cloud 问题
eureka 自我保护机制
eureka 是定时去拿
统计最近15分钟的eureka实例正常的心跳占比,如果低于85%,那么就会触发自我保护机制。
触发了自我保护机制,eureka 暂时会把失效的服务保护起来,不让其过期,但是这些服务也不是永远不过期。
eureka 在启动后定时任务,每 60s,检查一次服务健康状态,如果这些被保护起来的失效服务90s内还是没有恢复,·就会把这些服务剔除。,如果在此期间服务恢复了并且实例心跳数占比高于85%,就会关闭自我保护机制。
注册中⼼ eureka
1、⼼跳机制/服务剔除
⽣产者向eureka 进⾏注册之后,⽣产者会向eureka 进⾏30s⼼跳续约,如果说,在90s时间之内,都没有接受到⼼跳,于是eureka就判断⾃⼰是否有⾃我保护机制,如果有⾃我保护机制,这个服务他也不会删,如果没有⾃我保护机制,剔除⾃我保护机制:其实是为了防⽌⽹络抖动⽽产⽣的误删
2、详细介绍他的原理
eureka 底层有⼀个readOnly和readWrite缓存,⽣产者向eureka 进⾏服务的注册,⼀旦注册完,eureka 就⽴刻将数据同步给readWrite缓存,该缓存绑定了定时器,会定期将数据同步给readOnly缓存,消费者 会定期去拉取 readOnly中的数据,完成消费者对⽣产者的调⽤
nacos eureka
nacos :
临时实例: 默认,如果宕机,就剔除。 需要主动采用向nacos 心跳监测
非临时:宕机不会剔除,nacos 主动询问 是否 活着
spring:
cloud:
nacos:
discovery:
ephemeral: fale # 设置为非临时
服务注册,服务拉取,心跳等待,
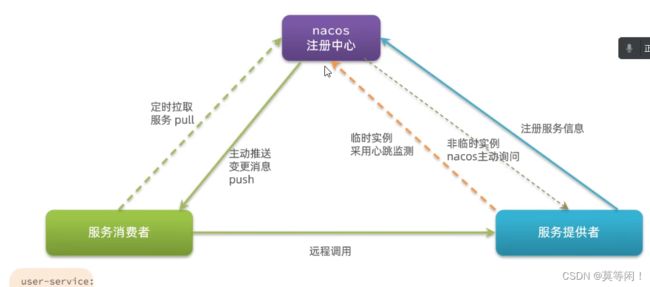
消费者 默认 定时拉取,一旦nacos 监测到服务变更,会主动推送变更的消息。
nacos eureka 相同点:
- 都支持服务的注册 和服务的拉取
- 都支持 服务提供者 心跳方式做监测。
不同点 - nacos 支持 服务端 主动监测 提供者的状态 ,临时实例采用心跳,永久实例 采用nacos 主动监测的方式。
- nacos 临时 会被剔除,永久不会
- nacos 监测到服务列表变更时,采用消息推送的模式。
nacos 学习
Nacos详细教程
Nacos Namespace、Group和DataID三者关系
1. nacos 分级存储模型
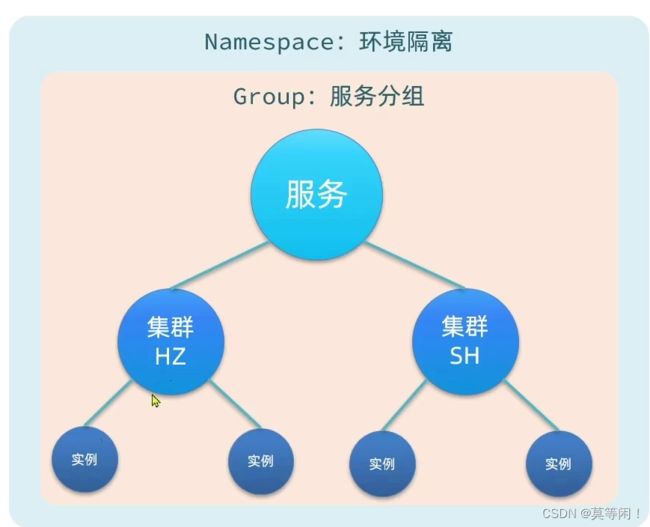
服务->集群(杭州集群、上海集群)-> 实例
配置了 sh 集群、hz集群 userservice
接着 修改 orderService 配置 hz集群
spring:
cloud:
nacos:
disvocery:
cluster-name: hz
期望: orderservice(hz集群) 调用 uservice(集群) 期望调用 本地集群也就是 hz 集群
修改 默认负载均衡策略
ribbon:
NacosRule
1.1 修改权重
编辑 集群 权重
权重设置为0 一次都不访问。
根据这一特性,先将8081 服务器权重改为0,进行停机版本升级。升级完后,进行灰度发布,平滑升级
1.2 环境隔离 namespace
创建namespace,
在代码配置文件,添加 namespace 的id,
总结:
环境隔离是使用 namespace 来实现的,2. 每个namespace 都有唯一id,3 不同namespace 下 服务是不可见的。
2. nacos eureka 对比

总结:
共同点:
都支持服务的注册和拉取。
都支持心跳监测机制
不同点:
- nacos 支持服务端 主动 检测提供者 状态,
临时实例用心跳模式,非临时实例采用 主动监测模式。 - 临时实例 不正常 会被剔除, 非临时实例 不回被剔除。
- nacos 支持 服务列表变更的消息推送模式, 服务列表更新更及时。 eureka 只支持定时拉取模式。
- Nacos
集群采用 默认 AP 模式 ,当集群有非临时 实例时,切换为cp 模式。
eureka 采用 ap 模式。
3 配置管理
DataId :服务名称-开发环境.yaml
项目启动,bootstrap.yaml 读取(nacos 地址),读取nacos、application.yaml读取本地配置文件, 创建spring 容器。
- 新建 bootstrap.yaml
1 配置服务名称, 2 dev
3 nacos 地址 4 文件后缀名称 yaml
服务名称-dev.后缀名 dataid
3.1 配置热更新
@RefreshScope
针对@Value 注解
@ConfigurationProperties
4 微服务 配置共享
服务在启动的时候 会读取一下配置
服务名称-环境.yaml
服务名称.yaml 不根据环境改变, 来保证环境共享。
4.1 配置文件优先级问题
本地 配置文件 name =1, 优先级 3
nacos uservice name=共享1 优先级 2
uservice-dev.yaml name= dev 优先级 1
优先级 记忆:
线上配置 服务名-dev.yaml > 服务名称.yaml > 本地配置
5 面试 nacos
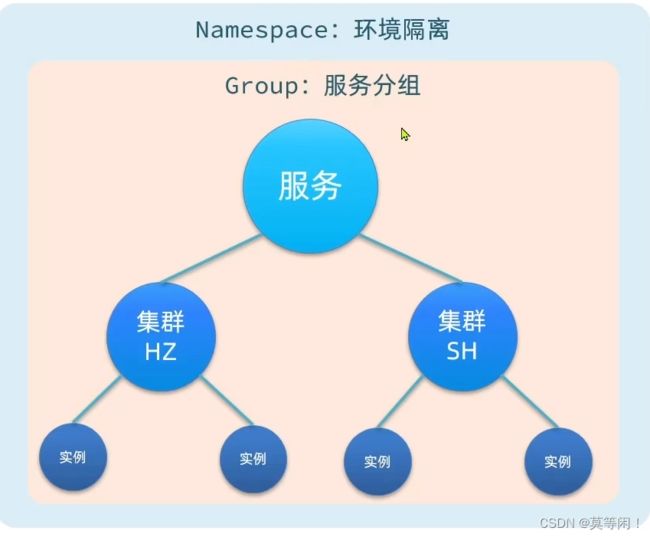
5.1 注册表结构
namespace-> group -> 服务-> 集群-> 实例
分级模型
服务分级存储模型
serviceMap 服务注册表
Map< String,Map < String ,Service > > serviceMap
注册表结构 话术:
- 讲 nacos 分级存储模型。
- 在源码中 分级存储模型的对应关系。
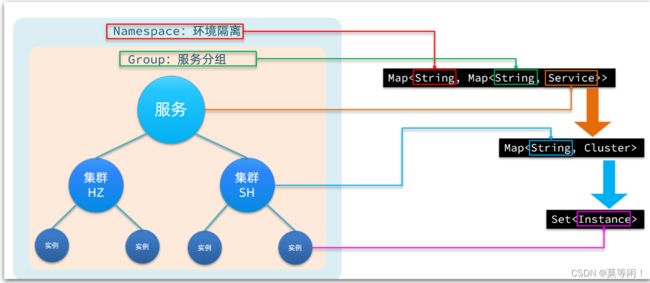
Nacos采用了数据的分级存储模型,最外层是Namespace,用来隔离环境。然后是Group,用来对服务分组。接下来就是服务(Service)了,一个服务包含多个实例,但是可能处于不同机房,因此Service下有多个集群(Cluster),Cluster下是不同的实例(Instance)。
对应到Java代码中,Nacos采用了一个多层的Map来表示。
结构为Map
内层Map的key是group拼接serviceName,值是Service对象。
Service对象内部又是一个Map,key是集群名称,值是Cluster对象。
而Cluster对象内部维护了Instance的 set 集合。 分为 临时实例set ,永久实例set。
5.2 如何支撑十万压力
- nacos 集群模式。
- 针对于
临时实例。 nacos 内部接收到服务注册请求时,不会立即更新注册表,而是将服务注册的任务放入阻塞队列中 takes.offer(),,然后立即响应给客户端。接着利用线程池读取阻塞队列中的任务 死循环 tasks.take() 获取任务,异步来完成实例的更新,从而提高并发能力。
5.3 如何避免并发读写冲突
并发写冲突问题
加synchronized 对Service 加锁,并且线程池使用单线程的方式。解决写冲突,
针对读写冲突。
Nacos 在更新实例列表时,会采用CopyonWrite 技术,首先将旧的数据拷贝一份,然后更新拷贝的实例列表,再用更新后的实例列表覆盖旧的实例列表。
这样在更新过程中,就不对 读实例列表的请求产生影响,也不会出现脏数据问题。
5.4 nacos eureka 区别
接口方式: 通过restful 方式,用来实现服务注册、发现等功能。
实例类型:nacos 实例分为永久实例 临时实例,eureka 只有临时实例。
健康监测:nacos 对临时实例采取心跳方式,对永久实例采用主动请求的方式。eureka 只支持心跳监测。
服务发现: Nacos 支持定时 拉取 和主动推送的 两种模式,eureka 只支持定时拉模式。
5.5 sentinel hystrix
线程隔离: hystrix 默认线程池,(也有信号量)。弊端 创建线程池过多。
sentinel 信号量默认 计数器。
线程池隔离优点: ·控制能力强。异步调用
缺点 : 线程额外开销大。
信号量隔离: 优点:轻量级,无额外开销。
缺点:不支持主动超时,不支持异步调用。
话术: hystrix 默认是基于线程池隔离的,每一个隔离的线程池都要创建一个独立的线程池。线程池过多会带来额外的cpu 开销。性能一般,但是隔离性强。
sentinel 是基于信号量(计数器) 实现的线程隔离。
| sentinel | hystrix | |
|---|---|---|
1. 隔离策略 |
信号量隔离 | 线程池隔离(默认).信号量 |
2.熔断降级策略 |
基于慢调用比例(响应时间)、或者异常比例 | 基于失败比例 |
3. 限流 |
基于qps, 调用关系、热点参数 param key | 基于线程池 大小 |
4. 流量整形 |
突发流量 变为稳定的流量,慢启动 warm up ,匀速排队 排队等待 | 不支持 |
5. 授权规则 |
黑白名单 |
| 信号量 | 线程池隔离 | |
|---|---|---|
| 优点 | 轻量级,不需要开启独立线程 | 支持主动超时,独立的线程 进行 异步调用 |
| 缺点 | 不支持异步调用 | 1. 线程开销大 |
| 场景 | 高扇出 网关() |
低扇出 ,扇出越多,需要的线程越多 |
hystrix 采用命令模式,将调用和调用结果封装到 HystrixCommand的命令类中,底层执行是基于rxjava,
sentinel
5.6 sentinel 限流和gateway 限流区别
gateway 采用基于redis 实现的令牌桶算法,sentinel 内部比较复杂:
- 默认限流模式是基于 滑动窗口算法
- 排队等待 (
流控效果)的限流模式是 基于漏桶算法 - 热点参数 基于令牌桶算法。
限流常见算法:
4. 计数算法。 窗口计数法,滑动窗口计数法( 窗口跨度 interval 为1s,划分 n个区间)。
5. 令牌桶算法。
固定速度生成令牌 放入桶中,桶满了,丢弃多余令牌。
请求来了,先获取令牌。 请求qps 6> 生成速度 5,多余的请求会被丢弃。
建议 设置服务器并发上限的 一半左右
6. 漏桶算法。
桶里存请求,以固定速度放出请求。
漏桶满了,多余的请求就会被丢弃。
优势: 应对突发请求,
sentinel 实现漏桶,采用排队等待模式。
6 雪崩问题
微服务 调用链路的某个服务发生故障,引起整个链路的所有服务都不可用,这就是雪崩问题。
6.1.1 超时处理
调用业务时,设置超时时间。
6.1.2 舱壁模式
限定每个业务使用的线程数,避免耗尽整个tomcat资源耗尽,因此也叫线程池隔离。
6.1.3 熔断降级模式
由断路器统计业务异常比例。如果超出阈值会熔断业务。
6.1.4 流量控制模式
限制业务qps, 预防雪崩。
6.2 流控规则 限流

6.2.1 高级模式
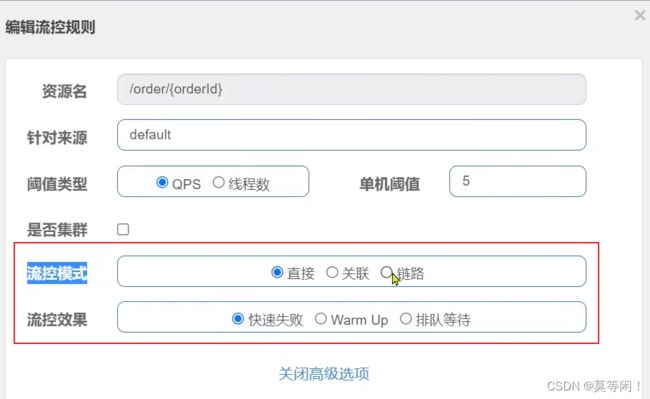
6.2.2 流控模式
直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
A b 两个资源,a触发阈值,对b 进行限流。链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
a b 都访问c,统计时,只统计从a 过来的,b 不管。
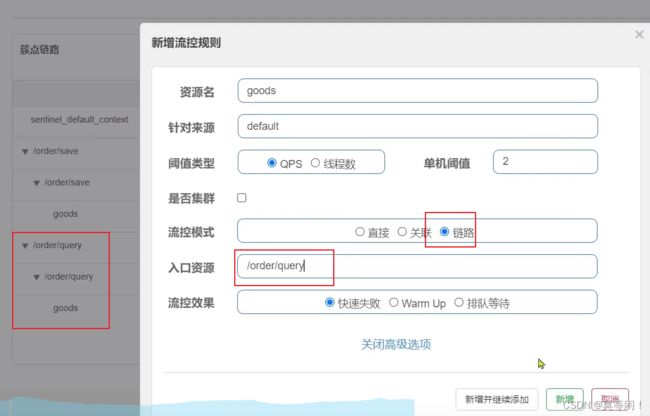
关联模式 资源
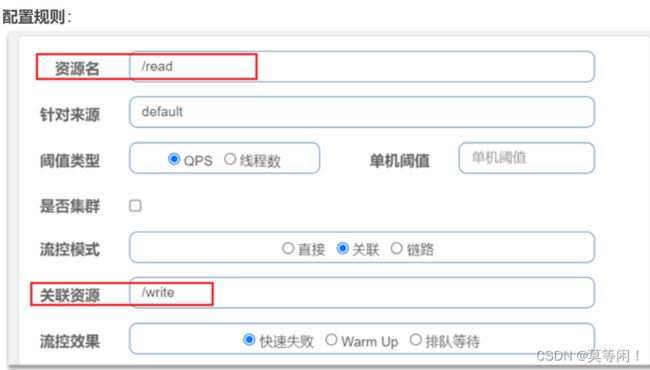
在OrderController新建两个端点:/order/query和/order/update,无需实现业务
配置流控规则,当/order/ update资源被访问的QPS超过5时,对/order/query请求限流
对query 进行添加流控规则
链路模式
a b 都有c 的依赖,
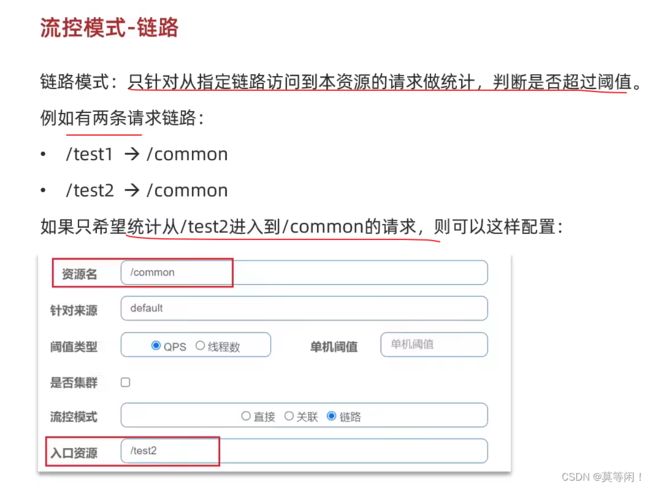
控制 query , goods
6.2.3 流控效果
效果有哪些


快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。是默认的处理方式。
-warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长
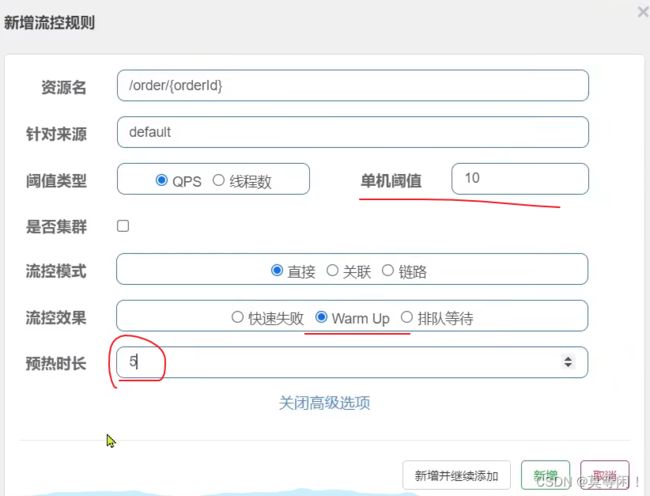
warm up
冷启动模式,初始阈值为 threshold /coldFactor ,持续增长后,逐渐提高到thrshold值, coldFactor 默认为3.
需求:给/order/{orderId}这个资源设置限流,最大QPS为10,利用warm up效果,预热时长为5秒
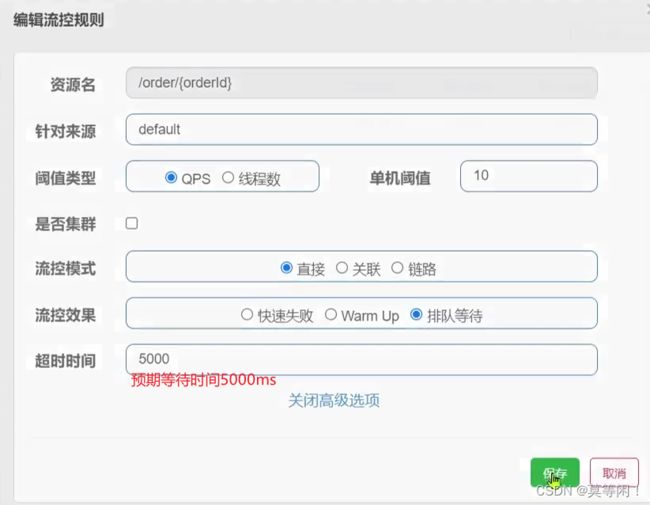
排队等待
排队等待是让所有请求 进入到一个队列中,按照阈值允许 的时间间隔依次执行。
后来的请求,必须等前面的执行完成,如果请求预期(timeOut)的等待时长 超出最大 等待时长,则会被拒绝。
QPS 等于5, 每个请求 200ms,表示(每个请求都需要200ms 时间,不到200ms,按200ms 来算),第二个请求执行时间是200ms 后; 当timecout =2000时,意味着每个请求预取等待2000ms,如果这个请求的等待时间超过2000ms,会被拒绝。


好处:稳定的qps 输出,流量整形。
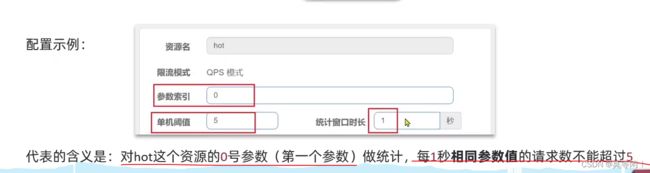
6.3 热点参数限流
注意事项:热点参数限流对默认的SpringMVC资源无效,需要利用@SentinelResource注解标记资源
根据参数值限流
案例
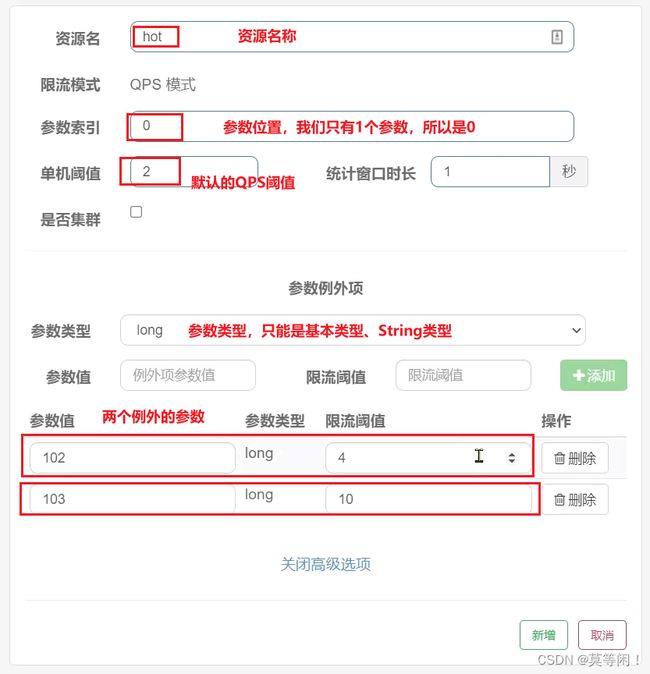
案例需求:给/order/{orderId}这个资源添加热点参数限流,规则如下:
•默认的热点参数规则是每1秒请求量不超过2
•给102这个参数设置例外:每1秒请求量不超过4
•给103这个参数设置例外:每1秒请求量不超过10
6.4 线程隔离和降级熔断
sentinel 支持雪崩的解决方案
- 线程隔离(舱壁模式)
- 降级熔断
线程隔离
方式1 线程池隔离
方式2 信号量隔离
| 信号量 | 线程池隔离 | |
|---|---|---|
| 优点 | 轻量级,不需要开启独立线程 | 支持主动超时,独立的线程 进行 异步调用 |
| 缺点 | 不支持异步调用 | 1. 线程开销大 |
| 场景 | 高扇出 网关() |
低扇出 ,扇出越多,需要的线程越多 |
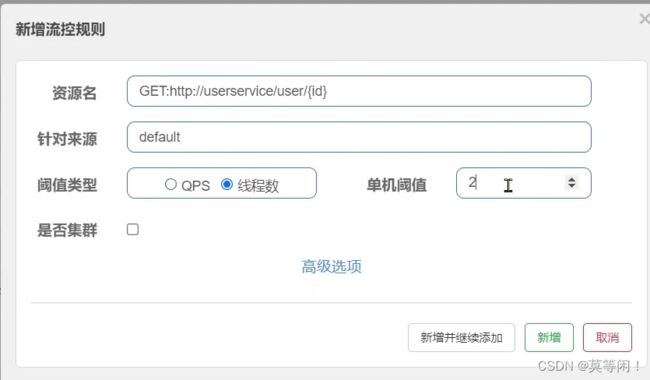
:给 order-service服务中的UserClient的查询用户接口设置流控规则,线程数不能超过 2。然后利用jemeter测试。
熔断降级
状态机
策略 慢调用、异常比例、异常数
慢调用 rt :
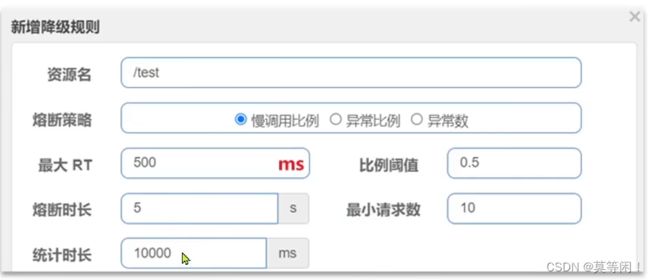
解读:·RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,并且慢调用比例不低于0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
异常比例 或者 异常数 :
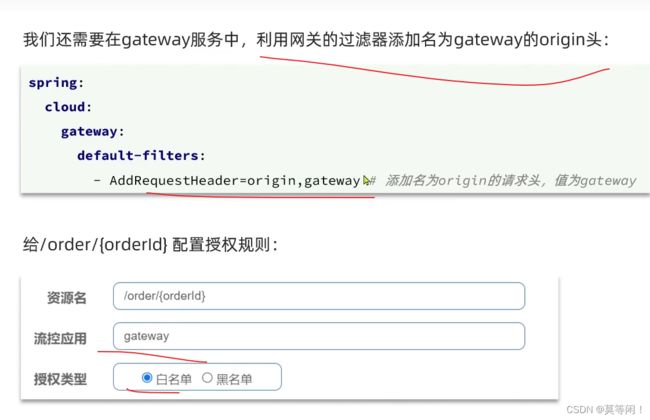
6.5 授权规则
授权规则对调用者做控制,有白名单、黑名单两种。
sentinel 通过RequestOriginParser 这个接口的parseOrigin来获取请求来源。
自定义异常
flowexception 限流异常
paramFlowException 热点参数异常
degradeException 降级异常
AuthorityException 授权异常
RequestOriginParser接口 判断请求来源名称,也就是黑白名单。
BlockExceptionHandler 自定义异常,不同类型异常。
6.6 规则持久话
默认模式 内存
pull 保存本地文件或者数据库,定时去读取。
push 把规则保存到 配置中心,微服务监听 变更,进行更新。
7. 分布式事务
cap 定理
一致性:操作成功,所有节点在同一时间的 数据必须完全一致。
强一致性:多个副本之间的数据必须保证一致性。时时刻刻都一致。
弱一致性:允许存在部分数据不一致,称为弱一致性。
最终一致性: 允许存在中间状态,经过一段时间后,数据保证最终一致性。
可用性:用户在访问集群中的任意节点, 总能在有限的时间内返回正常结果
有限时间: 对于操作请求,能在指定的时间内返回处理结果。
返回正常结果 : 正常结果 能够反应请求的处理结果,即成功或者失败。而不是返回会一个oom error
分区: 因为网络故障等原因,导致与分布式系统其他节点失去连接,形成独立分区。
容错: 在集群出现分区时,整个系统也要持续对外提供服务。
es 集群是cp 还是ap
cp。
故障节点从集群中剔除。数据分散到正常节点上。
base 理论
BASE理论的核⼼思想是:即使⽆法做到强⼀致性,但每个应⽤都可以根据⾃身业务
特点,采⽤适当的⽅式来使系统达到最终⼀致性。
基本可用 :在分布式系统出现故障时,允许损失部分服务的可用性,保证核心服务的可用性。
软状态 : 在一段时间内,允许出现中间状态,比如临时的不一致性,不会影响系统的可用性。
最终一致性 : 强调 系统中所有的数据副本,在经过一段时间同步后,达到最终一致性的一个状态。
seata模型
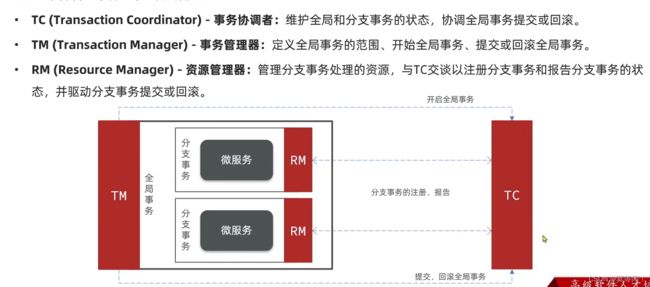
1.
seata xa 模式
- tm 事务管理器,开启全局事务,并注册到tc 事务协调者上。
- 调用每一个分支事务,被rm拦截,做一个分支事务的注册 注册到tc 上。
- 执行业务sql,执行完不提交。
报告事务状态 到tc
一阶段结束
二阶段:
tm结束,tc 检查 ·判断各个分支事务的状态,进行提交和回滚。
优点:
4. 事务强一致性。
5. 常用数据库都支持,实现简单。
缺点:
- 因为i一阶段需要锁定 数据库资源,等待二阶段结束才释放,性能较差。
- 依赖关系型数据库事务
seata at 模式
at 模式
一阶段:业务数据和回滚日志记录在同一个本地事务中 提交, 释放本地锁和资源
二阶段
- 提交异步化,非常快速的完成。
- 回滚,通过一阶段的回滚日志进行反向补偿。
优点:
在一阶段就提交了事务,释放锁,性能好。
利用全局锁实现业务的隔离性。
代码倾入低。
缺点:
两阶段属于软状态,属于最终一致性。
框架的快照功能会影响性能,。
xa 模式 和at 模式区别
at 模式第一阶段的流程来看,分支的 本地事务在第一阶段提交完成 之后,就会释放掉 本地事务 锁定的本地记录。这是at 和xa 最大的不同点, 在xa 模式中,被锁定的记录知道第二阶段结束才会 别释放。 因此 at 模式减少了锁记录的时间,提高了分布式事务的处理效率。
at 模式之所以能第一阶段 完成 就释放被锁定的记录,是因为seata 在每个服务 的 数据库中都维护了 一张undolog 表,记录了对 操作了 的逆向操作。 当第二阶段发生异常时,只需要通过undolog 表进行全局回滚即可
at 模式 脏写问题 隔离性
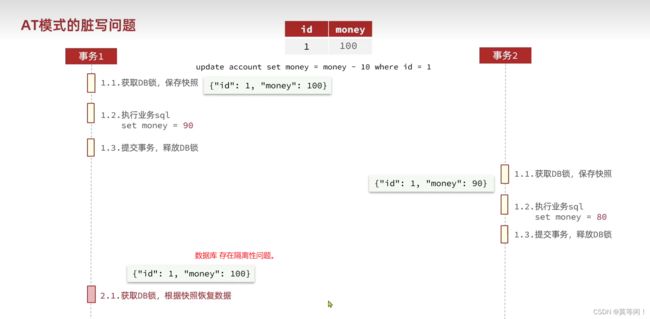
tc 事务协调者 在一阶段 和二阶段 加入 全局锁, 解决隔离性的问题。获取全局锁 重试 30次,每次10ms

针对非seata 管理事务
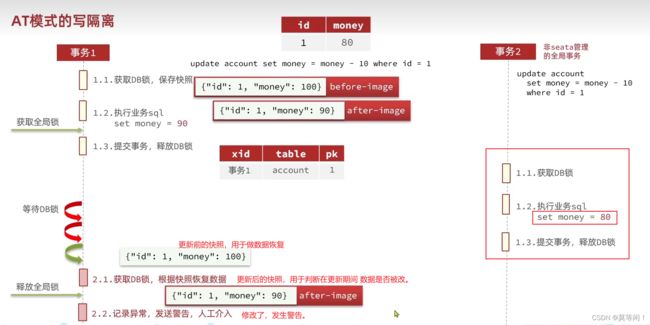
seata tcc 模式
- try
资源的监测 和预留 - confirm
完成资源操作任务。 要求 try 成功,confirm一定成功。 - cancel
预留资源的释放,可以理解为 try 的反向操作。
- tm 开启并注册全局事务 到tc 上。
- 通知每一个分支事务去执行
- 分支事务被rm 进行拦截,rm 注册分支事务到tc 上,再进行执行
- 执行 try 预留资源,报告状态 到tc。
二阶段:
tc 监测各个分支事务的状态。判断各个分支资源是否够。
进行 confirm 或者 cancel
优点:
- 一阶段完成 直接提交事务,是否数据库资源,性能好。
- 相比at 模式,无需生成数据库快照 记录到undolog 日志中,
无需使用全局锁 - 不依赖于 数据库的事务。
缺点: - try confirm cancel 都需要人工编写。麻烦
- 软状态,最终一致。
- 需要考虑confirm cancel 失败重试情况,
保证幂等性。
空回滚:rm 1 可以回滚,rm2 没有try 卡住了,回滚不了。 所以需要rm2 进行空回滚。
try 还没执行,cancel 已经执行。需要判断。
因此在回滚前 判断 是否已经有try 了,try 没执行, 设置 记录状态 为 cancel 状态。
幂等控制: 判断是否已经是cancel 。 已经cancel 直接返回。
业务悬挂: 已经回滚了,但是之前阻塞的 rm2 try 不阻塞了。 需要再try 之前判断 是否已经回滚了。
已经空回滚了,才执行 try,那不行。 判断冻结表 是否有冻结 记录 。有数据 那么直接return。

seata saga 模式
saga 是长事务解决方案。
一阶段: 直接提交本地事务。
二阶段:成功什么都不做,失败通过补偿逻辑业务来回滚。
没有保证隔离性。
状态机的方式进行数据的补偿操作。 用于第三方服务调用。
支付宝支付接口–>出库失败—>调用支付宝退款接口。
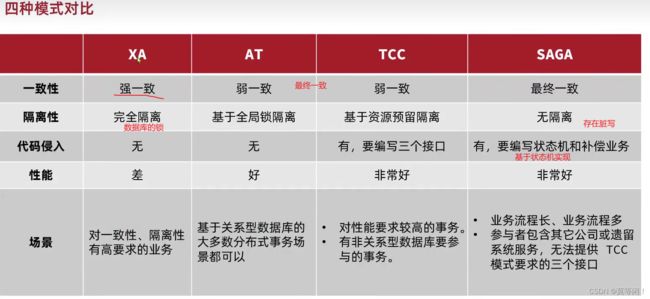
四种对比
8 xxl job
- 解决集群任务重复执行。
- corn 定义灵活
- 定时失败 重试 统计
- 任务量大,分片执行
任务管理 新增任务
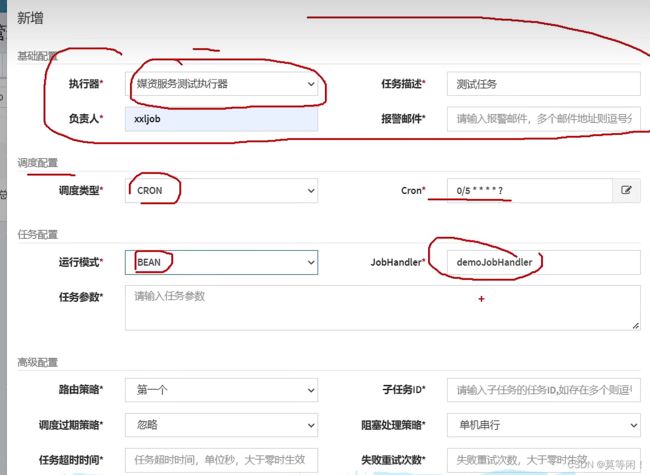
8.1 路由策略
集群环境下:
高级配置:
执行器在集群部署下调度中心有哪些调度策略呢?
第一个
最后一个
轮询
一致性 hash
故障转移
分片广播 都发送
过期策略:
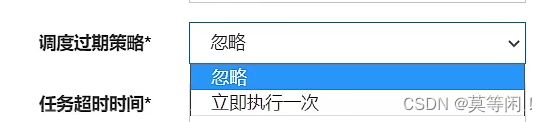
调度中心 该去调度,发生一些原因 没有调度。过期了。
如果过期了,是马上跑一次,还是忽略了。
阻塞策略:
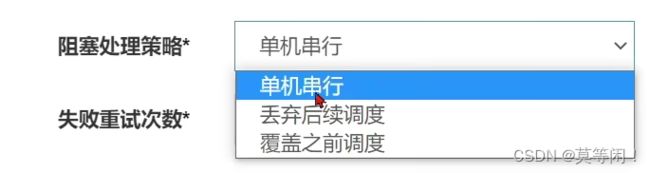
之前任务 还在执行,但是过了时间间隔,下一次再来调度,当前任务还在执行。
选择的策略。
单机串行: 排队,当前执行完了,再执行。
丢弃后续调度: 把下一个需要调度的任务抛弃
覆盖之前调度: 把当前任务终止,下一个任务开始执行。
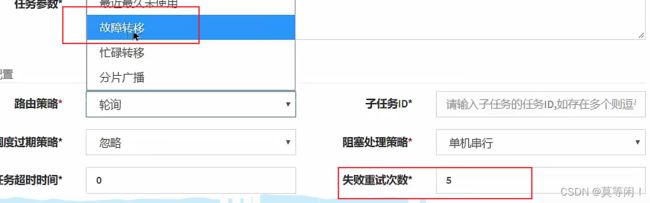
8.2 任务失败怎么办
- 设置路由策略为故障转移
- 设置失败重试次数
- 查看日志和邮件。
故障转移+失败重试次数,查看日志分析
8.3 如果有大数据量的任务同时都要执行,怎么解决
分片广播
index 分片号
total: 总分片数 ,集群总机器数量
