【TGRS 2023】RingMo: A Remote Sensing Foundation ModelWith Masked Image Modeling
RingMo: A Remote Sensing Foundation Model With Masked Image Modeling, TGRS 2023
论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9844015
代码:https://github.com/comeony/RingMo
MindSpore/RingMo-Framework (gitee.com)
解读:自监督论文阅读笔记 RingMo: A Remote Sensing Foundation Model with Masked Image Modeling-CSDN博客
【代码复现】RingMo:应用于遥感领域的图像掩码建模技术_lalula1999的博客-CSDN博客
摘要
深度学习方法促进了遥感 (RS) 图像解释的快速发展。最广泛使用的是利用ImageNet预训练模型来处理指定任务的 RS 数据。然而,存在自然场景与RS场景之间的领域差距,以及 RS模型泛化能力差 等问题。开发具有通用 RS 特征表示的基础模型是有意义的。由于有大量未标记的数据可用,自监督方法在遥感方面比全监督方法具有更大的发展意义。然而,目前大多数自监督方法都使用 对比学习,其性能对数据增强、附加信息以及正负对的选择很敏感。
本文利用 生成式自监督学习 对 RS 图像的优势,提出一个名为 RingMo 的遥感基础模型框架,它由两部分组成。首先,通过从卫星和航空平台收集200万张RS图像,构建一个大规模的数据集,覆盖全球多个场景和物体。其次,提出了一种 针对 复杂 RS 场景中 密集和小型物体的 RS 基础模型训练方法。
本文展示了使用 RingMo 方法在本文的数据集上训练的基础模型在四个下游任务的八个数据集上实现了最先进的模型,证明了所提出框架的有效性。通过深入探索,本文鼓励人们对RS拥抱生成式自监督学习,并利用其通用的表示能力 来加速 RS 应用程序的开发。
引言
动机

RS图像解译 的一般范式是 加载ImageNet预训练的权重,然后在指定的任务中使用RS数据和标签信息进行模型训练。尽管这些方法在特定任务中 针对特定目标 表现良好,但仍存在以下问题。
- 由于自然场景与RS场景的差异,ImageNet预训练的权值存在域偏差,这在一定程度上影响了RS模型的性能。
- 模型泛化能力较弱,有限的RS训练数据只能提供少量的场景和对象,难以适应其他任务。
- 为了扩展到更多的目标和任务,研究人员需要不断地注释数据,这降低了实际应用的效率。
综上,使用海量的 RS 数据 并设计具有通用 RS 特征表示的基础模型 有望解决上述问题。现有的 RS 基础模型训练方法 包括 监督学习 和 自监督学习 两大主流。
- 监督学习,需要大量标记数据来训练基础模型。尽管效果好,但获取标记数据需要专家花费大量时间。由于数据标注和数据采集速度之间的巨大差距,大量RS数据无法使用。
- 自监督方法,可以利用大量未标记的数据,并且是 RS 基础模型的主流方法。对比学习 [MoCo,SimCLR v1,v2 ] 在 RS 自监督方法领域占据主导地位。

自监督方法可以利用大量的未标记数据,是RS大模型建模的主流方法。自监督常用方法:
- 对比学习
对比学习的核心思想是缩小相似样本的特征距离。由于没有标签,研究者对同一张图像进行数据增强,形成正对,而其他图像作为该图像的负对。此外,一些研究者通过仔细搜索或匹配,引入RS特有的附加信息(地理信息、时间序列数据、音频数据等),并鼓励模型在数据增强的同时,学习附加信息的相似性。对比学习方法取得了很好的效果,但是它们默认将不同的图像作为负对,并且RS数据集中的不同图像经常包含同一类的实例。
- 掩码图像建模(MIM)
它的目的是重建被遮挡的像素点,并学习数据分布中的一般特征表示。一方面,它避免引入额外的信息,从而更容易利用大量数据。随着建模数据的增多,基础模型对不同场景的适应能力增强。另一方面,它的目标是从原始图像重建像素级信号。在不需要任何数据增广和负对的情况下,该模型也可以获得更好的特征表示。因此,生成式自监督方法更适合于RS基础模型的建立。
目前,大多数 MIM 方法都是 基于自然图像进行训练的。与自然场景相比,RS图像存在以下难点:
- 分辨率和方向范围大。受遥感传感器的影响,图像具有多种空间分辨率。此外,具有固定方向的自然图像不同,RS 图像中的对象 从鸟瞰角度 具有较大的角度分布范围。因此,由于尺度和角度的多样性,同一物体在不同的RS图像中具有不同的特征。
- 许多密集和小的目标。自然图像一般仅有少量目标且多在前景区域,RS图像中存在许多小目标,通常分布较密,在一定程度上影响了物级解译精度。
- 复杂的背景。RS图像中包含了大量的背景信息,导致图像的信噪比较低。物体的边界和背景模糊,干扰了物体的分类。RS影像容易受到天气、光线、云雾等外部因素的干扰,影响成像质量。
基于上述差异,使用自然图像训练的生成式自监督模型在 RS 场景上表现不佳。因此,有必要设计一个适合RS数据的基础模型。
本文提出了一个遥感基础模型框架RingMo,它由两部分组成:一个大规模的RS数据集 和 一个适合 多任务解译的基础模型训练方法。
有了更多的 RS 数据,基础模型可以学习更多的通用特征表示。为了覆盖 具有 复杂背景 和 大量目标 的 RS 数据,本文在无监督条件下收集了 200 万张图像的数据集。 RS 图像的分辨率范围 从 0.1m 到 30m,覆盖六大洲的多个场景和物体,从卫星和空中平台捕获。
基于该数据集,本文设计 RingMo 训练方法,将 MIM 方法应用于训练 RS 基础模型。由一个用于提取隐特征表示的 相对较重的编码器 和一个 用于输出重建结果的解码器 组成。
现有的 随机掩码策略 往往会丢失 RS 图像中的密集和小目标。为了解决这个问题,本文根据 RS 场景和目标的属性 设计了一种 Patch Incomplete Mask (PIMask) 策略。 RS目标在 复杂的遥感场景中 通过采用 局部不完全掩码 在保持整体掩码率的情况下 进行保留。
本文使用 RingMo 在本文的数据集上 进行训练 以获得基础模型,并且训练的特征表示 可以应用于广泛的 RS 下游任务。本文在四个 RS 任务上评估RingMo。使用 UCM、AID、NWPU-RESISC45进行 场景识别实验,使用 FAIR1M和 DIOR 进行 目标检测实验,使用 iSAID和 ISPRS Postdam 2 进行 语义分割实验,和 LEVIR-CD 用于 变化检测实验。实验结果表明,本文的基础模型可以在八个数据集上实现最先进的 (SOTA) 性能。此外,由于本文的框架不需要手动标注任何标签,还讨论了不同数量的 RS 数据对基础模型训练的影响,增加 RS 数据的数量可以获得更好的实验结果。
贡献
- 提出了遥感领域首个生成式自监督基础模型框架(RingMo)。该框架利用大量的遥感数据来获得通用特征表示,提高了各种遥感解译任务的准确性。
- 为了增强基础模型对RS数据的处理能力,论文根据RS图像的特性设计了一种自监督方法,改善了以往掩码策略在复杂RS场景中可能忽略密集小目标的情况。
- 在没有人为监督的情况下,论文收集了200万张图像的RS数据集,这些图像来自卫星和航空平台,涵盖了六大洲不同的物体和场景,包含了大量不同的RS图像,提高了基础模型对不同场景的适应性。
- 在收集到的数据集上使用RingMo训练方法得到基础模型后,在四个典型的RS任务上对其进行微调。实验表明,本文方法在8个下游数据集上实现了SOTA,并验证了RS基础模型在各种应用中的有效性和泛化性。
RingMo框架
本文提出了一种遥感基础模型开发框架RingMo,旨在 以生成的自监督学习方式 从收集的数据集中 获得训练的基础模型。在本节中,首先从 统计信息、捕获源 和 场景分布方面介绍本文提出的数据集。然后简要介绍了应用 RingMo 训练方法的自监督学习。其中,将详细介绍 掩码策略、模型架构 和 重构目标。
数据集
本节为遥感领域的自监督学习任务 收集了一个大规模数据集。该数据集全面覆盖了各种遥感场景,具有多源、多时相、多实例的特点。数据集的细节将在后续内容中从统计信息、采集来源、场景分布三个方面进行说明。
- 统计信息
数据集中的部分图像选自遥感领域的公开数据集,其他图像来自中国高分二号卫星。然后将不同平台捕获的图像裁剪为448 × 448像素,得到多种分辨率和场景的图像2,096,640幅。数据集的复杂特征可以使基础模型学习到更鲁棒的特征表示,更适合和特定于遥感领域的下游任务。我们的数据集图像数量最多,数据集的分辨率变化范围非常大,从0.3m到30m不等。
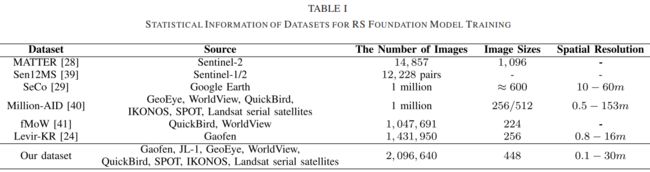
- 捕获来源
所利用的图像来自不同的传感器,具有不同的成像参数。与现有的其他遥感基础模型训练任务数据集相比,该数据集的图像同时来自航空和卫星平台:JL-1、GF-2、Ganfen satellites、GeoEye、WorldView、QuickBird、IKONOS、SPOT等。航空影像与卫星影像之间存在差异,使基础模型表现更好。卫星图像的拍摄角度往往是垂直的,而航空图像的拍摄角度则包含了倾斜的情况。航空图像的图像质量通常高于卫星图像,但卫星图像的覆盖范围比航空图像大。
- 场景分布
利用的图像覆盖了亚洲、欧洲、北美、南美、非洲、大洋洲六大洲的不同场景。在不同的季节和时间拍摄的图像也包括在内。图像之间的光照情况也不同,如光照强度、拍摄时间造成的差异、阴影造成的阴影等。上述所有情况都在下游任务中 引入了类内变化和类间相似,这对获得高度泛化的模型 提出了严峻的挑战。因此,利用尽可能多的不同特征的图像 进行预训练过程,学习更好的统一的特征表示。
基础模型训练方法RingMo
RingMo 训练方法通过生成式自监督学习来学习遥感表示。这种建模是一种典型的自动编码方法,它从原始信号的部分观察中重建。为了避免丢失小物体的特征信息,本文设计了PIMask策略。给定输入图像,PIMask 实现 区域选择 和 掩码生成。本文方法有一个编码器,提取掩码图像的隐表示,然后用于重建掩码区域的原始信号。学习到的编码器应该对各种光学遥感下游任务有用。在这项工作中,主要考虑了两种经典的视觉 Transformer 架构:ViT和 Swin Transformer。重建目标 指定要预测的原始信号的形式,L1回归损失 用于计算重建结果与像素值的差异。所提出的框架架构如图所示。

PIMask策略
大多数MIM方法常用的掩蔽策略是随机掩码,如图4所示。随机选取一定比例的图像斑块,然后进行完全掩码。这种方法在自然图像中很有用。然而,在遥感图像的应用中存在一些问题。特殊的成像机制使得背景更复杂,目标尺寸更小。随机掩码策略很容易忽略许多整体的小物体。如图 4 右侧红色块所示,随机掩模策略完全丢失了掩码patches中的小目标信息,这影响了基础模型重建小目标,增加了图像重建的难度。

因此,论文设计了一种新的掩码策略PIMask来解决这个问题。 如图 4 中左边的红色块所示,本文没有完全屏蔽图像块,而是 在屏蔽块中随机保留一些像素。采用这种掩码策略,可以有效地保留小目标的部分像素信息。就像图 4 中的蓝色块一样,本文增加了掩码块的数量以保持总掩码比率不变。
此外,为了更好地利用这些保留像素,采用 多层卷积 实现 patch embedding。一些相关研究证明,将早期卷积层 添加到 vision transformer 中可以帮助模型更好地学习图像特征。具体来说,在卷积过程中,本文让卷积核只在每个patch内部进行计算,不破坏模型的mask约束。并且不同于传统的embedding结果,多层卷积后的所有token都有特征信息,进一步提高了encoder的学习效率。
PIMask 策略的数学计算过程如下所示。首先,本文将图像分割成许多不重叠的块的集合。

本文以 被掩蔽的patch的比例α 和 patch的总数len(Cpatches) 作为输入,通过RTG(Randomly Label Generator)函数 确定每个patch的mask标签。因此,输出 mtag 是一个一维向量,其中包括patches的所有掩码标签。

得到patchi的 mask标签mtag后,就可以判断patch是否被部分屏蔽了。如公式2所示,以mask inside ratio β 和 patch的维度 dim(patchi))为输入,通过RTG函数生成每个patch的mask张量PIMaski。如公式 3 所示,直接将 patchi 与 I - PIMaski相乘,其中 I 表示单位矩阵,× 表示逐元素相乘。
模型架构
编码器:Vision Transformer / Swin Transformer
解码器:仅用于图像重建的预训练。本文用线性层进行实验。
本文将 可见patches 和掩码patches 连同位置嵌入的投影一起馈送到编码器中。具体来说,ViT 接收转换后的token嵌入序列 作为输入。与 BERT类似,ViT 预先为嵌入的token序列 准备了一个可学习的类嵌入,旨在表示 Transformer 编码器输出的全局类。 ViT 使用标准的可学习一维位置嵌入。 Transformer 编码器包括 交替的多层感知器 和 多头自注意力层。在每个部分之前使用分层模块和残差连接。 ViT 中特定于视觉的归纳偏差小于卷积神经网络 (CNN) 中的归纳偏差。
对于 Swin Transformer,它首先将图像裁剪成没有重叠的块。每个patches 都被视为一个“token”,其特征被设置为原始像素信息的聚合。投影层用于将每个patches 标记为随机维度(表示为 C)。patches token 上使用了几个指定的 Swin Transformer 块。这些块一起生成具有与经典 CNN 相同分辨率的分层表示。 Swin Transformer 是通过将 Transformer 块中的标准多头自注意力更改为基于移动窗口的模块来构建的,其他层保持不变。因此,Swin Transformer 可以方便地替换以前方法中的骨干网络来完成多项任务。
重建目标
由于像素值在光学空间中是连续的,我们的方法通过回归预测被遮挡区域的原始像素来重建输入。损失函数计算重建图像和原始图像之间的 L1 距离: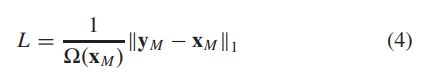
其中 ![]() 表示原始像素值和重建像素值; Ω 是元素的数量; M 表示掩码像素的集合。与其他 MIM 方法类似,RingMo只计算遮盖区域的损失。
表示原始像素值和重建像素值; Ω 是元素的数量; M 表示掩码像素的集合。与其他 MIM 方法类似,RingMo只计算遮盖区域的损失。
实验
遥感基础模型
本文使用 RingMo 训练方法用本文收集的数据集训练遥感基础模型。为了验证遥感数据对基础模型的影响,本文使用大规模遥感数据以随机掩码策略 训练基础模型,并评估不同数据量和训练epochs 的影响。此外,为了验证本文提出的创新方法,使用 PIMask 来训练基础模型。随后的实验表明,所提出的RS基础模型框架可以有效地在遥感图像上实现,更重要的是,它可以有效地提高各种下游解释任务的性能,而无需复杂的操作。
图 5:可视化了 使用 PIMask 策略重建基础模型的图像。它表明,在遥感数据集上预训练的生成式自监督模型基本上是 根据保留块的上下文信息 重建被掩蔽的区域。此外,如图5所示,这些重建结果与原始图像略有不同,表明 本文的模型 真正基于未掩蔽区域重建图像,而不是简单地记忆原始图像,并具有泛化能力。

在对基础模型进行预训练后,本文将特定任务的头 附加到预训练的主干上,并对下游任务的参数进行微调。本文在遥感图像解译中的常见任务上验证了本文的基础模型,例如场景分类、目标检测、语义分割和变化检测。实验结果验证了本文在构建的遥感数据集上预训练的生成式自监督模型的有效性。使用所提出的 RingMo 框架,可以直接在其他遥感解译任务中利用 pre-training-then-fine-tuning 的范式。
遥感场景分类

遥感目标检测


遥感语义分割

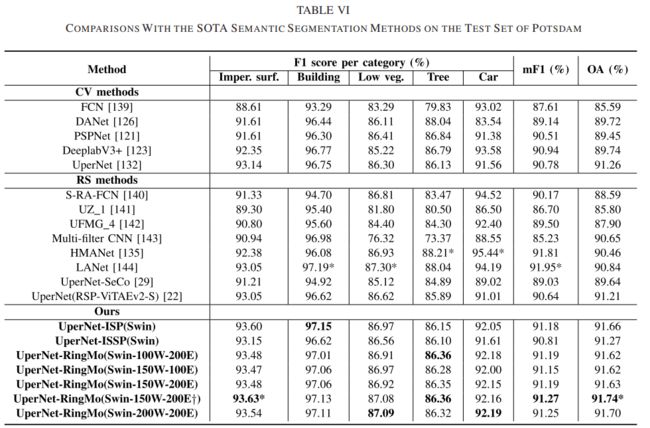
遥感变化检测


关键代码
ringmo.py
# https://github.com/comeony/RingMo/blob/master/ringmo_framework/arch/ringmo.py
# ============================================================================
"""ringmo of ringmo-framework"""
from mindspore import nn
from mindspore import ops as P
from mindspore import dtype as mstype
from ringmo_framework.loss.loss import L1Loss
from ringmo_framework.models.backbone.vit import Vit
from ringmo_framework.models.backbone.swin_transformer import SwinTransformer
class SwinTransformerForRingMo(SwinTransformer):
"""swim transformer for ringmo"""
def __init__(self, **kwargs):
super(SwinTransformerForRingMo, self).__init__(**kwargs)
assert self.num_classes == 0
dp = self.parallel_config.data_parallel
self.reshape = P.Reshape()
self.transpose = P.Transpose().shard(((dp, 1, 1),))
self.add_pos = P.Add().shard(((dp, 1, 1), (1, 1, 1)))
self.sub = P.Sub().shard(((), (dp, 1, 1)))
self.multi = P.Mul().shard(((dp, 1, 1), (dp, 1, 1)))
self.hw = int(self.final_seq ** 0.5)
def construct(self, x, mask):
"""construct of SwinTransformerForRingMo"""
# pylint: disable=W0221
x = self.multi(x, self.sub(1, mask))
x = self.patch_embed(x)
if self.ape:
x = self.add_pos(x, self.absolute_pos_embed)
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x)
x = self.transpose(x, (0, 2, 1))
x = self.reshape(x, (x.shape[0], x.shape[1], self.hw, self.hw))
return x
def no_weight_decay(self):
return super().no_weight_decay() | {'mask_token'}
class VisionTransformerForRingMo(Vit):
"""vision transformer for ringmo"""
def __init__(self, **kwargs):
super(VisionTransformerForRingMo, self).__init__(**kwargs)
assert self.num_classes == 0
dp = self.parallel_config.data_parallel
self.reshape = P.Reshape()
self.transpose = P.Transpose().shard(((dp, 1, 1),))
self.add_pos = P.Add().shard(((dp, 1, 1), (1, 1, 1)))
self.sub = P.Sub().shard(((), (dp, 1, 1)))
self.multi = P.Mul().shard(((dp, 1, 1), (dp, 1, 1)))
self.hw = int(self.num_patches ** 0.5)
self.slice = P.Slice().shard(((dp, 1, 1),))
def construct(self, x, mask):
"""construct of VisionTransformerForRingMo"""
# pylint: disable=W0221
x = self.multi(x, self.sub(1, mask))
x = self.patch_embed(x)
batch, seq, channel = x.shape
cls_tokens = self.tile(self.cls_tokens, (batch, 1, 1))
x = self.cat((cls_tokens, x))
if self.pos_embed is not None:
x = self.add_pos(x, self.pos_embed)
x = self.dropout(x)
if self.rel_pos_bias:
rel_pos_bias = self.rel_pos_bias()
x = self.encoder(x, self.encoder_input_mask, rel_pos_bias=rel_pos_bias)
else:
x = self.encoder(x, self.encoder_input_mask)
x = self.norm(x)
x = self.slice(x, (0, 1, 0), (batch, seq, channel)) # x = x[:, 1:]
x = self.transpose(x, (0, 2, 1))
x = self.reshape(x, (x.shape[0], x.shape[1], self.hw, self.hw))
return x
class RingMo(nn.Cell):
"""RingMo"""
def __init__(self, encoder, encoder_stride, use_lbp=False, parallel_config=None):
super(RingMo, self).__init__()
self.encoder = encoder
self.encoder_stride = encoder_stride
self.use_lbp = use_lbp
if parallel_config:
dp = parallel_config.data_parallel
else:
dp = 1
self.decoder = nn.Conv2d(
in_channels=self.encoder.num_features,
out_channels=self.encoder_stride ** 2 * 3,
kernel_size=1, has_bias=True, pad_mode='pad'
)
# encoder output -> [B,C,H,W]
self.decoder.conv2d.shard(((dp, 1, 1, 1), (1, 1, 1, 1)))
self.decoder.bias_add.shard(((dp, 1, 1, 1), (1,)))
self.decoder_lbp = nn.Conv2d(
in_channels=self.encoder.num_features,
out_channels=self.encoder_stride ** 2 * 3,
kernel_size=1, has_bias=True, pad_mode='pad'
)
# encoder output -> [B,C,H,W]
self.decoder_lbp.conv2d.shard(((dp, 1, 1, 1), (1, 1, 1, 1)))
self.decoder_lbp.bias_add.shard(((dp, 1, 1, 1), (1,)))
self.pixelshuffle = P.DepthToSpace(self.encoder_stride).shard(((dp, 1, 1, 1),))
self.in_chans = self.encoder.in_chans
self.patch_size = self.encoder.patch_size
self.l1_loss = L1Loss(reduction='none', parallel_config=parallel_config)
self.expand_dim = P.ExpandDims().shard(((dp, 1, 1),))
self.cast = P.Cast()
self.div = P.Div().shard(((), ()))
self.multi = P.Mul().shard(((dp, 1, 1, 1), (dp, 1, 1, 1)))
self.sum = P.ReduceSum().shard(((dp, 1, 1, 1),))
self.add = P.Add().shard(((), ()))
def ringmo_loss(self, x, x_rec, lbp=None, lbp_rec=None, mask=None):
"""ringmo loss"""
x = self.cast(x, mstype.float32)
x_rec = self.cast(x_rec, mstype.float32)
mask = self.cast(mask, mstype.float32)
loss_ori_recon = self.l1_loss(x, x_rec)
loss_ori_mask = self.mean(loss_ori_recon, mask)
loss_lbp_mask = 0.
if self.use_lbp:
loss_lbp_recon = self.l1_loss(lbp, lbp_rec)
loss_lbp_mask = self.mean(loss_lbp_recon, mask)
loss = self.add(loss_ori_mask, loss_lbp_mask)
return loss
def mean(self, loss, mask):
mul_a = self.multi(loss, mask)
div_a = self.sum(mul_a)
sum_b = self.sum(mask)
div_b = self.add(sum_b, 1e-5)
loss_mask = self.div(div_a, div_b)
loss_mask = self.div(loss_mask, self.in_chans)
return loss_mask
def _check_input(self, inputs):
if not self.use_lbp:
return inputs[0], None, inputs[1]
return inputs[0], inputs[1], inputs[2]
def construct(self, *inputs):
"""construct of RingMo"""
x_in, lbp_in, mask_in = self._check_input(inputs)
# x -> [B,L,C]
z = self.encoder(x_in, mask_in)
# z -> [B,C,H,W]
x_rec = self.decoder(z)
# self.summary_4d("decoder_conv2d", self.decoder.weight)
# z -> [B,C,H,W]
x_rec = self.pixelshuffle(x_rec)
lbp_rec = None
if lbp_in is not None:
lbp_rec = self.decoder_lbp(z)
lbp_rec = self.pixelshuffle(lbp_rec)
sim_loss = self.ringmo_loss(x_in, x_rec, lbp_in, lbp_rec, mask_in)
return sim_loss
def no_weight_decay(self):
if hasattr(self.encoder, 'no_weight_decay'):
return {'encoder.' + i for i in self.encoder.no_weight_decay()}
return {}
def no_weight_decay_keywords(self):
if hasattr(self.encoder, 'no_weight_decay_keywords'):
return {'encoder.' + i for i in self.encoder.no_weight_decay_keywords()}
return {}
def ringmo_vit_base_p16(**kwargs):
encoder = VisionTransformerForRingMo(patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, **kwargs)
return RingMo(encoder=encoder, encoder_stride=16)
def ringmo_vit_large_p16(**kwargs):
encoder = VisionTransformerForRingMo(patch_size=16, embed_dim=1024, depth=24, num_heads=16, mlp_ratio=4, **kwargs)
return RingMo(encoder=encoder, encoder_stride=16)
def ringmo_swin_tiny_p4_w6(**kwargs):
encoder = SwinTransformerForRingMo(
image_size=192, patch_size=4, embed_dim=96, depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24], window_size=6, mlp_ratio=4, **kwargs)
return RingMo(encoder=encoder, encoder_stride=32)
def ringmo_swin_tiny_p4_w7(**kwargs):
encoder = SwinTransformerForRingMo(
image_size=224, patch_size=4, embed_dim=96, depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24], window_size=6, mlp_ratio=4, **kwargs)
return RingMo(encoder=encoder, encoder_stride=32)
def ringmo_swin_base_p4_w6(**kwargs):
encoder = SwinTransformerForRingMo(
image_size=192, patch_size=4, embed_dim=128, depths=[2, 2, 18, 2],
num_heads=[4, 8, 16, 32], window_size=6, mlp_ratio=4, **kwargs)
return RingMo(encoder=encoder, encoder_stride=32)
def ringmo_swin_base_p4_w7(**kwargs):
encoder = SwinTransformerForRingMo(
image_size=224, patch_size=4, embed_dim=128, depths=[2, 2, 18, 2],
num_heads=[4, 8, 16, 32], window_size=7, mlp_ratio=4, **kwargs)
return RingMo(encoder=encoder, encoder_stride=32)
def build_ringmo(config):
"""build ringmo"""
model_type = config.model.backbone
if model_type == 'swin':
encoder = SwinTransformerForRingMo(
parallel_config=config.parallel_config,
moe_config=config.moe_config,
batch_size=config.train_config.batch_size * config.device_num
if config.parallel.parallel_mode == "semi_auto_parallel" else config.train_config.batch_size,
image_size=config.train_config.image_size,
patch_size=config.model.patch_size,
in_chans=config.model.in_chans,
num_classes=0,
embed_dim=config.model.embed_dim,
depths=config.model.depth,
num_heads=config.model.num_heads,
window_size=config.model.window_size,
mlp_ratio=config.model.mlp_ratio,
qkv_bias=config.model.qkv_bias,
qk_scale=config.model.qk_scale,
drop_rate=config.model.drop_rate,
drop_path_rate=config.model.drop_path_rate,
ape=config.model.ape,
patch_norm=config.model.patch_norm,
patch_type=config.model.patch_type)
encoder_stride = 32
elif model_type == 'vit':
encoder = VisionTransformerForRingMo(
parallel_config=config.parallel_config,
moe_config=config.moe_config,
batch_size=config.train_config.batch_size * config.device_num
if config.parallel.parallel_mode == "semi_auto_parallel" else config.train_config.batch_size,
image_size=config.train_config.image_size,
patch_size=config.model.patch_size,
in_chans=config.model.in_chans,
num_classes=0,
embed_dim=config.model.embed_dim,
depth=config.model.depth,
num_heads=config.model.num_heads,
mlp_ratio=config.model.mlp_ratio,
drop_rate=config.model.drop_rate,
drop_path_rate=config.model.drop_path_rate,
use_abs_pos_emb=config.model.use_abs_pos_emb,
init_values=config.model.init_values,
use_rel_pos_bias=config.model.use_rel_pos_bias,
use_shared_rel_pos_bias=config.model.use_shared_rel_pos_bias,
patch_type=config.model.patch_type)
encoder_stride = 16
else:
raise NotImplementedError(f"Unknown pre-train model: {model_type}")
model = RingMo(encoder=encoder, encoder_stride=encoder_stride, parallel_config=config.parallel_config,
use_lbp=config.model.use_lbp)
return model