多尺度特征融合总结(金字塔结构)
多尺度特征融合
参考连接:
多尺度融合介绍
MTCNN论文解读
图像金字塔----高斯和拉普拉斯
一、什么是多尺度?
所谓多尺度,实际上就是对信号的不同粒度的采样,通常在不同的尺度下我们可以观察到不同的特征,从而完成不同的任务
通常来说粒度更小/更密集的采样可以看到更多的细节,粒度更大/更稀疏的采样可以看到整体的趋势
二、深浅层蕴含的不同信息
- 深层网络的感受野比较大,语义信息表征能力强,但是特征图的分辨率低,几何信息的表征能力弱(空间几何特征细节缺乏)
- 低层网络的感受野比较小,几何细节信息表征能力强,虽然分辨率高,但是语义信息表征能力弱
下采样倍数小(一般是浅层)的特征感受野小,适合处理小目标,小尺度特征图(深层)分辨率信息不足不适合小目标。在yolov3中对多尺度检测的理解是,1/32大小的特征图(深层)下采样倍数高,所以具有大的感受野,适合检测大目标的物体,1/8的特征图(较浅层)具有较小的感受野,所以适合检测小目标
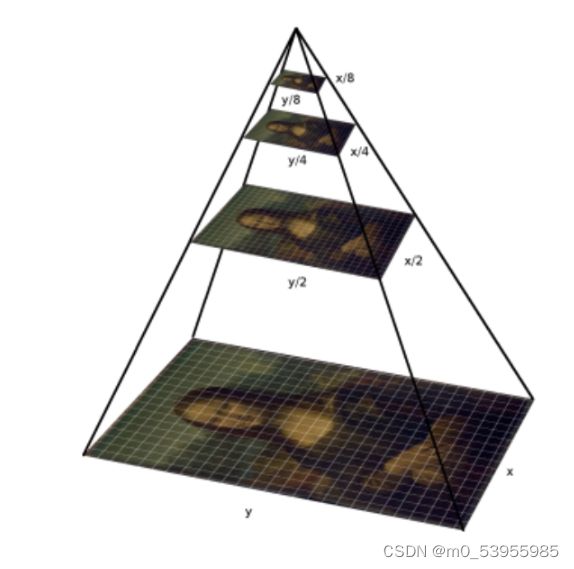
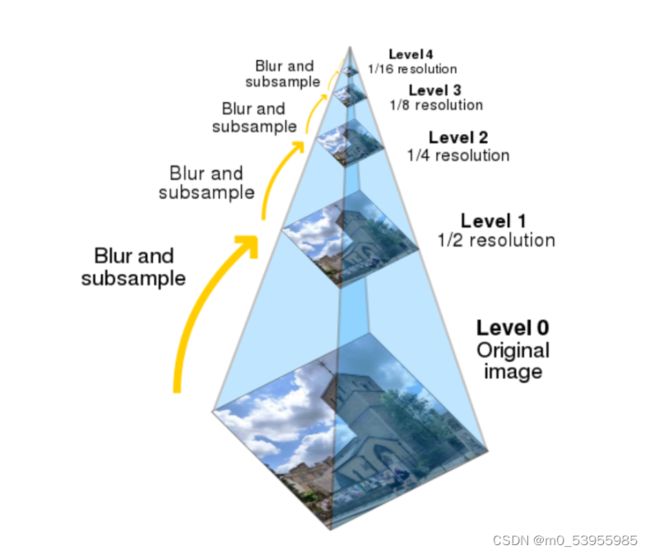
三、图像金字塔和特征金字塔
3.1 图像金字塔
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
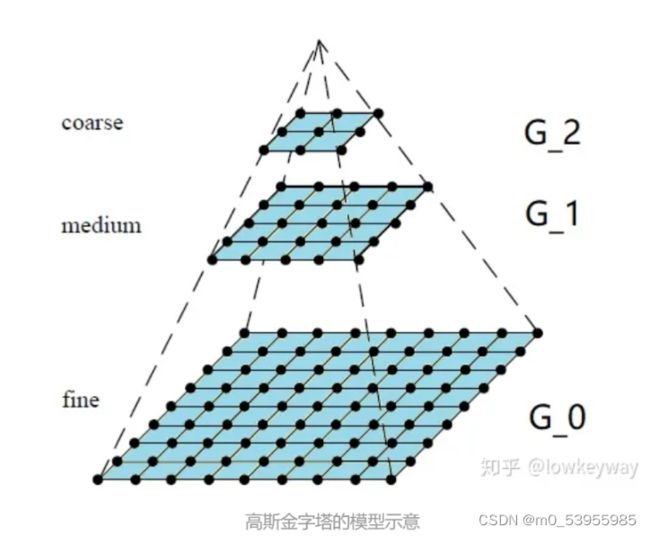
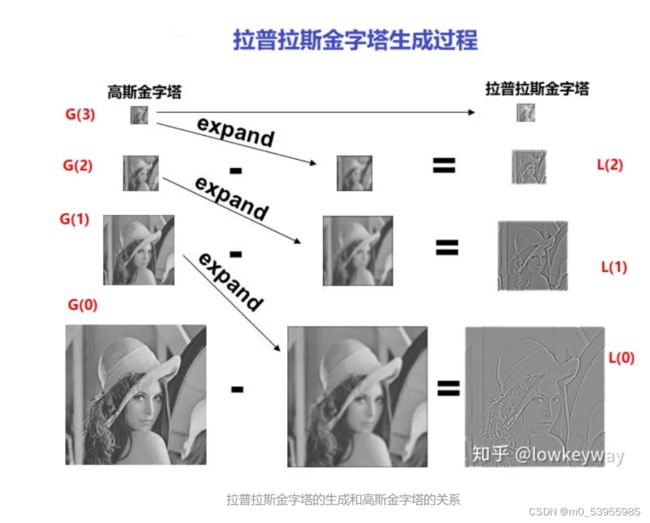
3.2 拉普拉斯金字塔
拉普拉斯金字塔:用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。达到一种增强的效果。
3.3 特征金字塔
DEF:利用特征图构建的图像金字塔
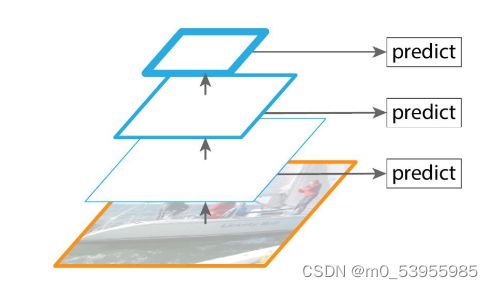
蓝色线条越粗表示语义特征越强
不同大小的目标都可以在相应的尺度下拥有合适的特征表示,通过融合多尺度信息,在不同尺度下对不同大小的目标进行预测,可以很好地提升模型的性能。
对于小目标的检测而言:
- 小尺度feature map无法提供必要的分辨率信息,所以应需结合大尺度的feature map
- 在深层图,做下采样损失过多信息,小目标信息或许已经被忽略。
由此,将深浅层特征的融合是完成检测小目标任务的一个解决办法。 如何更好地融合不同尺度的信息是重点研究的问题
四、利用多尺度信息的不同阶段
由于多尺度特征网络结构比较灵活,没有清晰的界限,粗略可把网络结构可以分为以下几种:
- 多尺度输入
- 多尺度特征融合
- 多尺度特征预测融合
4.1 多尺度输入网络
使用多个尺度的图像输入 (图像金字塔),然后将其结果进行融合
4.1.1 MTCNN
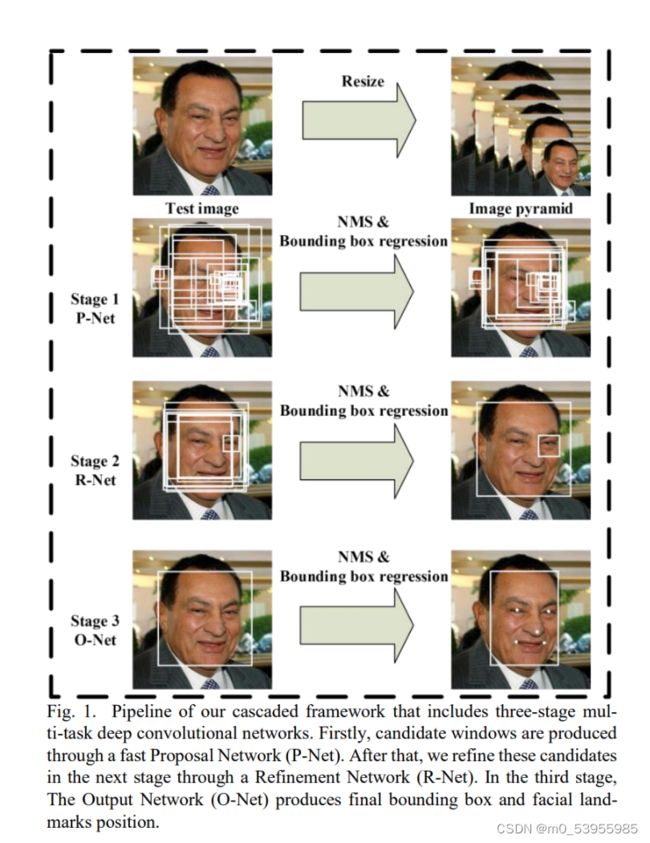
输入:原始图片reaize到不同尺寸,将这一组图片作为输入
因为图片上不同人脸的大小可能不一致。resize到不同尺寸图片,可以检测不同大小的人脸信息。
首先,对原图通过双线性插值构建图像金字塔。构建好金字塔后,将金字塔中的图像逐个输入给P-Net。
- P-Net:其实是个全卷积神经网络(FCN),前向传播得到的特征图在每个位置是个32维的特征向量,用于判断每个位置处约12×12大小的区域内是否包含人脸,如果包含人脸,则回归出人脸的Bounding Box,进一步获得Bounding Box对应到原图中的区域,通过NMS保留分数最高的Bounding box以及移除重叠区域过大的Bounding Box。
- O-Net:是单纯的卷积神经网络(CNN),先将P-Net认为可能包含人脸的Bounding Box 双线性插值到24×24,输入给O-Net,判断是否包含人脸,如果包含人脸,也回归出Bounding Box,同样经过NMS过滤。
- R-Net:也是纯粹的卷积神经网络(CNN),将O-Net认为可能包含人脸的Bounding Box 双线性插值到48×48,输入给R-Net,进行人脸检测和关键点提取。
4.2 多尺度特征融合网络
多尺度特征融合网络常见的有两种,第一种是并行多分支网络,第二种是串行的跳层连接结构,都是在不同的感受野下进行特征提取。
4.2.1 并行多分支结构
比如 Inception 网络中的 Inception 基本模块,包括有四个并行的分支结构,分别是 1×1 卷积,3×3 卷积,5×5 卷积,3×3 最大池化,最后对四个通道进行组合
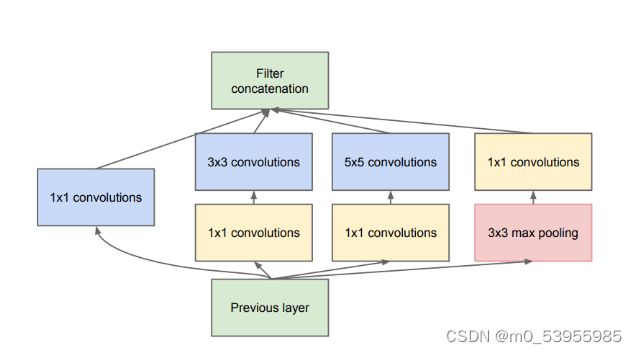
除了更高卷积核大小,还可以使用空洞卷积或者池化来控制感受野。在图像分割网络和目标检测网络中都使用了这样的策略。
1. SPP——SPPNet
Motivation:对于不同的输入总能得到需要的特征数量,而不用固定卷积层的输入尺寸
黑色图片代表卷积之后的特征图,接着我们以不同大小的块来提取特征,分别是4×4,2×2,1×1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化SPP
比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出
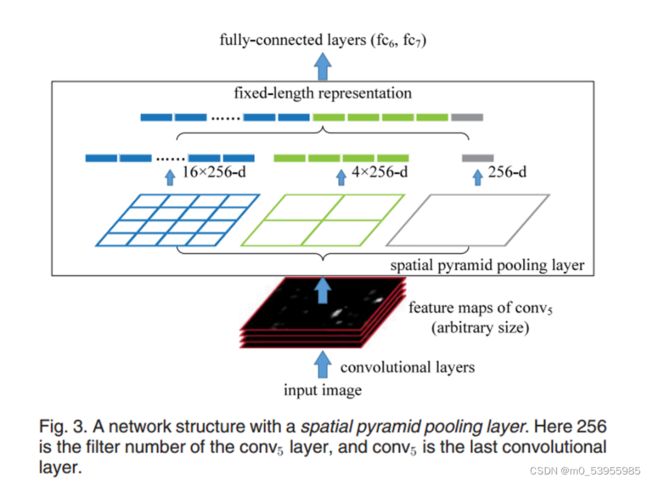
256是通道数,卷积核个数等于通道数
2. ASPP——DeepLab V2
空洞卷积
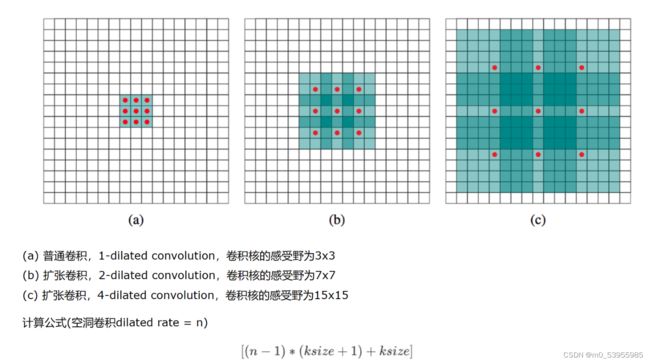
首先要介绍Atrous Convolution(空洞卷积)。和之前的non-local一样,都是为了增加感受野的方法。空洞卷积是是为了解决基于FCN思想的语义分割中,输出图像的size要求和输入图像的size一致而需要upsample的问题。
但由于FCN中使用pooling操作来增大感受野同时降低分辨率,导致upsample无法还原由于pooling导致的一些细节信息的损失的问题而提出的。为了减小这种损失,自然需要移除pooling层,因此空洞卷积应运而生
ASPP
受到SPPNet启发,通过对在单个尺度上提取的卷积特征进行重采样,可以准确有效地对任意比例的区域进行分类。DeepLab V2实现了这个方案的变体,它使用具有不同采样率的多个并行的空洞卷积层。为每个采样率提取的特征将在单独的分支中进一步处理并融合以生成最终结果

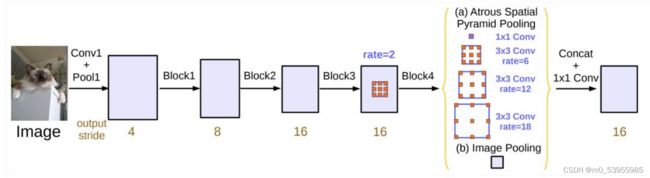
3. PSPNet
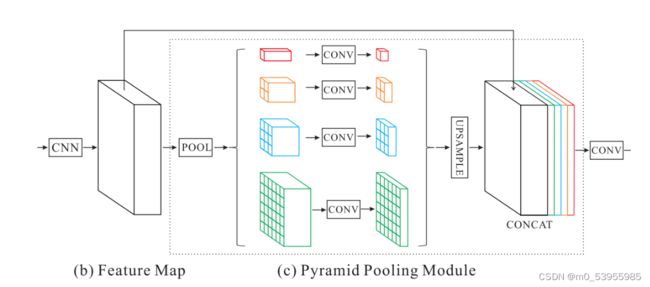
Motivation:为了使得CNN的感受野大到足以捕捉全局信息;多尺度特征融合,高层特征具有更多的语义和全局上下文信息,底层特征包含细节信息
为了保持全局特征的权重,若如果金字塔的数量为 N,则在每个金字塔级别之后使用 1×1 卷积层将上下文表示的维度减小到原先的 1/N。然后直接对feature map进行双线性插值,恢复到输入的长宽上。最后,将不同level的特征拼接起来作为金字塔池化的全局特征。
4.2.2 串行多分支结构
从上面这些模型可以看出,并行的结构能够在同一层级获取不同感受野的特征,经过融合后传递到下一层,可以更加灵活地平衡计算量和模型能力。串行的结构将不同抽象层级的特征进行融合,对于边界敏感的图像分割任务是不可缺少的
1. FPN——对SSD进行改进
Motivation:大多数方法为了检测速度而尽可能的去避免使用特征金字塔,而是只使用高层的特征来进行预测。高层的特征虽然包含了丰富的语义信息,但是由于低分辨率,很难准确地保存物体的位置信息。与之相反,低层的特征虽然语义信息较少,但是由于分辨率高,就可以准确地包含物体位置信息。所以如果可以将低层的特征和高层的特征融合起来,就能得到一个识别和定位都准确的目标检测系统。所以本文就旨在设计出这样的一个结构来使得检测准确且快速。
backbone可以分为浅层网络和深层网络,浅层网络负责提取目标边缘等底层特征,而深层网络可以构建高级的语义信息,通过使用FPN这种方式,让深层网络更高级语义的部分的信息能够融合到稍浅层的网络,指导浅层网络进行识别。
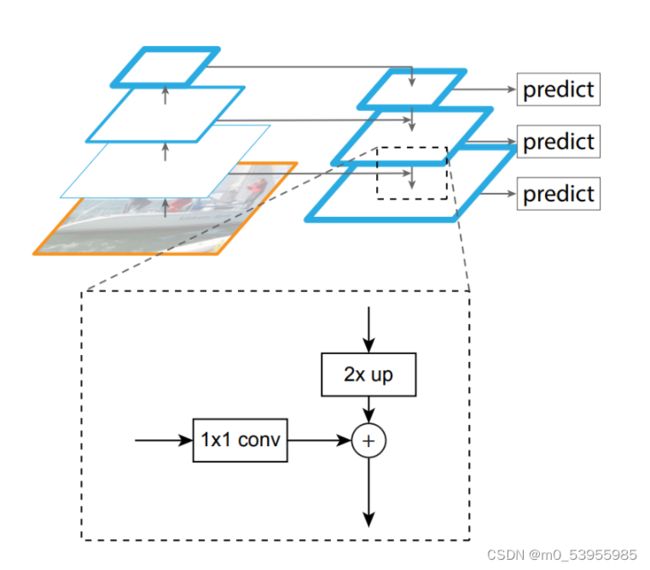
图中我们在第1层输出较大目标的实例分割结果,在第2层输出中型目标的实例检测结果,在第3层输出较小目标的实例分割结果。因为在大的feature map上进行操作,可以获得更多关于小目标的有用信息;检测也是一样,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标。
2. U-Net
Motivation:对FCN进行改进,获得更好的分割细节
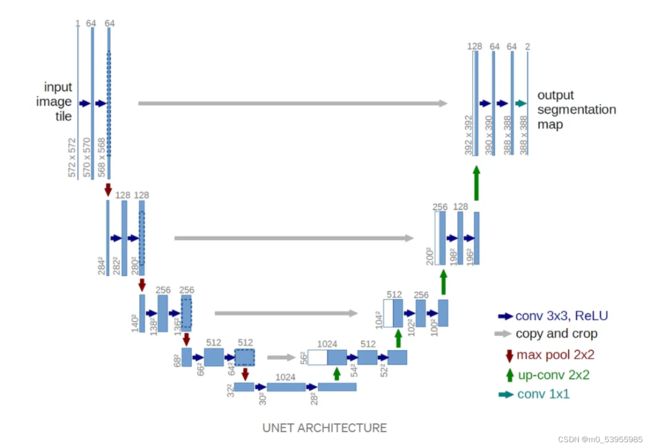
Encoder
编码器网络充当特征提取器,并通过一系列编码器块学习输入图像的抽象表示
Skip Connections
跳层连接帮助解码过程中可以获得更好的语义特征,简单来说,我们可以说跳过连接有助于在反向传播时更好地更新梯度,这反过来又有助于网络学习更好的表示。
Decoder
解码器网络用于获取抽象表示并生成语义分割掩码。
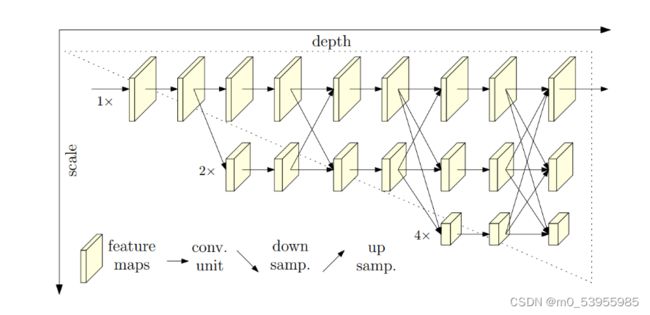
3. HRNet
Motivation:HRNet通过并行多个分辨率的分支,加上不断进行不同分支之间的信息交互,同时达到强语义信息和精准位置信息的目的。
将HRNet整个backbone部分进行拆解,分成4个stage,每个stage分成蓝色框和橙色框两部分。其中蓝色框部分是每个stage的基本结构,由多个branch组成,HRNet中stage1蓝色框使用的是BottleNeck,stage2&3&4蓝色框使用的是BasicBlock。其中橙色框部分是每个stage的过渡结构,HRNet中stage1橙色框是一个TransitionLayer,stage2&3橙色框是一个FuseLayer和一个TransitionLayer的叠加,stage4橙色框是一个FuseLayer。
FuseLayer是用来进行不同分支的信息交互的,TransitionLayer是用来生成一个下采样两倍分支的输入feature map的;
stage1橙色框显然没办法做FuseLayer,因为前一个stage只有一个分支,stage4橙色框后面接neck和head了,显然也不再需要TransitionLayer了
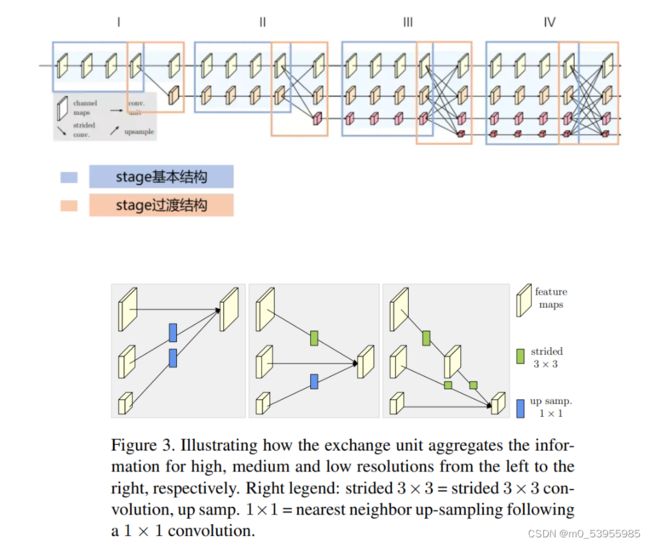
上采样:1*1 conv --> BN --> 插值
下采样:k=3,stride=2,padding=1
4. PANet
Motivation:网络的浅层特征对于实例分割非常重要,浅层特征中包含大量边缘形状等特征,这对实例分割这种像素级别的分类任务是起到至关重要的作用的
FPN已经证明了加入一条top-down的旁路连接,能给feature增加high-level的语义性有利于分类。
但是low-level的feature是很利于定位用的,虽然FPN中P5也间接得有了low-level的特征,但是信息流动路线太长了如红色虚线所示(其中有ResNet50/101很多卷积层),这样浅层信息丢失的情况比较严重
本文在FPN的P2-P5又加了low-level的特征,最底层的特征流动到N2-N5只需要经过很少的层如绿色需要所示(仅仅有几个降维的卷积)
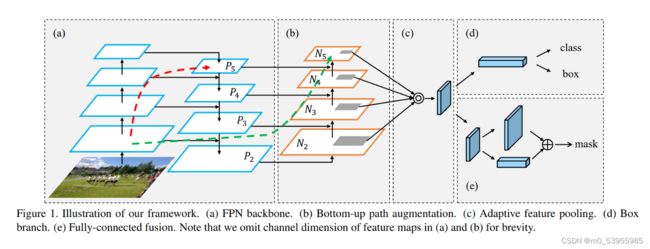
To shorten information path and enhance feature pyramid with accurate localization signals existing in low-levels
PANet 因此在自上向下的FPN网络结构中额外增加了自底向上的路径聚合模块,将低层特征图的信息又传导到高层中特征图去,同时在自上向下的路径中减少了高层特征图到低层特征图的信息流通需要穿过的卷积层的数量。
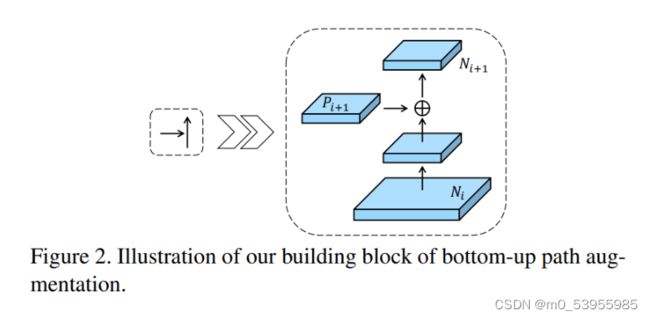
N i N_i Ni经过一个尺寸为 3 × 3 3×3 3×3,步长为 2 2 2的卷积之后,特征图尺寸减小为原来的一半然后和 P i + 1 P_{i+1} Pi+1这个特征图做add操作,得到的结果再经过一个卷积核尺寸为 3 × 3 3×3 3×3, s t r i d e = 1 stride=1 stride=1的卷积层得到 N i + 1 N_{i+1} Ni+1
5. BiFPN
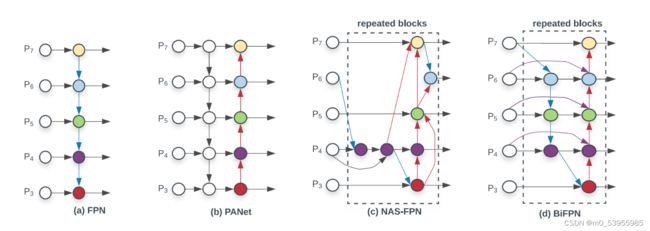
Motivation:PANet比FPN有更好的效果,但是计算量和参数量更大,为了提高效率提出BiFPN
- 删除那些只有一个输入边的节点。作者认为:如果一个节点只有一条输入边而没有特征融合,那么它对融合不同特征的特征网络的贡献就会更小
- 我们添加一个跳跃连接,在同一尺度的输入节点到输出节点之间加一个跳跃连接,因为它们在相同层,在不增加太多计算成本的同时,融合了更多的特征
- 与PANet 仅有一个自顶向下和一个自底向上的路径不同,我们将每个双向(自顶向下和自底向上)路径看作一个特征网络层(repeated blocks),并多次重复同一层,以实现更高层次的特征融合
4.3 多尺度特征输出网络
SSD
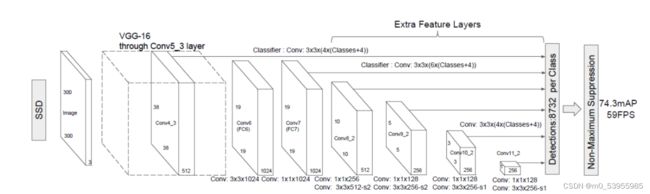
在不同尺度的特征图上进行检测
大尺度特征图可以用来检测小物体,而小尺度特征图用来检测大物体
它放弃了前面的low-level的feature map,而是从conv4_3开始用而且在后面加了一些conv,生成更多高层语义的feature map在上面检测
虽然 SSD 在多层特征图进行预测,但是相对于 Faster R-CNN, 小目标的检测结果并未能够得到明显的改善.其主要原因可能在于,浅层的特征层虽然有着较小的感受野,但特征表示能力相对于深层特征要弱很多.