JZYZ 暑假集训 Day1 基础数据结构总结
单调栈,单调队列和树状数组
- 单调栈
-
- 一. 概念
- 二 .例题
-
-
- 1. [圆环塔](https://codeforces.com/contest/777/problem/E)
- 2.[乱头发节](http://jzyz.code-fans.cn/problem/211)
- 3. [排队](http://sc6.snailcode.cn/homework/1/problem/208)
- 4. [子序列累加加](http://jzyz.code-fans.cn/problem/215)
- 5. [Largest Rectangle in a Histogram](http://jzyz.code-fans.cn/problem/1333)
- 6. [City Game](https://www.luogu.com.cn/problem/UVA1330)
-
- 单调队列
-
- 一.概念
- 二.例题
-
-
- 1. [滑动窗口](https://www.luogu.com.cn/problem/P1886)
- 2. [ 最大子段和(带长度限制)](http://jzyz.code-fans.cn/problem/1340)
-
- 树状数组
-
- 一. 概念
- 二. 原理
-
- 1. l o w b i t lowbit lowbit运算
- 2. 2的整数幂划分
- 三. 操作及代码实现
-
- 1.单点修改,区间查询
- 2.区间修改,单点查询
- 3.区间修改,区间查询
- 四. 例题
-
- 1.[【模板】逆序对统计](https://www.luogu.com.cn/problem/P1908)
- 2.[楼兰图腾](http://jzyz.code-fans.cn/problem/1438)
- 3.[Lost Cows](http://jzyz.code-fans.cn/problem/1437)
- 4.[[SHOI2007]园丁的烦恼](https://www.luogu.com.cn/problem/P2163)
单调栈
一. 概念
单调栈是一种解决单调问题,提高算法效率 的一种数据结构。单调栈,顾名思义,就是在栈内通过弹栈等操作只存储单调性的元素。核心思想就在于 及时排除不可能的选项,保持策略集合的高度有效性和秩序性, 从而为我们做出决策提供更多的条件和可能方法。
二 .例题
1. 圆环塔
题面大意:

分析: 首先读懂题意,我们很容易想到: 要想让搭在一起的环高度和最大,那么必然是要让其有序的被考虑,即选或不选。那么我们就可以考虑贪心。因为一个圆环A能放到圆环B上的条件必须满足A.外径 > B.内径 (保证不漏下去)。 B.外径 >= A.外径 (感觉是保证环塔的美观)。 于是我们可以先按照外径从大到小排序,如果外径相同则让内径大的放前面 (更利于放后面小的)。 考虑完贪心怎么做后,我们想一下后续如何进一步解决问题。
很显然,我们可以考虑 动态规划,这样能保证最终答案的全局最优性。 我们设 D P i DP_i DPi 表示在搭成的环塔中以 i i i号 环作为最顶端的最大高度。那么显然有 D P i DP_i DPi = max 1 ≤ j < i a n d a j < b i ( D P i , D P j + h i ) \max_{1\leq j\lt i \quad and \quad a_j\lt b_i}{(DP_i, DP_j + h_i)} 1≤j<iandaj<bimax(DPi,DPj+hi)
考虑时间复杂度,如果对于每个 D P i DP_i DPi都暴力枚举一个 j j j,那么时间复杂度为 O ( n 2 ) O(n^2) O(n2),显然会TLE。再次思考一下,对于当前环 X X X而言,如果前面存在一个环 Y Y Y的内径大于等于 X X X的外径那么对于 D P x DP_x DPx而言,最大高度环塔集合中一定没有环 Y Y Y,由于我们按环的外径进行了排序,那么环 Y Y Y也一定不会出现在后面最高高度环塔的集合中。显然我们可以将塔 Y Y Y从决策集合中清除。这令我们想到了,可以用单调栈解决问题。
时间复杂度 O ( n l o g n ) O(nlog_n) O(nlogn)
SOLUTION:
#include2.乱头发节
题目大意:


分析: 首先将问题转换,每只牛向右能看到多少只牛的和 等于 每只牛向左能看到多少次的和。 也就是说,显然当一只奶牛比后面的奶牛低时,他就会被挡住,不会再被看见了。我们可以维护一个身高单调下降的栈,对于每一头奶牛的身高而言,先进行弹栈操作后,栈内剩余元素的数量即为当前牛能看到的牛的数量。
时间复杂度 O ( n ) O(n) O(n)
SOLUTION:
#include3. 排队
题面大意:
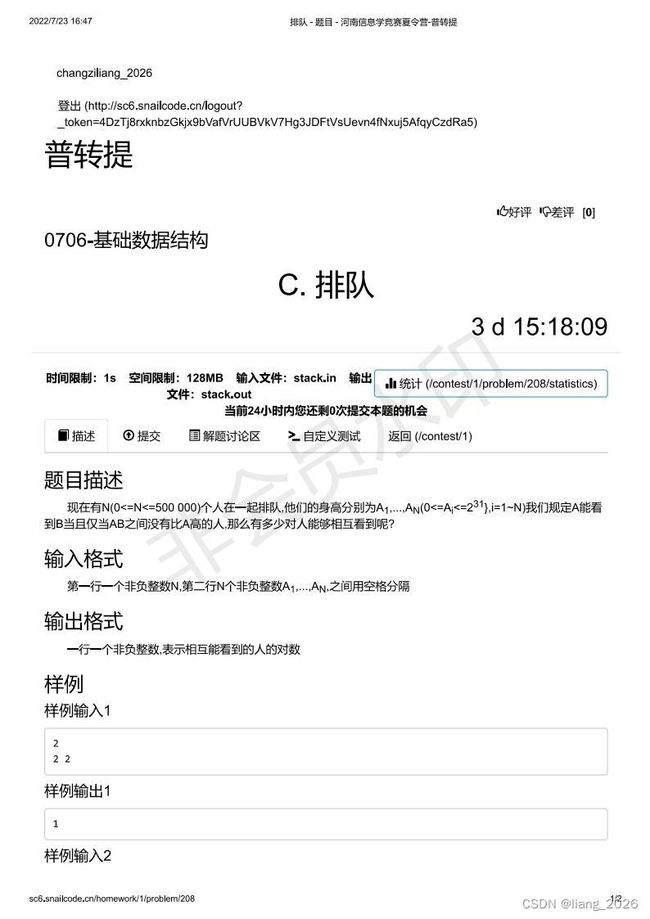

分析: 很明显能想到,暴力做法是枚举每一个人和其它人,判断能否互相看见,时间复杂度 O ( n 2 ) O(n^2) O(n2),很明显仅能过掉 30 30 30分的数据,十分拉跨 。
那么我们同样可以从对答案的贡献进行分析。很明显,当一个人第一次比后面的人低时 (从左到右),他就永远无法与后面的人互相看见。可以从决策集合中去除。基于这一点,我们可以考虑单调栈算法,维护一个单调不增的栈 对于当前的人而言,先弹掉栈内比他低的人的高度(或编号),并将累加人数并统计到答案中,然后再将当前人的高度(或编号)进栈即可。需要注意的是: 可能存在不同的人高度相同的情况,我们需要进行特别处理。
时间复杂度 O ( n ) O(n) O(n)
SOLUTION:
#include4. 子序列累加加
题面大意:

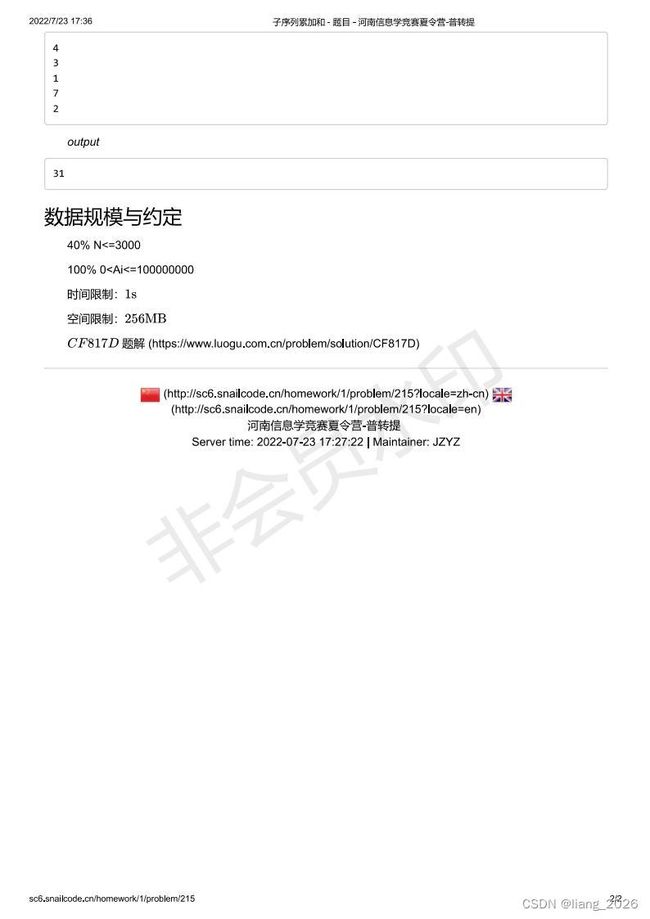
分析: 很显然,我们暴力枚举每一个子序列并求出其最大值的复杂度极高,无法AC,秉着正难则反的原则,我们考虑将问题转化一下。
因为我们 只注重所有子序列最大值的和,而并不关心每一个子序列的最大值的情况。于是我们可以考虑 N个数中每一个数作为某一子序列最大值的次数,并把这个次数 乘上这个数的值 就是这个数的贡献。现在问题变成了 如何求出每一个数作为子序列最大值的次数。我们考虑到当一个数 X X X后面出现第一个大于它的数 Y Y Y, X X X能作为子序列最大值的右范围就已经确定了,即为 Y Y Y的左边的一个位置,同理,我们通过这样的方式还能确定每个数的坐范围。
那么,对于数 X X X我们怎么处理呢? 我们可以想到若 Y Y Y后面的数大于Y,则一定大于 X X X。 若小于 Y Y Y,则左范围就只能到 Y Y Y右边的一个位置,同样不需要考虑 X X X。 要维护这种单调性,我们可以考虑单调栈。
时间复杂度 O ( n ) O(n) O(n)
SOLUTION:
#include5. Largest Rectangle in a Histogram
题面大意:


分析: 当一个矩形后面第一次出现比它低的矩形时,这个矩形此后所能贡献的最大高度就只能为第一个比它低的矩形的高度。由此我们可以考虑单调栈,考虑将多个矩形合并,维护一个单调不降的高度栈。
时间复杂度 O ( n ) O(n) O(n)
SOLUTION:
#include6. City Game
题面大意:


分析: 非常简单,上一题的拓展,我们可以以每一行(或每一列)作为地面,做一遍上一题。
时间复杂度 O ( n 2 ) O(n^2) O(n2)
SOLUTION:
#include单调队列
一.概念
单调队列同样是一种维护单调性决策集合的数据结构,与单调栈不同的是:单调队列一般对维护的决策集合有长度或其它限制。所以我们一般使用双端队列进行维护。
二.例题
1. 滑动窗口
分析: 同样是对单个元素对答案的贡献进行分析。首先我们开一个双端队列进行维护,如果当前元素小于队尾的元素,那么队尾元素一定不会再被用到,直接出队。对于窗户长度的限制,我们可以将队头元素的下标和当前元素的下标的差值与窗户长度进行比较,如果超出了窗户的长度限制,直接出队即可。最后将当前元素入队。则队头就是当前的答案。
一个元素最多入队一次,出队一次。时间复杂度 O ( n ) O(n) O(n)。
SOLUTION:
#include2. 最大子段和(带长度限制)
题面大意:


分析: 要求子段的和,显然我们可以通过前缀和相减的形式实现。那么此时思路就很清晰了:求出 1 − n 1-n 1−n的前缀和,对于当前位置 X X X而言,可从 X − 1 X-1 X−1到 X − l e n X-len X−len的前缀和中取一个最小值进行相减,并更新答案。问题就转化成了上一道题。
时间复杂度 O ( n ) O(n) O(n)
SOLUTION:
#include树状数组
一. 概念
树状数组是一个查询和插入的时间复杂度都为 ** O ( l o g n ) O(log_n) O(logn)**的数据结构,它可以用来 动态维护前缀和。主要操作有 ①单点修改,区间查询;②区间修改,单点查询;③区间修改,区间查询。同样也可以用树状数组解决 二位偏序问题 。
二. 原理
1. l o w b i t lowbit lowbit运算
l o w b i t ( n ) lowbit(n) lowbit(n)定义为非负整数 n n n 在二进制表示下“最低位 1 1 1 及其后边所有的 0 0 0 构成的数值”。例如, n = 10 n = 10 n=10 的二进制表示为 ( 1010 ) 2 (1010)_2 (1010)2,则 l o w b i t ( n ) = ( 10 ) 2 = 2 10 lowbit(n) = (10)_2 = 2_{10} lowbit(n)=(10)2=210。
l o w b i t ( n ) lowbit(n) lowbit(n) 的公式推导:
设 n > 0 n\gt 0 n>0, n n n 的第 k k k 位是 1 1 1,第 0 ∼ k − 1 0 \sim k - 1 0∼k−1 位都是 0 0 0。
为了实现 l o w b i t lowbit lowbit 运算,先把 n n n 取反,此时第 k k k 位变为 0 0 0,第 0 ∼ k − 1 0 \sim k - 1 0∼k−1 位都是 1 1 1。再令 n = n + 1 n = n + 1 n=n+1,此时因为进位,第 k k k 位变成 1 1 1,前 k − 1 k - 1 k−1 位变成 0 0 0。
在上面的取反加 1 1 1 后, n n n 的第 k k k 位到最高位恰好与原来相反,所以 n & ( ∼ n + 1 ) n \& (\sim n + 1) n&(∼n+1) 仅有第 k k k 位为 1 1 1,其余位都是 0 0 0。而在 补码 表示下, ∼ n = − 1 − n \sim n = -1 - n ∼n=−1−n,因此:
l o w b i t ( n ) = n & ( − n ) lowbit(n) = n \& (-n) lowbit(n)=n&(−n)。
代码如下:
int lowbit(int x){
return x & -x;
}
2. 2的整数幂划分
对于任意正整数 x x x 而言,若它能被 “二进制分解” 成 x = 2 p 1 + 2 p 2 + 2 p 3 + . . . + 2 p m x = 2^ {p_1} + 2^{p_2} + 2^{p_3} + ... +2^{p_m} x=2p1+2p2+2p3+...+2pm。其中 p 1 > p 2 > p 3 > . . . > p m p_1 \gt p_2 \gt p_3 \gt ... \gt p_m p1>p2>p3>...>pm。进一步地,区间 [ 1 , x ] [1,x] [1,x] 可以分成 O ( l o g x ) O(log_{x}) O(logx)个小区间:
1.长度为 2 p 1 2^{p_1} 2p1 的小区间 [ 1 , 2 p 1 ] [1, 2^{p_{1}}] [1,2p1]
2.长度为 2 p 2 2^{p_{2}} 2p2 的小区间 [ 2 p 1 + 1 , 2 p 1 + 2 p 2 ] [2^{p_{1}} + 1, 2^{p_1} + 2^{p_{2}}] [2p1+1,2p1+2p2]
3.长度为 2 p 3 2^{p_3} 2p3 的小区间 [ 2 p 1 + 2 p 2 + 1 , 2 p 1 + 2 p 2 + 2 p 3 ] [2^{p_1} + 2^{p_2} + 1, 2^{p_1} + 2^{p_2} + 2^{p_3}] [2p1+2p2+1,2p1+2p2+2p3]
. . . . . . ...... ......
m.长度为 2 p m 2^{p_m} 2pm的小区间 [ 2 p 1 + 2 p 2 + 2 p 3 + . . . + 2 p m − 1 + 1 , 2 p 1 + 2 p 2 + 2 p 3 + . . . + 2 p m − 1 + 2 p m ] [2^{p_1} + 2^{p_2} + 2^{p_3} + ... + 2^{p_{m-1}} + 1, 2^{p_1} + 2^{p_2} + 2^{p_3} + ... + 2^{p_{m-1}} + 2^{p_m}] [2p1+2p2+2p3+...+2pm−1+1,2p1+2p2+2p3+...+2pm−1+2pm]
这些小区间的共同特点是:若区间结尾是 R R R,则区间长度就等于 R R R的 “二进制分解下最小的2的次幂”,即 l o w b i t ( R ) lowbit(R) lowbit(R)。例如 x = 7 = 2 2 + 2 1 + 2 0 x = 7 = 2^2 + 2^1 + 2^0 x=7=22+21+20,区间 [ 1 , 7 ] [1, 7] [1,7] 可以分成 [ 1 , 4 ] [1, 4] [1,4]、 [ 5 , 6 ] [5, 6] [5,6]、 [ 7 , 7 ] [7, 7] [7,7] 三个小区间, 长度分别是 l o w b i t ( 4 ) = 4 、 l o w b i t ( 6 ) = 2 和 l o w b i t ( 7 ) = 1 lowbit(4) = 4、 lowbit(6) = 2 和 lowbit(7) = 1 lowbit(4)=4、lowbit(6)=2和lowbit(7)=1。这启发我们:对于任意数 X X X,要求出 [ 1 , x ] [1, x] [1,x]的前缀和,我们可以将 X X X二进制分解后累加上每一个小区间的值的和。因为任何一个数 X X X二进制分解下的位数一定不超过 l o g x log_x logx,而 l o w b i t ( ) lowbit() lowbit()运算又能 O ( 1 ) O(1) O(1)的找一个数二进制下最低位的 1 1 1,因此查询的时间复杂度为 O ( l o g x ) O(log_x) O(logx)。
所以,我们对于给定的序列 a a a,我们建立一个数组 c c c,其中 c [ x ] c[x] c[x] 保存序列 a a a 的区间 [ x − l o w b i t ( x ) + 1 , x ] [x - lowbit(x) + 1, x] [x−lowbit(x)+1,x] 中所有数的和, 即 ∑ i = x − l o w b i t ( x ) + 1 x a [ i ] \sum_{i = x - lowbit(x) + 1}^{x} a[i] ∑i=x−lowbit(x)+1xa[i]。事实上,数组 c c c 可以看作如下图所示的树形结构,图中最下边一行是 N N N个叶节点 ( N = 8 ) (N = 8) (N=8),代表数值 a [ 1 − N ] a[1 - N] a[1−N]。

该结构满足以下性质:
1.每个内部节点 c [ x ] c[x] c[x] 保存以它为根的子树中所有叶节点的和;(不用解释,定义)
2.每个内部节点 c [ x ] c[x] c[x] 的子节点个数等于 l o w b i t ( x ) lowbit(x) lowbit(x) 的位数;(等会再解释)
3.除树根外,每个内部节点 c [ x ] c[x] c[x] 的父节点是 c [ x + l o w b i t ( x ) ] c[x + lowbit(x)] c[x+lowbit(x)]; (设 y = x + l o w b i t ( x ) y = x + lowbit(x) y=x+lowbit(x),则 l o w b i t ( y ) ≥ l o w b i t ( x ) + l o w b i t ( x ) lowbit(y)\geq lowbit(x) + lowbit(x) lowbit(y)≥lowbit(x)+lowbit(x) 这是因为二进制下的进位和 l o w b i t ( ) lowbit() lowbit() 的用法得到的。那么 c [ y ] c[y] c[y] 所能覆盖的范围一定包含了 c [ x ] c[x] c[x] 的范围。所以 c [ y ] c[y] c[y] 一定是 c [ x ] c[x] c[x] 的父亲。同理,我们也能确定 c [ y ] c[y] c[y] 的父亲等等,这样就把 c [ x ] c[x] c[x] 的祖先都找到了了。)
4.树的深度为 O ( l o g N ) O(log_N) O(logN)。
三. 操作及代码实现
1.单点修改,区间查询
对于给定的序列 A A A,如何做到快速 在线单点修改和区间查询 ?
分析:对于 区间查询 而言,我们可以查询出 两段前缀和 并相减就能得到 区间值。求出 [ 1 ∼ x ] [1 \sim x] [1∼x] 的前缀和代码如下:
int ask(int x){
int res = 0;
for(; x; x -= lowbit(x)) res += c[x];
return res;
}
对于 单点修改 而言,如果我们要将序列里第 x x x 个位置加上 y y y,那么我们需要将所有包含第 x x x 个位置的 c [ i ] c[i] c[i] 加上 y y y。也就是 c [ x ] c[x] c[x] , c [ x ] c[x] c[x] 的父亲, c [ x ] c[x] c[x] 的父亲的父亲 . . . . . . ...... ......,这需要用到 性质3。
代码:
void add(int x, int y){
for(; x <= n; x += lowbit(x)) c[x] += y;
}
2.区间修改,单点查询
对于给定序列 A A A 而言,如何做到快速 在线区间修改和单点查询 ?
分析:利用 差分 的思想,我们可以考虑维护一个 单点值偏移量 的数组。如果操作是 在区间 [ L , R ] [L,R] [L,R] 中的每一个元素加上 y y y,我们可以考虑 在偏移量数组 A [ L ] A[L] A[L] 的位置上加上 y y y,在 A [ R + 1 ] A[R + 1] A[R+1] 的位置上减去 y y y。这样当我们要查询一定的修改操作后某个元素 X X X 的值,只需要求出 A [ 1 , X ] A[1,X] A[1,X] 的前缀和,并与原值相加即可。问题就转化成了上一道题。
代码:
void add(int x, int y){
for(; x <= n; x += lowbit(x)) c[x] += y;
}
int ask(int x){
int res = num[x];
for(; x; x -= lowbit(x)) res += c[x];
return res;
}
3.区间修改,区间查询
对于给定序列 A A A 而言,如何做到快速 在线区间修改和区间查询 ?
分析:在上一题中,我们用树状数组维护了一个数组 A A A,对于每一条修改指令,都采取了左端点加修改量,右端点加一的位置减去修改量。
对于 b b b 数组的前缀和 ∑ i = 1 x b [ i ] \sum_{i = 1} ^{x} b[i] ∑i=1xb[i] 就是经过一些修改指令后 a [ x ] a[x] a[x] 增加的值。
那么序列 a a a 的前缀和 a [ 1 ∼ x ] a[1 \sim x] a[1∼x] 整体增加的值就是:
∑ i = 1 x ∑ j = 1 i b [ j ] \sum_{i = 1}^x \sum_{j = 1}^{i} b[j] ∑i=1x∑j=1ib[j]
上式可改写为:
∑ i = 1 x ∑ j = 1 i b [ j ] = ∑ i = 1 x b [ i ] ∗ ( x − i + 1 ) = ( x + 1 ) ∑ i = 1 x b [ i ] − ∑ i = 1 x i ∗ b [ i ] \sum_{i = 1}^x \sum_{j = 1}^{i} b[j] = \sum_{i = 1}^{x} b[i] * (x - i + 1) = (x + 1) \sum_{i = 1}^{x} b[i] - \sum_{i = 1}^{x} i * b[i] ∑i=1x∑j=1ib[j]=∑i=1xb[i]∗(x−i+1)=(x+1)∑i=1xb[i]−∑i=1xi∗b[i]
那么我们就可以增加一个树状数组,用来维护 i ∗ b [ i ] i * b[i] i∗b[i] 的前缀和,上式就可以直接查询计算了。
代码:
#include四. 例题
1.【模板】逆序对统计
分析:由于 n n n 的范围不大,我们可以考虑利用 桶 的思想,及将数据 离散化 后 用树状数组的下标表示值域 。这样对于当前数而言,只需要查找比它小的数的前缀和即可。时间复杂度 O ( n l o g n ) O(nlog_n) O(nlogn)。这里放入没有离散化的代码。
code:
#include2.楼兰图腾
分析:前后扫两边,对于每个数,分别找出前后比它大、小的数的个数(用树状数组),最后遍历每个数并将贡献累加到答案即可。
CODE:
#include3.Lost Cows
分析:如果第 k k k 头牛前面有 A k A_k Ak 头比它低,那么它的身高 H k H_k Hk 就是数值 1 ∼ n 1 \sim n 1∼n 中第 A k + 1 A_k + 1 Ak+1 小的没有在 { H k + 1 , H k + 2 , . . . , H n } \{H_{k + 1},H_{k + 2} ,... ,H_{n} \} {Hk+1,Hk+2,...,Hn} 中出现过的数。 这是因为从后往前每头牛 身高的确定性 对它 后面的牛依赖越来越大 。 就比如最后面的牛只需要看前面比它的的牛的数量就能确定自己的身高,而最前面的奶牛的身高就是它后面的奶牛都没有选择的那个高度。
我们可以建立一个长度为 n n n 的 01 01 01 序列 b b b,起初全为 1 1 1。然后,从 n n n 到 1 1 1 倒叙扫描每一个 A i A_i Ai,对每个 A i A_i Ai 执行以下操作:
1.查询序列 b b b 里第 A i + 1 A_i + 1 Ai+1 个 1 1 1 的位置,则这个 位置号 就是第 i i i 头奶牛的身高 H i H_i Hi。
2.把 b [ H i ] b[H_i] b[Hi] 改为 0 0 0。
也就是说,我们需要 实时维护一个 01 01 01 序列,支持查询第 k k k 个 1 1 1 的位置 ( k k k 为任意整数),以及修改序列中的一个数值。
方法: 树状数组 + 二分,单次操作 O ( l o g 2 n ) O(log^2n) O(log2n)
用树状数组维护 01 01 01 序列 b b b 的前缀和,然后二分位置即可。
SOLUTION:
#include4.[SHOI2007]园丁的烦恼
分析:这是一道用树状数组解决 二位偏序 的问题的题目。
我的理解是,二维偏序 就是给定的特殊 二元关系 。例如 求逆序对,有两元的关系 1.a.pos < \lt < b.pos 2. a.val > \gt > b.val,只有满足了这两种关系,才称 a , b a,b a,b 是一组逆序对。用树状数组求解 二位偏序 的通常解法是 先按一维排序后,用树状数组统计数量及答案。
对于本题而言,因为要查找 二维平面的元素和,我们会想到 二维前缀和。对于每一组询问,我们可以离线处理每次要用到的四个点的信息,最后按询问顺序输出答案即可。
SOLUTION:
#include