机器学习之查准率、查全率与F1
文章目录
- 查准率(Precision):
- 查全率(Recall):
- F1分数(F1 Score):
- 实例
- P-R曲线
- F1度量
- python实现
查准率(Precision):
定义: 查准率是指在所有被分类为正类别的样本中,有多少比例的样本实际上是正类别的。它强调的是模型预测为正类别的样本中真正是正类别的比例。
应用场景: 当我们关心的是确保被模型预测为正类别的样本确实是正类别时,例如在医学诊断中,确保模型预测为患有某种疾病的患者确实患有该疾病。
查准率表示在所有被模型预测为正类别的样本中,有多少比例的样本实际上是正类别的。具体计算公式为:

查全率(Recall):
定义: 查全率是指在所有实际正类别的样本中,有多少比例的样本被模型成功地预测为了正类别。它强调的是模型能够捕捉到实际正类别样本的能力。
应用场景: 当我们关心的是确保所有真实正类别的样本都被模型找出来时,例如在安全检查中,确保所有危险品都被检测出来。
查全率表示在所有实际正类别的样本中,有多少比例的样本被模型成功地预测为了正类别。具体计算公式为:

F1分数(F1 Score):
定义: F1分数是查准率和查全率的调和平均数,它综合了查准率和查全率的信息,可以帮助我们在精度和召回率之间找到一个平衡点。
应用场景: 当我们需要综合考虑查准率和查全率时,避免查准率和查全率出现明显的不平衡时,例如在信息检索中,需要同时考虑搜索结果的准确性和完整性。
实例
这里写一个二分类的问题来展示什么是查准率与查全率。

为什么我们要关注全差率,和查准率呢?
挑出来的西瓜有多少西瓜是好瓜
挑出来的西瓜有多少是坏瓜
这个就要看自己关系什么了
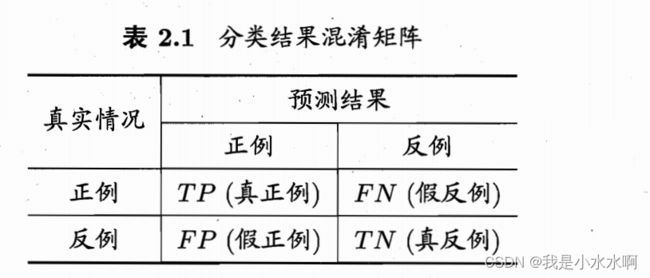
这里的表2.1 的混淆矩阵(代码实现不是二分类)可以用Python实现:
from sklearn.metrics import confusion_matrix
import numpy as np
# 示例的真实标签和预测标签
y_true = np.array([1, 0, 1, 2, 0, 1, 2, 3, 2])
y_pred = np.array([1, 0, 1, 2, 0, 2, 1, 3, 2])
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_true, y_pred)
# 输出混淆矩阵
print("Confusion Matrix:")
print(conf_matrix)
P-R曲线
关于全查率,和查准率的 P-R曲线
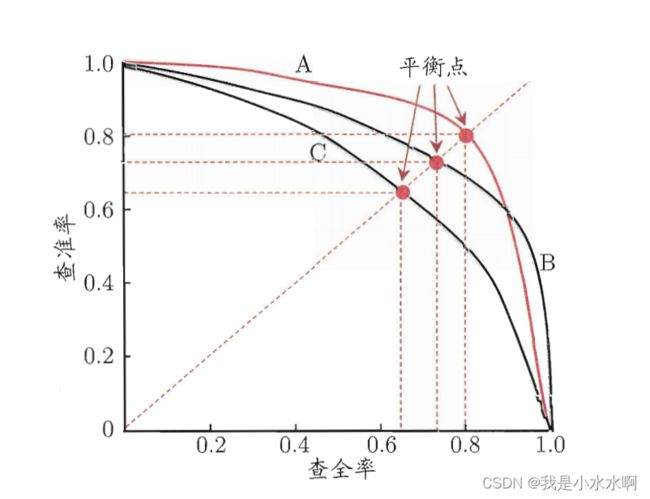
在图中 A曲线 包含C 曲线,所有一般来说A曲线优于C曲线,
在A曲线与B曲线当中,有交叉则需要看他们所围成的面积。但是这个面积通常不容易计算,所有找了平衡点(Break-Event Point)来评价 他是 全差率=查准率的点。
F1度量
但是平衡点还是过于简单所以有了F1度量。

P:查准率
R:查全率
TP:真正列
TN:真反列
注意看:上面的表2.1
注意: 在某些应用中 查全率和查准率的重视程度不一致。
比如说在:
- (1)商品推销当中,为了尽量打扰用户,更喜欢退出的是用户感兴趣的此时查准率比较重要。
- (2)在抓捕逃犯信息当中,希望尽可能减少漏掉逃犯则这个时候查全率比较重要。
为了更好的确定度量,表达出查全率\查准率的偏好我们将定义F为:



多次训练测试时取平均的F1(宏F1- mocro-F1)


python实现
P-R(Precision-Recall)曲线是一种用于可视化分类模型在不同阈值下查准率(Precision)和查全率(Recall)之间权衡关系的图形。以下是绘制P-R曲线的一般步骤:
-
计算不同阈值下的查准率和查全率: 使用不同的阈值将模型的预测概率转换为类别标签,然后计算每个阈值下的查准率和查全率。
-
绘制P-R曲线: 将计算得到的查准率和查全率值组成的点按照阈值的顺序绘制在二维坐标系上,横轴为查全率(Recall),纵轴为查准率(Precision)。
以下是一个Python示例代码,演示如何绘制P-R曲线,其中假设y_true为真实标签,y_scores为模型的预测概率。
= 这里也有阈值,就是thresholds ===
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
# 示例的真实标签和模型预测概率
y_true = [1, 1, 0, 1, 0, 1, 1, 0, 0, 1]
y_scores = [0.8, 0.7, 0.4, 0.6, 0.3, 0.9, 0.5, 0.2, 0.1, 0.75]
# 计算P-R曲线的查准率、查全率和阈值
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
# 绘制P-R曲线
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, marker='.')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('P-R Curve')
plt.grid(True)
plt.show()
在这个例子中,precision_recall_curve函数会返回在所有可能阈值下的查准率、查全率和相应的阈值。然后,通过plt.plot()函数绘制这些点,就得到了P-R曲线。曲线上的每个点对应于一个特定的阈值,展示了在该阈值下模型的查准率和查全率。通常,P-R曲线越靠近右上角,表示模型在不同阈值下的性能越好。