Pandas pivot 数据透视之后,去除多余列索引,转换行索引
Pandas 的数据透视功能很好用,但是它透视出来的结果,是将用来分组透视的行、列作为多层索引输出的,这可能和我们需要的数据格式不一样。
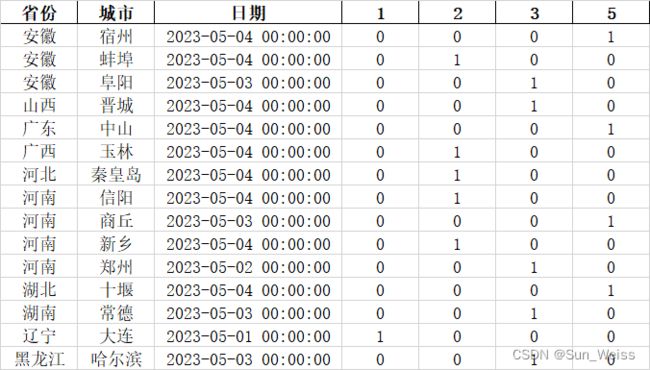
比如说,如下图所示的数据,我需要统计各 省份-城市-日期,每个分类的频次。
import pandas as pd
data = pd.read_excel('path')
pivoted_data = pd.pivot_table(data,
index=["省份","城市", "日期"],
values=["编号"],
columns="分类",
aggfunc=['count'],
fill_value=0)透视后的数据结果,有三层行索引:省份、城市、日期,三层列索引:count、编号、分类
我希望三层行索引能变成普通的列,列索引只保留分类一层。
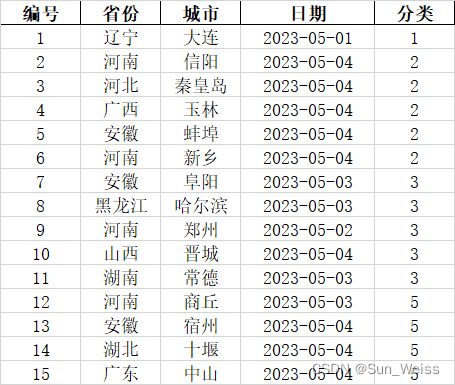
print(pivoted_data.index)
'''
MultiIndex([( '安徽', '宿州', '2023-05-04'),
( '安徽', '蚌埠', '2023-05-04'),
( '安徽', '阜阳', '2023-05-03'),
( '山西', '晋城', '2023-05-04'),
( '广东', '中山', '2023-05-04'),
( '广西', '玉林', '2023-05-04'),
( '河北', '秦皇岛', '2023-05-04'),
( '河南', '信阳', '2023-05-04'),
( '河南', '商丘', '2023-05-03'),
( '河南', '新乡', '2023-05-04'),
( '河南', '郑州', '2023-05-02'),
( '湖北', '十堰', '2023-05-04'),
( '湖南', '常德', '2023-05-03'),
( '辽宁', '大连', '2023-05-01'),
('黑龙江', '哈尔滨', '2023-05-03')],
names=['省份', '城市', '日期'])
'''
print(pivoted_data.columns)
'''
MultiIndex([('count', '编号', 1),
('count', '编号', 2),
('count', '编号', 3),
('count', '编号', 5)],
names=[None, None, '分类'])
'''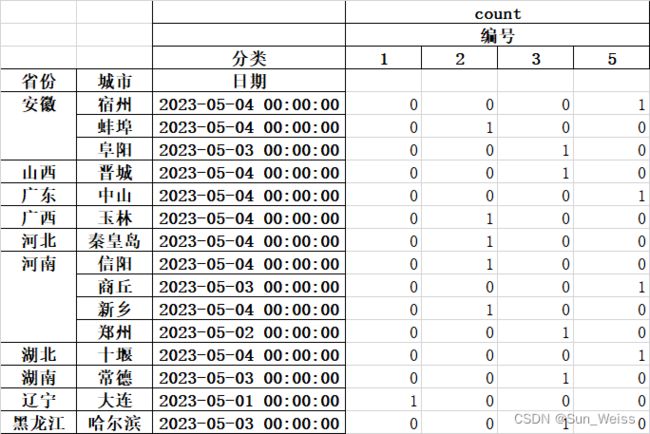
第一步,去除多余的列索引
# 只保留第三次的列索引
pivoted_data.columns = [col[2] for col in pivoted_data.columns.values]第二步,将行索引转换为普通的列
# 将行索引变为列
pivoted_data.reset_index(level=["省份","城市", "日期"], drop=False, inplace=True)完整代码:
data = pd.read_excel('input_path')
pivoted_data = pd.pivot_table(data,
index=["省份","城市", "日期"],
values=["编号"],
columns="分类",
aggfunc=['count'],
fill_value=0)
#print(pivoted_data)
#print(pivoted_data.index)
#print(pivoted_data.columns)
pivoted_data.columns = [col[2] for col in pivoted_data.columns.values]
pivoted_data.reset_index(level=["省份","城市", "日期"], drop=False, inplace=True)
pivoted_data.to_excel('output_path', index = None)最终输出的结果: