Xilinx FFT IP使用总结
Xilinx FFT IP使用总结
- 一、概述
- 二、FFT IP 配置过程
-
- 1、步骤一:配置FFT 点数及工作模式
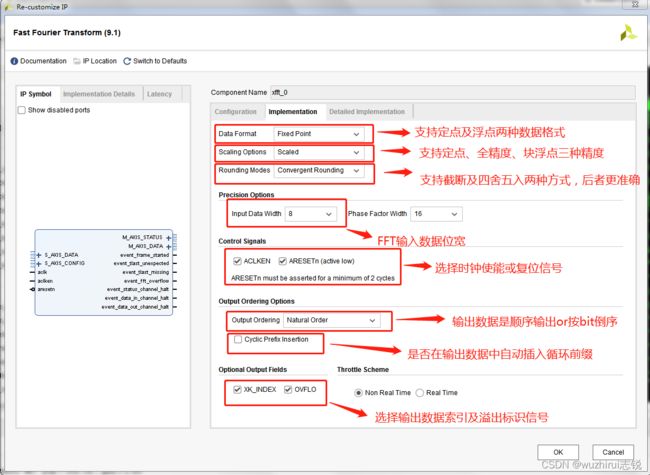
- 2、步骤二:配置数据格式、输出数据顺序、循环前缀等信息
- 3、步骤三:配置内部资源优化选项
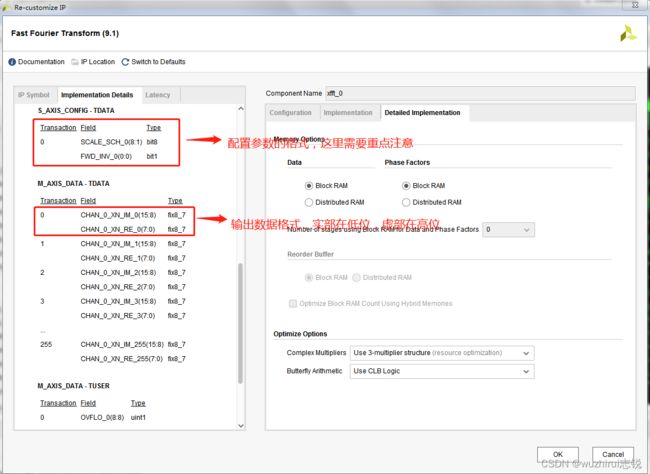
- 4、步骤四:查看生成了FFT信息,重点注意生成参数的格式
- 三、FFT IP的test bench
- 四、FFT结果及时序分析
-
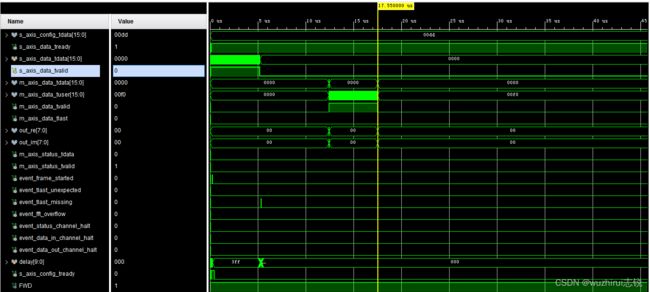
- 1、整体时序波形
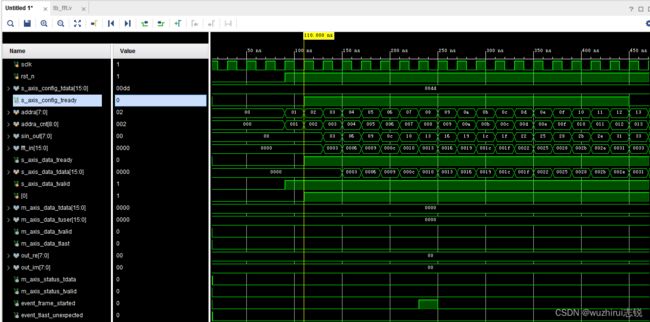
- 2、FFT输入数据时序波形
- 3、FFT输出结果时序波形
- 4、FFT输出结果分析
-
- 1)FPGA计算结果
- 2)matlab计算结果
- 3)结果比对
- 五、基2突发、基4突发、pipeline三种模式资源占用及性能分析
- 六、注意事项
一、概述
FFT快速傅里叶变换是我们在数字信号处理中经常会用到的DSP算法,本文将Xilinx FFT IP核的使用方法及注意事项总结如下 ,主要是产生一个周期256点的正弦信号,然后通过FFT的IP核做256点的FFT处理,最后通过仿真分析对比查看FFT输出结果与matlab结果差异。
二、FFT IP 配置过程
下面将通过vivado配置FFT IP核的过程说明如下。
1、步骤一:配置FFT 点数及工作模式

2、步骤二:配置数据格式、输出数据顺序、循环前缀等信息
3、步骤三:配置内部资源优化选项

4、步骤四:查看生成了FFT信息,重点注意生成参数的格式
三、FFT IP的test bench
下面是FFT IP的测试代码,具体见代码注释。
`timescale 1ns / 1ns
module tb_fft;
//基2的参数配置
//parameter FWD=1'b1;//选择是FFT还是IFFT
//parameter SCALE=16'b01_01_01_01_01_00_01_10;
//parameter PAD=7'b000_0000;
//基4的参数配置
parameter FWD=1'b1;//选择是FFT还是IFFT
parameter SCALE=8'b01_10_11_10;//每级右移位数
parameter PAD=7'b000_0000;
//基4+CP的参数配置
//parameter FWD=1'b1;//选择是FFT还是IFFT
//parameter SCALE=8'b01_10_11_10;
//parameter PAD=7'b000_0000;
//parameter CP_LEN=8'b0000_1000;
reg sclk;
reg rst_n;
reg [7:0] addra;
reg [8:0] addra_cnt;
wire [7:0] sin_out;
wire [15:0] fft_in;
//基2的寄存器长度
//wire [23:0] s_axis_config_tdata;
//基4的寄存器长度
wire [15:0] s_axis_config_tdata;
//基4+CP的寄存器长度
//wire [23:0] s_axis_config_tdata;
//wire s_axis_config_tready;
wire s_axis_data_tready;
reg[15:0] s_axis_data_tdata;
reg s_axis_data_tvalid;
wire[15:0] m_axis_data_tdata;
wire[15:0] m_axis_data_tuser;
wire m_axis_data_tvalid;
wire m_axis_data_tlast;
wire[7:0] out_re;
wire[7:0] out_im;
wire m_axis_status_tdata;
wire m_axis_status_tvalid;
wire event_frame_started;
wire event_tlast_unexpected;
wire event_tlast_missing;
wire event_fft_overflow;
wire event_status_channel_halt;
wire event_data_in_channel_halt;
wire event_data_out_channel_halt;
initial
begin
#0 sclk=0;rst_n=0;
#90 rst_n=1;
end
always #10 sclk=~sclk;
//产生从RAM中读取256点正弦信号地址
always@(posedge sclk or negedge rst_n)
begin
if(rst_n==1'b0)
addra<=8'd0;
else if(addra==8'd255)//只产生256个数据地址,然后一直保持
addra<=addra;
else
addra<=addra+1'b1;
end
//单口RAM的IP核
blk_mem_gen_0 blk_mem_gen_0_inst (
.clka(sclk), // input wire clka
.ena(1'b1), // input wire ena
.wea(1'b0), // input wire [0 : 0] wea
.addra(addra), // input wire [7 : 0] addra
.dina('d0), // input wire [7 : 0] dina
.douta(sin_out) // output wire [7 : 0] douta
);
//输入的正弦信号为实信号放在实部,虚部全部补零
assign fft_in={8'd0,sin_out};
//用于产生256个数据的s_axis_data_tvalid信号
always@(posedge sclk or negedge rst_n)
begin
if(rst_n==1'b0)
addra_cnt<=9'd0;
else if(addra_cnt==9'd256)
addra_cnt<=addra_cnt;
else
addra_cnt<=addra_cnt+1'b1;
end
//输入FFT数据与valid信号同步
always@(posedge sclk or negedge rst_n)
begin
if(rst_n==1'b0)
begin
s_axis_data_tvalid<=1'b0;
s_axis_data_tdata<=16'd0;
end
else if(addra_cnt==9'd256)
begin
s_axis_data_tvalid<=1'b0;
s_axis_data_tdata<=16'd0;
end
else
begin
s_axis_data_tvalid<=1'b1;
s_axis_data_tdata<=fft_in;
end
end
//将FFT输入数据的valid信号进行延时
reg [9:0] delay;
always@(posedge sclk or negedge rst_n)
begin
if(rst_n==1'b0)
delay<=10'd0;
else
delay[9:0]<={delay[8:0],s_axis_data_tvalid};
end
//配置FFT参数
//基4的参数配置
assign s_axis_config_tdata={PAD,SCALE,FWD};
//基4+CP的寄存器长度
//assign s_axis_config_tdata={PAD,SCALE,FWD,CP_LEN};
xfft_0 xfft_0_inst (
.aclk(sclk), // input wire aclk
.aclken(1'b1), // input wire aclken
.aresetn(rst_n), // input wire aresetn
.s_axis_config_tdata(s_axis_config_tdata), // input wire [23 : 0] s_axis_config_tdata
.s_axis_config_tvalid(1'b1), // input wire s_axis_config_tvalid
.s_axis_config_tready(s_axis_config_tready), // output wire s_axis_config_tready
.s_axis_data_tdata(s_axis_data_tdata), // input wire [15 : 0] s_axis_data_tdata
.s_axis_data_tvalid(delay[0]), // input wire s_axis_data_tvalid
.s_axis_data_tready(s_axis_data_tready), // output wire s_axis_data_tready
.s_axis_data_tlast(1'b0), // input wire s_axis_data_tlast
.m_axis_data_tdata(m_axis_data_tdata), // output wire [15 : 0] m_axis_data_tdata
.m_axis_data_tuser(m_axis_data_tuser), // output wire [15 : 0] m_axis_data_tuser
.m_axis_data_tvalid(m_axis_data_tvalid), // output wire m_axis_data_tvalid
.m_axis_data_tready(1'b1), // input wire m_axis_data_tready
.m_axis_data_tlast(m_axis_data_tlast), // output wire m_axis_data_tlast
.m_axis_status_tdata(m_axis_status_tdata), // output wire [7 : 0] m_axis_status_tdata
.m_axis_status_tvalid(m_axis_status_tvalid), // output wire m_axis_status_tvalid
.m_axis_status_tready(1'b1), // input wire m_axis_status_tready
.event_frame_started(event_frame_started), // output wire event_frame_started
.event_tlast_unexpected(event_tlast_unexpected), // output wire event_tlast_unexpected
.event_tlast_missing(event_tlast_missing), // output wire event_tlast_missing
.event_fft_overflow(event_fft_overflow), // output wire event_fft_overflow
.event_status_channel_halt(event_status_channel_halt), // output wire event_status_channel_halt
.event_data_in_channel_halt(event_data_in_channel_halt), // output wire event_data_in_channel_halt
.event_data_out_channel_halt(event_data_out_channel_halt) // output wire event_data_out_channel_halt
);
//查看FFT输出结果的实虚部
assign out_re=m_axis_data_tdata[7:0];
assign out_im=m_axis_data_tdata[15:8];
endmodule
四、FFT结果及时序分析
1、整体时序波形
2、FFT输入数据时序波形
FFT输入数据起始时序波形如下,将输入数据同步信号s_axis_data_tvalid延迟了1拍,是因为输入FFT参数配置信号s_axis_config_tready还没有拉高,即FFT参数还没有配置后,FFT输入数据已经进来,会导致输入数据点数少于FFT点数,出现event_data_in_channel_halt拉高报错。
3、FFT输出结果时序波形
从时序图中看出,FFT的输出数据与输出数据同步信号m_axis_data_tvalid和最后数据指示信号m_axis_data_tlast是完全同步的。
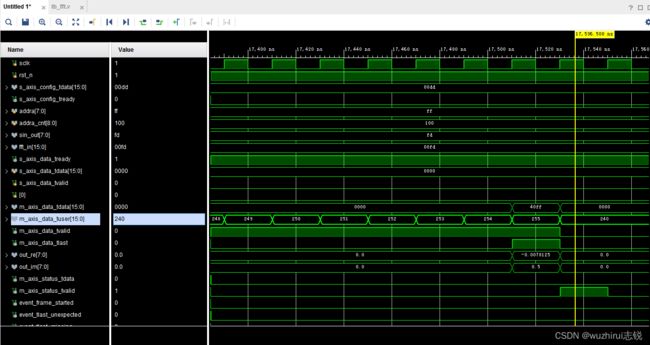
4、FFT输出结果分析
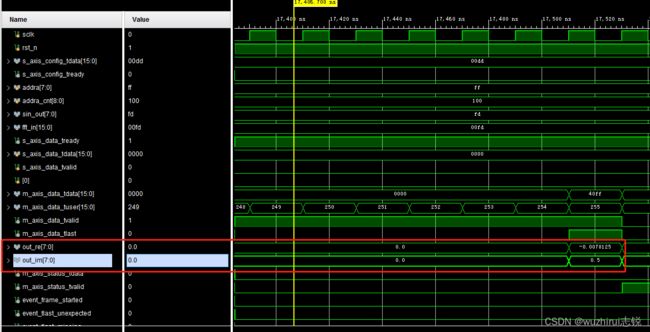
1)FPGA计算结果
便于比对FPGA与matalb结果,将输出结果配置为小数, 如下图。

第256个点FFT输出结果虚部为0.5
2)matlab计算结果
matlab代码如下:
clc;
close all;
clear all;
n=[0:255];
N=256;
sig=round(sin(2*pi*n/N)*127);
%sig=round(sin(2*pi*n/N)*32767);
sig_freq_re=real(fft(sin(2*pi*n/N),256));
sig_freq_im=imag(fft(sin(2*pi*n/N),256));
%figure(1),plot(abs(sig_freq));
for i=1:256
if(sig(i)<0)
sig(i)=256+sig(i);%对于负数要转换为补码形式
%sig(i)=65536+sig(i);%对于负数要转换为补码形式
else
sig(i)=sig(i);
end
end
fid=fopen('ram_init_data.coe','w+')
fprintf(fid,'memory_initialization_radix = 10; \n')
fprintf(fid,'memory_initialization_vector = \n')
for i=1:255
fprintf(fid,'%d,',sig(i));
end
fprintf(fid,'%d;',sig(256));
fclose(fid);
matlab输出结果如下:
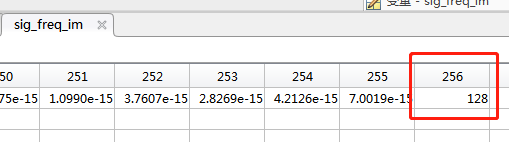
3)结果比对
为防止在计算FFT过程中出现溢出,我们在配置FFT的SCALE参数时,进行了右移处理,一共右移了8位后为0.5,正好与maltab结果是完全对应的,因此可以得出FFT IP核输出结果正确。
五、基2突发、基4突发、pipeline三种模式资源占用及性能分析
1、基2突发模式占用资源及时延
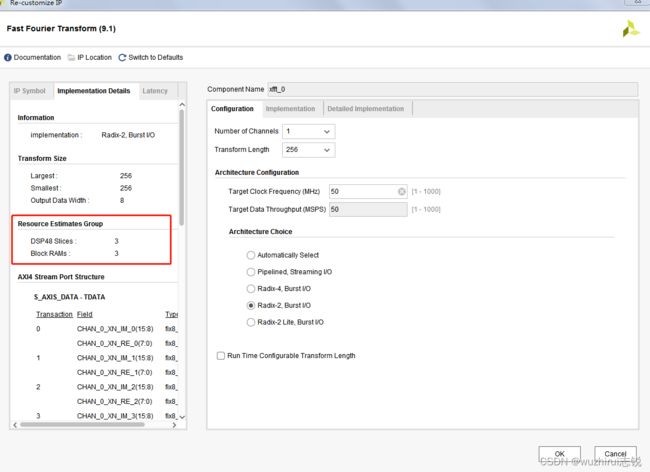

2、基4突发模式占用资源及时延

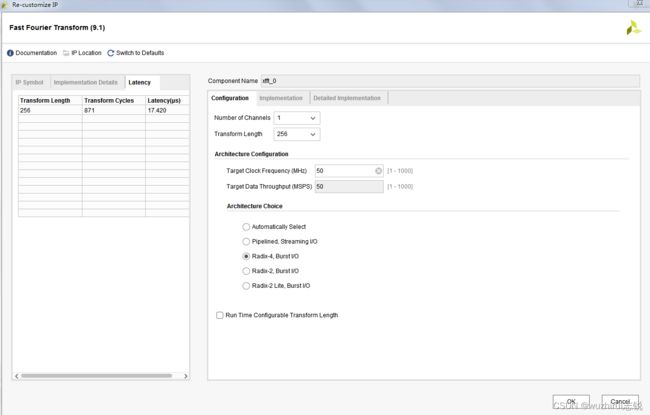
3、pipeline模式占用资源及时序
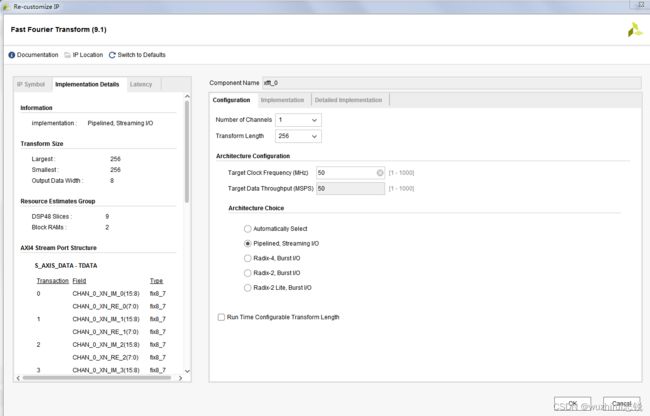

六、注意事项
1、为防止计算FFT过程中出现溢出,计算256点FFT时,在基4突发和pipeline这两种模式下,SCALE推荐采用[01_10_11_10],在基2突发模式下,推荐采用[01_01_01_01_01_00_01_10]。
2、在基2突发和基4突发模式,未采用流水下结果,只有FFT计算并输出完成后,采用允许继续输入;而pipeline模式可以连续输入数据进行FFT计算。
3、该FFT IP支持插入CP循环前缀,非常方便,但是要考虑输入数据的连续性。
4、基2突发模式占用资源最少但是处理时延大,基4突发模式正好相反,需要根据系统资源情况及时延要求综合考虑。
5、采用四舍五入方式比截断方式准确度更好。
关于xilinx FFT IP的具体使用,可以参见官方《Fast Fourier Transform v9.1 LogiCORE IP Product Guide》手册。