TensorFlow 原生分布式训练机制探究
TensorFlow 原生分布式训练机制探究
标签(空格分隔): 未分类
文章目录
- TensorFlow 原生分布式训练机制探究
-
-
- 分布式训练代码解析
-
- 构建estimator封装模型定义
- input_fn (dataset的使用)
- experiment
-
憋屈了三个月,公司招来了个牛逼的数据科学家(遗憾:还是走了),终于公司还是配了4条V100部署在两台服务器上,可把我兴奋坏了(原谅我小农,没见过大GPU集群)。有了资源当然是要充分的利用起来啦,今天小菜带同学们一起探究TensorFlow的跨卡跨机分布式训练。
TensorFlow的更新可谓是日新月异啊,15年开源以来,到现在已经有很多旧的API被遗弃了。这不,TensorFlow2.0 Alpha 版本已经在2019年3月发布,主打AI民主化,各媒体或者教育机构开始吹嘘,TensorFlow2.0 没有graph,没有Tensor,没有session,eager execution和keras能像numpy一样简单使用、调试,是入门AI的最佳时机。我去官网逛了一圈,计算架构还是那个计算架构,TensorFlow 当年之所以能够在caffe风靡一时的期间后来居上,凭借着优秀的计算图架构,灵活的计算子,现在有在原来基础上多封装了一层keras使得TensorFlow更加容易入门,所有原来的东西还在,最大的改变就是主打keras和eager execution。
不扯了,今天的主题是分布式训练,网上的资料都很“古老”了,包括TensorFlow1.13源码中的https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/tools/dist_test/python/mnist_replica.py 还是使用旧的API,到TensorFlow1.93往后就开始删除了(1.13就到1.93了)。
TensorFlow发布有个趋势,尽量轻量化源码,把很多东西从原来的源码中剥离出来,重立一个项目。






其中model,example中有很多例子,ecosystem是大型分布式训练的例子,包括用kubernetes 管理资源的案例。今天给同学们解读的是在model里的一个用cifar10的数据分布式训练resnet的例子(https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10_estimator)(这种连接随着github仓库的更新,很容易就失效,如果失效,在tensorflow/model 仓库找以前的版本可能找到):
这里用的不是最新的api,但是tensorflow2.0以前版本都是支持的,而且对于理解最新的2.0往后的api很有帮助。这里用到了tensorflow比较高级的api构件,包括Estimator(估算器)、Experiment(实验)和Dataset(数据集)。值得注意的是,你可以独立地使用Estimator,Experiment和Dataset。

贴出训练代码组织结构图,让同学们更好的理解下面的内容。这些高级api构件单独拿出来都能是很多内容可写,今天只是粗略的讲解一下,未能透彻清楚的请移步官方网站单独学习。
dataset : 是tf 提供专门为训练准备数据的,避免开发者使用低级的api 读数造成数据读取瓶颈,dataset 提供高效的队列机制,shuffle打撒功能,batch读取功能,还有高级初始化功能等,极易于开发。结合相应的Iterator来为高速度训练不间断地输送数据。
experiment : 目前是在tf.contrib 包里,2.0以后将被废弃,封装了训练过程。将来被tf.estimator.train_and_evaluate 代替。
estimator : 这个api将是tf的重点高级api,包括实现训练、评估和预测的所有功能,包括导出save-model 格式的trained模型,供tensorflow serving使用。各位同学要重点关注这个类。
分布式训练代码解析
整个项目文件功能如下,以下重点选cifar10_main.py 讲解:
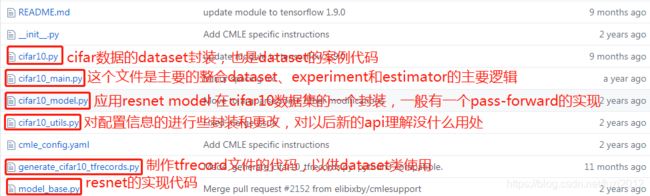
构建estimator封装模型定义
查看estimator的api:
__init__(
model_fn,
model_dir=None,
config=None,
params=None,
warm_start_from=None
)
Estimator对象包装了一个由模型指定的模型函数model_fn,该模型函数给定input和许多其他参数(封在params中),该函数返回的是执行训练、评估或预测所需的操作(封装在tf.estimator.EstimatorSpec里返回)。
所有日志输出(检查点、事件文件等)都写入model_dir或其子目录。如果没有设置model_dir,则使用临时目录。
config可以传递参数tf.estimator.runconfig对象,该对象包含有关执行环境的信息。如果模型有一个名为config的参数(以相同的方式输入函数),则它将被传递给定义好的模型。如果未传递config参数,则由estimastor实例化。不传递配置意味着使用对本地执行有用的默认值。Estimator使配置对模型可用。
params参数包含超参数。如果模型有一个名为params的参数,它将以相同的方式传递给model_fn和输入函数。估计量只传递参数,不检查参数。因此,参数的结构完全取决于开发人员。
Estimator的任何方法都不能在子类中被重写(其构造函数强制这样做)。子类应该使用model_fn来配置基类,并且可以添加实现特定功能的方法。
以上是estimator的构造器,我们来详细看看构造其中model_fn的定义,然后一层一层的剖析这个案例的源码,先看cifar10_main.py(https://github.com/tensorflow/models/blob/master/tutorials/image/cifar10_estimator/cifar10_main.py) 的38-352行:
classifier = tf.estimator.Estimator(
model_fn=get_model_fn(num_gpus, variable_strategy,
run_config.num_worker_replicas or 1),
config=run_config,
params=hparams)
这是一个estimator的构建,追溯下去,找model_fn的定义,看47-206行,是一个嵌套函数,返回一个model_fn,我在源码中加注释说明:
def get_model_fn(num_gpus, variable_strategy, num_workers):
"""返回一个model_fn模型函数,在本例中返回的是resnet模型"""
def _resnet_model_fn(features, labels, mode, params):
"""Resnet model body.
支持单GPU,多GPU训练,参数更新模式可实现两种模式.
1. 在CPU中控制梯度更新变量,在CPU中实现参数服务器 (parameter server)
2. 参数分布在GPU中更新,第一个GPU担任参数服务器
Args: model_fn固定的三个输入
features: a list of tensors, one for each tower :这个可以是封装Tensor的字典,也可以直接是Tensor,我比较喜欢当做字典用,因为比较适用范围比较广,可以有多个输入的情况
labels: a list of tensors, one for each tower 同理
mode: ModeKeys.TRAIN or EVAL
params: Hyperparameters suitable for tuning
Returns:
A EstimatorSpec object.
"""
is_training = (mode == tf.estimator.ModeKeys.TRAIN) # 获取执行模式,在我estimator的调用方式中可以指定是训练,评估和预测
weight_decay = params.weight_decay # 正则项参数
momentum = params.momentum # 学习率的参数
tower_features = features #网络模型的输入数据就在这个feature中带进来,是从input_fn中实现的,往后会讲到
tower_labels = labels # 标签也是在input_fn 来
tower_losses = [] # 这些数组是为了收集分布在各个GPU上执行后返回的结果数据,包括loss,gradient等等
tower_gradvars = []
tower_preds = []
# channels first (NCHW) is normally optimal on GPU and channels last (NHWC)
# on CPU. The exception is Intel MKL on CPU which is optimal with
# channels_last.
data_format = params.data_format # 数据格式主要是图像中通道那一维在第二维还是最后一维
if not data_format:
if num_gpus == 0:
data_format = 'channels_last'
else:
data_format = 'channels_first'
if num_gpus == 0:
num_devices = 1 # 用于计算的设备的个数
device_type = 'cpu'
else:
num_devices = num_gpus # 用GPU的计算的个数
device_type = 'gpu'
for i in range(num_devices): 把数据分摊到不同的GPU上执行,然后在收集结果,每个GPU上跑的是同一个模型
worker_device = '/{}:{}'.format(device_type, i)
if variable_strategy == 'CPU': # 这个是参数变量策略,在CPU上还在GPU上更新参数
device_setter = cifar10_utils.local_device_setter(
worker_device=worker_device)
elif variable_strategy == 'GPU':
device_setter = cifar10_utils.local_device_setter( # local_device_setter会自动的分配各个计算节点到相应的设备上,GPU #或CPU
ps_device_type='gpu',
worker_device=worker_device,
ps_strategy=tf.contrib.training.GreedyLoadBalancingStrategy( # 这个是参数负载均衡实现
num_gpus, tf.contrib.training.byte_size_load_fn))
with tf.variable_scope('resnet', reuse=bool(i != 0)):
with tf.name_scope('tower_%d' % i) as name_scope:
with tf.device(device_setter):
loss, gradvars, preds = _tower_fn( # 调用模型函数,跑网络,这里是一次pass-forward 待会会详细讲解这个函数
is_training, weight_decay, tower_features[i], tower_labels[i],
data_format, params.num_layers, params.batch_norm_decay,
params.batch_norm_epsilon)
tower_losses.append(loss) # 在各个计算设备上收集一次跑网络的结果
tower_gradvars.append(gradvars)
tower_preds.append(preds)
if i == 0:
# Only trigger batch_norm moving mean and variance update from
# the 1st tower. Ideally, we should grab the updates from all
# towers but these stats accumulate extremely fast so we can
# ignore the other stats from the other towers without
# significant detriment.
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS,
name_scope) # 这个是 batch——normalization的更新平均值和方差的地方,resnet用到了BN
## 接下来就是计算收集到各个设备上计算的结果的平均值,做汇总
# Now compute global loss and gradients.
gradvars = []
with tf.name_scope('gradient_averaging'):
all_grads = {}
for grad, var in itertools.chain(*tower_gradvars):
if grad is not None:
all_grads.setdefault(var, []).append(grad)
for var, grads in six.iteritems(all_grads):
# Average gradients on the same device as the variables
# to which they apply.
with tf.device(var.device):
if len(grads) == 1:
avg_grad = grads[0]
else:
avg_grad = tf.multiply(tf.add_n(grads), 1. / len(grads)) # 求平均梯度
gradvars.append((avg_grad, var))
# Device that runs the ops to apply global gradient updates.
consolidation_device = '/gpu:0' if variable_strategy == 'GPU' else '/cpu:0'
with tf.device(consolidation_device): ## 在那一设备上更新网络参数
# Suggested learning rate scheduling from
# https://github.com/ppwwyyxx/tensorpack/blob/master/examples/ResNet/cifar10-resnet.py#L155
# 以下这几行只是为了用到tf.train.piecewise_constant 的学习率递减器所需要的数据,其他递减器不需要的
num_batches_per_epoch = cifar10.Cifar10DataSet.num_examples_per_epoch(
'train') // (params.train_batch_size * num_workers)
boundaries = [
num_batches_per_epoch * x
for x in np.array([82, 123, 300], dtype=np.int64)
]
staged_lr = [params.learning_rate * x for x in [1, 0.1, 0.01, 0.002]]
learning_rate = tf.train.piecewise_constant(tf.train.get_global_step(),
boundaries, staged_lr)
loss = tf.reduce_mean(tower_losses, name='loss') # 损失函数
examples_sec_hook = cifar10_utils.ExamplesPerSecondHook( ## 监控训练的频次
params.train_batch_size, every_n_steps=10)
tensors_to_log = {'learning_rate': learning_rate, 'loss': loss} ##这个是监控的时候应该答应出来的log
logging_hook = tf.train.LoggingTensorHook(
tensors=tensors_to_log, every_n_iter=100) # 没100步打印上面的日志
train_hooks = [logging_hook, examples_sec_hook]
optimizer = tf.train.MomentumOptimizer(
learning_rate=learning_rate, momentum=momentum)
if params.sync:
optimizer = tf.train.SyncReplicasOptimizer( # 把优化器封装在一个分布式的优化器中,使训练得以分布式进行
optimizer, replicas_to_aggregate=num_workers)
sync_replicas_hook = optimizer.make_session_run_hook(params.is_chief)
train_hooks.append(sync_replicas_hook)
# Create single grouped train op
train_op = [
optimizer.apply_gradients(
gradvars, global_step=tf.train.get_global_step())
]
train_op.extend(update_ops)
train_op = tf.group(*train_op)
predictions = { ## 预测阶段 输出的结果
'classes':
tf.concat([p['classes'] for p in tower_preds], axis=0),
'probabilities':
tf.concat([p['probabilities'] for p in tower_preds], axis=0)
}
stacked_labels = tf.concat(labels, axis=0)
metrics = { ## 评估阶段 输出的结果
'accuracy':
tf.metrics.accuracy(stacked_labels, predictions['classes']) ## 这里必须是一个tf.metrics定义的东西,我曾经掉在这个坑里
}
return tf.estimator.EstimatorSpec( # model_fn 就是要返回一个tf.estimator.EstimatorSpec,封装训练、评估和预测的返回值
mode=mode,
predictions=predictions,
loss=loss,
train_op=train_op,
training_hooks=train_hooks,
eval_metric_ops=metrics)
return _resnet_model_fn
详细的解析我都注释在代码中了,在接下来的讲解中,突然想起不知大家是否有TensorFlow分布式训练的基本架构,还需要补充一下:
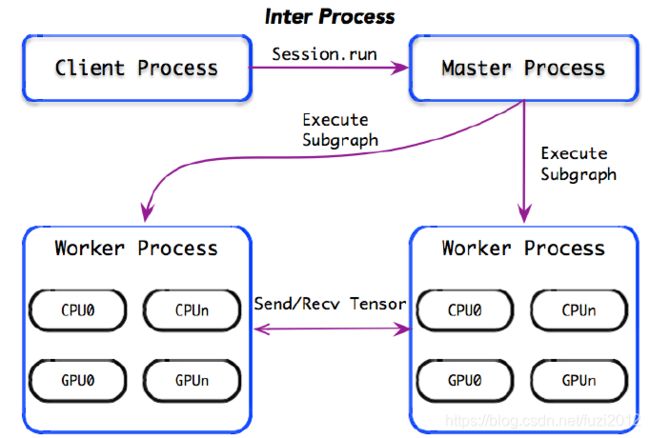
在分布式模式中,Client 负责计算图的构造,然后通过调用Session.run,启动计算图的执行过程。
Master 进程收到计算图执行的消息后,启动计算图的剪枝,分裂,优化等操作;最终将子图分发注册到各个Worker 进程上,然后触发各个Worker 进程并发执行子图。
Worker 进程收到子图注册的消息后,根据本地计算设备资源,再将计算子图实施二次分裂,将子图分配在各个计算设备上,最后启动各个计算设备并发地执行子图;如果Worker 之间存在数据交换,可以通过进程间通信完成交互。
我要继续贴代码了(209-250行)这个一个封装了resnet的pass-forward函数,这个不属于estimator范畴,完全可以自定义:
def _tower_fn(is_training, weight_decay, feature, label, data_format,
num_layers, batch_norm_decay, batch_norm_epsilon):
"""Build computation tower (Resnet).
Args:
is_training: true if is training graph.
weight_decay: weight regularization strength, a float.
feature: a Tensor.
label: a Tensor.
data_format: channels_last (NHWC) or channels_first (NCHW).
num_layers: number of layers, an int.
batch_norm_decay: decay for batch normalization, a float.
batch_norm_epsilon: epsilon for batch normalization, a float.
Returns:
A tuple with the loss for the tower, the gradients and parameters, and
predictions.
"""
model = cifar10_model.ResNetCifar10( ## 这个函数的实现在另一个文件cifar10_model中
num_layers,
batch_norm_decay=batch_norm_decay,
batch_norm_epsilon=batch_norm_epsilon,
is_training=is_training,
data_format=data_format)
logits = model.forward_pass(feature, input_data_format='channels_last')
tower_pred = {
'classes': tf.argmax(input=logits, axis=1),
'probabilities': tf.nn.softmax(logits)
}
tower_loss = tf.losses.sparse_softmax_cross_entropy(
logits=logits, labels=label)
tower_loss = tf.reduce_mean(tower_loss)
model_params = tf.trainable_variables()
tower_loss += weight_decay * tf.add_n(
[tf.nn.l2_loss(v) for v in model_params])
tower_grad = tf.gradients(tower_loss, model_params)
return tower_loss, zip(tower_grad, model_params), tower_pred
使用这个分布式训练框架主要就是修改着以上这两个函数,改成你自己的模型函数。
input_fn (dataset的使用)
使用estimator训练模型,就鄙视定义好input_fn,可以使train_input_fn和eval_input_fn。(253-292行)这里非常值得借鉴的地方就是多GPU的使用,划分数据。
def input_fn(data_dir,
subset,
num_shards,
batch_size,
use_distortion_for_training=True):
"""Create input graph for model.
Args:
data_dir: Directory where TFRecords representing the dataset are located.
subset: one of 'train', 'validate' and 'eval'.
num_shards: num of towers participating in data-parallel training.
batch_size: total batch size for training to be divided by the number of
shards.
use_distortion_for_training: True to use distortions.
Returns:
two lists of tensors for features and labels, each of num_shards length.
"""
with tf.device('/cpu:0'):
use_distortion = subset == 'train' and use_distortion_for_training
dataset = cifar10.Cifar10DataSet(data_dir, subset, use_distortion)
image_batch, label_batch = dataset.make_batch(batch_size)
if num_shards <= 1:
# No GPU available or only 1 GPU.
return [image_batch], [label_batch]
# Note that passing num=batch_size is safe here, even though
# dataset.batch(batch_size) can, in some cases, return fewer than batch_size
# examples. This is because it does so only when repeating for a limited
# number of epochs, but our dataset repeats forever.
image_batch = tf.unstack(image_batch, num=batch_size, axis=0)
label_batch = tf.unstack(label_batch, num=batch_size, axis=0)
feature_shards = [[] for i in range(num_shards)]
label_shards = [[] for i in range(num_shards)]
for i in xrange(batch_size):
idx = i % num_shards
feature_shards[idx].append(image_batch[i])
label_shards[idx].append(label_batch[i])
feature_shards = [tf.parallel_stack(x) for x in feature_shards]
label_shards = [tf.parallel_stack(x) for x in label_shards]
return feature_shards, label_shards
experiment
experiment这种训练方式在tf.contrib包里实现,在新的TensorFlow中终将废弃,会被estimator的trian_and_eval代替,但这里尊重源码直接讲解(直至TensorFlow1.13版本都是可用的),先看源码(381-387行)
tf.contrib.learn.learn_runner.run(
get_experiment_fn(data_dir, num_gpus, variable_strategy,
use_distortion_for_training),
run_config=config,
hparams=tf.contrib.training.HParams(
is_chief=config.is_chief,
**hparams))
tf.contrib.learn.learn_runner.run 把experiment调起来,完成分布式训练, experiment在get_experiment_fnd的嵌套函数中返回。
源码()
def get_experiment_fn(data_dir,
num_gpus,
variable_strategy,
use_distortion_for_training=True):
"""Returns an Experiment function.
Experiments perform training on several workers in parallel,
in other words experiments know how to invoke train and eval in a sensible
fashion for distributed training. Arguments passed directly to this
function are not tunable, all other arguments should be passed within
tf.HParams, passed to the enclosed function.
Args:
data_dir: str. Location of the data for input_fns.
num_gpus: int. Number of GPUs on each worker.
variable_strategy: String. CPU to use CPU as the parameter server
and GPU to use the GPUs as the parameter server.
use_distortion_for_training: bool. See cifar10.Cifar10DataSet.
Returns:
A function (tf.estimator.RunConfig, tf.contrib.training.HParams) ->
tf.contrib.learn.Experiment.
Suitable for use by tf.contrib.learn.learn_runner, which will run various
methods on Experiment (train, evaluate) based on information
about the current runner in `run_config`.
"""
def _experiment_fn(run_config, hparams):
"""Returns an Experiment."""
# Create estimator.
train_input_fn = functools.partial(
input_fn,
data_dir,
subset='train',
num_shards=num_gpus,
batch_size=hparams.train_batch_size,
use_distortion_for_training=use_distortion_for_training)
eval_input_fn = functools.partial(
input_fn,
data_dir,
subset='eval',
batch_size=hparams.eval_batch_size,
num_shards=num_gpus)
num_eval_examples = cifar10.Cifar10DataSet.num_examples_per_epoch('eval')
if num_eval_examples % hparams.eval_batch_size != 0:
raise ValueError(
'validation set size must be multiple of eval_batch_size')
train_steps = hparams.train_steps
eval_steps = num_eval_examples // hparams.eval_batch_size
classifier = tf.estimator.Estimator(
model_fn=get_model_fn(num_gpus, variable_strategy,
run_config.num_worker_replicas or 1),
config=run_config,
params=hparams)
# Create experiment.
return tf.contrib.learn.Experiment(
classifier,
train_input_fn=train_input_fn,
eval_input_fn=eval_input_fn,
train_steps=train_steps,
eval_steps=eval_steps)
return _experiment_fn
我的公众号会有更多学习笔记哦,欢迎关注:
