【测试工具】jmeter组件大全及如何使用详解
文章目录
- 前言
- 一、Jmeter是什么?可以做什么?
- 二、jmeter入门到进阶
-
- 1.基础组件
-
-
- 线程组
- 逻辑控制器
- HTTP请求
- http信息头管理器
- 响应断言
- BeanShell断言
- HTTP Cookie管理器
- 查看结果树
- 聚合报告
- 用户自定义变量
- Debug Sampler
- 后置处理器
-
-
- json提取器
- 正则表达式提取器
- BeanShell
-
- Test Action
- CSV数据文件设置
- 随机变量
- 函数
- jp@gc - Stepping Thread Group
- 最后说一下变量引用方式跟命令行执行脚本的格式:
-
前言
对于一个测试工程师来说,掌握一个测试工具是非常有必要的,下边将介绍 Jmeter 各种组件基础使用
一、Jmeter是什么?可以做什么?
JMeter是一个开源的自动化性能测试工具。在我的测试日常工作中会用Jmeter来干嘛呢?
- 单接口的接口测试
- 数据生成(半自动化)
- 接口自动化测试(jmeter+ant+jenkins)
- 性能测试
二、jmeter入门到进阶
1.基础组件
线程组
JMeter中的线程组(Thread Group)是其测试计划的基础组成部分之一,也是使用JMeter进行性能测试时的关键组件。线程组是一组线程或用户,模拟Web应用程序的多用户访问以测试负载情况。
1、线程数:指的是模拟访问Web应用程序的线程数;在做接口功能测试、自动化测试时,只配一个线程就可以,在执行压测时,根据目标性能进行配置
2、Ramp-Up Time:多长时间内启用所配置的线程数,主要在压测中用,默认是1s就可以
3、循环次数:每个线程执行多少次,主要在压测中使用,批量造数也会用到
4、持续时间:每个线程执行多长时间,压测中使用
逻辑控制器
1、简单控制器:作用相当于目录
2、if控制器:符合条件则执行该目录下的接口脚本,不符合条件则跳过
3、循环控制器:类似与线程的循环次数
4、模块控制器:引用其他已存在控制器
5、forEach控制器:类似java的foreach循环,但是可以控制索引的起始位置
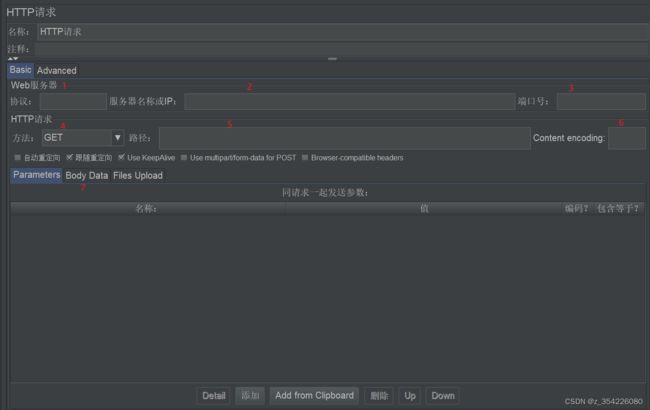
HTTP请求
1:协议:http或https
2:服务器名称或IP:域名 或 IP
3:端口:如果用的是IP地址,需要填写端口
4:请求方法:一般是get或post,其他很少用,并且调用方式类似
5:路径:接口URI,接口地址
6:编码方式:可以为空,如果请求中有中文,需要填写utf-8,否则会乱码
7:请求参数:Parameters(参数直接在请求路径上),BodyData(主要是post请求,json格式请求体),Files Upload(上传文件)
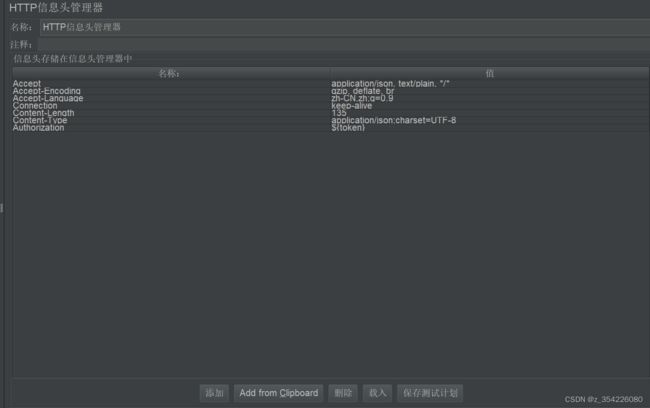
http信息头管理器
管理请求头信息,可以放在单个请求下,也可以作为全部接口的公共请求头
响应断言
根据需要,可以对接口请求的各种信息进行断言,这里就不详细解释了,之后有时间可以在写一下,最简单的就是判断一个能标识接口请求成功的字段,比如 “success”:true ,就代表接口请求成功了

BeanShell断言
如果上边的断言不能满足你的需求,可以使用beanshell自己去写一个断言逻辑,你说啥是beanshell??不要急,下边会说的
HTTP Cookie管理器
发起一个HTTP请求,并且响应包含 cookie,则 cookie 管理器会自动存储该 cookie,并将其用于后面对该网站的所有请求,也就是说,如果你们公司的网站是使用cookie的,你可以在线程添加一个cookie管理器,你只需要维护好一个登录接口(登录接口是请求的时候不需要cookie,响应值包含cookie),后边所有的接口就不需要考虑cookie的问题啦

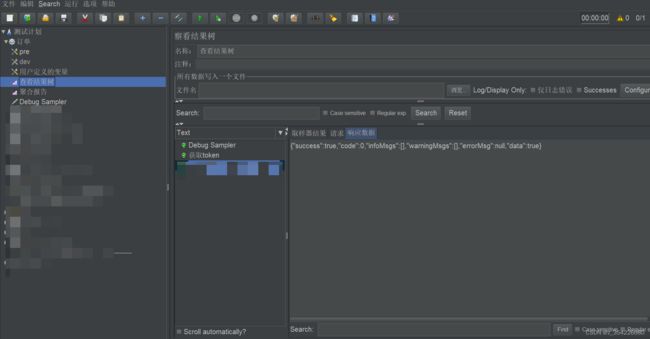
查看结果树
查看接口调用的结果喽
聚合报告
一般在压测的时候用,可以查看一些压测的指标,比如平均响应时间、错误率、吞吐量啥的

用户自定义变量
定义一些公共的变量,我们做自动化都讲究参数化,这是第一步啦

Debug Sampler
调试器,配合参数化,可以查看你自己定义变量在运行中的值

后置处理器
参数化最重要的东西啦,这里只说三个比较常用的,其他的小伙伴们可以自己去研究下啦
json提取器
最最最最常用的!提取方式为$.success;他的值就是 true 了
{“success”:true,“code”:0,“infoMsgs”:[],“warningMsgs”:[],“errorMsg”:null,“data”:true}

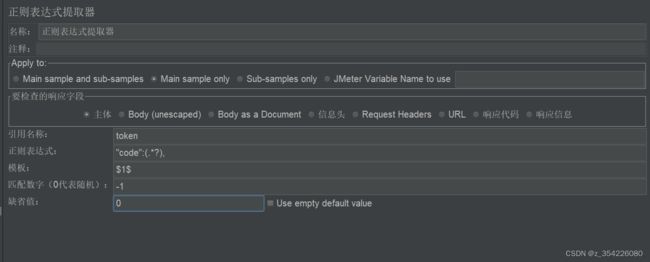
正则表达式提取器
相比与json提取器更加灵活一点,至于正则表达式这里就先不说了,之后可以再写一篇专门介绍正则表达式跟jmeter配合使用(老搁着画大饼)
BeanShell
哈哈哈,如果你能用到这个玩意,说明你对jmeter的使用开始有点小深入啦,少说废话!!对了,你需要会一点点java哦,不然可整不了,来,看下chatgpt给的解释(如果想部署一个基于开源库的chatgpt网站,可以联系我哦)

咱这里只说他获取接口响应参数来进行参数化的操作:
import org.json.*;
import java.util.*;
String response_data = prev.getResponseDataAsString(); // 获取返回参数,类型是字符串
JSONObject data_obj = new JSONObject(response_data); //将字符串转换为json对象
String diaryList_str = data_obj.get("content").get("Tree").get(0).get("nodeTree").toString(); //然后就可以去获取里边某一个字段的值啦
JSONArray diaryList_array = new JSONArray(diaryList_str);//字符串转换为json数组
vars.put("v_id","123")//jmeter自带对象跟方法,将 123 赋值给 v_id
vars.get("v_id")//jmeter自带对象跟方法,获取v_id的值
log.info("打印日志")//sl4j打印日志的方法哦
大家看代码+备注应该就看懂了吧,当然还有好多用法,比如读取文件啥的,就是用java写其实,就不多说了
Test Action
测试组件,加延时或者断点用:这是停了300s哦,单位是毫秒

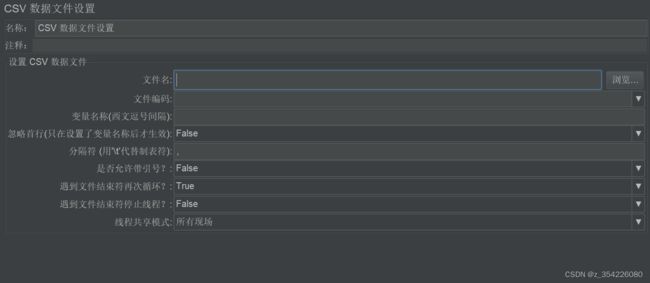
CSV数据文件设置
读取csv文件的,主要是放压测数据
文件名:填文件路径
文件编码:一般是utf-8,默认就是
变量名称:跟你csv文件的列对应起来,一列是一个变量,在脚本就可以用变量来引用csv文件中的数据啦
其他的基本都用默认就行
随机变量
在自动化过程经常会用到一些随机数啊啥的,可以用这个来生成,哦,包括计数器,是另外一个组件,就不说了很简单,有需要的自己去用一下就会了
这个就是一个生成138开头的随机的手机号,随机种子为空就行啦,好像为空是用的Random构造器

函数
函数我只用过生成时间戳跟随机数的,这里只说时间戳的,其他的大家自己去了解吧,以后可能用到在更新
P1D是偏移量,就是明天,P-1D就是昨天,P7D就是七天之后,其他的大家应该都能看懂的哈

jp@gc - Stepping Thread Group
这个吧这里简单提一下,之后在压测模块说,这个线程组就是压测的时候用,可以模拟更加真实的场景;
下边的图是,线程随时间的变化增加
This group will start:最大线程数
First,wait for:开始等待时间
Ten start:等待之后启动多少个线程
Next,add:{10} threads every {30} seconds :每30秒启动10个 线程
using ramp-up:这 10 个线程在几秒内启动完毕
Then hold load for :达到最大线程数后执行多少秒
Finally stop :{5} threads every {1} seconds:每秒停掉5个线程
根据这些参数的定义,对应下边的线状图,大家应该就差不多能理解了吧,怎么用咱之后再说哈

最后说一下变量引用方式跟命令行执行脚本的格式:
● 变量引用:${变量名}
● 命令行执行(压测)
jmeter -n -t <测试计划的文件路径> -l <测试结果文件的保存路径> -e -o <测试结果的web报告保存路径>
第一次写技术分享,有很多问题还请各位看官多多包涵,有啥测试相关问题(测试的发展啦,测试工具的使用啦啥的),欢迎在评论区提问,我每天晚上都会去看哒
最最后,希望各位测试工作者能一起朝着测试架构师发展哦!!!