMethod("doSomeThing", String.class, int.class);
method3.invoke(obj2,"写作业",5);//p.dosomeThing("写作业",5);
/*
控制台输出:
张三正在写作业0次
张三正在写作业1次
张三正在写作业2次
张三正在写作业3次
张三正在写作业4次
*/
}
}
05.调用有参方法 和 强行打开私有方法访问权限:
package apiday.reflect;
import java.lang.reflect.Method;
/**
* 调用有参方法 和 强行打开私有方法访问权限:
* (1)forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
*
* (2)类对象提供了newInstance():可以调用无参【new Person();】且公开的构造器实例化
*
* (3)getMethod(方法名,参数类型列表)/getMethods():它们都是获取Class所表示的类的所有公开方法,包含从超类继承的
*
* (4)getDeclaredMethod(),getDeclaredMethods():这两个方法获取的都是Class所表示的类中当前类自身定义的方法。包含私有方法
*
* (5)Object invoke(Object obj,Object... args)在具有指定参数的指定对象上调用此 Method 对象表示的基础方法
*
* (6)setAccessible(boolean):将此对象的可访问标志设置为指示的布尔值。
* 值为:true表示反射对象在使用时应禁止 Java 语言访问检查。
* 值为:false表示反射对象应该强制执行 Java 语言访问检查。
*/
public class ReflectDemo4 {
public static void main(String[] args) throws Exception {
// Person p = new Person();
// p.dosome();
Class cls = Class.forName("apiday.reflect.Person");
Object obj = cls.newInstance();
/*
getMethod(),getMethods()
它们都是获取Class所表示的类的所有公开方法,包含从超类继承的
getDeclaredMethod(),getDeclaredMethods()
这两个方法获取的都是Class所表示的类中当前类自身定义的方法。包含私有方法
*/
// Method[] methods = cls.getDeclaredMethods();
// for(Method method : methods){
// System.out.println(method.getName());
// }
System.out.println("");
/** 强行打开私有方法访问权限 */
/* 在Person中再写一个私有方法 dosome()做测试: */
Method method = cls.getDeclaredMethod("dosome");
method.setAccessible(true);//强行打开dosome方法的访问权限
method.invoke(obj);//p.dosome()
/* 控制台输出:【我是Person的私有方法dosome()!!!!】 */
}
}
06.JDK 5之后推出了一个特性:变长参数
package apiday.reflect;
import java.util.Arrays;
/**
* JDK 5之后推出了一个特性:变长参数
* 该特性用于适应那些传入参数的个数不固定的使用场景,使得使用一个方法就可以解决该问题,而无需穷尽
* 所有参数个数组合的重载
*
*/
public class ArgDemo {
public static void main(String[] args) {
dosome(1,"one");
dosome(1,"one","two");
dosome(1,"one","three");
dosome(1,"one","three","four");
}
/*
一个方法里只能有一个变长参数,且必须是最后一个参数
*/
private static void dosome(int a, String... arg) {
System.out.println("arg的长度为:"+arg.length);
//在数组调用toString把数字转为字符串:
System.out.println(Arrays.toString(arg));
}
}
07.在本类中自动调用本包中自己定义的无参的公开方法:
package apiday.reflect;
import java.io.File;
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
import java.net.URISyntaxException;
/**
* 在本类中自动调用本包中自己定义的无参的公开方法:
*
* 此案例:自动调用与当前类ReflectDemo5所在同一个包中:
*
* 自动调用本类自己定义的无参的公开方法:
* 具体步骤:
* (0)查找具有给定名称(".")的资源。
* (1)通过当前类ReflectDemo5的类对象获取所在的包名:
* (2)获取ReflectDemo5.class文件所在的目录中所有.class文件:
* ①获取字节码文件的文件名:
* ②由于java命名要求:文件名必须与类名一致,所有我们可以通过文件名得知该字节码文件中保存的类的名
* ③获取加载该类的类对象:
* ④通过类对象获取本类定义的所有方法:
* ⑤遍历每个方法,检查哪个方法是无参的:
*
* 所用到的API:
* (1)①Package getPackage():获取此类的包。
* ②String getName():返回此抽象路径名表示的文件或目录的名称。
* ||
* ③getPackage().getName():获取此类的包的名字。
*
* (2)getResource(String name):查找具有给定名称的资源。
*
* (3)toURI():返回与此URL等效的URI。此方法的功能与new URI(this.toString())相同。
*
* (4)boolean endsWith(String suffix):测试此字符串是否以指定的后缀结尾。 注:suffix:后缀
*
* (5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)
*
* (6)forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
* (7)类对象提供了newInstance():可以调用无参【new Person();】且公开的构造器实例化
* (8)getDeclaredMethod(),getDeclaredMethods():这两个方法获取的都是Class所表示的类中当前类自身定义的方法。包含私有方法
* (9)int parameterCount():Method类上定义的方法:该方法可以返回当前Method对象表示的方法的参数个数
* (10)int getModifiers():返回此对象表示的可执行文件的 Java 语言修饰符。
* (11)Object invoke(Object obj,Object... args):在具有指定参数的指定对象上调用此Method对象表示的基础方法
*
*/
public class ReflectDemo5 {
/*
* main方法上的参数String[] args的作用:
* 在dos窗口命令行上使用java命令指定当前类时,可以传递参数进来,此时会被main上的String[] args接收
*
* 例如: 在dos窗口的命令行中:
* java ReflectDemo7 arg1 arg2 arg3
* main方法执行后,args数组就有三个元素,对应的就是"arg1","arg2","arg3"
*
*/
public static void main(String[] args) throws Exception {
/** 两个开发中常用的相对路径: */
/** 1 这里的当前目录表示的是当前ReflectDemo5这个类所在最外层包的上一级目录 */
// File dir = new File(ReflectDemo5.class.getClassLoader().getResource(".").toURI());
// System.out.println(dir);//F:\danei\softone\Java\CGB2202\out\production\CGB2202
/** 2 这里的当前目录就是当前类所在的目录 */
//(0)查找具有给定名称(".")的资源。
File dir = new File(ReflectDemo5.class.getResource(".").toURI());
System.out.println(dir);//F:\danei\softone\Java\CGB2202\out\production\CGB2202\apiday\reflect
//(1)通过当前类ReflectDemo5的类对象获取所在的包名:
String packageName = ReflectDemo5.class.getPackage().getName();
System.out.println("ReflectDemo5类的包名是:"+packageName);//ReflectDemo5类的包名是:apiday.reflect
//(2)获取ReflectDemo5.class文件所在的目录中所有.class文件:
File[] subs = dir.listFiles(f->f.getName().endsWith(".class"));
for(File sub : subs){
System.out.println("");
//①获取字节码文件的文件名:
String fileName = sub.getName();
// System.out.println("文件名:"+fileName);
//②由于java命名要求:文件名必须与类名一致,所有我们可以通过文件名得知该字节码文件中保存的类的名
String className = fileName.substring(0,fileName.indexOf("."));
// System.out.println("类名:"+className);
//③获取加载该类的类对象:
Class cls = Class.forName(packageName+"."+className);
Object obj = cls.newInstance();
// System.out.println("加载的类为:"+cls.getName());
//④通过类对象获取本类定义的所有方法:
Method[] methods = cls.getDeclaredMethods();
//⑤遍历每个方法,检查哪个方法是无参的:
for(Method method : methods){
if(method.getParameterCount()==0 && method.getModifiers() == Modifier.PUBLIC){
System.out.println("自动调用"+className+"的方法:"+method.getName());
method.invoke(obj);
}
}
}
}
}
3、反射常用API之:注解(在某个类的上一行加上注解以此指定目标类搜索)
01.在[类上]查看注解:
(1)注解可以在什么上用?
创建注解并命名为AutoRunClass:
创建类的时候,点击键盘下箭头选择:【Annotation】,命名为【AutoRunClass】类!
注解:————>@:该注解是用来标注那些可以被反射机制自动调用的类
01.概述:①在开发中常被我们利用到反射机制中,辅助反射机制做更多灵活的操作
②注解在如今JAVA流行的框架中被大量的应用,简化了以前繁琐的配置工作。
02.注解可以在什么上用:————>可以在注解上用(在注解上还会有一些内置的注解)、类上用、属性上用、构造器上用、参数上、方法上用!
定义注解时,我们通常会使用java内置的两个注解来加以修饰当前注解:
(1)@Target注解: 用于表示当前注解可以被应用的位置,可选项都定义在ElementType上。
常见的有:
例1:@Target(ElementType.TYPE)——————>注解只能被用于类上
例2:@Target(ElementType.FIELD)—————>注解只能被用于属性上
例3:@Target(ElementType.METHOD)————>注解只能被用于方法上
例4:@Target({ElementType.TYPE,ElementType.CONSTRUCTOR})————>注解只能被用于
当可以用于多个位置时,需要定义成数组的方式包含所有ElementType的值,即"{}"包含
(2)@Retention注解:用于标注当前注解的保留级别,有三个选项:
①@Retention(RetentionPolicy.SOURCE)————>注解仅保留在源代码中
②@Retention(RetentionPolicy.CLASS)—————>注解保留在字节码中,但是反射机制不能被调用
③@Retention(RetentionPolicy.RUNTIME)———>注解保留在字节码文件中,并且可以被反射机制所使用
注:当不指定@Retention时,默认的保留级别为CLASS,因此我们通常都需要明确指出保留级别为RUNTIME
package apiday.reflect.annotations;
import javax.xml.bind.Element;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 创建注解并命名为AutoRunClass:
* 创建类的时候,点击键盘下箭头选择:【Annotation】,命名为【AutoRunClass】类!
*
* 注解:————>@:该注解是用来标注那些可以被反射机制自动调用的类
* 01.概述:①在开发中常被我们利用到反射机制中,辅助反射机制做更多灵活的操作
* ②注解在如今JAVA流行的框架中被大量的应用,简化了以前繁琐的配置工作。
*
* 02.注解可以在什么上用:————>可以在注解上用(在注解上还会有一些内置的注解)、类上用、属性上用、构造器上用、参数上、方法上用!
*
* 定义注解时,我们通常会使用java内置的两个注解来加以修饰当前注解:
* (1)@Target注解: 用于表示当前注解可以被应用的位置,可选项都定义在ElementType上。
* 常见的有:
* 例1:@Target(ElementType.TYPE)——————>注解只能被用于类上
* 例2:@Target(ElementType.FIELD)—————>注解只能被用于属性上
* 例3:@Target(ElementType.METHOD)————>注解只能被用于方法上
* 例4:@Target({ElementType.TYPE,ElementType.CONSTRUCTOR})————>注解只能被用于类上或方法上
* 当可以用于多个位置时,需要定义成数组的方式包含所有ElementType的值,即"{}"包含
*
* (2)@Retention注解:用于标注当前注解的保留级别,有三个选项:
* ①@Retention(RetentionPolicy.SOURCE)————>注解仅保留在源代码中
* ②@Retention(RetentionPolicy.CLASS)—————>注解保留在字节码中,但是反射机制不能被调用
* ③@Retention(RetentionPolicy.RUNTIME)———>注解保留在字节码文件中,并且可以被反射机制所使用
* 注:当不指定@Retention时,默认的保留级别为CLASS,因此我们通常都需要明确指出保留级别为RUNTIME
*
*
*/
@Target({ElementType.TYPE,ElementType.CONSTRUCTOR})
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoRunClass {
}
(2)反射机制中查看类对象所表示的类是否被注解标注了
反射机制中查看类对象所表示的类是否被注解标注了:
01.相关API:
(0)Class.forName(String className)
:使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
(0)String getName():获取当前类对象所表示的类的完全限定名
(1)boolean isAnnotationPresent():
:如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
package apiday.reflect.annotations;
/**
* 反射机制中查看类对象所表示的类是否被注解标注了:
* 01.相关API:
* (0)Class.forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
* (0)String getName():获取当前类对象所表示的类的完全限定名
*
* (1)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
*
* 步骤:
* (1)在Person类上添加注解:@AutoRunClass
* (2)测试哪个类有无添加该注解?
*/
public class ReflectDemo6 {
public static void main(String[] args) throws Exception {
/** 判断一个类是否有被@AutoRunClass标注 */
// Class cls = Class.forName("apiday.reflect.Person");
Class cls = Class.forName("apiday.reflect.ReflectDemo1");
//判断当前类对象所表示的类是否被 @AutoRunClass标注了?
boolean tf = cls.isAnnotationPresent(AutoRunClass.class);
System.out.println(tf);
if(tf){
System.out.println(cls.getName()+":被注解(@AutoRunClass)标注了");
/* 测试"apiday.reflect.Person",则控制台输出:[apiday.reflect.Person:被注解(@AutoRunClass)标注了] */
}else{
System.out.println(cls.getName()+":没有被注解(@AutoRunClass)标注");
/* 测试"apiday.reflect.ReflectDemo1",则控制台输出:[apiday.reflect.ReflectDemo1:没有被注解(@AutoRunClass)标注] */
}
}
}
(3)自动实例化与当前类(Test3)在同一包中被@AutoRunClass标注的类:
(1)getResource(String name):查找具有给定名称的资源。
(2)toURI():返回与此URL等效的URI。此方法的功能与new URI(this.toString())相同。
(3)getPackage().getName():getPackage().getName():获取此类的包的名字。
(4)boolean endsWith(String suffix):测试此字符串是否以指定的后缀结尾。 注:suffix:后缀
(5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)
(6)int ①indexOf(String str):检索给定字符串在当前字符串的开始位置--------根据字符串找位置
(7)Class.forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
(8)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
(9)类对象提供了newInstance():可以调用无参【new Person();】且公开的构造器实例化;
如果尚未初始化该类,则将其初始化。
package apiday.reflect.annotations;
import java.io.File;
/**
* 自动实例化与当前类Test3在同一包中被@AutoRunClass标注的类:
* 01.相关API:
* (1)getResource(String name):查找具有给定名称的资源。
* (2)toURI():返回与此URL等效的URI。此方法的功能与new URI(this.toString())相同。
* (3)getPackage().getName():getPackage().getName():获取此类的包的名字。
* (4)boolean endsWith(String suffix):测试此字符串是否以指定的后缀结尾。 注:suffix:后缀
* (5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)
* (6)int ①indexOf(String str):检索给定字符串在当前字符串的开始位置--------根据字符串找位置
*
* (7)Class.forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
* (8)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
* (9)类对象提供了newInstance():可以调用无参【new Person();】且公开的构造器实例化;如果尚未初始化该类,则将其初始化。
*
*/
public class Test3 {
public static void main(String[] args) throws Exception {
/** 01.自动实例化与当前类Test3在同一包中被@AutoRunClass标注的类: */
File dir = new File(
Test3.class.getResource(".").toURI()
);
//通过当前类Test3的类对象获取所在的包名
String packageName = Test3.class.getPackage().getName();
//获取Test3.class文件所在的目录中所有.class文件
File[] subs = dir.listFiles(f->f.getName().endsWith(".class"));
for(File sub : subs) {
//获取字节码文件的文件名
String fileName = sub.getName();
String className = fileName.substring(0, fileName.indexOf("."));
//加载该类的类对象
Class cls = Class.forName(packageName + "." + className);
if(cls.isAnnotationPresent(AutoRunClass.class)){
System.out.println("实例化:"+className);
Object o = cls.newInstance();
}
}
}
}
02.在[类中的方法上]查看注解:
package apiday.reflect.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 在Person类中:把三个无参方法(sayHello/sayHi/watchTV)
* 和
* Student类中:把无参方法(study)
* 都加上【@AutoRunMethod】
*
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoRunMethod {
}
(1)反射机制中查看类对象所表示的方法是否被注解标注了:
反射机制中查看类对象所表示的方法是否被注解标注了:
除了类对象Class之外,
像方法对象Method、属性对象Field等都有该方法,用于判断其表示的内容是否被某个注解标注了
01.相关API:
(0)Class.forName(String className)
:使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
(1)Method[] getDeclaredMethods():
:返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
(2)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
(3)String getName():获取当前类对象所表示的类的完全限定名
步骤:(1)在【Person类中:把三个无参方法(sayHello/sayHi/watchTV)】
和【Student类中:把无参方法(study)】
————>都加上【@AutoRunMethod】
(2)测试Person类中哪个方法被@AutoRunClass标注了
package apiday.reflect.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 在Person类中:把三个无参方法(sayHello/sayHi/watchTV)
* 和
* Student类中:把无参方法(study)
* 都加上【@AutoRunMethod】
*
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoRunMethod {
}
package apiday.reflect.annotations;
import java.lang.reflect.Method;
/**
* 反射机制中查看类对象所表示的方法是否被注解标注了:
*
* 除了类对象Class之外,
* 像方法对象Method、属性对象Field等都有该方法,用于判断其表示的内容是否被某个注解标注了
*
* 01.相关API:
* (0)Class.forName(String className)
* :使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
*
* (1)Method[] getDeclaredMethods():
* :返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
* 包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
*
* (2)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
* (3)String getName():获取当前类对象所表示的类的完全限定名
*
*
* 步骤:(1)在【Person类中:把三个无参方法(sayHello/sayHi/watchTV)】
* 和【Student类中:把无参方法(study)】
* ————>都加上【@AutoRunMethod】
* (2)测试Person类中哪个方法被@AutoRunClass标注了
*
*/
public class ReflectDemo7 {
public static void main(String[] args) throws Exception {
/** 判断一个方法是否有被@AutoRunClass标注 */
Class cls = Class.forName("apiday.reflect.Person");
Method[] methods = cls.getDeclaredMethods();
for(Method method : methods){
/*
除了类对象Class之外,像方法对象Method,属性对象Field等都有该方法,
用于判断其表示的内容是否被某个注解标注了
*/
//判断当前类对象所表示的方法是否被 @AutoRunMethod标注了?
if(method.isAnnotationPresent(AutoRunMethod.class)){
System.out.println(method.getName()+":被注解(@AutoRunMethod)标注了");
}else{
System.out.println(method.getName()+":没有被注解(@AutoRunMethod)标注");
}
/*
控制台输出:
toString:没有被注解(@AutoRunMethod)标注
sing:没有被注解(@AutoRunMethod)标注
watchTV:被注解(@AutoRunMethod)标注了
sayHi:被注解(@AutoRunMethod)标注了
doSomeThing:没有被注解(@AutoRunMethod)标注
doSomeThing:没有被注解(@AutoRunMethod)标注
dosome:没有被注解(@AutoRunMethod)标注
sayHello:被注解(@AutoRunMethod)标注了
*/
}
}
}
(2)自动调用与当前类(Test4)在同一个包中被@AutoRunClass标注的类中所有被@AutoRunMethod标注的方法
01.相关API:
(1)getResource(String name):查找具有给定名称的资源。
(2)toURI():返回与此URL等效的URI。此方法的功能与new URI(this.toString())相同。
(3)getPackage().getName():getPackage().getName():获取此类的包的名字。
(4)boolean endsWith(String suffix):测试此字符串是否以指定的后缀结尾。 注:suffix:后缀
(5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)
(6)int ①indexOf(String str):检索给定字符串在当前字符串的开始位置--------根据字符串找位置
(7)Class.forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
(8)boolean isAnnotationPresent()
:如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
(9)类对象提供了newInstance()
:可以调用无参【new Person();】且公开的构造器实例化;如果尚未初始化该类,则将其初始化。
(10)Method[] getDeclaredMethods()
:返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
(11)Object invoke(Object obj,Object... args)
:在具有指定参数的指定对象上调用此 Method 对象表示的基础方法
package apiday.reflect.annotations;
import java.io.File;
import java.lang.reflect.Method;
/**
* 自动调用与当前类(Test4)在同一个包中哪些被@AutoRunClass标注的类中所有被@AutoRunMethod标注的方法:
*
* 01.相关API:
* (1)getResource(String name):查找具有给定名称的资源。
* (2)toURI():返回与此URL等效的URI。此方法的功能与new URI(this.toString())相同。
* (3)getPackage().getName():getPackage().getName():获取此类的包的名字。
* (4)boolean endsWith(String suffix):测试此字符串是否以指定的后缀结尾。 注:suffix:后缀
* (5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)
* (6)int ①indexOf(String str):检索给定字符串在当前字符串的开始位置--------根据字符串找位置
*
* (7)Class.forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
*
* (8)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
*
* (9)类对象提供了newInstance():可以调用无参【new Person();】且公开的构造器实例化;如果尚未初始化该类,则将其初始化。
*
* (10)Method[] getDeclaredMethods():返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
* 包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
*
* (11)Object invoke(Object obj,Object... args)在具有指定参数的指定对象上调用此 Method 对象表示的基础方法
*/
public class ReflectDemo7Test4 {
public static void main(String[] args) throws Exception {
File dir = new File(
ReflectDemo7Test4.class.getResource(".").toURI()
);
//通过当前类Test3的类对象获取所在的包名
String packageName = ReflectDemo7Test4.class.getPackage().getName();
//获取Test3.class文件所在的目录中所有.class文件
File[] subs = dir.listFiles(f->f.getName().endsWith(".class"));
for(File sub : subs) {
//获取字节码文件的文件名
String fileName = sub.getName();
String className = fileName.substring(0, fileName.indexOf("."));
//加载该类的类对象
Class cls = Class.forName(packageName + "." + className);
if(cls.isAnnotationPresent(AutoRunClass.class)){
Object o = cls.newInstance();
//获取该类定义的所有方法
Method[] methods = cls.getDeclaredMethods();
for(Method method : methods){
if(method.isAnnotationPresent(AutoRunMethod.class)){
System.out.println("自动调用"+className+"类的方法:"+method.getName());
method.invoke(o);
}
/*
控制台输出:
自动调用Student类的方法:study
Student:good good study!day day up!
*/
}
}
}
}
}
03.在[类中的方法的参数上]定义注解:
(1)在方法注解类中定义参数时需要在关联类中的方法上也传参
注解可以定义方法的参数:————>在方法注解类中定义参数,需要在关联类中的方法上也传参
【定义参数的格式为:类型 参数名() [default 默认值];】
【使用注解传参时格式:@注解名(参数名1=参数值1[,参数名2=参数值2,....])】
例1:若在注解(AutoRunMethod)类中定义参数: int value() default 1;
则在Person类上的注解:———————————————>@AutoRunMethod(1)————>必须要传参。否则报错
!(1)default可选,用于为当前参数定义默认值。如果不指定(相关联的类会报错),则使用注解时必须为次参数赋值。
!(2)如果default指定了默认值,则可以不指定参数,此时注解中参数的使用default的默认值
例2:若在注解类(AutoRunMethod)中定义参数: int num();
则在Person类上的注解:———————————————>@AutoRunMethod(num=1)————>除了value不需要写成:valu
!(3):如果注解类中只有一个参数且参数名为num时(int num();),那么使用时格式如下:@AutoRunMethod(num=1)
例3:若在注解类(AutoRunMethod)中定义参数: int value();
则在Person类上的注解:———————————————>@AutoRunMethod(1)
!(4)如果注解中只有一个参数,参数名建议选取value,这样的好处是:使用时可以不指定参数名。
package apiday.reflect.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
*
* 注解可以定义参数:————>在注解中定义参数,需要在关联类中的方法上也传参
* 【定义参数的格式为:类型 参数名() [default 默认值];】
* 【使用注解传参时格式:@注解名(参数名1=参数值1[,参数名2=参数值2,....])】
*
* 例1:若在注解(AutoRunMethod)类中定义参数: int value() default 1;
* 则在Person类上的注解:———————————————>@AutoRunMethod(1)————>必须要传参。否则报错
* !(1)default可选,用于为当前参数定义默认值。如果不指定(相关联的类会报错),则使用注解时必须为次参数赋值。
* !(2)如果default指定了默认值,则可以不指定参数,此时注解中参数的使用default的默认值
*
* 例2:若在注解类(AutoRunMethod)中定义参数: int num();
* 则在Person类上的注解:———————————————>@AutoRunMethod(num=1)————>除了value不需要写成:value=1 其余都要写!
* !(3):如果注解类中只有一个参数且参数名为num时(int num();),那么使用时格式如下:@AutoRunMethod(num=1)
*
* 例3:若在注解类(AutoRunMethod)中定义参数: int value();
* 则在Person类上的注解:———————————————>@AutoRunMethod(1)
* !(4)如果注解中只有一个参数,参数名建议选取value,这样的好处是:使用时可以不指定参数名。
*
*
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoRunMethod {
/*
定义参数的格式为:
格式:类型 参数名() [default 默认值]
注:default可选,用于为当前参数定义默认值。如果不指定,则使用注解时必须为此参数赋值。
使用注解传参时格式:
@注解名(参数名1=参数值1[,参数名2=参数值2,....])
如果注解@AutoRunMethod只有一个参数,且参数名为num时,那么使用时格式如下:
@AutoRunMethod(num=1)
=============重点=============
如果注解中只有一个参数,参数名建议选取value,这样的好处是,使用时可以不指定参数名,如:
@AutoRunMethod(1)
如果指定了默认值,则可以不指定参数,例如:
@AutoRunMethod() 此时注解中参数的使用default的默认值
*/
//格式: 类型 参数名() [default 默认值];
//int num() default 1;//一个参数时,参数名不建议选取value以外的名字。
int value() default 1;
}
(2)在反射机制中获取注解的参数:
01.相关API:
(0)Class.forName(String className)
:使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
(1)Method[] getDeclaredMethods():
:返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
(2)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
(3)getAnnotation():如果存在这样的注释,则返回此元素的指定类型的注释,否则返回 null。
(4)String getName():获取当前类对象所表示的类的完全限定名
package apiday.reflect.annotations;
import java.lang.reflect.Method;
/**
* 在反射机制中获取注解的参数:
* 01.相关API:
* (0)Class.forName(String className)
* :使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
*
* (1)Method[] getDeclaredMethods():
* :返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
* 包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
*
* (2)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
* (3)getAnnotation():如果存在这样的注释,则返回此元素的指定类型的注释,否则返回 null。
* (4)String getName():获取当前类对象所表示的类的完全限定名
*
*/
public class ReflectDemo8 {
public static void main(String[] args) throws ClassNotFoundException {
Class cls = Class.forName("apiday.reflect.Person");
Method[] methods = cls.getDeclaredMethods();
for(Method method : methods){
//判断该方法是否被注解@AutoRunMethod标注了
if(method.isAnnotationPresent(AutoRunMethod.class)){
//通过方法对象获取该注解
AutoRunMethod arm = method.getAnnotation(AutoRunMethod.class);
int value = arm.value();
System.out.println("方法"+method.getName()+ "上的注解AutoRunMethod指定的参数值为:"+value);
}
/*
控制台输出:
方法sayHi上的注解AutoRunMethod指定的参数值为:1
方法watchTV上的注解AutoRunMethod指定的参数值为:1
方法sayHello上的注解AutoRunMethod指定的参数值为:5
*/
}
}
}
(3)自动调用与当前类(Test5)在同一个包中:那些被@AutoRunClass标注的类中:所有被@AutoRunMethod标注的方法n次
01.相关API:
(1)getResource(String name):查找具有给定名称的资源。
(2)toURI():返回与此URL等效的URI。此方法的功能与new URI(this.toString())相同。
(3)getPackage().getName():getPackage().getName():获取此类的包的名字。
(4)boolean endsWith(String suffix):测试此字符串是否以指定的后缀结尾。 注:suffix:后缀
(5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)
(6)int ①indexOf(String str):检索给定字符串在当前字符串的开始位置--------根据字符串找位置
(7)Class.forName(String className)
使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
(8)boolean isAnnotationPresent()
:如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
(9)类对象提供了newInstance()
:可以调用无参【new Person();】且公开的构造器实例化;如果尚未初始化该类,则将其初始化。
(10)Method[] getDeclaredMethods()
:返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
(11)getAnnotation():如果存在这样的注释,则返回此元素的指定类型的注释,否则返回 null。
(12)定义参数的格式为:类型 参数名() [default 默认值];
(13)Object invoke(Object obj,Object... args)
:在具有指定参数的指定对象上调用此 Method 对象表示的基础方法
package apiday.reflect.annotations;
import java.io.File;
import java.lang.reflect.Method;
import java.net.URISyntaxException;
/**
* 自动调用与当前类(Test5)在同一个包中:那些被@AutoRunClass标注的类中:所有被@AutoRunMethod标注的方法n次
* 注:n对应的是:注解@AutoRunMethod传入的参数值
*
* 01.相关API:
* (1)getResource(String name):查找具有给定名称的资源。
* (2)toURI():返回与此URL等效的URI。此方法的功能与new URI(this.toString())相同。
* (3)getPackage().getName():getPackage().getName():获取此类的包的名字。
* (4)boolean endsWith(String suffix):测试此字符串是否以指定的后缀结尾。 注:suffix:后缀
* (5)String substring(int start,int end):截取当前字符串中指定范围内的字符串(含头不含尾–包含start,但不包含end)
* (6)int ①indexOf(String str):检索给定字符串在当前字符串的开始位置--------根据字符串找位置
* (7)Class.forName(String className)————>使用Class的静态方法forName传入【要加载的类的完全限定名(包名.类名)】
* (8)boolean isAnnotationPresent():如果此元素上存在指定类型的注释,则返回 true,否则返回 false。
* (9)类对象提供了newInstance():可以调用无参【new Person();】且公开的构造器实例化;如果尚未初始化该类,则将其初始化。
* (10)Method[] getDeclaredMethods():返回一个包含Method对象的数组。该对象反映了此Class对象表示的类或接口的所有声明方法,
* 包括公共、受保护、默认(包)访问和私有方法(但不包括继承方法)。
*
* (11)getAnnotation():如果存在这样的注释,则返回此元素的指定类型的注释,否则返回 null。
* (12)定义参数的格式为:类型 参数名() [default 默认值];
* (13)Object invoke(Object obj,Object... args)在具有指定参数的指定对象上调用此 Method 对象表示的基础方法
*
*/
public class ReflectDemo8Test5 {
public static void main(String[] args) throws Exception {
File dir = new File(
ReflectDemo8Test5.class.getResource(".").toURI()
);
//通过当前类Test3的类对象获取所在的包名
String packageName = ReflectDemo8Test5.class.getPackage().getName();
//获取Test3.class文件所在的目录中所有.class文件
File[] subs = dir.listFiles(f->f.getName().endsWith(".class"));
for(File sub : subs) {
//获取字节码文件的文件名
String fileName = sub.getName();
String className = fileName.substring(0, fileName.indexOf("."));
//加载该类的类对象
Class cls = Class.forName(packageName + "." + className);
if(cls.isAnnotationPresent(AutoRunClass.class)){
Object o = cls.newInstance();
//获取该类定义的所有方法
Method[] methods = cls.getDeclaredMethods();
for(Method method : methods){
if(method.isAnnotationPresent(AutoRunMethod.class)){