HashMap扩容resize流程
resize函数触发时机:
1.初始化HashMap的默认扩容一个cap为16 threshold为12的Node
2.当hashMap的size>threshold的时候再次扩容,扩容为16*2的cap,threshold*2的Node
3.当table中Node链表大于8且tab.length小于64的时候,hash再次double扩容
下面直接上流程图
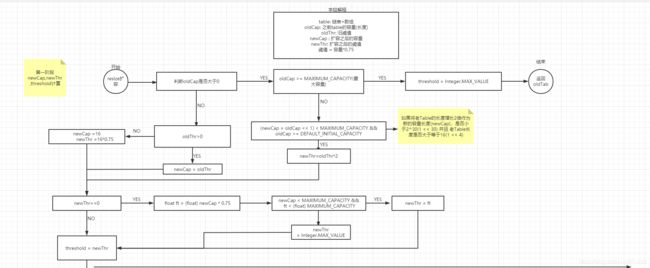
第一阶段:主要为计算出新的newCap(扩容后的容量)和newThr(扩容后阈值)
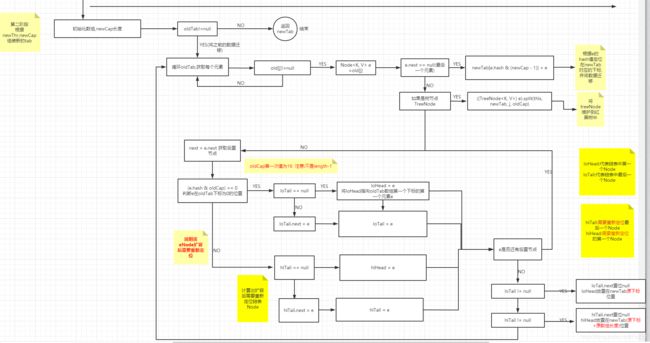
第二阶段: 根据newCap和newThr组装出新的newTab
接下来直接上源码
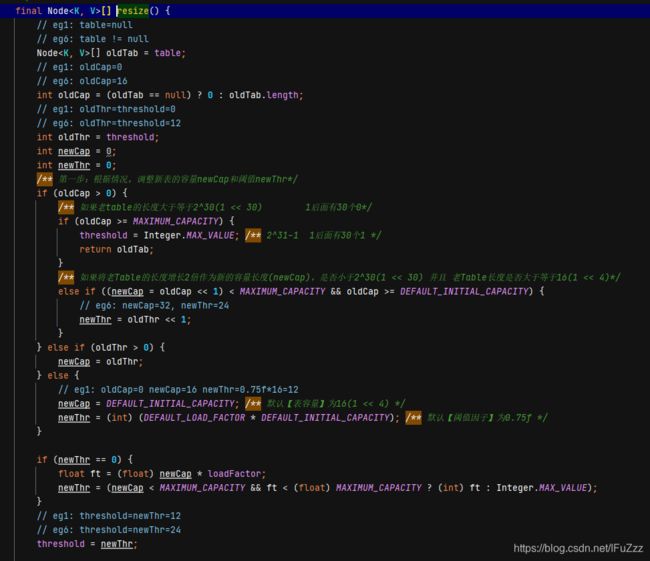
若之前的数据为空,默认初始化一个容量为16 阈值为12
newCap = DEFAULT_INITIAL_CAPACITY; /** 默认【表容量】为16(1 << 4) */
newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
若扩容两倍之后小于最大长度且大于等于初始化的tab(16),cap和thr直接*2
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {
// eg6: newCap=32, newThr=24
newThr = oldThr << 1;
}若oldCap已经达到最大值,直接将最大的tab返回
从以上源码可以看出,第一部分主要是为计算出newCap和newThr
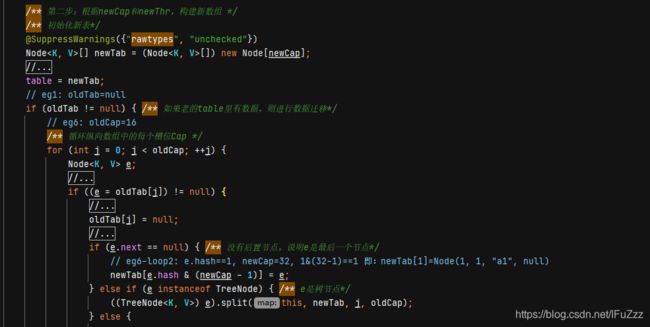
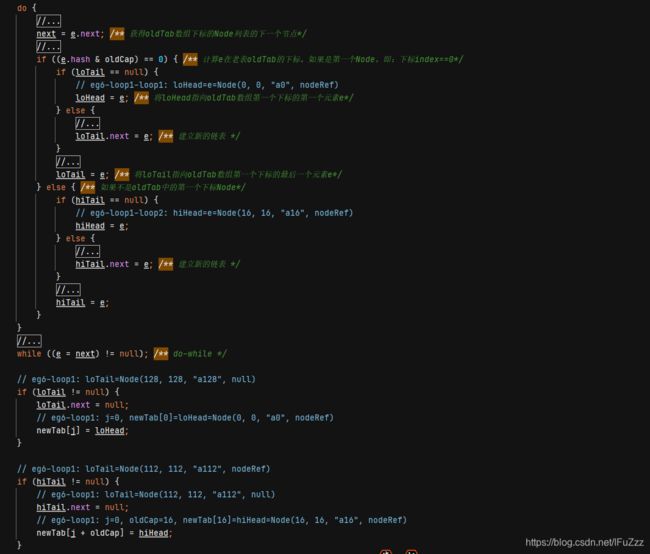
第二阶段:主要是根据newCap和newThr构造出新的newTab
1.组装出一个新的newTab
2.查询oldTab中是否还存在数据,存在数据的需要迁移到newTab
3.若oldTab下标只有一个链表Node,直接根据该Node的hash直接在newTab中重新定位存储
newTab[e.hash & (newCap - 1)] = e;4.如果是树节点,直接维护到TreeNode
5.
if ((e.hash & oldCap) == 0)
true:该e节点(Node)不需要重新定位
loHead:数组中第一个Node
loTail:该下标中最后一个Node
不需要重新定位:
newTab[j] = loHead;false:该e节点(Node)需要根据newTab重新定位
hiHead:该下标中第一个需要重新定位的Node
hiTail:该下标中最后一个需要重新定位的Node
需要重新定位:
newTab[j + oldCap] = hiHead;6.e.next再次回到第五步判读是否需要重新定位,再次定位在新的newTab,直到循环结束,oldTab数据迁移完毕!