数据库连接池实战学习笔记
数据库连接池实战学习
-
-
- 1. HikariCP
-
- 1.1 HikariCP 单数据源
- 1.2 HikariCP 多数据源
- 2. Druid
-
- 2.1 Druid 单数据源
-
- Druid 的监控功能
- 2.2 Druid 多数据源
- 3. Mybatis
-
- 3.1 Mybatis + XML
- 3.2 Mybatis-Plus
- 3.3 关于 Mybatis 的一些认识
- 4. Spring 多数据源
-
- 4.1 多数据源的使用场景
- 4.2 如何实现多数据源
- 5. Spring Boot 多数据源(读写分离)
-
- 5.1 概述
- 5.2 实现
- 5.3 Sharding-JDBC 多数据源
- 5.4 Sharding-JDBC 读写分离
- 5.5 Sharding-JDBC 分库分表
- 6. 数据库版本管理
-
- 6.1 Flyway
-
最近学习了一些常用数据库连接池的实战,将一些数据库的特点和要点记录下来。
主要学习了关系型数据库: hikari(号称性能最好的 Java 数据库连接池)、Druid(这两个数据库表现是很好的,比之前的 C3P0、DBCP、BoneCP 效果好太多,但是 Druid 主要用来做监控),mybatis、spring-data-jpa、spring-jdbc-template,以及关于读写分析和分库分表等的学习笔记。
非关系型数据库:redis、缓存 Cache、MongoDB、Elasticsearch 和 Soir。
1. HikariCP
号称性能最好的 Java 数据库连接池,且 Spring Boot 2.X 版本默认采用的连接池。
1.1 HikariCP 单数据源
pom.xml 中引入以下依赖: 无需主动引入 HikariCP 的依赖。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.25version>
<scope>runtimescope>
dependency>
spring:
#
datasource:
url: jdbc:mysql://127.0.0.1:3306/test1228?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: admin111111
#
hikari:
minimum-idle: 10
maximum-pool-size: 10
在 Application 类如下:
@SpringBootApplication
public class DatasourcePoolHikaricpApplication implements CommandLineRunner {
private final Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private DataSource dataSource;
public static void main(String[] args) {
SpringApplication.run(DatasourcePoolHikaricpApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
try (Connection conn = dataSource.getConnection()) {
//这里可以添加其他代码
logger.info("[run][获得连接:{}", conn);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
1.2 HikariCP 多数据源
依赖和单数据源一样。
spring:
datasource:
#
orders:
url: jdbc:mysql://127.0.0.1:3306/test1228?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: admin111111
#
hikari:
minimum-idle: 20
maximum-pool-size: 20
users:
url: jdbc:mysql://127.0.0.1:3306/test1228?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: admin111111
#
hikari:
minimum-idle: 15
maximum-pool-size: 15
数据源配置类,为了避免每个数据源都配置 Hikari 数据源导致匹配不到的问题,我们采用以下方式读取配置:
在 config 包下创建 DataSourceConfig:
@Configuration
public class DataSourceConfig {
/**
* 创建 “orders” 数据源的配置对象 DataSourceProperties
* @return
*/
@Primary //保证项目中有一个主 DataSourceProperties Bean
@Bean(name = "ordersDataSourceProperties")
@ConfigurationProperties(prefix = "spring.datasource.orders")
public DataSourceProperties ordersDataSourceProperties() {
return new DataSourceProperties();
}
/**
* 创建 orders 数据源
* @return
*/
@Bean(name = "ordersDataSource")
@ConfigurationProperties(prefix = "spring.datasource.orders.hikari")
public DataSource ordersDataSource() {
DataSourceProperties properties = this.ordersDataSourceProperties();
return createHikariDataSource(properties);
}
/**
* 创建 “users” 数据源的 DataSourceProperties
* @return
*/
@Bean(name = "usersDataSourceProperties")
@ConfigurationProperties(prefix = "spring.datasource.users")
public DataSourceProperties usersDataSourceProperties() {
return new DataSourceProperties();
}
/**
* 创建 users 数据源
* @return
*/
@Bean(name = "usersDataSource")
@ConfigurationProperties(prefix = "spring.datasource.users.hikari")
public DataSource usersDataSource() {
//
DataSourceProperties properties = this.usersDataSourceProperties();
//
return createHikariDataSource(properties);
}
private static HikariDataSource createHikariDataSource(DataSourceProperties properties) {
// 创建 HikariDataSource 对象
HikariDataSource dataSource = properties.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
// 设置线程池名
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
}
需要注意一下 @Primary注解,可以保证项目中有一个主要的 DataSourceProperties Bean
Application 类代码如下:
@SpringBootApplication
public class Application implements CommandLineRunner {
private Logger logger = LoggerFactory.getLogger(Application.class);
@Resource(name = "ordersDataSource")
private DataSource ordersDataSource;
@Resource(name = "usersDataSource")
private DataSource usersDataSource;
public static void main(String[] args) {
// 启动 Spring Boot 应用
SpringApplication.run(Application.class, args);
}
@Override
public void run(String... args) {
// orders 数据源
try (Connection conn = ordersDataSource.getConnection()) {
// 这里,可以做点什么
logger.info("[run][ordersDataSource 获得连接:{}]", conn);
} catch (SQLException e) {
throw new RuntimeException(e);
}
// users 数据源
try (Connection conn = usersDataSource.getConnection()) {
// 这里,可以做点什么
logger.info("[run][usersDataSource 获得连接:{}]", conn);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
2. Druid
2.1 Druid 单数据源
引入依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.25version>
<scope>runtimescope>
dependency>
Druid 单数据源 yaml 配置如下:
spring:
# datasource 配置
datasource:
url: jdbc:mysql://127.0.0.1:3306/test1228?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: admin111111
type: com.alibaba.druid.pool.DruidDataSource
druid:
min-idle: 0 # 池中维护的最小空闲连接数,默认为 0 个
max-active: 20 # 池中最大连接数,包括空闲和使用中的连接,默认为 8 个
filter: #
stat: # 配置 StatFilter,统计监控信息
log-slow-sql: true # 开启慢查询记录
slow-sql-millis: 5000 # 慢 SQL 的标准,单位:毫秒
stat-view-servlet: # 配置 StateViewServlet,提供监控信息的展示的 HTML 页面和 JSON API
enabled: true # 开启 StateViewServlet
login-password:
login-username:
@SpringBootApplication
public class DatasourcePoolDruidSingleApplication implements CommandLineRunner {
private Logger logger = LoggerFactory.getLogger(getClass());
private @Autowired
DataSource dataSource;
public static void main(String[] args) {
SpringApplication.run(DatasourcePoolDruidSingleApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
logger.info("[run][获得数据源:{}", dataSource.getClass());
}
}
Druid 的监控功能
我们在 yaml 中配置了如下信息:
- 通过
spring.datasource.druid.filter.stat配置了 StatFilter,用来统计监控信息。 - 通过
spring.datasource.druid.stat-view-servlet配置了 StateViewServlet,提供监控信息展示的 HTML 和 JSON API。
此时通过:http://ip:端口/druid 就可以查看相关信息。
监控信息会随着 JVM 重启失效,要想将监控信息持久化到存储器中,可以通过 StateViewServlet 提供的 JSON API 接口采集信息。
2.2 Druid 多数据源
依赖一样。
应用配置如下:
spring:
# datasource 数据源配置内容
datasource:
# 订单数据源配置
orders:
url: jdbc:mysql://127.0.0.1:3306/test_orders?useSSL=false&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
username: root
password:
type: com.alibaba.druid.pool.DruidDataSource # 设置类型为 DruidDataSource
# Druid 自定义配置,对应 DruidDataSource 中的 setting 方法的属性
min-idle: 0 # 池中维护的最小空闲连接数,默认为 0 个。
max-active: 20 # 池中最大连接数,包括闲置和使用中的连接,默认为 8 个。
# 用户数据源配置
users:
url: jdbc:mysql://127.0.0.1:3306/test_users?useSSL=false&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
username: root
password:
type: com.alibaba.druid.pool.DruidDataSource # 设置类型为 DruidDataSource
# Druid 自定义配置,对应 DruidDataSource 中的 setting 方法的属性
min-idle: 0 # 池中维护的最小空闲连接数,默认为 0 个。
max-active: 20 # 池中最大连接数,包括闲置和使用中的连接,默认为 8 个。
# Druid 自定已配置
druid:
# 过滤器配置
filter:
stat: # 配置 StatFilter
log-slow-sql: true # 开启慢查询记录
slow-sql-millis: 5000 # 慢 SQL 的标准,单位:毫秒
# StatViewServlet 配置
stat-view-servlet: # 配置 StatViewServlet
enabled: true # 是否开启 StatViewServlet
login-username: yudaoyuanma # 账号
login-password: javaniubi # 密码
不同于在 hikari 中多数据的配置,这里将 Druid 数据源的通用配置放在同一层,这样后续,我们只需使用访问一层的方式就可以完成 DruidDataSource 的属性配置。
对应的数据源配置类:
@Configuration
public class DataSourceConfig {
/**
* 创建 orders 数据源
*/
@Primary
@Bean(name = "ordersDataSource")
@ConfigurationProperties(prefix = "spring.datasource.orders") // 读取 spring.datasource.orders 配置到 HikariDataSource 对象
public DataSource ordersDataSource() {
return DruidDataSourceBuilder.create().build();
}
/**
* 创建 users 数据源
*/
@Bean(name = "usersDataSource")
@ConfigurationProperties(prefix = "spring.datasource.users")
public DataSource usersDataSource() {
return DruidDataSourceBuilder.create().build();
}
}
@SpringBootApplication
public class Application implements CommandLineRunner {
private Logger logger = LoggerFactory.getLogger(Application.class);
@Resource(name = "ordersDataSource")
private DataSource ordersDataSource;
@Resource(name = "usersDataSource")
private DataSource usersDataSource;
public static void main(String[] args) {
// 启动 Spring Boot 应用
SpringApplication.run(Application.class, args);
}
@Override
public void run(String... args) {
// orders 数据源
logger.info("[run][获得数据源:{}]", ordersDataSource.getConnection());
// users 数据源
logger.info("[run][获得数据源:{}]", usersDataSource.getConnection());
}
}
至此,Druid 和 Hikari 的简单学习就完成了。
3. Mybatis
每个团队使用 Mybatis 的方式不同,主要是以下几种类型:
- Mybatis + XML 组合
- Mybatis + 注解 组合
- Mybatis-Plus
- tkmybatis
这里着重说一下第一种和第三种情况:
3.1 Mybatis + XML
在 pom.xml 中,引入依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.6.3version>
<relativePath/>
parent>
<groupId>com.guigroupId>
<artifactId>mybatis-spring-bootartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>mybatis-spring-bootname>
<description>mybatis-spring-bootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.2.2version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.25version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
exclude>
excludes>
configuration>
plugin>
plugins>
build>
project>
在 Application 上添加注解:
@SpringBootApplication
@MapperScan(basePackages = "com.gui.mybatisspringboot.mapper")
public class MybatisSpringBootApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisSpringBootApplication.class, args);
}
}
在 resources 下要写配置文件,这是 Mybatis 的弊端:
# application.yml
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/test1228?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: admin111111
# mybatis 配置内容
mybatis:
config-location: classpath:mybatis-config.xml # 配置 MyBatis 配置文件路径
mapper-locations: classpath:mapper/*.xml # 配置 Mapper XML 地址
type-aliases-package: com.gui.mybatisspringboot.DO # 配置数据库实体包路径
编写 mybatis-config.xml:
DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
settings>
<typeAliases>
<typeAlias type="java.lang.Integer" alias="Integer"/>
<typeAlias type="java.lang.Long" alias="Long"/>
<typeAlias type="java.util.HashMap" alias="HashMap"/>
<typeAlias type="java.util.LinkedHashMap" alias="LinkedHashMap"/>
<typeAlias type="java.util.ArrayList" alias="ArrayList"/>
<typeAlias type="java.util.LinkedList" alias="LinkedList"/>
typeAliases>
configuration>
因为在数据库中的表字段是使用下划线分割,而数据库实体类的字段是驼峰命名风格,所以通过 mapUnderscoreToCamelCase = true 来自动转换。
创建 UserDO:
@Data
public class UserDO {
private Integer id;
private String username;
private String password;
private Date createTime;
public UserDO setId(Integer id) {
this.id = id;
return this;
}
public UserDO setUsername(String username) {
this.username = username;
return this;
}
public UserDO setPassword(String password) {
this.password = password;
return this;
}
public UserDO setCreateTime(Date creatTime) {
this.createTime = creatTime;
return this;
}
}
对应的操作 UserMapper :
@Repository //用于标记是数据访问的 Bean 对象,这是非必须的,只是为了避免在 Service 中使用 @Autowired 注入时报警
public interface UserMapper {
int insert(UserDO user);
int updateById(UserDO user);
int deleteById(@Param("id") Integer id); //生产请使用标记删除
UserDO selectById(@Param("id") Integer id); // 单参时,
UserDO selectByUsername(@Param("username") String username);
List<UserDO> selectByIds(@Param("ids") Collection<Integer> ids);
}
@Param注解是用来声明变量名的,在方法为单参数时是非必须的;但在方法为多参数时,必须使用。(禁止使用 Map 作为查询参数,因为无法通过方法的定义来直观的知道含义)
在 resources/mapper 下 创建 UserMapper.xml :
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.gui.mybatisspringboot.mapper.UserMapper">
<sql id="FIELDS">
id, username,password,create_time
sql>
<insert id="insert" parameterType="UserDO" useGeneratedKeys="true" keyProperty="id">
INSERT INTO users (
username,password,create_time
) values (
#{username},#{password},#{createTime}
)
insert>
<update id="updateById" parameterType="UserDO">
UPDATE users
<set>
<if test="username != null">
,username = #{username}
if>
<if test="password != null">
, password = #{password}
if>
set>
where id = #{id}
update>
<delete id="deleteById" parameterType="Integer">
DELETE FROM users
where id = #{id}
delete>
<select id="selectById" parameterType="Integer" resultType="UserDO">
SELECT
<include refid="FIELDS">include>
FROM users
WHERE id =#{id}
select>
<select id="selectByUsername" parameterType="String" resultType="UserDO">
SELECT
<include refid="FIELDS"/>
FROM users
WHERE id IN
<foreach collection="ids" item="id" separator="," open="(" close=")" index="">
#{id}
foreach>
select>
mapper>
这里有几条建议:
- 对于绝大多数查询,我们是统一返回字段,所以可以使用
标签,定义 SQL 段。对于性能或查询字段比较大的查询,再单独按需要的字段查询。- 对于数据库的关键字,使用大写。例如:SELECT , WHERE 等。
- SQL 语句要排版干净。
简单测试:
@SpringBootTest(classes = MybatisSpringBootApplication.class)
public class UserMapperTest {
@Autowired
private UserMapper userMapper;
@Test
public void testInsert() {
UserDO userDO = new UserDO().setUsername(UUID.randomUUID().toString())
.setPassword("nicai")
.setCreateTime(new Date());
userMapper.insert(userDO);
}
。。。。。。
}
3.2 Mybatis-Plus
引入依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.6.3version>
<relativePath/>
parent>
<groupId>com.guigroupId>
<artifactId>mybatis-plusartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>mybatis-plusname>
<description>mybatis-plusdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.2version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
<version>8.0.25version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
exclude>
excludes>
configuration>
plugin>
plugins>
build>
project>
application:
@SpringBootApplication
@MapperScan(basePackages = "com.gui.mybatisplus.mapper")
public class MybatisPlusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisPlusApplication.class, args);
}
}
应用配置文件:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/test1228?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: admin111111
# mybatis-plus 配置内容
mybatis-plus:
configuration:
map-underscore-to-camel-case: true # 虽然默认为 true ,但是还是显示去指定下。
global-config:
db-config:
id-type: auto # ID 主键自增
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.gui.mybatisplus.DO
# logging
logging:
level:
# dao 开启 debug 模式 mybatis 输入 sql
com:
gui:
mybatisplus:
mapper: debug
相比 mybatis 配置项来说,mybatis-plus 增加了更多配置项,因此我们也就无需再配置 mybatis-config.xml 配置文件了。
配置 Logger 的原因是方便我们看到 mybatis-plus 自动生成的 SQL。其他环境关闭即可。
DO 包下创建 UserDO:
@TableName(value = "user1")
@Data
public class UserDO {
private Integer id;
private String username;
private String password;
private Date createTime;
@TableLogic
private Integer deleted;
}
增加了 @TableName注解,设置了实体类对应的数据库表名,这样,mybatis-plus 就自动生成对应的 CRUD 代码。
@TableLogic注解,设置该字段为逻辑删除的标记。在配置文件中,我们设置了删除和未删除标记。
UserMapper:
@Mapper
@Repository
public interface UserMapper extends BaseMapper<UserDO> {
default UserDO selectByUsername(@Param("username") String username) {
return selectOne(new QueryWrapper<UserDO>().eq("username", username));
}
List<UserDO> selectByIds(@Param("ids") Collection<Integer> ids);
default IPage<UserDO> selectPageByCreateTime(IPage<UserDO> page, @Param("createTime") Date createTime) {
return selectPage(page, new QueryWrapper<UserDO>().gt("create_time", createTime));
}
}
因为 UserMapper 继承了 Mybatis-Plus 的 BaseMapper接口,所以常规的 CRUD 操作都不需要手动写了,Mybatis-Plus 会自动生成对应的操作。有些公司最常用的方式就是 Mapper 继承,因为库表有时候字段很多,DO 对应很麻烦。
这样我们需要手动实现的方法就只剩这三个。
对于selectByUsername()方法,我们使用了com.baomidou.mybatisplus.core.conditions.query.QueryWrapper构造相对灵活的条件,这样**一些动态 SQL **也不需要全在 XML 中编写。
对于 QueryMapper 的使用建议:
- 不要在 Service 中,使用 QueryWrapper 拼接动态条件,因为 BaseMapper 提供了
selectList(Wrapper等方法,促使我们能够在 Service 层的逻辑中,使用 QueryWrapper 拼接动态条件,这样会导致逻辑里遍布各种查询,使我们无法对实际查询条件做统一处理。碰到这种事情建议封装到对应的 Mapper 中,这样会更简洁干净。queryMapper) - 因为 QueryWrapper 暂时不支持一些类似
/**
* 拓展 MyBatis Plus QueryWrapper 类,主要增加如下功能:
*
* 1. 拼接条件的方法,增加 xxxIfPresent 方法,用于判断值不存在的时候,不要拼接到条件中。
*
* @param 数据类型
*/
public class QueryWrapperX<T> extends QueryWrapper<T> {
public QueryWrapperX<T> likeIfPresent(String column, String val) {
if (StringUtils.hasText(val)) {
return (QueryWrapperX<T>) super.like(column, val);
}
return this;
}
public QueryWrapperX<T> inIfPresent(String column, Collection<?> values) {
if (!CollectionUtils.isEmpty(values)) {
return (QueryWrapperX<T>) super.in(column, values);
}
return this;
}
public QueryWrapperX<T> inIfPresent(String column, Object... values) {
if (!ArrayUtils.isEmpty(values)) {
return (QueryWrapperX<T>) super.in(column, values);
}
return this;
}
public QueryWrapperX<T> eqIfPresent(String column, Object val) {
if (val != null) {
return (QueryWrapperX<T>) super.eq(column, val);
}
return this;
}
public QueryWrapperX<T> gtIfPresent(String column, Object val) {
if (val != null) {
return (QueryWrapperX<T>) super.gt(column, val);
}
return this;
}
public QueryWrapperX<T> betweenIfPresent(String column, Object val1, Object val2) {
if (val1 != null && val2 != null) {
return (QueryWrapperX<T>) super.between(column, val1, val2);
}
if (val1 != null) {
return (QueryWrapperX<T>) ge(column, val1);
}
if (val2 != null) {
return (QueryWrapperX<T>) le(column, val2);
}
return this;
}
// ========== 重写父类方法,方便链式调用 ==========
@Override
public QueryWrapperX<T> eq(boolean condition, String column, Object val) {
super.eq(condition, column, val);
return this;
}
@Override
public QueryWrapperX<T> eq(String column, Object val) {
super.eq(column, val);
return this;
}
@Override
public QueryWrapperX<T> orderByDesc(String column) {
super.orderByDesc(true, column);
return this;
}
@Override
public QueryWrapperX<T> last(String lastSql) {
super.last(lastSql);
return this;
}
}
最后在 resources/mapper 包下,编写配置文件:
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.gui.mybatisplus.mapper.UserMapper">
<sql id="FIELDS">
id, username, password, create_time
sql>
<select id="selectByIds" resultType="UserDO">
SELECT
<include refid="FIELDS">include>
FROM user1
WHERE id IN
<foreach collection="ids" item="id" separator="," open="(" close=")" index="">
#{id}
foreach>
select>
mapper>
xml 文件少了很多。最后自行测试即可。
3.3 关于 Mybatis 的一些认识
mybatis 和 hibernate 比较:
首先是基于它们不同的特性:hibernate 可以让你不用写 SQL 开发,且支持 lazy,且还有自己的 cache(适于小项目使用);而 mybatis 就不一样,需要你从 SQL 语句写起,手工活会多一些,但是带来调试的便利性还是可以接受的,且没有很多自带的功能。这就很清晰可控,当数据量大的时候,hibernate 的 cache 和其他毛病就显露出来了。
mybatis 几种方式的比较:
推荐 Mybatis-Plus 方式。
4. Spring 多数据源
这里的整理于此处
在实际开发中,经常会遇到应用要访问多个数据库的情况,需要配置多个数据源。
4.1 多数据源的使用场景
在实际情况中需要访问多数据源的场景:
- 业务复杂:数据分布在不同的数据库中,一个业务中同时操作不同的数据库,业务代码需要根据用户不同的操作去访问不同的库。
- 读写分离:一些小规模的公司,没有使用数据库访问层中间件。使用多数据源来实现简单的读写分离功能。

在读写分离中,主库和从库的数据库是一致的(不考虑主从延迟)。数据更新操作(insert、update、delete)都是在主库上进行,主库将数据变更信息同步给从库。在查询时,可以在从库上进行,从而分担主库压力。
需要注意的是:使用多数据源实现的读写分离操作,需要开发人员自行判断执行的 SQL 是读还是写。如果使用了数据库访问层中间件,通常会有中间件来实现读写分离的逻辑,对业务更加透明。
4.2 如何实现多数据源
对于大多数的 java 应用,都使用了 Spring 框架,spring-jdbc 模块提供了 AbstractRoutingDataSource,其内部包含了多个 DataSource,然后在运行时来动态决定访问哪个数据库。这种方式访问数据库的架构图如下:

应用直接操作的就是 AbstractRoutingDataSource的实现类。
可以自定义实现了 Spring 的 AbstractRoutingDataSource的功能,并在内部管理多个数据源;支持按照 package(包名)进行读写分离验证。
5. Spring Boot 多数据源(读写分离)
5.1 概述
在项目中,我们可能会碰到需要多数据源的场景(上一节已经简单介绍了)。比如:
- 读写分离:数据库主节点压力比较大,需要增加从节点提供读操作,以减少压力。
- 多数据源:一个复杂的单体项目,因为没有拆分成不同的服务,需要连接多个业务的数据源(不同数据库)。
本质上,读写分离,仅仅是多数据源的一个场景,从节点是只提供读操作的数据源。所以只要实现了多数据源的功能,也就能提供读写分离。
5.2 实现
目前实现多数据源的方案有三种。
- 基于 Spring
AbstractRoutingDataSource做拓展:- 简单来说就是通过继承
AbstractRoutingDataSource抽象类,实现一个管理项目中多个 DataSource 的动态DynamicAbstractRoutingDataSource实现类。这样 Spring 在获取数据源时可以通过实现类返回实际的 DataSource。 - 然后自定义一个注解
@DS,添加在 Service 的方法、Dao 方法上,表示其实际对应的 DataSource。 - 整个过程就是:执行数据操作时,通过配置的“@DS”注解,使用
DynamicAbstractRoutingDataSource获得对应的实际 DataSource,之后,再通过该 DataSource 获得 Connection 连接,最后发起数据库操作。 - 这种方式的缺点是在结合 Spring 事务的时候,会存在无法切换数据源的问题。
- 简单来说就是通过继承
- 不同操作类,固定数据源:这个比较晦涩
- 以 Mybatis 举例,假设有 orders 和 users 两个数据源。那么,我们可以创建两个 SqlSessionTemplate ,分别是
ordersSqlSessionTemplate和usersSqlSessionTemplate; - 然后配置不同的 Mapper 使用不同的
SqlSessionTemplate; - 整个过程变成:执行数据操作时,通过 Mapper 可以对应到其
SqlSessionTemplate,使用SqlSessionTemplate获得对应的实际的 DataSource。之后,再通过该 DataSource 获得 Connection 连接,最后发起数据库操作。 - 缺点:和上面的一样,在结合 Spring 事物的时候,也会存在无法切换数据源的问题。
- 以 Mybatis 举例,假设有 orders 和 users 两个数据源。那么,我们可以创建两个 SqlSessionTemplate ,分别是
- 分库分表中间件:对于分库分表的中间件,会解析我们编写的 SQL,路由操作到对应的数据源。所以,它们天然就支持多数据源,如此,我们只要配置好每个表对应的数据源,中间件就可以透明的实现多数据源或者读写分离。目前,Java 最好用的分库分表中间件是 Apache ShardingSphere,没有之一。且这种方式在结合 Spring 的时候不会存在无法切换数据源的问题。上述两种方式获得的 Connection 及其上的事务,然后通过 ThreadLocal 的方式和当前线程进行绑定,这样才导致我们无法切换数据源。
- 难道分库分表中间件不也是需要 Connection 然后进行这些事件吗?是的,但是不同的是分库分表中间件的 Connection 返回的实际是动态的
DynamicAbstractRoutingDataSource(它管理了整个请求过程中所有的 Connection),而最终执行 SQL 的时候,DynamicAbstractRoutingDataSource会解析 SQL,获得表对应的真正的 Connection 执行 SQL 操作。
- 难道分库分表中间件不也是需要 Connection 然后进行这些事件吗?是的,但是不同的是分库分表中间件的 Connection 返回的实际是动态的
5.3 Sharding-JDBC 多数据源
Sharding- JDBC 是 Apache 基金会下开源的基于 JDBC 的分库分表中间件。对于 Java 来说,推荐使用 Sharding- JDBC优于 Sharding-Proxy,主要原因是:减少了一层 Proxy 的开销,无需多考虑一次 Proxy 的高可用,性能更优;去中心化(无中心化架构,适用于 Java 开发的高性能的轻量级 OLTP 应用)。
引入依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.2.2version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-coreartifactId>
<version>4.1.1version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.1.1version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-aspectsartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
<version>8.0.25version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
应用配置文件:
spring:
shardingsphere:
datasource:
names: ds-users,ds-accounts
# 所有数据源名称
ds-users:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://127.0.0.1:3306/db1?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: admin111111
ds-accounts:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/db2?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: admin111111
# 分片规则
sharding:
tables:
user:
# 将user 逻辑表的操作路由到 ds-users 数据源的 user 真实表
actualDataNodes: ds-users.user
user-account:
actualDataNodes: ds-accounts.user_account
mybatis:
type-aliases-package: com.gui.springsharding.dataobject
config-location: classpath:mybatis-config.xml
mapper-locations: classpath:mapper/*.xml
剩下的 mybatis-config.xml 以及 dataobject、mapper、mapper.xml、Application 和之前一样。
Service 包下创建 UserService:
@Service
public class UserService {
private final UserMapper userMapper;
private final UserAccountMapper accountMapper;
public UserService(UserMapper userMapper, UserAccountMapper accountMapper) {
this.userMapper = userMapper;
this.accountMapper = accountMapper;
}
private UserService selfService() {
return (UserService) AopContext.currentProxy();
}
public void method01() {
UserDO userDO = userMapper.selectedById(2);
System.out.println(userDO);
System.out.println(accountMapper.selectById(1));
}
/**
* 即使在和 Spring 事务结合的时候,会通过 ThreadLocal 的方式将 Connection 和当前线程进行绑定,只要这个 Connection
* 是动态的连接就可以
*/
@Transactional
public void method02() {
System.out.println(userMapper.selectedById(2));
System.out.println(accountMapper.selectById(1));
}
public void method03() {
selfService().method031();
selfService().method032();
}
@Transactional
public void method031() {
System.out.println(userMapper.selectedById(2));
}
@Transactional
public void method032() {
System.out.println(accountMapper.selectById(1));
}
@Transactional
public void method05() {
System.out.println(userMapper.selectedById(2));
selfService().method052();
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void method052() {
System.out.println(accountMapper.selectById(1));
}
}
最后进行测试。
5.4 Sharding-JDBC 读写分离
读写分离的概念可以看官方文档。
依赖、application 等和上面一样。
spring:
# ShardingSphere 配置项
shardingsphere:
# 数据源配置
datasource:
# 所有数据源的名字
names: ds-master, ds-slave-1, ds-slave-2
# 订单 orders 主库的数据源配置
ds-master:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
# 订单 orders 从库数据源配置
ds-slave-1:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders_01?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
# 订单 orders 从库数据源配置
ds-slave-2:
type: com.zaxxer.hikari.HikariDataSource # 使用 Hikari 数据库连接池
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/test_orders_02?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
# 读写分离配置,对应 YamlMasterSlaveRuleConfiguration 配置类
masterslave:
name: ms # 名字,任意,需要保证唯一
master-data-source-name: ds-master # 主库数据源
slave-data-source-names: ds-slave-1, ds-slave-2 # 从库数据源
# mybatis 配置内容
mybatis:
config-location: classpath:mybatis-config.xml # 配置 MyBatis 配置文件路径
mapper-locations: classpath:mapper/*.xml # 配置 Mapper XML 地址
type-aliases-package: cn.iocoder.springboot.lab17.dynamicdatasource.dataobject # 配置数据库实体包路径
测试类:
@SpringBootTest(classes = Application.class)
public class OrderMapperTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSelectById() { // 测试从库的负载均衡
for (int i = 0; i < 10; i++) {
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
}
@Test
public void testSelectById02() { // 测试强制访问主库
try (HintManager hintManager = HintManager.getInstance()) {
// 设置强制访问主库
hintManager.setMasterRouteOnly();
// 执行查询
OrderDO order = orderMapper.selectById(1);
System.out.println(order);
}
}
@Test
public void testInsert() { // 插入
OrderDO order = new OrderDO();
order.setUserId(10);
orderMapper.insert(order);
}
}
testSelectById02 方法测试强制访问主库。在一些业务场景下,对数据延迟敏感,所以只能强制读取主库。此时可以使用 HintManager 强制访问主库。但是在使用完后,需手动清理 HintManager(它是基于线程变量,后传给 Sharding-JDBC 的内部实现)避免影响下次使用,可以一直强制访问主库。好在 Sharding-JDBC 的 HintManager 实现了 AutoCloseable 接口,可以通过 Try-With-Resource 机制自动关闭。
5.5 Sharding-JDBC 分库分表
分库分表的数据库结构如下:
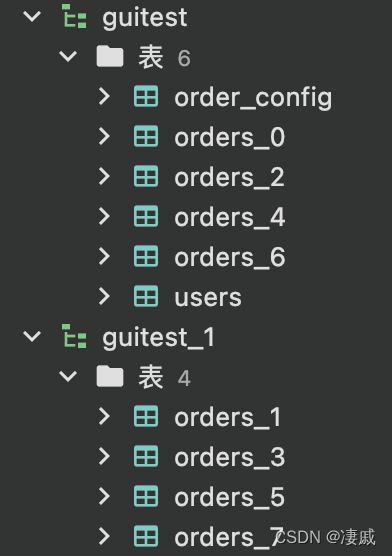
偶数后缀的表都在 guitest 库下;奇数后缀的表都在 guitest_1 库下。
我们根据订单表中的 user_id 用户 ID 进行处理,进行分库分表的规则如下:
- 首先,按照 index = user_id % 2 计算,将记录路由到 两个库(ds-orders-$->{index})中。
- 然后,按照 index = user_id % 8 计算,将记录路由到 对应库的表(orders_$->{index})中。
如果有数据不需要分库分表,我们会配置路由到 ds-orders-0 库下。
依赖与之前的一样。
启动类:
@SpringBootApplication
@MapperScan(basePackages = "com.gui.shardingdatasource01.mapper")
public class Shardingdatasource01Application {
public static void main(String[] args) {
SpringApplication.run(Shardingdatasource01Application.class, args);
}
}
应用配置文件:application.yml
spring:
# ShardingSphere 配置项
shardingsphere:
datasource:
# 所有数据源的名字
names: ds-orders-0, ds-orders-1
ds-orders-0:
driver-class-name: com.mysql.cj.jdbc.Driver
# 使用 Hikari 数据库连接池
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://127.0.0.1:3306/guitest?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: admin111111
ds-orders-1:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://127.0.0.1:3306/guitest_1?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: admin111111
# 分片规则
sharding:
tables:
orders:
# 映射到 ds-orders-0 和 ds-orders-1 数据源的 orders 表
actualDataNodes: ds-orders-0.orders_$->{[0,2,4,6]},ds-orders-1.orders_$->{[1,3,5,7]}
# 主键生成策略
key-generator:
column: id
type: SNOWFLAKE
# 数据库匹配机制
database-strategy:
inline:
algorithm-expression: ds-orders-$->{user_id % 2}
sharding-column: user_id
# 表匹配机制
table-strategy:
inline:
algorithm-expression: orders_$->{user_id % 8}
sharding-column: user_id
# 不需分库分表的表
order_config:
actualDataNodes: ds-orders-0.order_config
# 拓展属性
props:
sql:
show: true
mybatis:
type-aliases-package: com.gui.shardingdatasource01.dataobject
config-location: classpath:mybatis-config.xml
mapper-locations: classpath:mapper/*.xml
spring.shardingsphere.datasource 配置项:配置了两个数据源分别对应不同的数据库。其他的见注释
Mybatis 配置文件:mybatis-config.xml 和之前的一样。
实体类:
@Data
public class OrderDO {
private Long id;
private Integer userId;
}
@Data
public class OrderConfigDO {
private Integer id;
private Integer paymentTimeout;
}
在 guitest 库下,创建偶数表和 OrderConfig 表:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for orders_0
-- ----------------------------
DROP TABLE IF EXISTS `orders_0`;
CREATE TABLE `orders_0` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
-- ----------------------------
-- Table structure for orders_2
-- ----------------------------
DROP TABLE IF EXISTS `orders_2`;
CREATE TABLE `orders_2` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
-- ----------------------------
-- Table structure for orders_4
-- ----------------------------
DROP TABLE IF EXISTS `orders_4`;
CREATE TABLE `orders_4` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
-- ----------------------------
-- Table structure for orders_6
-- ----------------------------
DROP TABLE IF EXISTS `orders_6`;
CREATE TABLE `orders_6` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
SET FOREIGN_KEY_CHECKS = 1;
-- ----------------------------
-- Table structure for order_config
-- ----------------------------
DROP TABLE IF EXISTS `order_config`;
CREATE TABLE `order_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '编号',
`pay_timeout` int(11) DEFAULT NULL COMMENT '支付超时时间;单位:分钟',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单配置表';
在guitest_1 库下,创建奇数表:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for orders_1
-- ----------------------------
DROP TABLE IF EXISTS `orders_1`;
CREATE TABLE `orders_1` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=400675304294580226 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
-- ----------------------------
-- Table structure for orders_3
-- ----------------------------
DROP TABLE IF EXISTS `orders_3`;
CREATE TABLE `orders_3` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
-- ----------------------------
-- Table structure for orders_5
-- ----------------------------
DROP TABLE IF EXISTS `orders_5`;
CREATE TABLE `orders_5` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
-- ----------------------------
-- Table structure for orders_7
-- ----------------------------
DROP TABLE IF EXISTS `orders_7`;
CREATE TABLE `orders_7` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单编号',
`user_id` int(16) DEFAULT NULL COMMENT '用户编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='订单表';
SET FOREIGN_KEY_CHECKS = 1;
Mapper:
@Repository
public interface OrderMapper {
OrderDO selectById(@Param(value = "id") Integer id);
List<OrderDO> selectListByUserId(@Param("userId") Integer userId);
void insert(OrderDO order);
}
@Repository
public interface OrderConfigMapper {
OrderConfigDO selectById(@Param("id") Integer id);
}
对应的 mapper.xml:
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.gui.shardingdatasource01.mapper.OrderMapper">
<sql id="FIELDS">
id, user_id
sql>
<select id="selectById" resultType="com.gui.shardingdatasource01.dataobject.OrderDO" parameterType="Integer">
SELECT
<include refid="FIELDS"/>
FROM orders
WHERE id=#{id}
select>
<select id="selectListByUserId" resultType="com.gui.shardingdatasource01.dataobject.OrderDO" parameterType="Integer">
select <include refid="FIELDS"/>
from orders
where user_id = #{userId}
select>
<insert id="insert" parameterType="com.gui.shardingdatasource01.dataobject.OrderDO" keyProperty="id" useGeneratedKeys="true">
insert into orders(user_id)
values (#{userId})
insert>
mapper>
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.gui.shardingdatasource01.mapper.OrderConfigMapper">
<sql id="FIELDS">
id, payment_timeout
sql>
<select id="selectById" resultType="com.gui.shardingdatasource01.dataobject.OrderConfigDO" parameterType="Integer">
select
<include refid="FIELDS"/>
from order_config
where id = #{id}
select>
mapper>
最后,自行测试
在测试 selectById(id)方法的时候,会发现它进行了 8 个表的查询,这是因为:
我们使用 id,作为查询条件的时候,此时 Sharding-JDBC 匹配不到我们配置的 user_id 片键,所以只好全库表路由,查询所有的数据节点,这样在获得所有查询结果后,通过归并引擎合并返回最终结果。
那么,一次性发起这么多条 Actual SQL 是不是会顺序执行,导致时间很长呢?实际上,Sharding-JDBC 有执行引擎,会并行执行多条查询操作,所以,最长时间由最慢的 SQL 决定。
6. 数据库版本管理
在我们的认知中,我们会使用 SVN 或 Git 进行代码的版本管理,但是你是否好奇过,数据库也是需要版本管理的。
在每次发布版本的时候,我们可能都会对数据库的表结构进行新增或变更,又或者需要插入一些初始化的数据。而且我们的环境不可能只有一套,一般来说会有 DEV、UAT、PRED 和 PROD 四套环境,会对应 DEV、UAT、PROD 三个数据库。
那就意味着如果有数据库更改我们就需要对这三个数据库都做一遍操作,这是很麻烦的。
基于上述以及可能带来的影响,我们需要一个能管理数据库版本的工具。
Spring Boot 内置了 Flyway 和 Liquibase 的支持,所以优先学习这俩。
6.1 Flyway
Flyway:Database migrations made easy. Version control for your database, so you can migrate it with ease and confidence.
Flyway 提供了基于SQL 的合并方式和基于 Java 代码的合并方式。
依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.25version>
dependency>
<dependency>
<groupId>org.flywaydbgroupId>
<artifactId>flyway-coreartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
配置文件:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/guitest?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: admin111111
# flyway 配置内容,对应 FlywayAutoConfiguration.FlywayConfiguration 配置项
flyway:
# 开启 flyway 功能
enabled: true
# 禁用 Flyway 所有的 drop 相关的逻辑,避免出现跑路情况
cleanDisabled: true
# 迁移脚本目录
locations:
# 配置 SQL-based 的SQL 脚本在该目录下
- classpath:db/migration
# 配置 Java-based 的Java 文件在该目录下
- classpath:com.gui.flyway01.migration
# 是否校验迁移脚本目录,如果为 true,如果目录下没有迁移脚本,会抛出 IllegalStateException 异常
check-location: false
# 迁移出的数据库
url: jdbc:mysql://127.0.0.1:3306/flyway01?useSSL=false&useUnicode=true&characterEncoding=UTF-8
user: root
password: admin111111