[论文精读]Semi-Supervised Classification with Graph Convolutional Networks
论文原文:[1609.02907] Semi-Supervised Classification with Graph Convolutional Networks (arxiv.org)
论文代码:GitHub - tkipf/gcn: Implementation of Graph Convolutional Networks in TensorFlow
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
目录
1. 省流版
1.1. 心得
1.2. 论文框架图
2. 论文逐段阅读
2.1. Abstract
2.2. Introduction
2.3. Fast approximate convolutions on graphs
2.3.1. Spectral graph convolutions
2.3.2. Layer-wise linear model
2.4. Semi-supervised node classification
2.4.1. Example
2.4.2. Implementation
2.5. Related work
2.5.1. Graph-based semi-supervised learning
2.5.2. Neural networks on graphs
2.6. Experiments
2.6.1. Datasets
2.6.2. Experimental set-up
2.6.3. Baselines
2.7. Results
2.7.1. Semi-supervised node classifiication
2.7.2. Evaluation of propagation model
2.7.3. Training time per epoch
2.8. Discussion
2.8.1. Semi-supervised model
2.8.2. Limitations and future work
2.9. Conclusion
3. 知识补充
3.1. Skip-gram
3.2. Bag of words
3.3. Spectral graph convolutions
4. Reference List
1. 省流版
1.1. 心得
(1)怎么开头我就不知道在说什么啊这个论文感觉表述不是很清晰?
(2)数学部分推理很清晰
(3)要是模型展示更清晰就好了
1.2. 论文框架图
![[论文精读]Semi-Supervised Classification with Graph Convolutional Networks_第1张图片](http://img.e-com-net.com/image/info8/29b3fe5476304633aba430be87b08bb8.jpg)
2. 论文逐段阅读
2.1. Abstract
①Their convolution is based on localized first-order approximation
②They encode node features and local graph structure in hidden layers
2.2. Introduction
①The authors think adopting Laplacian regularization in the loss function helps to label:

where ![]() represents supervised loss with labeled data,
represents supervised loss with labeled data,
![]() is a differentiable function,
is a differentiable function,
 denotes weight,
denotes weight,
 denotes matrix with combination of node feature vectors,
denotes matrix with combination of node feature vectors,
![]() represents the unnormalized graph Laplacian,
represents the unnormalized graph Laplacian,
 is adjacency matrix,
is adjacency matrix,
 is degree matrix.
is degree matrix.
②The model trains labeled nodes and is able to learn labeled and unlabeled nodes
③GCN achieves higher accuracy and efficiency than others
2.3. Fast approximate convolutions on graphs
①GCN (undirected graph):
![]()
where  denotes self-connection adjacency matrix, which means
denotes self-connection adjacency matrix, which means 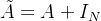 ,
,
![]() denotes identity matrix,
denotes identity matrix,
![]() denotes self-connection degree matrix,
denotes self-connection degree matrix,
 represents the trainable weight matrix in
represents the trainable weight matrix in  -th layer,
-th layer,
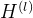 denotes the activation matrix in -th layer,
denotes the activation matrix in -th layer,
![]() represents activation function
represents activation function
2.3.1. Spectral graph convolutions
①Spectral convolutions on graphs:
![]()
where the filter ![]() ,
,
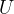 comes from normalized graph Laplacian
comes from normalized graph Laplacian ![]() and is the matrix of
and is the matrix of  's eigenvectors,
's eigenvectors,
 denotes a diagonal matrix with eigenvalues.
denotes a diagonal matrix with eigenvalues.
②However, it is too time-consuming to compute matrix especially for large graph. Ergo, approximating it in 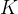 -th order by Chebyshev polynomials:
-th order by Chebyshev polynomials:
![]()
where ![]() ,
,
![]() denotes Chebyshev coefficients vector,
denotes Chebyshev coefficients vector,
recursive Chebyshev polynomials are ![]() with baseline
with baseline 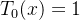 and
and 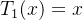
③Then get new function:
![]()
where ![]() ,
, ![]() .
.
④Through this approximation method, time complexity reduced from  to
to ![]()
2.3.2. Layer-wise linear model
①Then, the authors stack the function above to build multiple conv layers and set ![]() ,
, 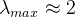
②They simplified 2.3.1. ③ to:
![]()
where ![]() and
and ![]() are free parameters
are free parameters
③Nevertheless, more parameters bring more overfitting problem. It leads the authors change the expression to:
![]()
where they define ![]() ,
,
eigenvalues are in ![]() .
.
But keep using it may cause exploding/vanishing gradients or numerical instabilities.
④Then they adjust ![]()
⑤The convolved signal matrix ![]() :
:
![]()
where  denotes input channels, namely feature dimensionality of each node,
denotes input channels, namely feature dimensionality of each node,
 denotes the number of filters or feature maps,
denotes the number of filters or feature maps,
![]() represents matrix of filter parameters
represents matrix of filter parameters
2.4. Semi-supervised node classification
The whole model shows:
![[论文精读]Semi-Supervised Classification with Graph Convolutional Networks_第2张图片](http://img.e-com-net.com/image/info8/26091d7fb099498c994cce072fc6ac56.jpg)
2.4.1. Example
①They take 2 layers model
②Forward propagation:
![]()
where ![]() is a weight matrix with
is a weight matrix with  feature maps, it crosses input layer to hidden layer,
feature maps, it crosses input layer to hidden layer,
![]() is a weight matrix crossing hidden layer to output layer,
is a weight matrix crossing hidden layer to output layer,
ReLU is for every row
③Cross entropy:
![]()
where ![]() is the set of node indices of which nodes with labels
is the set of node indices of which nodes with labels
④They adopt mini-batch stochastic gradient descent
2.4.2. Implementation
①Framework: TensorFlow
②Method: sparse-dense matrix multiplications
③Computational complexity: ![]()
2.5. Related work
2.5.1. Graph-based semi-supervised learning
(1)Previous graph representations:
①Explicit graph Laplacian regularization: such as deep semi-supervised embedding, manifold regularization, label propagation
②Graph-embedding
(2)Recent works:
①DeepWalk
②LINE
③node2vec
2.5.2. Neural networks on graphs
①Briefly introduced other works
②Their approach is based on spectral graph convolutional neural networks
2.6. Experiments
They tested their model in:
①Semi-supervised document classification in citation networks
②Semi-supervised entity classification in a bipartite graph extracted from a knowledge graph
③Evaluation of various graph propagation models
④Run-time analysis on random graphs
bipartite adj.两部分组成的;有两个部分的
2.6.1. Datasets
①Datasets table:
![[论文精读]Semi-Supervised Classification with Graph Convolutional Networks_第3张图片](http://img.e-com-net.com/image/info8/edde1408a0fd4f09b33b15864d51203b.jpg)
where documents represented by nodes, citation links represented by edges;
also, ![]() ;
;
NELL is a bipartite graph dataset including 55,864 relation nodes and 9,891 entity nodes
②Citation networks: sparse bag-of-words feature vectors and list of citation links for and between documents are contained. Besides, undirected edges are citation links and 20 labels for one class only
③NELL: edges are labeled, directed connections. Additionally, one-hot representation is adopted in each node
④Random graphs: randomly genetate graph with N nodes and 2N edges
2.6.2. Experimental set-up
①Labeled sample test set: 1,000
②They usually adopt 2 layers, but further test extra 10 layers in appendix b
③Epoch: under 200
④Optimizer: Adam
⑤Stop training when there is no decreasing of loss for 10 consecutive epochs
⑥Hidden layer includes 32 units
⑦Omit dropout and regularization
2.6.3. Baselines
①They train local classifier with labeled data and then train unlabeled with a random node ordering for 10 iterations
②L2 regularization parameter and aggregation operator selected by performance of validation set
2.7. Results
2.7.1. Semi-supervised node classifiication
(1)Comparison of accuracy table with mean accuracy of 100 times in random ordering:
![[论文精读]Semi-Supervised Classification with Graph Convolutional Networks_第4张图片](http://img.e-com-net.com/image/info8/f088fcbeaab74cf38311003c29740fcb.jpg)
(2)Parameters for Citeseer, Cora and Pubmed
①Dropout rate: 0.5
②L2 regularization: 5e-4
③Hidden units number: 16
(3)Parameters for NELL
①Dropout rate: 0.1
②L2 regularization: 1e-5
③Hidden units number: 64
2.7.2. Evaluation of propagation model
They compared variants of their propagation model on citation network datasets, where GCN is the bold one:
![[论文精读]Semi-Supervised Classification with Graph Convolutional Networks_第5张图片](http://img.e-com-net.com/image/info8/121d281c7a914287b6251134eea91980.jpg)
2.7.3. Training time per epoch
Mean training time per epoch of 100 epochs. Each epoch contains forward propagation, cross entropy computing, backward propagation:
![[论文精读]Semi-Supervised Classification with Graph Convolutional Networks_第6张图片](http://img.e-com-net.com/image/info8/409150b82ef34c34a0c7aade6976dda4.jpg)
where * denotes memory explosion
2.8. Discussion
2.8.1. Semi-supervised model
①The authors attribute low efficiency of graph-Laplacian regularization to only encoding similar nodes
②In addition, they think skip-gram is hard to optimize
③Then, they reckon renormalized propagation is better than na¨ıve 1 st-order model and higher-order graph convolutional models with Chebyshev polynomials
2.8.2. Limitations and future work
①Lack of memory. Slightly alleviated by mini-batch stochastic gradient descent
②The model does not support directed edge or edge features. (后面说的那句话不是很能理解,翻译成中文是“通过将原始有向图表示为具有原始图中表示边缘的附加节点的无向二部图,可以同时处理有向边和边缘特征”。难道说原本是一个普通的图,把每条边都变成一个节点放在另一边,然后和原先的节点合起来变成二部图?但是很奇怪啊)
③Weight of self-connection might vary in different graphs:
![]()
2.9. Conclusion
They proposed a novel and efficient semi-supervised graph convolutional network
3. 知识补充
3.1. Skip-gram
相关链接:理解 Word2Vec 之 Skip-Gram 模型 - 知乎 (zhihu.com)
3.2. Bag of words
相关链接:使用 Python 的 NLP 中的单词袋简介 |什么是 BoW? (mygreatlearning.com)
3.3. Spectral graph convolutions
相关链接:谱图卷积 - 知乎 (zhihu.com)
4. Reference List
Kipf, T. & Welling, M. (2017) 'Semi-Supervised Classification with Graph Convolutional Networks', ICLR 2017, doi: https://doi.org/10.48550/arXiv.1609.02907