华为昇腾NPU卡 大模型LLM ChatGLM2模型推理使用
参考:https://gitee.com/mindspore/mindformers/blob/dev/docs/model_cards/glm2.md#chatglm2-6b
1、安装环境:
昇腾NPU卡对应英伟达GPU卡,CANN对应CUDA底层; mindspore对应pytorch;mindformers对应transformers
本次环境:
CANN-6.3.RC2.b20231016
mindspore 2.0.0
mindformers (离线安装:https://gitee.com/mindspore/mindformers)


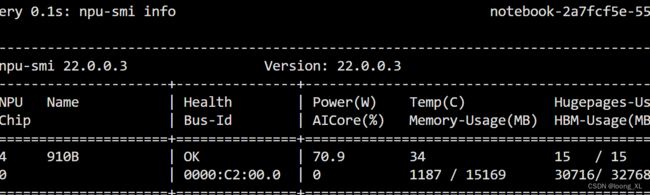
查看npu使用信息:
npu-smi info
2、ChatGLM2模型使用
参考:https://gitee.com/mindspore/mindformers/blob/dev/docs/model_cards/glm2.md
问题参考:
https://gitee.com/mindspore/mindformers/issues/I897LA#note_22105999
代码:
1)pipline方式运行:
import os
import mindspore as ms
os.environ['DEVICE_ID']='0'
ms.set_context(mode=ms.GRAPH_MODE, device_target="Ascend", device_id=0) ##需要使用才能npu加速
from mindformers import pipeline, TextGenerationPipeline
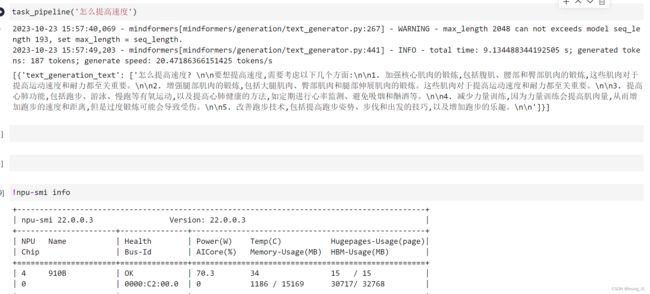
task_pipeline = pipeline(task='text_generation', model='glm2_6b', max_length=2048) ##模型自动会下载到checkpoint_download文件夹下
task_pipeline('你好') ## 第一次很慢,加载编译阶段
task_pipeline('写一首关于一带一路的诗') ##第二次开始速度才有提升

由于mindspore不支持一张卡上运行多个任务,所以启动任务都是直接默认申请31G显存占用的,挺耗资源
2)接口运行
import os
import mindspore as ms
os.environ['DEVICE_ID']='0'
ms.set_context(mode=ms.GRAPH_MODE, device_target="Ascend",device_id=0)
from mindformers import AutoConfig, AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("glm2_6b")
config = AutoConfig.from_pretrained("glm2_6b")
config.use_past = True
model = AutoModel.from_config(config)
##第一轮问问题
inputs = tokenizer("你好")["input_ids"]
# print(inputs)
outputs = model.generate(inputs, max_new_tokens=20, do_sample=True, top_k=3)
response = tokenizer.decode(outputs)
print(response)
第一轮加载编译还是很慢,后续速度才提升
##第二轮问问题
inputs = tokenizer("写一首一带一路的诗")["input_ids"]
# print(inputs)
outputs = model.generate(inputs, max_new_tokens=500, do_sample=True, top_k=3)
response = tokenizer.decode(outputs)
print(response)

3)流式输出(与transformers接口基本相似;基本只支持配合上面的2)接口运行使用,pipline不大支持)
参考:https://gitee.com/mindspore/mindformers/blob/dev/mindformers/generation/streamers.py#L64
https://blog.csdn.net/weixin_44491772/article/details/131205174
第一种(主要用):TextIteratorStreamer
##加载模型
import os
import mindspore as ms
os.environ['DEVICE_ID']='0'
ms.set_context(mode=ms.GRAPH_MODE, device_target="Ascend",device_id=0)
from mindformers import AutoConfig, AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("glm2_6b")
config = AutoConfig.from_pretrained("glm2_6b")
config.use_past = True
model = AutoModel.from_config(config)
##第一轮问问题
inputs = tokenizer("你好")["input_ids"]
# print(inputs)
outputs = model.generate(inputs, max_new_tokens=20, do_sample=True, top_k=3)
response = tokenizer.decode(outputs)
print(response)
###流式代码
from mindformers import TextIteratorStreamer
from threading import Thread
streamer = TextIteratorStreamer(tokenizer)
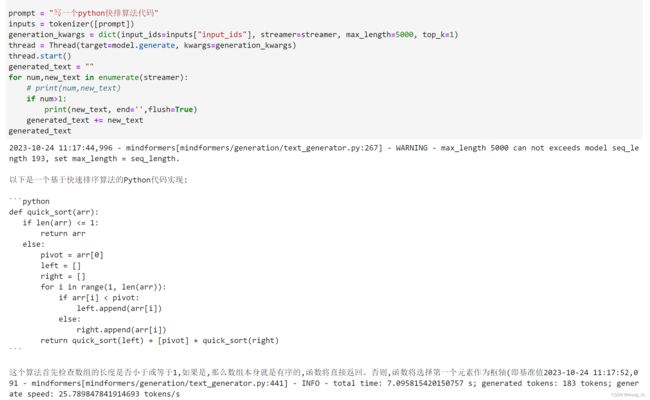
prompt = "写一首一带一路的诗"
inputs = tokenizer([prompt])
generation_kwargs = dict(input_ids=inputs["input_ids"], streamer=streamer, max_length=500, top_k=1)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
generated_text = ""
for num,new_text in enumerate(streamer):
# print(num,new_text)
if num>1:
print(new_text, end='',flush=True)
#print(new_text, end='',flush=True)
generated_text += new_text
generated_text

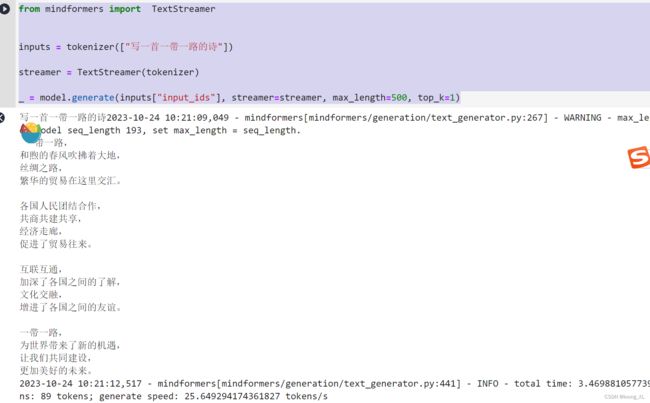
第二种:TextStreamer
from mindformers import TextStreamer
inputs = tokenizer(["写一首一带一路的诗"])
streamer = TextStreamer(tokenizer)
_ = model.generate(inputs["input_ids"], streamer=streamer, max_length=500, top_k=1)
4)history构建
参考:https://aistudio.baidu.com/projectdetail/6519985
https://zhuanlan.zhihu.com/p/650730807
def prepare_query_for_chat(query: str, history = None):
if history is None:
return query
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n问:{}\n答:{}\n".format(i, old_query, response)
prompt += "[Round {}]\n问:{}\n答:".format(len(history), query)
return prompt
prompt = prepare_query_for_chat(
query="你是谁?", history=[("你叫小乐主要擅长是智慧城市和智慧安全方向,核心技术包括专用高性能计算,解密设备,无人机智能反制系统,云计算平台,AI行为分析等,愿景是让城市更智慧,让世界更安全;每次回答请都简要回答不超过30个字","好的,小乐很乐意为你服务")]
)
print(prompt)
完整代码:
from mindformers import TextIteratorStreamer
from threading import Thread
streamer = TextIteratorStreamer(tokenizer)
prompt = prepare_query_for_chat(
query="你能做什么?", history=[("你主要擅长是智慧城市和智慧安全方向,核心技术包括专用高性能计算,解密设备,无人机智能反制系统,云计算平台,AI行为分析等,愿景是让城市更智慧,让世界更安全;每次回答请都简要回答不超过30个字","好的,小**很乐意为你服务")]
)
inputs = tokenizer([prompt])
generation_kwargs = dict(input_ids=inputs["input_ids"], streamer=streamer, max_length=5000, top_k=1)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
generated_text = ""
for num,new_text in enumerate(streamer):
# print(num,new_text)
if num>=1:
print(new_text, end='',flush=True)
generated_text += new_text
generated_text
