豆瓣电影top250信息爬取
摘要
python的网络爬虫可以方便抓取网页的消息,本文以豆瓣网站为例,实现了python网络爬虫抓取豆瓣电影排行榜top250的过程,以及其中遇到的问题和解决过程。
1.引言
网络爬虫又称网络蜘蛛,或网络机器人。是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。网络爬虫通过网页的链接地址来查找网页内容,并直接返回给用户所需要的数据,不需要人工操纵浏览器获取。Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言,具有易于学习、易于维护等优点,其自带了urlib、urlib2等库满足了爬虫的基本使用,同时网络爬虫对于python的入门具有非常大的帮助。
2.系统结构
分别使用了Beautiful Soup模块以及csv模块
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。所以不需要考虑编码方式。
CSV模块之中实现了读写CSV格式文件的一些类,他可以让你的程序以一种更容易被Excel处理的格式来输出或者读入数据,而不必纠结于CSV文件的一些麻烦的小细节。而且CSV模块可以让你更自由的定制你想要的CSV格式文件。
3. 实现代码
数据的抓取
import requests
import tkinter
import unicodecsv as csv
from bs4 import BeautifulSoup
from tkinter import *
首先导入几个基本的库:
Request相对于urllib来说既能满足需求,而且更加方便,
Tkinter为之后的gui界面设计提供条件,
Csv模块能让结果输出成csv文件,方便数据的处理,
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能,通过解析文档为用户提供需要抓取的数据。

打开网页豆瓣电影top250,f12进行观察分析。
网址为:https://movie.douban.com/top250?start=0&filter=

通过分析观察得知,每次点下一页,则start增加25,且start初始值为0。
start = 0
使变量start=0,表示从第一页开始。
result = []
其次定义存储结果的列表result
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
f12,在Headers中找到User-Agent,代码中定义headers,模拟浏览器访问。
for i in range(0,10):
#250部电影,一页25部
html = requests.get('https://movie.douban.com/top250?start='+str(start)+'&filter=',headers=header)
html.encoding = 'utf-8'
for循环抓取每页信息,共10页,利用requests发送请求,因为返回要求为中文,所以定义编码格式为utf-8。
start+=25
每循环一次跳转下一页,start增加25。
for item in soup.find_all('div','info'):
#搜索以该标签为起始的内容
title = item.div.a.span.string
该段代码首先f12观察规律


经过对比发现关于电影的部分都是以该标签为起始,再次观察定位标题部分的位置,最后捕捉。
try:
intro = item.find('span',{'class':'inq'}).string
#获取电影简介
except AttributeError:
pass
在获取简介时出现AttributeError类型异常,为保证程序正常运行,捕捉异常但不进行处理。
about = item.find('div','bd').p.contents[2].string
about = about.replace('\n','')
#去掉分行
about = about.replace(' ', '')
#去掉空格
about1 = about.split('\xa0/\xa0')
#去掉\xa0字符
year = about1[0]
#获取电影拍摄时间
country = about1[1]
#获取电影拍摄国家
people = item.find('div', 'bd').p.contents[0].string
people = people.replace('\n','')
#去掉分行
people = people.replace(' ','')
#去掉空格
people = people.split(' ',1)
#将该行信息分成导演与演员
director = people[0]
#获取电影拍摄导演
rating = item.find('span',{'class':'rating_num'}).get_text()
#获取电影评分
result.append([title,year,director,rating,country,intro])
#结果传入resul
分别捕捉导演、评分、时间、国家等信息

网页中,这些信息都会有空格以及分行等因素干扰,使用replace()去掉分行和空格。又因为发现输出结果中有空白符\xa0,所以使用split()去掉结果中的空白符,并使该行内容分为时间和国家两部分。最后把所有结果传入result。
with open('text.csv','wb') as f:
w = csv.writer(f)
w.writerows(result)
#将结果保存为csv文件
print(result)
使用with open语句写入文件,writerows()可将写入的结果分行。
数据可视化的实现
import collections
import pandas as pd
from matplotlib import pyplot as plt
collections模块提供计数功能
pandas模块进行数据分析
matplotlib模块提供绘图功能
df = pd.read_excel("data.xlsx")
# 读取表格数据
show_time = list(df["year"])
#时间列表
show_time_count = collections.Counter(show_time)
show_time_count = show_time_count.most_common(10)
#Counter方法设立计数器,统计前十的年份
show_time_dic = {k: v for k, v in show_time_count}
# 字典推导式更换年份和次数排行
show_time = sorted(show_time_dic)
# 按年份从小到大排序
counts = [show_time_dic[k] for k in show_time]
# 高分电影数量
统计前十年份并排序
plt.figure(figsize=(9, 6), dpi=100)
#设定宽高和分辨率
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 设置字体
plt.bar(show_time, counts, width=0.5, color="cyan")
# 绘制条形图
plt.yticks(range(0, 16, 2))
#重新设置y轴刻度
plt.xlabel("年份")
plt.ylabel("高分电影数量")
plt.title("高分电影数量最多年份Top10", fontsize=15)
# 添加描述信息
plt.grid(alpha=0.2, linestyle=":", c='r')
# 添加网格、网格的透明度、线条样式
plt.show()
设置可视化界面
4.实验
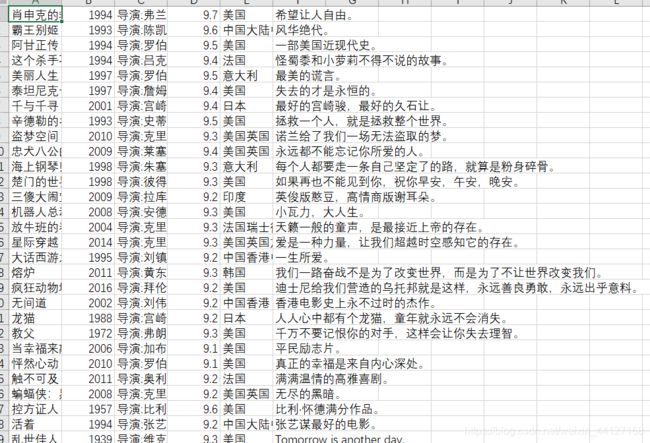
实验结果如下

表格打开
可视化处理

5. 总结和展望
经过本次实验后,我了解到了python网络爬虫的部分运用,利用Beautiful Soup模块可以获取网页的内容,并通过正则表达式提取分析所需要的信息。遗憾的是,设想中电影预告片的下载与gui界面的设计由于时间原因并未实现,希望在这次作业之后,能在假期将所有功能完善。此次实验也让我对python的功能与便捷有了进一步的理解,python是一门较好入门的语言,具有很大的潜力,希望能在以后的学习中更加深入挖掘python的功能,掌握其更多知识。
参考文献:
[1] bilibili. python爬虫爬取豆瓣电影
[2] 钱程,阳小兰,朱福喜. 基于python的网络爬虫技术