【Flink】Flink中的窗口API、窗口函数以及迟到数据处理问题
目录
一、窗口
1、窗口的概念
2、窗口的分类
(1)按照驱动类型分类——时间窗口和计数窗口
(2)按照窗口分配数据的规则分类
3、窗口 API
(1)按键分区窗口(Keyed Windows)
(2)非按键分区(Non-Keyed Windows)
(3)窗口 API 的调用
4、窗口分配器
(1)滚动处理时间窗口
(2)滑动处理时间窗口
(3)处理时间会话窗口
(4)滚动事件时间窗口
(5)滑动事件时间窗口
(6)事件时间会话窗口
(7)滚动计数窗口
(8)滑动计数窗口
5、窗口函数
(1)增量聚合函数(incremental aggregation functions)
(2)全窗口函数(full window functions)
(3)增量聚合和全窗口函数的结合使用
6、其他 API
(1)触发器(Trigger)
(2)移除器(Evictor)
(3)允许延迟(Allowed Lateness)
(4)将迟到的数据放入侧输出流
7、窗口的生命周期
(1) 窗口的创建
(2)窗口计算的触发
(3)窗口的销毁
二、迟到数据的处理
1、设置水位线延迟时间
2、允许窗口处理迟到数据
3、将迟到数据放入窗口侧输出流
一、窗口
1、窗口的概念
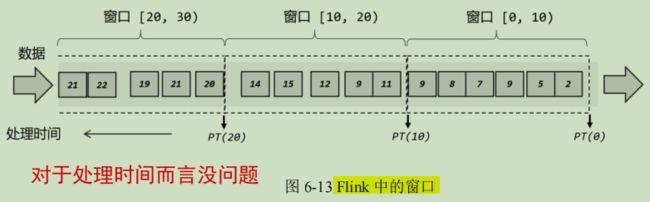

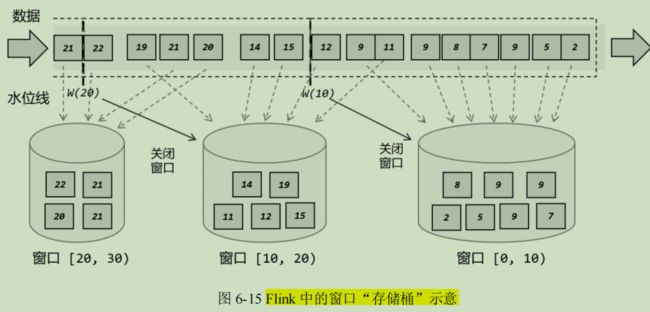
2、窗口的分类
(1)按照驱动类型分类——时间窗口和计数窗口

Flink 中有一个专门的类来表示时间窗口,名称就叫作 TimeWindow。这个类只有两个私有属性:start 和 end,表示窗口的开始和结束的时间戳,单位为毫秒。
在 Flink 内部也并没有对应的类来表示计数窗口,底层是通过“全局窗口”(Global Window)来实现的。
(2)按照窗口分配数据的规则分类
- 滚动窗口(Tumbling Windows)
- 滑动窗口(Sliding Windows)
- 会话窗口(Session Windows)
- 全局窗口(Global Windows)
3、窗口 API
(1)按键分区窗口(Keyed Windows)
stream.keyBy(...)
.window(...)(2)非按键分区(Non-Keyed Windows)
stream.windowAll(...)(3)窗口 API 的调用
stream.keyBy()
.window()
.aggregate() 4、窗口分配器
窗口分配器其实就是在指定窗口的类型。窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。标准的声明方式就是直接调用.window(),在里面传入对应时间语义下的窗口分配器。我们不需要专门定义时间语义,默认就是事件时间;如果想用处理时间,那么在这里传入处理时间的窗口分配器就可以了。
(1)滚动处理时间窗口
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
// 得到北京时间每天 0 点开启的滚动窗口
// 只要设置-8 小时的偏移量就可以了:
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))(2)滑动处理时间窗口
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)(3)处理时间会话窗口
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)(4)滚动事件时间窗口
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5))) .aggregate(...)(5)滑动事件时间窗口
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)(6)事件时间会话窗口
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)(7)滚动计数窗口
stream.keyBy(...)
.countWindow(10)(8)滑动计数窗口
stream.keyBy(...)
.countWindow(10,3)(9)全局窗口
stream.keyBy(...)
.window(GlobalWindows.create());5、窗口函数
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream。窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。

(1)增量聚合函数(incremental aggregation functions)
- 归约函数(ReduceFunction)
stream.keyBy(r -> r.f0)
// 设置滚动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction>() {
@Override
public Tuple2 reduce(Tuple2 value1, Tuple2 value2) throws Exception {
// 定义累加规则,窗口闭合时,向下游发送累加结果
return Tuple2.of(value1.f0,value1.f1+value2.f1);
}
}).print(); - 聚合函数(AggregateFunction)
// 使用AggregateFunction实现PV/UV
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 确定时间戳和水位线,取出字段中的时间戳
SingleOutputStreamOperator stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
// 所有数据设置相同的key,发送到同一个分区内统计PV和UV,再相除
stream.keyBy(r -> "chris")
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(2)))
.aggregate(new AvgPV())
.print();
env.execute();
}
// 自定义 aggregate 方法
public static class AvgPV implements AggregateFunction,Long>,Double> {
@Override
public Tuple2, Long> createAccumulator() {
// 创建累加器
return Tuple2.of(new HashSet<>(),0L);
}
@Override
public Tuple2, Long> add(Event event, Tuple2, Long> accumulator) {
// 属于本窗口的数据,来一条累加一条,并返回累加器
accumulator.f0.add(event.user);
return Tuple2.of(accumulator.f0,accumulator.f1+1L);
}
@Override
public Double getResult(Tuple2, Long> accumulator) {
// 窗口闭合时,增量聚合结束,将计算结果发送到下游
return (double) accumulator.f1 / accumulator.f0.size();
}
@Override
public Tuple2, Long> merge(Tuple2, Long> hashSetLongTuple2, Tuple2, Long> acc1) {
return null;
}
} (2)全窗口函数(full window functions)
全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。很明显,这就是典型的批处理思路了——先攒数据,等一批都到齐了再正式启动处理流程,这样做毫无疑问是低效的。
- 窗口函数(WindowFunction)
stream
.keyBy()
.window()
.apply(new MyWindowFunction()); - 处理窗口函数(ProcessWindowFunction)
// 自定义窗口处理函数
public static class UvCountByWindow extends ProcessWindowFunction{
@Override
public void process(Boolean aBoolean, Context context, Iterable elements, Collector out) throws Exception {
HashSet userSet = new HashSet<>();
// 遍历所有数据,放到Set里去重
for (Event event: elements){
userSet.add(event.user);
}
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect("窗口: " + new Timestamp(start) + " ~ " + new Timestamp(end)
+ " 的独立访客数量是:" + userSet.size());
}
} (3)增量聚合和全窗口函数的结合使用
// 按照url分组,开滑动窗口统计
stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
// 同时传入 增量聚合函数 和 全窗口函数
.aggregate(new urlCountAgg(),new urlCountResult())
.print();
// 自定义增量聚合函数,来一条数据就加一条
public static class urlCountAgg implements AggregateFunction {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long accumulator) {
return accumulator+1;
}
@Override
public Long getResult(Long aLong) {
return aLong;
}
@Override
public Long merge(Long aLong, Long acc1) {
return null;
}
}
// 自定义窗口处理函数,只需要包装窗口信息
public static class urlCountResult extends ProcessWindowFunction {
@Override
public void process(String url, ProcessWindowFunction.Context context, Iterable iterable, Collector collector) throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
// 迭代器中只有一个元素,就是增量聚合函数的计算结果
collector.collect(new UrlViewCount(url,iterable.iterator().next(),start,end));
}
} 6、其他 API
(1)触发器(Trigger)
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())(2)移除器(Evictor)
stream.keyBy(...)
.window(...)
.evictor(new MyEvictor())- evictBefore():定义执行窗口函数之前的移除数据操作
- evictAfter():定义执行窗口函数之后的以处数据操作
(3)允许延迟(Allowed Lateness)
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))(4)将迟到的数据放入侧输出流
DataStream stream = env.addSource(...);
OutputTag outputTag = new OutputTag("late") {};
winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
DataStream lateStream = winAggStream.getSideOutput(outputTag); 7、窗口的生命周期
(1) 窗口的创建
(2)窗口计算的触发
(3)窗口的销毁
二、迟到数据的处理
1、设置水位线延迟时间
2、允许窗口处理迟到数据
3、将迟到数据放入窗口侧输出流
// 处理迟到数据的综合案例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取socket文本流
SingleOutputStreamOperator stream = env.socketTextStream("localhost", 7777)
.map(new MapFunction() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split(" ");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
})
// 方式一:设置watermark延迟时间,2秒钟
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 定义侧输出流标签
OutputTag outputTag = new OutputTag("late"){};
SingleOutputStreamOperator result = stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 方式二:允许窗口处理迟到数据,设置1分钟的等待时间
.allowedLateness(Time.minutes(1))
// 方式三:将最后的迟到数据输出到侧输出流
.sideOutputLateData(outputTag)
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult());
result.print("result");
result.getSideOutput(outputTag).print("late");
// 为方便观察,可以将原始数据也输出
stream.print("input");
env.execute();
}
public static class UrlViewCountAgg implements AggregateFunction {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
public static class UrlViewCountResult extends ProcessWindowFunction {
@Override
public void process(String url, Context context, Iterable elements, Collector out) throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}