Flink 窗口函数(Window Functions)处理迟到数据
文章目录
- 将迟到的数据放入侧输出流
Lambda架构:用一个流处理器,先快速的得到一个正确,近似正确的结果,然后在另外一层是一个批处理器,然后在它是一直等着的,等所有数据都到齐了,计算出一个最终准确的结果,更新最终的结果,得到一个最终正确的结果。
将迟到的数据放入侧输出流
我们自然会想到,即使可以设置窗口的延迟时间,终归还是有限的,后续的数据还是会被丢弃。如果不想丢弃任何一个数据,又该怎么做呢?
Flink 还提供了另外一种方式处理迟到数据。我们可以将未收入窗口的迟到数据,放入“侧输出流”(side output)进行另外的处理。所谓的侧输出流,相当于是数据流的一个“分支”,这个流中单独放置那些错过了该上的车、本该被丢弃的数据。
基于 WindowedStream 调用.sideOutputLateData() 方法,就可以实现这个功能。方法需要传入一个“输出标签”(OutputTag),用来标记分支的迟到数据流。因为保存的就是流中的原始数据,所以 OutputTag 的类型与流中数据类型相同。
DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
将迟到数据放入侧输出流之后,还应该可以将它提取出来。基于窗口处理完成之后的DataStream,调用.getSideOutput()方法,传入对应的输出标签,就可以获取到迟到数据所在的流了。
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
这里注意,getSideOutput()是 SingleOutputStreamOperator 的方法,获取到的侧输出流数据类型应该和 OutputTag 指定的类型一致,与窗口聚合之后流中的数据类型可以不同。
调用.allowedLateness()指定允许延迟时间、调用.sideOutputLateData()将迟到数据写入侧输出流,这些都是可选的 API,一般不需要实现。而如果定义了侧输出流,可以基于窗口聚合之后的 DataStream 调用.getSideOutput()获取侧输出流
stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(10)) //允许10秒钟数据迟到延迟
.sideOutputLateData(late)
.aggregate(new UrlCountViewExample.UrlViewCountAgg(), new UrlCountViewExample.UrlViewCountResult());
//计算后的数据
result.print("result");
//侧输出流的数据
result.getSideOutput(late).print("late");
类比班车的例子,我们可以这样理解:大多数人是在发车时刻前后到达的,所以我们只要把表调慢,稍微等一会儿,绝大部分人就都上车了,这个把表调慢的时间就是水位线的延迟;到点之后,班车就准时出发了,不过可能还有该来的人没赶上。于是我们就先慢慢往前开,这段时间内,如果迟到的人抓点紧还是可以追上的;如果有人追上来了,就停车开门让他上来,然后车继续向前开。当然我们的车不能一直慢慢开,需要有一个时间限制,这就是窗口的允许延迟时间。一旦超过了这个时间,班车就不再停留,开上高速疾驰而去了。
代码如下:Gitee上的源代码
public class LateDataTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据,并提取时间戳、生成水位线
DataStream<Event> stream = env.socketTextStream("hadoop102",8888)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split(" ");
return new Event(fields[0].trim(),fields[1].trim(),Long.valueOf(fields[2].trim()));
}
})
//允许数据延迟一秒触发计算
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
//每一条的数据
stream.print("input");
//定义一个输出标签
OutputTag<Event> late = new OutputTag<Event>("late"){};
//统计每个url的访问量
SingleOutputStreamOperator<UrlViewCount> result = stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(10)) //允许10秒钟数据迟到延迟
.sideOutputLateData(late)
.aggregate(new UrlCountViewExample.UrlViewCountAgg(), new UrlCountViewExample.UrlViewCountResult());
//计算后的数据
result.print("result");
//侧输出流的数据
result.getSideOutput(late).print("late");
env.execute();
}
}
我们还是先启动 nc –lk 8888,然后依次输入以下数据:
Bob ./home 1000
Bob ./home 2000
Bob ./home 3000
Bob ./home 4000
Bob ./home 5000
Bob ./home 6000
Bob ./home 7000
Bob ./home 8000
Bob ./home 9000
Bob ./home 11000
Bob ./home 13000
Bob ./home 15000
Bob ./home 16000
Bob ./home 4000
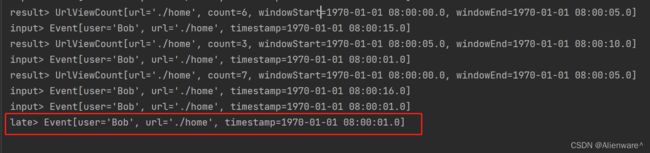
我们来分析一下程序的运行过程。当输入数据到[Bob ./home 4000]时,时间戳为4000,由于设置了 1 秒钟的水位线延迟时间,所以此时水位线到达了 4 秒(事实上是 3999毫秒,这里不再追究减 1 的细节),并没有触发 [0, 5s) 窗口的计算;所以接下来时间戳为 5000的数据到来,同样可以直接进入窗口做增量聚合。当时间戳为 6000 的数据到来时(无所谓url 是什么,所有数据都可以推动水位线前进),水位线到达了 6000 – 1 * 1000 = 5000,所以触发了[0, 5s) 窗口的计算,第一次输出了窗口统计结果,如下所示:
输入的每一条数据是input>
计算的结果是result>
迟到的侧输出流的数据是late>
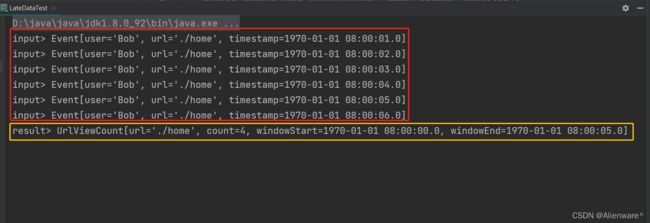
这里 count 值为 4,就包括了之前输入的时间戳为 1000、2000、3000、4000 的四条数据。不过窗口触发计算之后并没有关闭销毁,而是继续等待迟到数据。之后时间戳为 7000的数据继续推进水位线,此时时钟已经进展到了 6000ms;此时再来一条时间戳为 4000 的数据,我们会发现立即输出了一条统计结果:
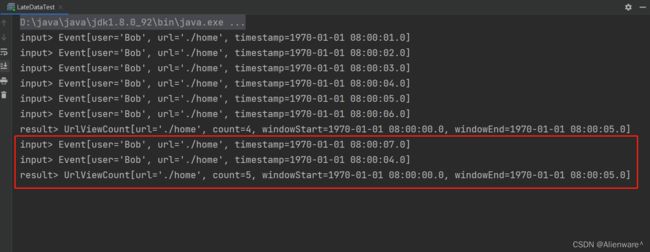
很明显,这仍然是[0, 5s) 的窗口,在之前计数值 4 的基础上继续叠加,更新统计结果为5。所以允许窗口处理迟到数据之后,相当于窗口有了一段等待时间,在这期间所有的迟到数据都会立即触发窗口计算,更新之前的结果。因此,之后时间戳为 3000 的数据到来,同样会立即输出:
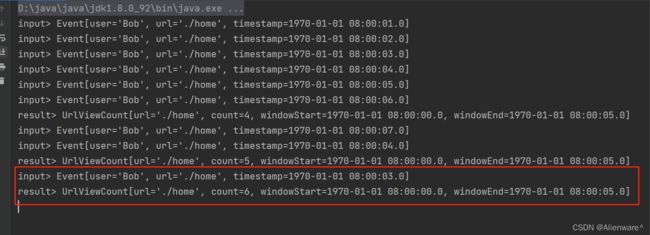
我们设置窗口等待的时间为 10 秒中,所以当时间推进到 5000 + 10 * 1000 = 15000 时,窗口就会真正被销毁。此前的所有迟到数据可以直接更新窗口的计算结果,而之后的迟到数据已经无法整合进窗口,就只能用侧输出流来捕获了。需要注意的是,这里的“时间”依然是由水位线来指示的,所以时间戳为 15000 的数据到来,并不会触发窗口的销毁;当时间戳为 16000的数据到来,水位线推进到了 16000 – 1 * 1000 = 15000,此时窗口真正销毁关闭,之后再来的迟到数据就会输出到侧输出流了: