机器学习实战——决策树算法
点击查看:数据集+代码
决策树
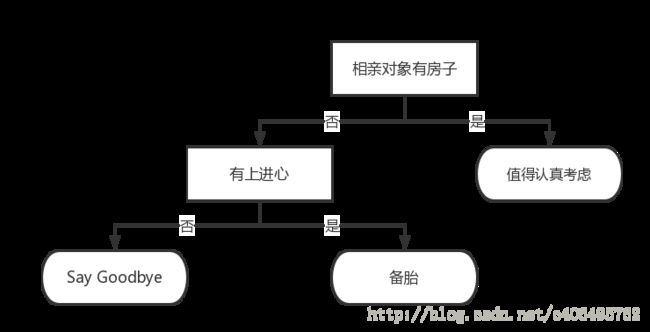
该流程图就是一个决策树,长方形代表判断模块 (decision block),椭圆形代表终止模块(terminating block),表示已经得出结论,可以终止运行。 从判断模块引出的左右箭头称作分支(branch),它可以到达另一个判断模块或者终止模块。
决策树ID3算法
上一篇的k-近邻算法可以完成很多分类任务,但是它最大的缺点就是无法给出数据的内在含义,决策树的主要优势就在于数据形式非常容易理解,决策树的一个重要任务是为了数据中所蕴含的知识信息,如不同特征之间的关联,因此决策树可以使用不熟悉的数据集合,并从中提取出一 系列规则,在这些机器根据数据集创建规则时,就是机器学习的过程。
步骤:
分析数据:可以使用任何方法,决策树构造完成之后,我们可以检查决策树图形是否符合预期。
训练算法:这个过程也就是构造决策树,同样也可以说是决策树学习,就是构造一个决策树的数据结构。
测试算法:使用经验树计算错误率。当错误率达到了可接收范围,这个决策树就可以投放使用了。
原文链接:https://blog.csdn.net/c406495762/article/details/75663451
决策树算法的训练,实际上就是构建决策树的过程。
ID3算法:利用不同特征值对最终决策产生的信息增益不同,选择当前判断模块按照的分类标准,信息增益越大说明该特征值对决策的影响越大,将最大的作为第一次判断的特征,在之后,去除掉第一次判断的特征,进行递归。
信息熵与信息增益:
对于随机变量xi,信息定义为:
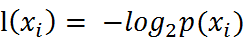
信息熵,也可以说是信息的期望值,表征信息的不确定性:
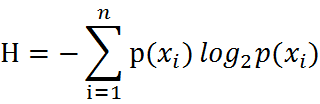
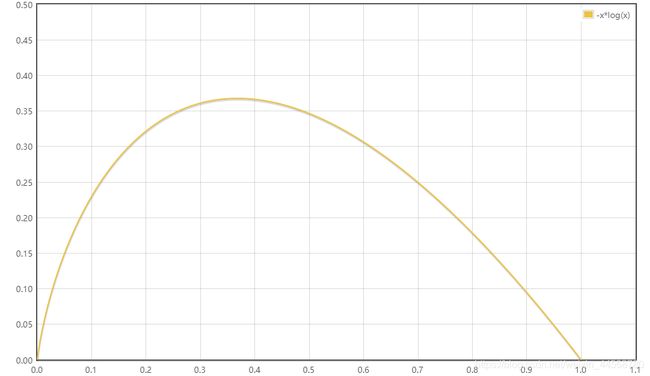
此处附上函数图像帮助理解:
条件熵:
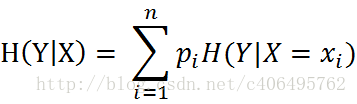
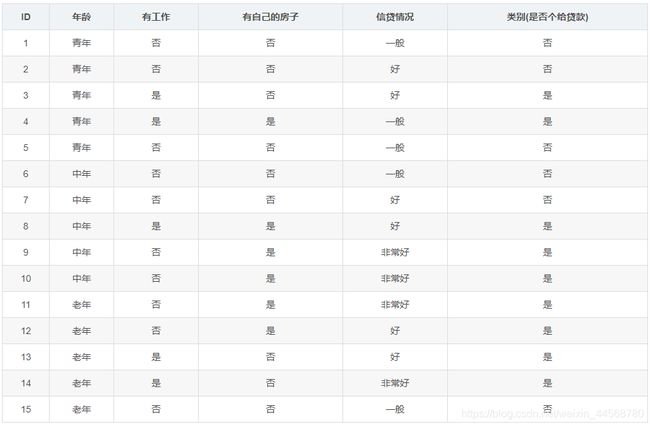
例如我想计算有无房子对类别的条件熵
先把有无房子的类别分为有和无
再把有房子与无房子的训练数据看成两类,分别按照信息熵的概念,计算两类数据各自的信息熵。
最后,把两类各自的信息熵,分别乘以有房和无房的概率。把乘积相加,得到条件熵。
信息增益:

实例代码:是否放贷,可见上图数据
sorted方法与operator的联合使用:
operator.itemgetter()用于指定排序按照哪个数据进行
>>> import operator
>>> a=[[1,2],[2,1]]
>>> sorted(a)
[[1, 2], [2, 1]]
>>> sorted(a,key=operator.itemgetter(1))
[[2, 1], [1, 2]]
>>> sorted(a,key=operator.itemgetter(2))
本例原来代码中采用matplotlib进行决策树可视化,由于SKlearn有更简单的操作,此处删除不再赘述,pickle模块也删除不再赘述。
# -*- coding: UTF-8 -*-
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
from math import log
import operator
import pickle
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-24
"""
def calcShannonEnt(dataSet):
numEntires = len(dataSet) #返回数据集的行数
labelCounts = {} #保存每个标签(Label)出现次数的字典
for featVec in dataSet: #对每组特征向量进行统计
currentLabel = featVec[-1] #提取标签(Label)信息
if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
for key in labelCounts: #计算香农熵
prob = float(labelCounts[key]) / numEntires #选择该标签(Label)的概率
shannonEnt -= prob * log(prob, 2) #利用公式计算
return shannonEnt #返回经验熵(香农熵)
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 特征标签
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-20
"""
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] #特征标签
return dataSet, labels #返回数据集和分类属性
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-24
"""
def splitDataSet(dataSet, axis, value):
retDataSet = [] #创建返回的数据集列表
for featVec in dataSet: #遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #去掉axis特征
reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集
retDataSet.append(reducedFeatVec)
return retDataSet #返回划分后的数据集
"""
函数说明:选择最优特征
Parameters:
dataSet - 数据集
Returns:
bestFeature - 信息增益最大的(最优)特征的索引值
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-20
"""
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数量
baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵
bestInfoGain = 0.0 #信息增益
bestFeature = -1 #最优特征的索引值
for i in range(numFeatures): #遍历所有特征
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) #创建set集合{},元素不可重复
newEntropy = 0.0 #经验条件熵
for value in uniqueVals: #计算信息增益
subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率
newEntropy += prob * calcShannonEnt(subDataSet) #根据公式计算经验条件熵
infoGain = baseEntropy - newEntropy #信息增益
# print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益
if (infoGain > bestInfoGain): #计算信息增益
bestInfoGain = infoGain #更新信息增益,找到最大的信息增益
bestFeature = i #记录信息增益最大的特征的索引值
return bestFeature #返回信息增益最大的特征的索引值
"""
函数说明:统计classList中出现此处最多的元素(类标签)
Parameters:
classList - 类标签列表
Returns:
sortedClassCount[0][0] - 出现此处最多的元素(类标签)
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-24
"""
def majorityCnt(classList):
classCount = {}
for vote in classList: #统计classList中每个元素出现的次数
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序
return sortedClassCount[0][0] #返回classList中出现次数最多的元素
"""
函数说明:创建决策树
Parameters:
dataSet - 训练数据集
labels - 分类属性标签
featLabels - 存储选择的最优特征标签
Returns:
myTree - 决策树
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-25
"""
def createTree(dataSet, labels, featLabels):
classList = [example[-1] for example in dataSet] #取分类标签(是否放贷:yes or no)
if classList.count(classList[0]) == len(classList): #如果类别完全相同则停止继续划分
return classList[0]
if len(dataSet[0]) == 1 or len(labels) == 0: #遍历完所有特征时返回出现次数最多的类标签
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat] #最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
del(labels[bestFeat]) #删除已经使用特征标签
featValues = [example[bestFeat] for example in dataSet] #得到训练集中所有最优特征的属性值
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征,创建决策树。
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels, featLabels)
return myTree
"""
函数说明:创建绘制面板
Parameters:
inTree - 决策树(字典)
Returns:
无
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-24
"""
def createPlot(inTree):
fig = plt.figure(1, facecolor='white') #创建fig
fig.clf() #清空fig
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴
plotTree.totalW = float(getNumLeafs(inTree)) #获取决策树叶结点数目
plotTree.totalD = float(getTreeDepth(inTree)) #获取决策树层数
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移
plotTree(inTree, (0.5,1.0), '') #绘制决策树
plt.show() #显示绘制结果
"""
函数说明:使用决策树分类
Parameters:
inputTree - 已经生成的决策树
featLabels - 存储选择的最优特征标签
testVec - 测试数据列表,顺序对应最优特征标签
Returns:
classLabel - 分类结果
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-25
"""
def classify(inputTree, featLabels, testVec):
firstStr = next(iter(inputTree)) #获取决策树结点
secondDict = inputTree[firstStr] #下一个字典
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else: classLabel = secondDict[key]
return classLabel
"""
函数说明:存储决策树
Parameters:
inputTree - 已经生成的决策树
filename - 决策树的存储文件名
Returns:
无
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-07-25
"""
if __name__ == '__main__':
dataSet, labels = createDataSet()
featLabels = []
myTree = createTree(dataSet, labels, featLabels)
testVec = [0,1] #测试数据
result = classify(myTree, featLabels, testVec)
if result == 'yes':
print('放贷')
if result == 'no':
print('不放贷')
注意:
python中我们用字典来表示决策树数据结构,如本例最后的字典为
然后利用该数据进行可视化,测试等操作
使用Sklearn构建决策树
决策树用于解决回归与分类问题。
点击查看:官方文档


criterion:默认为gini(CART),可修改为香农熵(entropy)(ID3算法)
splitter:特征点数据选择标准,取决于计算量,random会只使用部分点,为局部最优点
最大深度等:防止过拟合(训练数据分类较好,其他数据却很差):不要太深
类别权重:防止样本不平衡
实例:隐形眼镜
数据的格式化处理:
pandas数据处理后,把字符串转化为Dataframe对象,然后可以使用该对象作为参数进行编码
LabelEncoder:将字符串转换为增量值
OneHotEncoder:使用One-of-K算法将字符串转换为整数
# -*- coding: UTF-8 -*-
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import pydotplus
from sklearn.externals.six import StringIO
if __name__ == '__main__':
with open('lenses.txt', 'r') as fr: #加载文件
lenses = [inst.strip().split('\t') for inst in fr.readlines()] #处理文件
lenses_target = [] #提取每组数据的类别,保存在列表里
for each in lenses:
lenses_target.append(each[-1])
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] #特征标签
lenses_list = [] #保存lenses数据的临时列表
lenses_dict = {} #保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels: #提取信息,生成字典
for each in lenses:
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
lenses_list = []
# print(lenses_dict) #打印字典信息
lenses_pd = pd.DataFrame(lenses_dict) #生成pandas.DataFrame
print(lenses_pd) #打印pandas.DataFrame
le = LabelEncoder() #创建LabelEncoder()对象,用于序列化
for col in lenses_pd.columns: #为每一列序列化
lenses_pd[col] = le.fit_transform(lenses_pd[col])
print(lenses_pd)
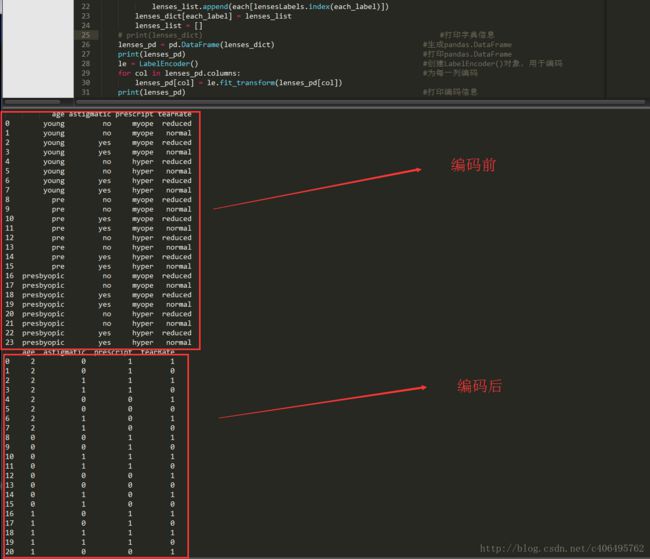
常用处理:
from sklearn import tree
clf = tree.DecisionTreeClassifier(max_depth = 4)
clf = clf.fit(lenses_pd.values.tolist(), lenses_target)
tree.export_graphviz()函数进行可视化,非常方便
# -*- coding: UTF-8 -*-
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.externals.six import StringIO
from sklearn import tree
import pandas as pd
import numpy as np
import pydotplus
if __name__ == '__main__':
with open('lenses.txt', 'r') as fr: #加载文件
lenses = [inst.strip().split('\t') for inst in fr.readlines()] #处理文件
lenses_target = [] #提取每组数据的类别,保存在列表里
for each in lenses:
lenses_target.append(each[-1])
# print(lenses_target)
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] #特征标签
lenses_list = [] #保存lenses数据的临时列表
lenses_dict = {} #保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels: #提取信息,生成字典
for each in lenses:
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
lenses_list = []
# print(lenses_dict) #打印字典信息
lenses_pd = pd.DataFrame(lenses_dict) #生成pandas.DataFrame
# print(lenses_pd) #打印pandas.DataFrame
le = LabelEncoder() #创建LabelEncoder()对象,用于序列化
for col in lenses_pd.columns: #序列化
lenses_pd[col] = le.fit_transform(lenses_pd[col])
# print(lenses_pd) #打印编码信息
clf = tree.DecisionTreeClassifier(max_depth = 4) #创建DecisionTreeClassifier()类
clf = clf.fit(lenses_pd.values.tolist(), lenses_target) #使用数据,构建决策树
dot_data = StringIO()
tree.export_graphviz(clf, out_file = dot_data, #绘制决策树
feature_names = lenses_pd.keys(),
class_names = clf.classes_,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf") #保存绘制好的决策树,以PDF的形式存储。
print(clf.predict([[1,1,1,0]])) #预测