震惊!| EfficientFormerV2:Transformer居然还能比MobileNet还快更准!
2023
点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院

计算机视觉研究院专栏
作者:Edison_G
这篇论文讨论了在计算机视觉任务中使用 Vision Transformer(ViT)的情况下,如何优化ViT的性能和复杂度,使其能够在移动设备上运行。论文提出了多种方法来加速注意力机制,改善低效的设计,或者将移动设备友好的轻量级卷积结合在一起形成混合架构。
学习群|扫码在主页获取加入方式

论文链接:
https://arxiv.org/pdf/2212.08059.pdf
代码链接:
https://github.com/snap-research/EfficientFormer
导读

然而,即使是几年前的 MobileNet,ViT 及其变体仍然具有更高的延迟或更多的参数。在实际应用中,延迟和大小对于在资源受限的硬件上运行都是至关重要的。在这项工作中,我们研究了一个核心问题:Transformer 模型是否可以像 MobileNet 一样快速运行,并保持相似的大小? 我们重新检查ViT的设计选择,并提出了一个具有低延迟和高参数效率的改进型超网络。我们进一步引入了一种细粒度的联合搜索策略,可以通过同时优化延迟和参数数量来找到高效的架构。本文所提出的 EfficientFormerV2 模型在 ImageNet-1K 上的 Top-1 精度比 MobileNetV2 和 MobileNetV2×1.4 高出约 4%,同时具有相似的延迟和参数。我们证明,经过适当设计和优化的 Vision Transformer 可以实现 MobileNet 水平的性能,同时具有 MobileNet 水平的大小和速度。
这篇论文的主要贡献:
提出了一种新的超网络设计方法,该方法在维护较高的准确性的同时,可以在移动设备上运行。
提出了一种细粒度的联合搜索策略,该策略可以同时优化延迟和参数数量,从而找到高效的架构。
EfficientFormerV2 模型在 ImageNet-1K 数据集上的准确性比 MobileNetV2 和 MobileNetV2×1.4高出约 4%,同时具有相似的延迟和参数。
背景
为了缓解 Vision Transformer(ViT)在移动设备上运行时存在的局限性,研究人员采取了许多研究努力。其中一个方向是减少注意机制的二次计算复杂度。Swin 等后续工作提出了基于窗口的注意,使感受野被限制在预定义的窗口大小,这也启发了后续工作对注意模式进行改进。通过预定义的注意跨度,计算复杂度变为与分辨率成线性关系。然而,由于密集的形状和索引操作,在移动设备上很难支持或加速复杂的注意模式。另一种方法是将轻量级CNN和注意机制结合在一起形成混合架构。这样做有两个好处。首先,卷积是不变移位的,擅长捕捉局部和详细信息,可以被视为 ViT 的良好补充。其次,通过将卷积放在早期阶段,将 MHSA 放在最后几个阶段以模拟全局依赖关系,我们可以自然地避免在高分辨率上执行 MHSA 并节省计算。Transformer 是一种特殊的神经网络架构,它可以帮助解决序列模型的问题。然而,Transformer 模型往往比较大,并且计算效率也不够高。因此,作者提出了一个问题:是否有可能设计一种基于 Transformer 的模型,既轻巧又能快速运行,同时保留较高的性能?
作者考虑了三个关键因素:参数数量,延迟和模型性能。这些因素反映了磁盘存储,移动 FPS 和应用质量。首先,作者重新审视了最近的有效 ViT 模型,验证并改进网络架构,形成了一个更强的设计范式。其次,作者提出了一种细粒度的架构搜索算法,该算法联合优化模型大小和速度。通过改进的设计和搜索方法,作者在各种模型大小和速度的限制下获得了一系列模型,同时保持了较高的性能,命名为 EfficientFormerV2。在 iPhone 12上,具有完全相同大小和延迟(latency)的 EfficientFormerV2-S0 在 ImageNet-1K 上的 top-1 准确度比 MobileNetV2高出 3.9%。与 EfficientFormer-L1 相比,EfficientFormerV2-S1 的性能相似,同时更小2倍,更快1.3倍。
论文的贡献可以归纳如下:
提供了一个综合研究,旨在验证和改进移动友好的设计选择,这是一个实用的指南,可以获得超高效的Vision Backbone。
提出了一种细粒度的联合搜索算法,可以同时优化模型大小和速度,实现优越的帕累托 (Pareto curve) 最优性。
这种模型具有超快速的推理能力和超小的模型尺寸,在各种下游任务中表现出色,大幅优于之前的技术。
Method
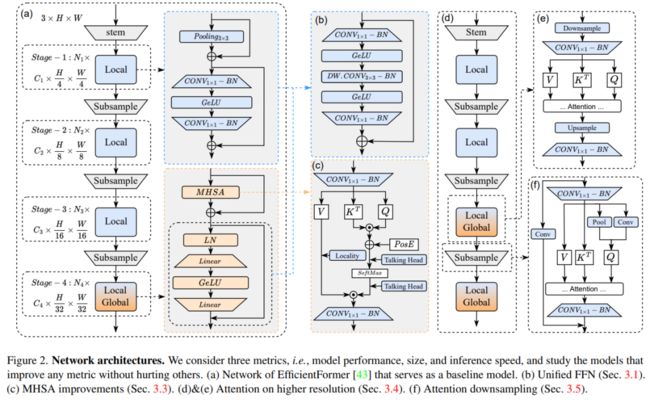
上图展示了EfficientFormerV2模型中多个模块的结构组成细节。
Rethinking Hybrid Transformer Network
研究人员研究了提高 ViTs 效率的设计选择,并确定了导致模型尺寸变小、速度变快而性能不降低的变化。论文中使用了 EfficientFormerL1 作为基准模型,以验证修改的效果,因为它在移动设备上表现出色。
Token Mixers vs. Feed Forward Network
本段讨论了如何在 ViTs 模型中改进性能,使其更加鲁棒,并且能够更好地处理位置信息。文中提到,PoolFormer 和 EfficientFormer 模型使用3×3平均池化层作为局部令牌混合器,将这些层替换为相同内核大小的深度卷积(DWCONV)可以在不增加延迟的情况下提高性能0.6%,且参数增加微不足道(0.02M)。另外,最近的研究表明,在ViTs的前馈网络(FFN)中注入局部信息建模层也有助于提升性能,且开销较小。在FFN中添加深度卷积以捕获局部信息会复制原来的局部混合器(池化或卷积)的功能。因此,他们决定删除显式的残留连接的局部令牌混合器,并将深度卷积移入FFN,从而得到一个带有局部性的统一 FFN。然后,他们将统一 FFN 应用于网络的所有阶段。这种设计修改使得网络架构只有两种类型的块(局部 FFN 和全局注意力),在延迟相同的情况下,提高了准确率至80.3%,且参数增加较少(0.1M)。这种修改方式允许直接搜索网络深度,以确切的模块数量来提取局部和全局信息,特别是在网络的后期阶段。
Search Space Refinement
探究在统一的 FFN 和删除残留连接的令牌混合器的情况下,EfficientFormer 的搜索空间是否仍然足够,特别是在深度方面。研究人员通过改变网络深度(每个阶段中的块数)和宽度(通道数)来进行研究,并发现较深较窄的网络导致更高的准确度(0.2%的改进),更少的参数(0.13M的减少),以及较低的延迟(0.1ms的加速)。因此,我们将这种网络设置为新的基准(准确度80.5%),以验证后续设计修改,后文启用更深的超级网络进行体系结构搜索。
为了进行比较,研究人员将额外的一个阶段添加到当前的基准网络中,并验证性能增益和开销。值得注意的是,尽管在小特征分辨率的情况下计算开销不是问题,但额外的阶段仍然需要大量的参数。因此,我们需要缩小网络维度(深度或宽度),以使参数和延迟与基准模型保持一致,以便进行公平的比较。如后续实验所示,五阶段模型的最佳性能意外地下降到了80.31%,尽管在 MACs(0.12G)方面节省了成本,但参数(0.39M)和延迟开销(0.2ms)增加了。这与我们的直觉相符,即第五阶段在计算效率方面很好,但在参数方面需要很多。考虑到五阶段网络在我们的尺寸和速度范围内无法引入更多的潜力,我们坚持四阶段设计。这项分析也解释了为什么一些ViT在 MACs-Accuracy 方面提供了优秀的帕累托曲
MHSA Improvements
作者探究了两种用于 MHSA 的方法。首先,通过添加深度方向的3 x 3卷积(CONV)将局部信息注入值矩阵(V)。其次,通过在头维度之间添加全连接层,使注意力头之间进行通信。通过这些改进,我们进一步将性能提升至80.8%,至此精度和时延都与 baseline 模型相近。
Attention on Higher Resolution
MHSA 的注意力机制在较高分辨率的特征上的应用可能会导致手机效率降低的问题。作者尝试在较高分辨率的特征(早期阶段)上有效地应用 MHSA,并在测试中发现,在最后一个具有 1/32 空间分辨率的输入图像的阶段中应用 MHSA 可以使准确率提高 0.9%,但是推理速度减慢了 2.7 倍。因此,有必要适当减少注意力模块的复杂度。
现有的方法,即窗口基注意力和下采样键和值,可以解决注意力机制在移动设备上应用时带来的复杂度增加问题,但是作者认为这些方法并不适用于移动设备的部署。窗口基注意力因其复杂的窗口划分和重排难以在移动设备上加速。至于下采样键(K)和值(V),为了保留注意力矩阵相乘后的输出分辨率(Out),需要使用全分辨率查询(Q)。
作者使用了一种名为 "Stride Attention" 的方法来在网络的早期阶段应用 MHSA,从而减少了模型的延迟时间,并在保证准确率的情况下提高了手机的效率。在这种方法中,作者将所有的查询、键和值下采样到固定的空间分辨率(1/32),然后将注意力的输出插值回原始分辨率,以便输入到下一层。根据测试,使用这种方法可以将模型的延迟时间从 3.5ms 降低到 1.5ms,同时准确率仅略有下降(81.5% vs. 81.7%)。
Attention Downsampling
一些视觉后端使用步幅卷积或池化层来执行静态和局部下采样,并构成分层结构的情况。一些最近的工作开始探索注意力下采样。例如,LeViT [22] 和 UniNet [46] 提出通过注意力机制将特征分辨率减半,以便具有全局感受野的上下文感知下采样。具体来说,将查询中的令牌数减半,从而使注意力模块的输出下采样:

作者提出的一种结合本地性和全局依赖的策略,用于在网络的早期阶段应用注意力下采样,从而在保证可接受的推理速度的情况下提高准确率。在这种策略中,作者使用池化作为静态局部下采样,使用 3 × 3 DWCONV 作为可学习的局部下采样,并将结果组合并投影到查询维度。此外,注意力下采样模块与正常的步幅 CONV 进行残差连接,以形成本地-全局的方式,类似于下采样瓶颈或反向瓶颈。根据后续实验所示,使用注意力下采样后,准确率进一步提高到 81.8%,虽然参数和延迟开销略有增加。
EfficientFormerV2
也就是现有的方法仅仅关注于优化一个度量标准(metric),因此要么在大小上是冗余的(redundant in size),要么在推理(inference)时慢。为了找到最适合移动部署的视觉主干(vision backbones),作者提出了联合优化模型大小和速度的方法。此外,文章中提到的网络设计(network designs)偏向于更深的网络架构(deeper network architecture)和更多的注意力(more attentions),因此需要改进搜索空间和算法。在接下来的内容中,作者将介绍 EfficientFormerV2 的超网(supernet)设计和搜索算法。
Design of EfficientFormerV2
作者提到了使用 4 阶分层设计的方法,该方法获得输入分辨率为 {1/4, 1/8, 1/16, 1/32} 的特征大小。EfficientFormerV2 使用小内核卷积模块(small kernel convolution stem)将输入图像嵌入,而不是使用不高效的非重叠块(non-overlapping patches)嵌入。
总的来说就是使用分层设计的方法来获得不同大小的特征。此外,作者还提到了使用小内核卷积模块来嵌入输入图像,而不是使用不高效的嵌入方法。
Jointly Optimizing Model Size and Speed
作者提到了基准网络 EfficientFormer 的两个主要缺陷。首先,搜索过程仅受到速度的限制,导致最终模型参数冗余。其次,它仅搜索每个阶段的深度(块数 Nj)和宽度 Cj,这是一种粗粒度的方式。实际上,网络的大多数计算和参数都在 FFN 中,并且参数和计算复杂度与其扩展率 Ei,j 线性相关。Ei,j 可以独立为每个 FFN 指定,而无需相同。因此,搜索 Ei,j 可以启用更细粒度的搜索空间,其中计算和参数可以在每个阶段内灵活且非均匀分布。这是最近 ViT NAS 中缺失的属性,其中 Ei,j 在每个阶段中保持相同。我们提出了一种搜索算法,该算法启用了灵活的每块配置,并在大小和速度之间进行联合约束,并找到最适合移动设备的视觉主干。
为了解决 EfficientFormer 的缺陷,作者提出了一种搜索算法,该算法允许灵活的每块配置,并在大小和速度之间进行联合约束,以找到最适合移动设备的视觉主干。作者指出,在大多数最近的 ViT NAS 模型中,Ei,j 在每个阶段中保持相同,因此缺少了在每个阶段内计算和参数可以灵活且非均匀分布的能力。作者认为,通过搜索 Ei,j,可以在可以分布灵活且非均匀的搜索空间中找到最优的解决方案。
Search Objective
作者介绍了指导其联合搜索算法的度量标准。由于在评估移动友好型模型时网络的大小和延迟都很重要,因此我们考虑使用一种通用且公平的度量标准,更好地了解网络在移动设备上的性能。为了不损失一般性,我们定义了一个 Mobile Efficiency Score(MES):

MES 度量了网络在移动设备上的效率,它既考虑了网络的速度,也考虑了网络的大小。作者认为,通过使用 MES 这种度量标准,可以更好地找到最适合移动设备的网络。
Search Space and SuperNet
作者讨论了搜索空间的构成。搜索空间包括:(i)网络的深度,用每个阶段的块数 Nj 测量,(ii)网络的宽度,即每个阶段的通道维度 Cj,以及(iii)每个 FFN 的扩展比 Ei,j。MHSA 的数量可以在深度搜索期间轻松确定,它控制超网中块的保留或删除。因此,作者在超网的最后两个阶段中将每个块设置为 MHSA,然后跟随 FFN,并通过深度搜索获得具有所需全局 MHSA 数量的子网络。
作者进一步讨论了超网的构建方式。作者使用了可缩减网络(slimmable network)[78]来构建超网,该网络具有弹性深度和宽度,从而可以执行基于评估的纯搜索算法。弹性深度可以通过随机丢弃路径增强(stochastic drop path augmentation)[32]自然实现。对于宽度和扩展比,我们遵循 Yu 等人[78]的方法构建具有共享权值但独立归一化层的可切换层,使得相应层可以从预定义集合中的不同通道数执行,即 16 或 32 的倍数。
Search Algorithm
作者介绍了在已确定搜索目标、搜索空间和超网的情况下使用的搜索算法。由于超网可以在弹性深度和可切换宽度下执行,因此可以通过分析每次缩减操作的效率收益和精度下降来搜索具有最佳帕累托曲线(Pareto curve)的子网络。作者定义了操作池(action pool)如下:1.每个块的宽度缩减,2. 每个块的深度减少,3. 删除操作池中的块。通过这些操作,作者可以找到一个子网络,其具有最优的帕累托曲线,即在保持精度的同时尽可能降低模型的大小和推理时间。

实验
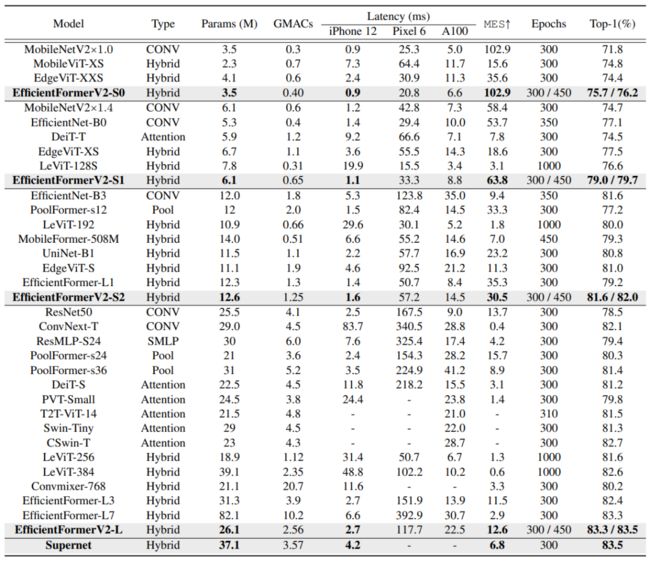
在ImgeNet-1K的分类任务中,对比SOTA模型,EfficientFormerV2在同规模参数下推理速度和精度均取得更优。

在MS COCO 2017的目标检测和实例分割任务中,EfficientFormerV2的AP和mIOU比SOTA模型分别高出3%和2%。

对比上一版本的EfficientFormer,EfficientFormerV2保持模型复杂度不变并取得了更高的精度。

在ImageNet-1K数据集中,EfficientFormerV2在 MES 和 Accuary 两个指标上超越了近几年所有的SOTA模型。


EfficientFormerV2的网络结构以及训练参数,其中训练参数中的drop path中四个数值表示分别用在S0、S1、S2和L网络规模中。
总结
本文深入研究了混合视觉骨干网络并验证了适用于移动设备的设计选择。作者进一步提出了一种针对大小和速度的细粒度联合搜索,并获得了 EfficientFormerV2 模型系列,该模型既轻量又在推理速度上极快。由于本文简单地关注了大小和速度,因此未来的一个方向是将联合优化方法应用于探索其他关键指标(如内存占用和二氧化碳排放)的后续研究中。
END
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、图像分割、模型量化、模型部署等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606
