如何实现对象存储?
Part 1
引言
从结绳记事到竹简成书,再到纸张的出现,数据记录方式的革新伴随着人类文明的每一个进步。
随着计算机和通信技术的发展,人类产生和共享数据的速率呈指数级增长。如何有效的保存和管理这些数据是计算机存储技术首先要解决的问题。
很多人都听过对象存储这种说法,但是究竟什么是对象存储?对象存储如何实现呢?
Part 2
对象存储
01
什么是对象存储?
对象存储(Object Storage)不是新技术,很多人都听过对象存储这种说法,但是究竟什么是对象存储?这个问题可能会让一些人不知所措。
除了对象存储,你可能还听说过文件存储(File Storage)和块存储(Block Storage),我们把三者放在一起比较:
-
文件存储 - 数据保存在文件中,按目录(文件夹)进行组织,当需要访问文件时,用户需要知道它完整的路径;
-
块存储 - 块存储提供了文件存储的替代方案,它将文件分成大小相等的数据块,然后将数据块存储在唯一的地址。块存储可以提供比文件存储更好的性能;
-
对象存储 - 对象存储不使用文件夹、目录或更复杂的层次结构,每个文件作为一个对象保存在扁平的命名空间中。
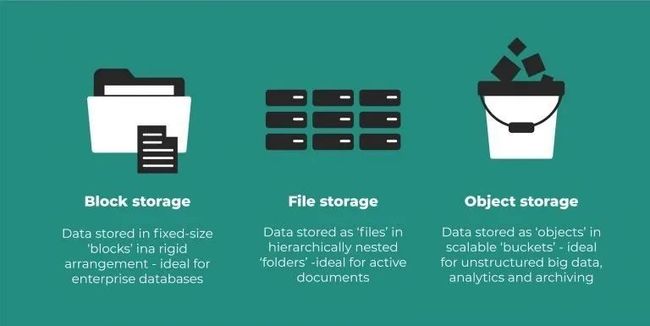
本质上,文件存储、块存储和对象存储是不同的数据访问形式,它们分别适合于不同类型的数据:
-
文件存储和块存储非常适合处理结构化数据;
-
对象存储适用于处理大量非结构化数据的数据。
今天的互联网通信数据很大程度上是非结构化的,包括电子邮件、视频、照片、网页、音频文件以及其他类型的媒体和Web内容。这些内容从社交媒体、搜索引擎、移动设备和“智能”设备源源不断地流出。
市场研究公司IDC估计,到2025年,非结构化数据可能占全球所有数据的80%。
基于对象的存储已成为数据归档和备份的首选方法,它可以提供传统基于文件或基于块的存储无法提供的可扩展性。
02
对象存储工作方式
对象(Object)保存在扁平的命名空间中,没有文件夹、目录或复杂的层次结构。
对象数据分为数据(data)和元数据(metadata)两部分,每个对象都有唯一的标识符(ID),用于定位和访问对象。
对象存储系统提供基于HTTP的RESTful服务,用户通过HTTP命令访问对象存储,例如PUT或POST上传对象,GET检索对象,DELETE删除对象。
此外,还有其他RESTful API标准,允许用户管理对象存储、帐户、多租户、安全性、计费等。
基于对象的存储天然契合当前云原生领域蓬勃发展的趋势,是存储、归档、备份和管理大量静态或非结构化数据的理想解决方案。
Part 3
对象存储实现
计算机存储技术涵盖广泛的范畴,从存储硬件到存储网络,从操作系统到分布式系统。
一个功能完备的存储系统需要考虑数据的可用性、一致性和持久性,需要具备灾备和恢复能力,并且运维友好。
要把这些说清楚,大概需要“一千零一夜”,好在业界有不少成熟的方案,下面我们通过分析一些开源项目的架构来了解对象存储系统是如何实现的。
01
对象存储开源项目
基于对象的存储系统,业界有几种可用的开源解决方案,例如Ceph、MinIO、Openio.io、OpenStack Swift等等。
这些项目在其功能上不尽相同,但是都有相同的设计目标——实现非结构化数据的大规模存储。
在对象存储的发展中,有两个对象存储协议值得一提:Swift和S3 (Simple Storage Service)。前者源于OpenStack项目,后者来自于Amazon公司。
如今作为对象存储协议,Swift很少被提及,而Amazon的S3已经成为业界的事实标准,每个对象存储系统都会提供与Amazon S3 RESTful API兼容的服务。
例如,OpenStack Swift除了提供自己的Swift Open API和一些独特的功能,还支持Amazon的S3 API;Ceph对象存储和Openio.io与S3兼容。

02
Ceph存储系统实现
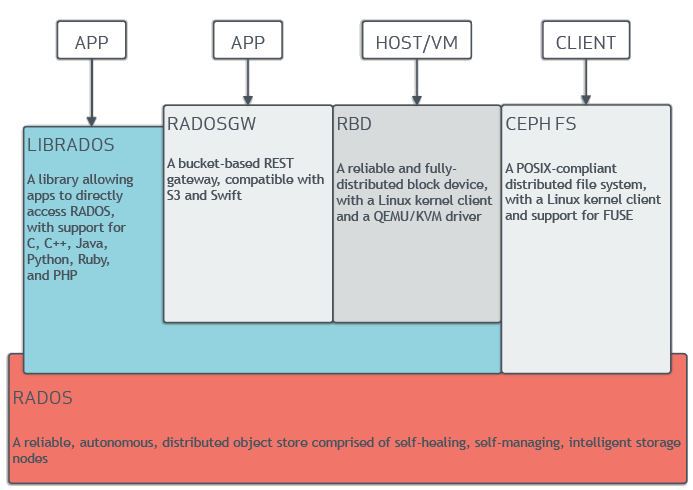
基于同一套存储基础设施,Ceph同时提供了文件、块、对象三种数据访问接口,Ceph逻辑层次如下图所示:
-
RADOS本身是一个完整的对象存储系统,所有存储在Ceph中的数据最终都是由这一层来存储的。Ceph的高可靠、高可扩展、高性能、高自动化等特性,本质上也是由这一层提供的;
-
LIBRADOS是对Ceph客户端与RADOS集群交互协议的封装,基于librados,我们可以创建自己的客户端;
-
RADOS GW、RBD、CEPH FS属于高层接口,它们在librados库的基础上分别提供对象存储接口、文件接口和块存储接口。
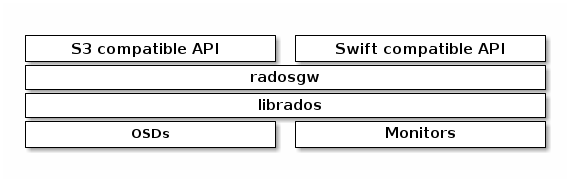
其中RADOS GW为应用访问Ceph集群提供了一个与Amazon S3和Swift兼容的RESTful风格的网关,其逻辑层次如下:
>>> Ceph RADOS存储集
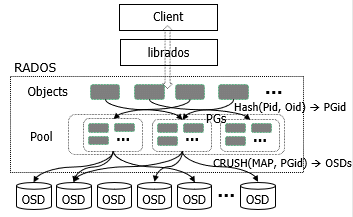
RADOS集群主要有两种节点:为数众多的OSD节点,负责完成数据的存储和维护;若干Monitor节点,负责完成系统状态检测和维护。
OSD和Monitor之间互相传递节点的状态信息,共同得出系统的总体运行状态。
而根据集群总体运行状态,基于CRUSH算法,用户上传的数据经过层层映射,最终会送到不同的OSD上面:
-
用户上传的数据被切割为固定大小的分片;
-
根据规则,每个数据分片都有其唯一的ID,每个数据分片独立的映射到不同的逻辑归置组(PG);
-
基于CRUSH算法,确定逻辑归置组锁对应的 OSD。
>>> Ceph ObjectStore
数据切片后,最终会落到不同的OSD上,Ceph OSD通过ObjectStore完成数据的实际存储。
ObjectStore由不同的实现方式,有FileStore、BlueStore、MemStore等等。
其中MemStore主要用于测试目的。
FileStore基于Linux现有的文件系统,利用传统的文件系统操作实现ObjectStore API:每个Object被FileStore看做是一个文件,Object的属性会作为文件的属性(xattr)存取,而超出文件系统限制的属性会作为omap存储。
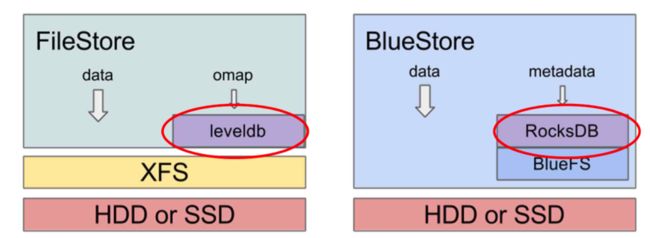
FileStore最初是针对机械盘设计的,写数据之前先写journal带来了写放大问题。为了解决FileStore存在的问题,Ceph社区推出了BlueStore。
BlueStore去掉了journal,通过直接管理裸设备的方式来减少文件系统的部分开销。
和传统的文件系统一样,BlueStore由3个部分组成:数据管理、元数据管理、空间管理(Allocator)。
BlueStore不再基于本地文件系统,而是直接管理裸设备,为此在用户态实现了BlockDevice,使用Linux AIO直接对裸设备进行I/O操作,并实现了Allocator对裸设备进行空间管理。
BlueStore的元数据则以Key/Value的形式保存在KV数据库中,默认RocksDB。但RocksDB并不是基于裸设备进行操作的,而是基于文件系统进行操作的,为此BlueStore还实现了一个小的文件系 BlueFS。
* Ceph 的强一致性实现依赖于 RocksDB 提供的事务特性。
03
OpenStack Swift存储系统实现
Swift 架构可以划分为两个层次:访问层(Access Tier) 和存储层(Storage Nodes)。
访问层的功能类似于网络设备中的 Hub,主要负责 RESTful 请求的处理与用户身份的认证。
存储层由一系列的物理存储节点组成,负责对象数据的存储。
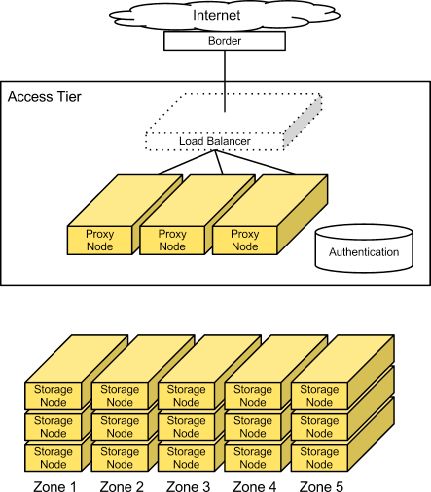
Storage Node上存储的对象在逻辑上分层3个层次:Account、Container 以及 Object。
为了对应这3个层次,每个Storage Node上运行了3种服务:
-
Account Server - 提供Account相关服务,包括Container列表以及Account的元数据等。Account的信息被存储在一个SQLite数据库中;
-
Container Server - 提供Container相关服务,包括Object列表以及Container的元数据。Conainer的信息也被存储在一个SQListe数据库中;
-
Object Server - 提供Object的存取和元数据服务。对象的内容以二进制文件的形式存储在文件系统中,元数据作为文件的扩展属性来存储。
为了保证数据在某个存储硬件损坏的情况下也不会丢失,Swift为每个对象建立了一定数量的副本,默认为3,并将每个副本放在不同的逻辑区域中。
Swift通过3种服务来解决数据一致性问题:
-
Auditor - 持续扫描磁盘检查Account、Container和Object的完整性,如果发现数据有损坏的情况,就会对文件进行隔离,然后通过Replicator从其他节点上获取对应的副本以恢复本地数据;
-
Updater - 创建一个Container或者Object时,更新SQLite中相应的信息。更新并不总是成功,对于那些没有成功更新的操作Swift会通过Updater服务继续处理;
-
Replicator - 负责检测各个节点上的数据及其副本是否一致,当发现不一致时会将过时的副本更新为最新版本,并负责将标记为删除的数据真正从物理介质上删除。
Swift 通过 Consistent Hash Ring 来实现对集群中物理节点的管理。
由于没有条带化,Swift处理几个G的大文件时性能会比较差,不过作为对象存储,Swift的优势在于它能与OpenStack社区的其他项目无缝结合。
Part 4
结语
计算机世界里没有“银弹”,任何设计都有其取舍,存储系统亦是如此。基于其特定的应用场景,不同的存储实现提供了不同的数据访问方式以及存储能力。
但是本质上,所有的存储系统都在解决“数据如何保存”和“数据如何访问”的问题。尽管Ceph和OpenStack Swift出现已久,但是它们的设计仍值得借鉴。本文仅分析了Ceph和OpenStack Swift的宏观架构,感兴趣的朋友可以从文章末尾给出的参考链接中获取更多细节。
目前,矩阵起源的对象存储正在设计和原型阶段,未来还会分享我们在这方面的一些实践,敬请关注。
Part 5
参考链接
* IBM Cloud Learn Hub: Object Storage [https://www.ibm.com/cloud/learn/object-storage]
* Object Storage: Everything You Need to Know [https://lakefs.io/object-storage/]
* Amazon S3 REST API Introduction [https://docs.aws.amazon.com/AmazonS3/latest/API/Welcome.html]
* OpenIO on Github [https://github.com/open-io]
* Ceph on Github [https://github.com/ceph/ceph]
* Ceph Documents [https://docs.ceph.com/en/latest/]
* Swift Document [https://docs.openstack.org/swift/latest/getting_started.html]
* Linux 开源存储全栈详解 [https://book.douban.com/subject/34815557/]
作为一家数据库创业公司,矩阵起源在数据库方面汇集了众多经验丰富的工程师,分布式数据库内核开发涉及计算引擎、存储引擎和分布式这几个方面。
那这篇讲对象存储的文章会不会有些“偏题”?对象存储和存储引擎是一回事吗?首先它们都跟存储有关,但是各自要解决的问题不同,因而在技术上也各有侧重。对象存储和存储引擎都是比较大的话题,这篇文章作为铺垫是合适的。
在后面的文章中,我们会继续把对象存储和存储引擎放在一起做个简单的比较。