Easy-ES
快速入门
一,简介
Easy-Es(简称EE)是一款基于ElasticSearch(简称Es)官方提供的RestHighLevelClient打造的ORM开发框架,在 RestHighLevelClient 的基础上,只做增强不做改变,为简化开发、提高效率而生,您如果有用过Mybatis-Plus(简称MP),那么您基本可以零学习成本直接上手EE,EE是MP的Es平替版,在有些方面甚至比MP更简单,同时也融入了更多Es独有的功能,助力您快速实现各种场景的开发。
二,优势
- 全自动索引托管: 全球开源首创的索引托管模式,开发者无需关心索引的创建更新及数据迁移等繁琐步骤,索引全生命周期皆可托管给框架,由框架自动完成,过程零停机,用户无感知,彻底解放开发者
- 智能字段类型推断: 根据索引类型和当前查询类型上下文综合智能判断当前查询是否需要拼接.keyword后缀,减少小白误用的可能
- 屏蔽语言差异: 开发者只需要会MySQL语法即可使用Es,真正做到一通百通,无需学习枯燥易忘的Es语法,Es使用相对MySQL较低频,学了长期不用也会忘,没必要浪费这时间.开发就应该专注于业务,省下的时间去撸铁,去陪女朋友陪家人,不做资本家的韭菜
- 代码量极少: 与直接使用RestHighLevelClient相比,相同的查询平均可以节省3-5倍左右的代码量
- 零魔法值: 字段名称直接从实体中获取,无需输入字段名称字符串这种魔法值,提高代码可读性,杜绝因字段名称修改而代码漏改带来的Bug
- 零额外学习成本: 开发者只要会国内最受欢迎的Mybatis-Plus语法,即可无缝迁移至EE,EE采用和前者相同的语法,消除使用者额外学习成本,直接上手,爽
- 降低开发者门槛: Es通常需要中高级开发者才能驾驭,但通过接入EE,即便是只了解ES基础的初学者也可以轻松驾驭ES完成绝大多数需求的开发,可以提高人员利用率,降低企业成本
三,特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper,仅仅通过少量配置即可实现大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错段
- 支持主键自动生成:支持2 种主键策略,可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置分页插件:基于RestHighLevelClient 物理分页,开发者无需关心具体操作,且无需额外配置插件,写分页等同于普通 List 查询,且保持和PageHelper插件同样的分页返回字段,无需担心命名影响
- MySQL功能全覆盖:MySQL中支持的功能通过EE都可以轻松实现
- 支持ES高阶语法:支持高亮搜索,分词查询,权重查询,Geo地理位置查询,IP查询,聚合查询等高阶语法
- 良好的拓展性:底层仍使用RestHighLevelClient,可保持其拓展性,开发者在使用EE的同时,仍可使用RestHighLevelClient的功能
四,使用场景
1. 检索类服务
- 搜索文库
- 电商商品检索
- 海量系统日志检索
2. 问答类服务(本质上也是检索类)
- 在线智能客服
- 机器人
3. 地图类服务
- 打车app
- 外卖app
- 社区团购配送
- 陌生人社交
五,性能
EE在整个查询过程中做了什么事? 其核心事宜总结起来就2件:
-
把用户输入的MySQL语法(Mybatis-Plus语法)转换成RestHighLevel语法,然后调用RestHighLevelClient执行本次查询
-
把查询结果转换成用户想要的格式:如
List并返回.
EE除了查询会比直接使用RestHighLevelClient平均慢10-15毫秒,增删改API并无差异,而且随着查询数据量的增大,实体字段缓存生效后,查询差异会进一步降低,几乎可以忽略不计. 牺牲10毫秒,对用户而言是无感知的,但对开发而言,可以节省大量代码和时间,我认为这是值得的,基本上没有哪款ORM框架是不会损耗性能的
六,安全
我们已接入OSCS墨菲安全扫描,ee源码中未被扫描出任何风险项(超越100%的项目),确保人畜无害! 大家可放心使用,当然如果您仍不放心,我们推荐您在使用前下载ee源码亲自阅读一番,我们是100%开源,是否有风险您一看便知. 另外本框架所有三方依赖有elastic search官方提供的es操作套件和RestHighLevelClient,阿里的fastJson,Spring官方的SpringbootAutoConfig,Apache的commons-codec以及Lombok,无二方依赖,空口黄牙,口说无凭,大家可以点开maven中央仓库,亲自查看一番:maven中央仓库 (opens new window)以上套件即使不使用EE,你在实际开发中也会用到,且都是官方出品,所以您无需担心. 那么EE有没有可能有安全问题?毕竟是个人开发者写的,没有前面提到的框架那么强的背书.首先我认为任何框架都有可能有安全风险,即便是有强大的公司背书,比如前阵子阿里FastJson的安全漏洞. 对于EE,我个人认为目前不会有特别严重的安全问题,EE框架的核心原理上面的图中已经列出来了,EE的核心原理只是转换,相当于一个翻译或者中介,并无其它涉及安全类的操作,加上EE框架本身十分轻量,没有引入任何多余的类库,所有工具类都是自己封装,封装的时候也参照了apache工具类,所以有理由认为使用EE是相对安全的,除非下游的官方依赖本身有安全漏洞. 另外关于FastJson其实一直争议不断,其性能确实是目前市面上当之无愧的一哥,确实够快,安全方面的话之前因为AutoType问题和黑客上演的魔高一尺道高一丈故事,让很多人误以为它漏洞百出,其实它没有那么不堪,之前的漏洞频繁本质上都是一个问题.阿里内部尚且那么多项目在使用FastJson,只要其社区活跃,并有积极处理,都是可以考虑使用的,毕竟没有哪个框架可以保证完全没有漏洞,只不过还没被发现罢了.当前依赖的fastjson为其最新版本,墨菲扫描无任何漏洞. 我们单元测试用例综合覆盖率超95%,已上线的所有功能均有测试用例覆盖,且经过生产环境和开源社区大量用户使用验证,敬请放心使用.
七,拓展性
EE底层用的就是Es官方提供的RestHighLevelClient,我们只是对RestHighLevelClient做了增强,并没有改变减少或是削弱它原有的功能,所以您无需担心拓展性. 任何框架的使用都会降低系统的灵活性,因为框架是死的,使用了以后不可避免的会碰到一些场景框架无法满足,需要定制化开发,或是短期内您不了解框架本身,不敢贸然使用,不然以后遇到问题怎么办? 为了解决上述问题,我特地在框架中留了混合查询和原生查询 目前EE提供的所有API可以覆盖实际开发中99%的需求,当极小概率下1%的需求无法覆盖时,您可以通过使用混合查询,也就是能支持的语句用EE生成,不能支持的语句就直接用RestHighLevelClient的语法,然后通过原生接口去完成查询,既简单有省事.当然如果您不喜欢这种"油电混动"的方式,您也可以直接用原生查询接口去完成查询,和直接使用RestHighLevelClient一样. 当然如果您实在不想用EE提供的任何方法,EE仍可以作为一个自动配置版的RestHighLevelClient使用,直接在需要的地方注入RestHighLevelClient进行使用即可,EE已经帮您把RestHighLevelClient按照您在配置文件中指定配置,自动装配成SpringBean了,所以在任何情况下,您都可以很自信很从容,就像直接使用官方的RestHighLevelClient一样,根本不需要担心有一天出问题了怎么办,大不了不用EE,只把它当成一个引入依赖和自动配置的工具.而且这种可能性也非常的低,我们还有专门的答疑群无偿在线给予您支持,对您的合理需求也会第一时间响应并安排落地. EE对所有项目透明,代码零侵入,引入不影响您当前项目的所有功能,引入后您依旧可以使用RestHighLevelClient全部功能,并且可以享受到EE为您提供的各种开箱即用的功能和解放双手的智能化套件
八,接入优势
- 简单易用高效不用我多说了吧,MyBatis-Plus用户懂的都懂! 大把的时间节省出来,做...爱做的事情,真香!
- 使用门槛降低,就算是刚不懂Es的小白,也可以用EE开发各种功能
- 大幅减少代码量,提升代码可读性,降低重复代码量,提升代码质量
- 专业答疑团队,无忧售后
- 永久免费
九,避坑指南
1,ES版本及SpringBoot版本
由于我们底层用了ES官方的RestHighLevelClient,所以对ES版本有要求,要求ES和RestHighLevelClient JAR依赖版本必须为7.14.0,至于es客户端,实际 测下来7.X任意版本都可以很好的兼容.
值得注意的是,由于SpringData-ElasticSearch的存在,Springboot它内置了和ES及RestHighLevelClient依赖版本,这导致了不同版本的Springboot实际引入的ES及RestHighLevelClient 版本不同,而ES官方的这两个依赖在不同版本间的兼容性非常差,进一步导致很多用户无法正常使用Easy-Es,抱怨我们框架有缺陷,实际上这只是一个依赖冲突的问题. 我们在项目启动时做了依赖校验,如果您的项目在启动时可以在控制台看到打印出级别为Error且内容为"Easy-Es supported elasticsearch and restHighLevelClient jar version is:7.14.0 ,Please resolve the dependency conflict!" 的日志时,则说明有依赖冲突待您解决. 解决方案其实很简单,可以像下面一样配置maven的exclude移除Springboot或Easy-Es已经声明的ES及RestHighLevelClient依赖,然后重新引入,引入时指定版本号为7.14.0即可解决.
org.springframework.boot
spring-boot-starter-web
org.elasticsearch.client
elasticsearch-rest-high-level-client
org.elasticsearch.client
elasticsearch-rest-client
org.elasticsearch
elasticsearch
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.14.0
org.elasticsearch.client
elasticsearch-rest-client
7.14.0
org.elasticsearch
elasticsearch
7.14.0
也可以简单粗暴的把springboot版本调整到2.5.5,其它都不需要调整,也可以勉强正常使用.
2,ES索引的keyword类型和text类型以及termQuery,match,match_phrase区别

ES中的keyword类型,和MySQL中的字段基本上差不多,当我们需要对查询字段进行精确匹配,左模糊,右模糊,全模糊,排序聚合等操作时,需要该字段的索引类型为keyword类型,否则你会发现查询没有查出想要的结果,甚至报错. 比如EE中常用的API eq(),like(),distinct()等都需要字段类型为keyword类型.
当我们需要对字段进行分词查询时,需要该字段的类型为text类型,并且指定分词器(不指定就用ES默认分词器,效果通常不理想). 比如EE中常用的API match()等都需要字段类型为text类型. 当使用match查询时未查询到预期结果时,可以先检查索引类型,然后再检查分词器,因为如果一个词没被分词器分出来,那结果也是查询不出来的.
当同一个字段,我们既需要把它当keyword类型使用,又需要把它当text类型使用时,此时我们的索引类型为keyword_text类型,EE中不指定字段类型时,则默认该字段类型为此keyword+text双类型,双类型如下图所示,值得注意的是,当我们把该字段当做keyword类型查询时,ES要求传入的字段名称为"字段名.keyword",当把该字段当text类型查询时,直接使用原字段名即可. 值得庆幸的是,自2.0版本起,框架内部对此作了处理,默认会根据当前字段的索引类型和查询的类型来决定实际到底使用哪种类型,.keyword后缀框架会自动拼接,进一步减少了小白踩此坑的可能,如果您不希望框架自动根据上下文拼接.keyword后缀,您也可以通过配置文件关闭此项智能化功能, easy-es.global-config.db-config.smartAddKeywordSuffix=false

3,字段id
由于框架很多功能都是借助id实现的,比如selectById,update,deleteById...,而且ES中也必须有一列作为数据id,因此我们强制要求用户封装的实体类中包含字段id列,否则框架不少功能无法正常使用.
public class Document {
/**
* es中的唯一id,如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize或直接在全局配置文件中指定,如此id便支持任意数据类型)
*/
@TableId(type = IdType.CUSTOMIZE)
private String id;
}
如果不添加@TableId注解或者添加了注解但未指定type,则id默认为es自动生成的id.
在调用insert方法时,如果该id数据在es中不存在,则新增该数据,如果已有该id数据,则即便你调用的是insert方法,实际上的效果也是更新该id对应的数据,这点需要区别于MP和MySQL
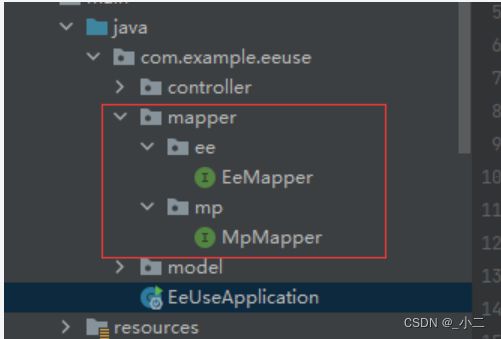
4,项目中同时使用Mybatis-Plus和Easy-Es
在此场景下,您需要将MP的mapper和EE的mapper分别放在不同的目录下,并在配置扫描路径时各自配各自的扫描路径,如此便可共存使用了,否则两者在SpringBoot启动时都去扫描同一路径,并尝试注册为自己的bean,由于底层实现依赖的类完全不一样,所以会导致其中之一注册失败,整个项目无法正常启动.可参考下图:
快速开始
一,环境准备
- 拥有 Java 开发环境以及相应 IDE
- 熟悉MySQL
- 熟悉 Spring Boot (推荐版本2.5.x +)
- 熟悉 Maven
- 了解Es基本概念或已读避坑指南 (强烈推荐)
- 已安装Es 推荐7.x版本(没有安装的可自行百度教程,建议再装一个es-head插件,便于可视化验证),低版本可能存在API不兼容或其它未知情况,因为底层采用RestHighLevelClient而非RestLowLevelClient,本Demo采用Es版本为7.14.0
特别注意
由于springboot内置关联了es版本,不同的springboot版本会导致实际项目中引入的es依赖版本过低或过高, 而es不同版本兼容性比较差,很多用户踩到一些因依赖冲突而导致兼容问题的坑,在此特地提醒用户,如果您项目实际依赖的es版本不为 7.14.0版本,我们强烈建议您显示指定es依赖jar包版本为7.14.0,与我们底层使用的es依赖版本保持一致,如此兼容性最佳, 不易踩坑. 底层之所以采用7.14.0也是经过多方调研,选择了一个稳定无安全漏洞的版本,经墨菲扫描该版本安全可靠. 至于ES客户端版本,7.10+实测兼容性都非常出色,依赖中的jar包版本与客户端版本不匹配无妨,重点是依赖的Jar版本
二,初始化工程
1,创建一个空的 Spring Boot 工程
添加依赖
org.dromara.easy-es
easy-es-boot-starter
Latest Version
org.springframework.boot
spring-boot-starter-web
org.elasticsearch.client
elasticsearch-rest-high-level-client
org.elasticsearch
elasticsearch
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.14.0
org.elasticsearch
elasticsearch
7.14.0
配置
在 application.yml 配置文件中添加EasyEs必须的相关配置:
easy-es:
enable: true #默认为true,若为false则认为不启用本框架
address : 127.0.0.1:9200 # es的连接地址,必须含端口 若为集群,则可以用逗号隔开 例如:127.0.0.1:9200,127.0.0.2:9200
username: elastic #若无 则可省略此行配置
password: WG7WVmuNMtM4GwNYkyWH #若无 则可省略此行配置
其它配置暂可省略,后面有章节详细介绍EasyEs的配置
在 Spring Boot 启动类中添加 @EsMapperScan 注解,扫描 Mapper 文件夹:
@SpringBootApplication
@EsMapperScan("com.xpc.easyes.sample.mapper")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
需求
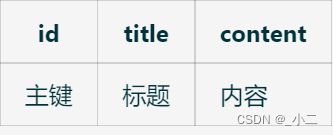
现有一张Document文档表,随着数据量膨胀,其查询效率已经无法满足产品需求,其表结构如下,我们打算将此表内容迁移至Es搜索引擎,提高查询效率
编码
编写实体类Document.java
@Data
public class Document {
/**
* es中的唯一id
*/
private String id;
/**
* 文档标题
*/
private String title;
/**
* 文档内容
*/
private String content;
}
温馨提示
- 上面字段名称以及下划线转自动驼峰,字段在ES中的存储类型,分词器等均可配置,在后续章节会有介绍.
- String类型默认会被EE创建为keyword类型,keyword类型支持精确查询等
- 如需分词查询,可像上面content一样,在字段上加上@TableField注解并指明字段类型为text,并指定分词器.
编写Mapper类 DocumentMapper.java
public interface DocumentMapper extends BaseEsMapper {
}
前置操作
手动创建索引(相当于MySQL等数据库中的表),有了索引才能进行后续CRUD操作.
@Test
public void testCreateIndex() {
// 测试创建索引,框架会根据实体类及字段上加的自定义注解一键帮您生成索引 需确保索引托管模式处于manual手动挡(默认处于此模式),若为自动挡则会冲突
boolean success = documentMapper.createIndex();
Assertions.assertTrue(success);
}
温馨提示
- 我们目前提供了4种索引创建的方式,上述演示的是推荐新手使用的一键创建模式,如果您对其它集中模式感兴趣,可以移步至索引托管章节查看
- 其中自动挡模式之平滑模式可以自动感知索引变化,自动调整索引,平滑迁移数据,但不推荐小白使用,建议了解原理及源码后再使用
- 当然您也可以通过其它几种模式来维护索引,或者通过logstash,es-head等工具进行索引维护
开始使用(CRUD)
新增一条数据(相当于MySQL中的Insert操作)
@Test
public void testInsert() {
// 测试插入数据
Document document = new Document();
document.setTitle("老汉");
document.setContent("推*技术过硬");
int successCount = documentMapper.insert(document);
System.out.println(successCount);
}
根据条件查询指定数据(相当于MySQL中的Select操作)
@Test
public void testSelect() {
// 测试查询 写法和MP一样 可以用链式,也可以非链式 根据使用习惯灵活选择即可
String title = "老汉";
Document document = EsWrappers.lambdaChainQuery(documentMapper)
.eq(Document::getTitle, title)
.one();
System.out.println(document);
Assert.assertEquals(title,document.getTitle());
}
更新数据(相当于MySQL中的Update操作)
@Test
public void testUpdate() {
// 测试更新 更新有两种情况 分别演示如下:
// case1: 已知id, 根据id更新 (为了演示方便,此id是从上一步查询中复制过来的,实际业务可以自行查询)
String id = "krkvN30BUP1SGucenZQ9";
String title1 = "隔壁老王";
Document document1 = new Document();
document1.setId(id);
document1.setTitle(title1);
documentMapper.updateById(document1);
// case2: id未知, 根据条件更新
LambdaEsUpdateWrapper wrapper = new LambdaEsUpdateWrapper<>();
wrapper.eq(Document::getTitle,title1);
Document document2 = new Document();
document2.setTitle("隔壁老李");
document2.setContent("推*技术过软");
documentMapper.update(document2,wrapper);
}
删除数据(相当于MySQL中的Delete操作)
@Test
public void testDelete() {
// 测试删除数据 删除有两种情况:根据id删或根据条件删
// 鉴于根据id删过于简单,这里仅演示根据条件删,以老李的名义删,让老李心理平衡些
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
String title = "隔壁老李";
wrapper.eq(Document::getTitle,title);
int successCount = documentMapper.delete(wrapper);
System.out.println(successCount);
}
三,springboot集成Easy-ES
1,创建springboot项目,pom文件添加Easy-ES依赖
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.6.0
com.example
ee-use
0.0.1-SNAPSHOT
ee-use
Demo project for Spring Boot
1.8
org.springframework.boot
spring-boot-starter-web
org.elasticsearch.client
elasticsearch-rest-high-level-client
org.elasticsearch
elasticsearch
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.14.0
org.elasticsearch
elasticsearch
7.14.0
org.dromara.easy-es
easy-es-boot-starter
${Latest version}
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
特别注意 当前发行的最新版本Latest version请看上图获取,实际填入的是具体的版本号数字,比如2.0.0,并不是Latest version!!!
另外由于springboot内置关联了es版本,不同的springboot版本会导致实际项目中引入的es依赖版本过低或过高, 而es不同版本兼容性比较差,很多用户踩到一些因依赖冲突而导致兼容问题的坑,在此特地提醒用户,如果您项目实际依赖的es版本不为 7.14.0版本,我们强烈建议您显示指定es依赖jar包版本为7.14.0,与我们底层使用的es依赖版本保持一致,如此兼容性最佳, 不易踩坑. 底层之所以采用7.14.0也是经过多方调研,选择了一个稳定无安全漏洞的版本,经墨菲扫描该版本安全可靠. 至于ES客户端版本,7.10+实测兼容性都非常出色,依赖中的jar包版本与客户端版本不匹配无妨,重点是依赖的Jar版本
1,核心代码
@RestController
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class TestUseEeController {
private final DocumentMapper documentMapper;
@GetMapping("/createIndex")
public Boolean createIndex() {
// 1.初始化-> 创建索引(相当于mysql中的表)
return documentMapper.createIndex();
}
@GetMapping("/insert")
public Integer insert() {
// 2.初始化-> 新增数据
Document document = new Document();
document.setTitle("老汉");
document.setContent("推*技术过硬");
return documentMapper.insert(document);
}
@GetMapping("/search")
public List search() {
// 3.查询出所有标题为老汉的文档列表
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉");
return documentMapper.selectList(wrapper);
}
}
2,启动及使用
添加配置信息
easy-es:
enable: true # 默认为true,若为false时,则认为不启用本框架
address: 127.0.0.0:9200 #填你的es连接地址
# username: 有设置才填写,非必须
# password: 有设置才填写,非必须
启动项目
使用
依次请求下述三个接口:
http://localhost:8080/createIndex (opens new window)(创建索引)
http://localhost:8080/insert (opens new window)(插入数据)
http://localhost:8080/search (opens new window)(查询)3,配置
基础配置:
如果缺失可导致项目无法正常启动,其中账号密码可缺省.
easy-es:
address : 127.0.0.1:9200 # es连接地址+端口 格式必须为ip:port,如果是集群则可用逗号隔开
username: elastic #如果无账号密码则可不配置此行
password: WG7WVmuNMtM4GwNYkyWH #如果无账号密码则可不配置此行
扩展配置
可缺省,不影响项目启动,为了提高生产环境性能,建议您按需配置
特别注意
如果您开启了索引托管-平滑模式(默认开启),并且您需要迁移的数据量很大,可以调大socketTimeout,否则迁移可能会超时异常 单位是毫秒,默认为1分钟,我们经过测试发现迁移1万条数据大约需要5秒左右,当然该数值需要综合考虑您的服务器硬件负载等因素,因此建议 您按需配置,尽量给大不给小,跟那玩意一样,大点没事,太小你懂的!
easy-es:
keep-alive-millis: 30000 # 心跳策略时间 单位:ms
connect-timeout: 5000 # 连接超时时间 单位:ms
socket-timeout: 600000 # 通信超时时间 单位:ms
request-timeout: 5000 # 请求超时时间 单位:ms
connection-request-timeout: 5000 # 连接请求超时时间 单位:ms
max-conn-total: 100 # 最大连接数 单位:个
max-conn-per-route: 100 # 最大连接路由数 单位:个
全局配置:
easy-es:
enable: true # 是否开启EE自动配置 默认开启,可缺省
schema: http # 默认为http 可缺省
banner: true # 默认为true 打印banner 若您不期望打印banner,可配置为false
global-config:
process-index-mode: manual #索引处理模式,smoothly:平滑模式, not_smoothly:非平滑模式, manual:手动模式,,默认开启此模式
print-dsl: true # 开启控制台打印通过本框架生成的DSL语句,默认为开启,测试稳定后的生产环境建议关闭,以提升少量性能
distributed: false # 当前项目是否分布式项目,默认为true,在非手动托管索引模式下,若为分布式项目则会获取分布式锁,非分布式项目只需synchronized锁.
reindexTimeOutHours: 72 # 重建索引超时时间 单位小时,默认72H 可根据ES中存储的数据量调整
async-process-index-blocking: true # 异步处理索引是否阻塞主线程 默认阻塞 数据量过大时调整为非阻塞异步进行 项目启动更快
active-release-index-max-retry: 4320 # 分布式环境下,平滑模式,当前客户端激活最新索引最大重试次数,若数据量过大,重建索引数据迁移时间超过4320/60=72H,可调大此参数值,此参数值决定最大重试次数,超出此次数后仍未成功,则终止重试并记录异常日志
active-release-index-fixed-delay: 60 # 分布式环境下,平滑模式,当前客户端激活最新索引最大重试次数 分布式环境下,平滑模式,当前客户端激活最新索引重试时间间隔 若您期望最终一致性的时效性更高,可调小此值,但会牺牲一些性能
db-config:
map-underscore-to-camel-case: false # 是否开启下划线转驼峰 默认为false
index-prefix: daily_ # 索引前缀,可用于区分环境 默认为空 用法和MP的tablePrefix一样的作用和用法
id-type: customize # id生成策略 customize为自定义,id值由用户生成,比如取MySQL中的数据id,如缺省此项配置,则id默认策略为es自动生成
field-strategy: not_empty # 字段更新策略 默认为not_null
enable-track-total-hits: true # 默认开启,开启后查询所有匹配数据,若不开启,会导致无法获取数据总条数,其它功能不受影响,若查询数量突破1W条时,需要同步调整@IndexName注解中的maxResultWindow也大于1w,并重建索引后方可在后续查询中生效(不推荐,建议分页查询).
refresh-policy: immediate # 数据刷新策略,默认为不刷新,若对数据时效性要求比较高,可以调整为immediate,但性能损耗高,也可以调整为折中的wait_until
batch-update-threshold: 10000 # 批量更新接口的阈值 默认值为1万,突破此值需要同步调整enable-track-total-hits=true,@IndexName.maxResultWindow > 1w,并重建索引.
smartAddKeywordSuffix: true # 是否智能为字段添加.keyword后缀 默认开启,开启后会根据当前字段的索引类型及当前查询类型自动推断本次查询是否需要拼接.keyword后缀
其它配置:
logging:
level:
tracer: trace # 开启trace级别日志,在开发时可以开启此配置,则控制台可以打印es全部请求信息及DSL语句,为了避免重复,开启此项配置后,可以将EE的print-dsl设置为false.
温馨提示
id-type支持3种类型:
- auto: 由ES自动生成,是默认的配置,无需您额外配置 推荐
- uuid: 系统生成UUID,然后插入ES (不推荐)
- customize: 用户自定义,在此类型下,用户可以将任意数据类型的id存入es作为es中的数据id,比如将mysql自增的id作为es的id,可以开启此模式,或通过@TableId(type)注解指定.
field-strategy支持3种类型:
- not_null: 非Null判断,字段值为非Null时,才会被更新
- not_empty: 非空判断,字段值为非空字符串时才会被更新
- ignore: 忽略判断,无论字段值为什么,都会被更新
- 在配置了全局策略后,您仍可以通过注解针对个别类进行个性化配置,全局配置的优先级是小于注解配置的
refresh-policy支持3种策略
- none: 默认策略,不刷新数据
- immediate : 立即刷新,会损耗较多性能,对数据实时性要求高的场景下适用
- wait_until: 请求提交数据后,等待数据完成刷新(1s),再结束请求 性能损耗适中
4,注解
@EsMapperScan
-
描述:mapper扫描注解,功能与MP的@MapperScan一致
-
使用位置:Springboot启动类
-
@EsMapperScan("cn.easy-es-mapper") public class Application{ // 省略其它... }
温馨提示
由于EE和MP对Mapper的扫描都是采用Springboot的doScan,而且两套系统互相独立,所以在扫描的时候没有办法互相隔离,因此如果您的项目同时有用到EE和MP,您需要将EE的Mapper和MP的Mapper放在不同的包下,否则项目将无法正常启动
@IndexName
-
描述:索引名注解,标识实体类对应的索引 对应MP的@TableName注解,在v0.9.40之前此注解为@TableName.
-
使用位置:实体类
-
@IndexName public class Document { // 省略其它字段 }属性 类型 必须指定 默认值 描述 value String 否 "" 索引名,可简单理解为MySQL表名 shardsNum int 否 1 索引分片数 replicasNum int 否 1 索引副本数 aliasName String 否 "" 索引别名 keepGlobalPrefix boolean 否 false 是否保持使用全局的 tablePrefix 的值,与MP用法一致 child boolean 否 false 是否子文档 childClass Class 否 DefaultChildClass.class 父子文档-子文档类 maxResultWindow int 否 10000 分页返回的最大数据量,默认值为1万条,超出推荐使用searchAfter或滚动查询等方式,详见拓展功能章节. 当此值调整至大于1W后,需要重建索引并同步开启配置文件中的enable-track-total-hits=true方可生效 routing String 否 "" 路由,CRUD作用的路由 refreshPolicy Enum 否 NONE 索引数据刷新策略,默认为不刷新,其取值参考RefreshPolicy枚举类,一共有3种刷新策略 动态索引名称支持 如果你的索引名称是不固定的,我们提供了两种方式可修改CRUD时的索引名称
调用mapper.setCurrentActiveIndex(String indexName)方法,此处的mapper为你自定义的mapper,如documentMapper,通过此API修改索引名称后,全局生效.
在对应的参数中指定当前操作作用的索引,例如 wrapper.index(String indexName),通过此API修改索引名称后,仅作用于该wrapper对应的操作,粒度最细.
温馨提示
- 当您想直接把类名当作索引名,且并不需要对索引进行其它配置时,可省略此注解
- 通过注解指定的索引名称优先级最高,指定了注解索引,则全局配置和自动生成索引不生效,采用注解中指定的索引名称. 优先级排序: 注解索引>全局配置索引前缀>自动生成
- keepGlobalPrefix选项,(0.9.4+版本才支持)默认值为false,是否保持使用全局的 indexPrefix 的值:
- 既配置了全局tablePrefix,@TableName注解又指定了value值时,此注解选项才会生效,如果其值为true,则框架最终使用的索引名称为:全局indexPrefix+此注解的value,例如:dev_document
- 此注解选项用法和MP中保持一致.
- 其中shardNum为分片数,replicasNum为副本数,如果不指定,默认值均为1
- RefreshPolicy 数据刷新策略
- None 不刷新,es默认的策略,此策略下数据变更后有一定延迟才会生效,但写入性能最好,通常情况下使用此默认策略即可
- IMMEDIATE 立即刷新,适用于对数据延迟敏感的业务场景,但消耗的系统资源最大
- WAIT_UNTIL 请求提交数据后,等待数据完成刷新(约1s),再结束请求 性能损耗适中 属于折中方案
@IndexId
- 描述:ES主键注解
- 使用位置:实体类中被作为ES主键的字段, 对应MP的@TableId注解
public class Document {
@IndexId
private String id;
// 省略其它字段
}

温馨提示
当您字段命名为id且类型为String时,且不需要采用UUID及自定义ID类型时,可省略此注解
由于es对id的默认名称做了处理(下划线+id):_id,所以EE已为您屏蔽这步操作,您无需在注解中指定,框架也会自动帮您完成映射.
- Id的生成类型支持以下几种:
- IdType.NONE: 由ES自动生成,是默认缺省时的配置,无需您额外配置 推荐
- IdType.UUID: 系统生成UUID,然后插入ES (不推荐)
- IdType.CUSTOMIZE: 由用户自定义,用户自己对id值进行set,如果用户指定的id在es中不存在,则在insert时就会新增一条记录,如果用户指定的id在es中已存在记录,则自动更新该id对应的记录
@IndexField
- 描述:ES字段注解, 对应MP的@TableField注解
- 使用位置:实体类中被作为ES索引字段的字段
- 使用场景举例:
- 实体类中的字段并非ES中实际的字段,比如把实体类直接当DTO用了,加了一些ES中并不存在的无关字段,此时可以标记此字段,以便让EE框架跳过此字段,对此字段不处理.
- 字段的更新策略,比如在调用更新接口时,实体类的字段非Null或者非空字符串时才更新,此时可以加字段注解,对指定字段标记更新策略.
- 需要对类型为text或keyword_tex字段聚合时,可指定其fieldData=true,否则es会报错.
- 对指定字段进行自定义命名,比如该字段在es中叫wu-la,但在实体model中叫ula,此时可以在value中指定value="wu-la".
- 在自动托管索引模式下,可指定索引分词器及索引字段类型.
- 在自动托管索引模式下,可指定索引中日期的format格式.
- 可指定创建索引时,自动对指定字段添加忽略大小写的配置.
使用示例:
public class Document {
// 此处省略其它字段...
// 场景一:标记es中不存在的字段
@IndexField(exist = false)
private String notExistsField;
// 场景二:更新时,此字段非空字符串才会被更新
@IndexField(strategy = FieldStrategy.NOT_EMPTY)
private String creator;
// 场景三: 指定fieldData
@IndexField(fieldType = FieldType.TEXT, fieldData = true)
private String filedData;
// 场景四:自定义字段名
@IndexField("wu-la")
private String ula;
// 场景五:支持日期字段在es索引中的format类型
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private String gmtCreate;
// 场景六:支持指定字段在es索引中的分词器类型
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String content;
// 场景七:支持指定字段在es的索引中忽略大小写,以便在term查询时不区分大小写,仅对keyword类型字段生效,es的规则,并非框架限制.
@IndexField(fieldType = FieldType.KEYWORD, ignoreCase = true)
private String caseTest;
}
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 字段名 |
| exist | boolean | 否 | true | 字段是否存在 |
| fieldType | Enum | 否 | FieldType.NONE | 字段在es索引中的类型 |
| fieldData | boolean | 否 | false | text类型字段是否支持聚合 |
| analyzer | String | 否 | Analyzer.NONE | 索引文档时用的分词器 |
| searchAnalyzer | String | 否 | Analyzer.NONE | 查询分词器 |
| strategy | Enum | 否 | FieldStrategy.DEFAULT | 字段验证策略 |
| dateFormat | String | 否 | "" | es索引中的日期格式,如yyyy-MM-dd |
| nestedClass | Class | 否 | DefaultNestedClass.class | 嵌套类 |
| parentName | String | 否 | "" | 父子文档-父名称 |
| childName | String | 否 | "" | 父子文档-子名称 |
| joinFieldClass | Class | 否 | JoinField.class | 父子文档-父子类型关系字段类 |
| ignoreCase | boolean | 否 | false | keyword类型字段是否忽略大小写 |
| ignoreAbove | int | 否 | 256 | 字符串将被索引或存储的最大长度 |
| scalingFactor | int | 否 | 100 | 用于指定浮点数字段的缩放因子,scaled_float类型字段必须指定此参数,否则es创建索引报错 |
温馨提示
- 更新策略一共有3种:
- NOT_NULL: 非Null判断,字段值为非Null时,才会被更新
- NOT_EMPTY: 非空判断,字段值为非空字符串时才会被更新
- IGNORE: 忽略判断,无论字段值为什么,都会被更新
- 针对BigDecimal类型字段,其scalingFactor若用户未指定,则系统默认值为100
其中场景四和场景五仅在索引自动托管模式下生效,如果开启了手动处理索引模式,则需要用户通过手动调用我提供的API传入相应的分词器及日期格式化参数进行索引的创建/更新
@MultiIndexField
- 描述:多字段注解
- 使用位置:实体类中单个字段期望用多种分词器或多种字段类型的字段上
- 使用场景举例:比如一个字段既想要用中文分词器查询,又想要用拼音分词器查询
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| mainIndexField | @IndexField | 是 | - | 主字段必须指定,用法可以参考上面的@IndexField |
| InnerIndexField | @InnerIndexField[] | 否 | {} | 内部字段,可以为空数组,当内部字段不指定时,则此注解降级为@IndexField,与@IndexField注解效果一致 |
@InnerIndexField
- 描述:内部字段注解
- 使用位置:@MultiIndexField内部
- 使用场景举例:比如一个字段既想要用中文分词器查询,又想要用拼音分词器查询,可以在@MultiIndexField中指定
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| suffix | String | 是 | - | 内部字段后缀 |
| fieldType | FieldType | 是 | - | 内部字段的字段类型,此枚举与@IndexField中的FieldType是同一个,用法可以直接参考 |
| analyzer | String | 否 | - | 索引分词器,与@IndexField中的Analyzer是同一个,用法可直接参考 |
| searchAnalyzer | String | 否 | - | 查询分词器,与@IndexField中的Analyzer是同一个,用法可直接参考 |
| ignoreAbove | int | 否 | 256 | 内部字段,字符串将被索引或存储的最大长度 |
使用示例:
public class Document {
/**
* 复合字段,此注解和SpringData中的MultiField用法类似 适用于对同一个字段通过多种分词器检索的场景
*/
@MultiIndexField(mainIndexField = @IndexField(fieldType = FieldType.KEYWORD),
otherIndexFields = {@InnerIndexField(suffix = "zh", fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART),
@InnerIndexField(suffix = "pinyin", fieldType = FieldType.TEXT, analyzer = Analyzer.PINYIN)})
private String multiField;
}
查询示例:
@Test
public void testMultiFieldSelect() {
// 药品 中文名叫葡萄糖酸钙口服溶液 英文名叫 Calcium Gluconate 汉语拼音为 putaotangsuangaikoufurongye
// 用户可以通过模糊检索,例如输入 Calcium 或 葡萄糖 或 putaotang时对应药品均可以被检索到
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.match("english", "Calcium")
.or()
.match("multi_field.zh", "葡萄糖")
.or()
.match("multi_field.pinyin", "putaotang");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
上述使用案例中,开启了驼峰自动转下划线,因此字段名为"multi_field",实际上在查询中用户只需要用"字段名.suffix"组合,即可确定当前启用哪个内部字段,当查询主字段时,则无需指定suffix,直接字段名即可.
@HighLight
- 描述:高亮注解
- 使用位置:实体类中需要高亮的被查询字段
- 使用场景举例:比如输入关键词"老汉"进行查询,期望内容中包含"老汉"的部分被展示为红色或加粗
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| mappingField | String | 否 | "" | 高亮内容映射字段的名称,比如我想把高亮内容"老汉"赋值到字段pushCar上,就可以指定此属性值为pushCar |
| fragmentSize | int | 否 | 100 | 高亮字段截取长度,默认为100 |
| numberOfFragments | int | 否 | -1 | 搜索返回的高亮片段数量,默认全部返回 |
| preTag | String | 否 | < em > | 高亮标签,高亮内容将处于preTag之后 |
| postTag | String | 否 | < /em > | 高亮标签,高亮内容将处于postTag之前 |
| highLightType | HighLightTypeEnum | 否 | UNIFIED | 高亮类型 |
@Score
- 描述:得分注解
- 使用位置:实体类中被作为ES查询得分返回的字段
- 使用场景举例:比如需要知道本次匹配查询得分有多少时,可以在实体类中添加一个类型为Float/float的字段,并在该字段上添加@Score注解,在后续查询中,若es有返回当次查询的得分,则此得分会自动映射至此字段上
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| decimalPlaces | int | 否 | 0 | 得分保留小数位,默认不处理,保持es返回的得分值 |
@Distance
- 描述:距离注解
- 使用位置:实体类中被作为ES地理位置排序距离值的返回字段
- 使用场景举例:比如需要知道按距离由近及远查询后的数据,实际距离某一坐标有多远,可以在实体类中添加一个类型为Double/double的字段,并在该字段上添加@Distance注解,在后续查询中,若es有返回距离,则此距离会自动映射至此字段上
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| decimalPlaces | int | 否 | 0 | 距离保留小数位,默认不处理,保持es返回的距离值 |
其它注解
除了上面这几个高频注解,项目中偶尔还会用到一些其它注解,比如比如拦截器注解@Intercepts等注解,我们会在后面具体的章节详细介绍,此处仅列出几个必须掌握的注解,其它注解按需学习即可。
核心功能
一,条件构造器
1,介绍
Wrapper支持两种方式创建:
- 直接new,例如 new
LambdaEsQueryWrapper<>(). - 通过EsWrappers.lambdaQuery()创建,可支撑链式编程的场景,对标MP的Wrappers
说明
- 以下出现的第一个入参boolean condition表示该条件是否加入最后生成的语句中,例如:query.like(StringUtils.isNotBlank(name), Entity::getName, name) .eq(age!=null && age >= 0, Entity::getAge, age)
- 以下代码块内的多个方法均为从上往下补全个别boolean类型的入参,默认为true
- 以下出现的泛型Param均为Wrapper的子类实例(均具有AbstractWrapper的所有方法)
- 以下方法在入参中出现的R为泛型,在普通wrapper中是String,在LambdaWrapper中是函数(例:Entity::getId,Entity为实体类,getId为字段id的getMethod)
- 以下方法入参中的R column均表示数据库字段,当R具体类型为String时则为数据库字段名(字段名是数据库关键字的自己用转义符包裹!)!而不是实体类数据字段名!!!,另当R具体类型为SFunction时项目runtime不支持eclipse自家的编译器!!!
- 以下举例均为使用普通wrapper,入参为Map和List的均以json形式表现!
- 使用中如果入参的Map或者List为空,则不会加入最后生成的sql中!
警告
不支持以及不赞成在 RPC 调用中把 Wrapper 进行传输
- wrapper 很重
- 传输 wrapper 可以类比为你的 controller 用 map 接收值(开发一时爽,维护火葬场)
- 正确的 RPC 调用姿势是写一个 DTO 进行传输,被调用方再根据 DTO 执行相应的操作
- 我们拒绝接受任何关于 RPC 传输 Wrapper 报错相关的 issue 甚至 pr
AbstractWrapper
说明
QueryWrapper(LambdaEsQueryWrapper) 和 UpdateWrapper(LambdaEsUpdateWrapper) 的父类用于生成 语句 的 where 条件, entity 属性也用于生成 语句 的 where 条件注意: entity 生成的 where 条件与 使用各个 api 生成的 where 条件 没有任何关联行为
QueryWrapper
说明
继承自 AbstractWrapper ,自身的内部属性 entity 也用于生成 where 条件及 LambdaEsQueryWrapper
UpdateWrapper
说明
继承自 AbstractWrapper ,自身的内部属性 entity 也用于生成 where 条件及 LambdaEsUpdateWrapper
AbstractChainWrapper
说明
继承自 Wrapper ,用于支持链式调用
2,索引条件构造器
LambdaEsIndexWrapper
提示
索引的CRUD中的相关条件依托于此构造器进行封装
API说明
LambdaEsIndexWrapper提供了下述API可供用户使用
mapping(R column, FieldType fieldType);
mapping(R column, FieldType fieldType, Boolean fieldData);
mapping(R column, FieldType fieldType, Float boost);
mapping(R column, FieldType fieldType, Boolean fieldData, Float boost);
mapping(R column, FieldType fieldType, String dateFormat);
mapping(R column, FieldType fieldType, String analyzer, String searchAnalyzer);
mapping(R column, FieldType fieldType, String analyzer, String searchAnalyzer, String dateFormat);
mapping(R column, FieldType fieldType, String analyzer, String searchAnalyzer, Float boost);
mapping(R column, FieldType fieldType, String analyzer, String searchAnalyzer, String dateFormat, Boolean fieldData, Float boost);
mapping(Map mapping);
createAlias(String aliasName);
settings(Settings settings);
settings(Integer shards, Integer replicas);
maxResultWindow(Integer maxResultWindow);
indexName(String... indexNames);
使用案例
/**
* LambdaEsIndexWrapper构造器使测案例一:创建索引,通过开箱即用的方法创建
*/
@Test
public void testCreateIndex() {
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
// 此处简单起见 索引名称须保持和实体类名称一致,字母小写 后面章节会教大家更如何灵活配置和使用索引
wrapper.indexName(Document.class.getSimpleName().toLowerCase());
// 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型(支持分词查询)
wrapper.mapping(Document::getTitle, FieldType.KEYWORD, 2.0f)
.mapping(Document::getLocation, FieldType.GEO_POINT)
.mapping(Document::getGeoLocation, FieldType.GEO_SHAPE)
.mapping(Document::getContent, FieldType.TEXT, Analyzer.IK_SMART, Analyzer.IK_MAX_WORD);
// 设置分片及副本信息,可缺省
wrapper.settings(3, 2);
// 设置别名信息,可缺省
String aliasName = "daily";
wrapper.createAlias(aliasName);
// 设置父子信息,若无父子文档关系则无需设置
wrapper.join("joinField", "document", "comment");
// 创建索引
boolean isOk = documentMapper.createIndex(wrapper);
Assertions.assertTrue(isOk);
}
/**
* LambdaEsIndexWrapper构造器使测案例二:创建索引,通过自定义map 最难用但也最灵活
*/
@Test
public void testCreateIndexByMap() {
// 演示通过自定义map创建索引,最为灵活,若方案一不能满足时可用此方法
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
wrapper.indexName(Document.class.getSimpleName().toLowerCase());
wrapper.settings(3, 2);
Map map = new HashMap<>();
Map prop = new HashMap<>();
Map field = new HashMap<>();
field.put("type", FieldType.KEYWORD.getType());
prop.put("this_is_field", field);
map.put("properties", prop);
wrapper.mapping(map);
boolean isOk = documentMapper.createIndex(wrapper);
Assertions.assertTrue(isOk);
}
/**
* LambdaEsIndexWrapper构造器使测案例三:更新索引(不推荐使用,因为索引变动ES会重建索引,有其它更好的方式,可参考后面索引托管章节)
*/
@Test
public void testUpdateIndex() {
// 测试更新索引
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
// 指定要更新哪个索引
String indexName = Document.class.getSimpleName().toLowerCase();
wrapper.indexName(indexName);
wrapper.mapping(Document::getCreator, FieldType.KEYWORD);
wrapper.mapping(Document::getGmtCreate, FieldType.DATE);
boolean isOk = documentMapper.updateIndex(wrapper);
Assertions.assertTrue(isOk);
}
3,查询条件构造器
LambdaEsQueryWrapper
提示
此条件构造器主要用于查询数据时所需查询条件的封装
allEq
allEq(Map params)
全部eq
个别参数说明
params : key为数据库字段名,value为字段值
- 例: allEq({id:1,name:"老王",age:18})--->id = 1 and name = '老王' and age = 18
allEq(BiPredicate filter, Map params)
个别参数说明
filter : 过滤函数,是否允许字段传入比对条件中 params 与 null2IsNull : 同上
- 例: allEq((k,v) -> k.indexOf("a") >= 0, {id:1,name:"老王",age:18})--->name = '老王' and age = 18
eq
eq(R column, Object val)
eq(boolean condition, R column, Object val)
- 等于 =
- 例: eq("name", "老王")--->name = '老王'
gt
gt(R column, Object val)
gt(boolean condition, R column, Object val)
- 大于 >
- 例: gt("age", 18)--->age > 18
ge
ge(R column, Object val)
ge(boolean condition, R column, Object val)
- 大于等于 >=
- 例: ge("age", 18)--->age >= 18
lt
lt(R column, Object val)
lt(boolean condition, R column, Object val)
- 小于 <
- 例: lt("age", 18)--->age < 18
le
le(R column, Object val)
le(boolean condition, R column, Object val)
- 小于等于 <=
- 例: le("age", 18)--->age <= 18
between
between(R column, Object val1, Object val2)
between(boolean condition, R column, Object val1, Object val2)
- BETWEEN 值1 AND 值2
- 例: between("age", 18, 30)--->age between 18 and 30
like
like(R column, Object val)
like(boolean condition, R column, Object val)
- LIKE '%值%'
- 例: like("name", "王")--->name like '%王%'
likeLeft
likeLeft(R column, Object val)
likeLeft(boolean condition, R column, Object val)
- LIKE '%值'
- 例: likeLeft("name", "王")--->name like '%王'
likeRight
likeRight(R column, Object val)
likeRight(boolean condition, R column, Object val)
- LIKE '值%'
- 例: likeRight("name", "王")--->name like '王%'
isNotNull
isNotNull(R column)
isNotNull(boolean condition, R column)
- 字段 IS NOT NULL
- 例: isNotNull(Document::getTitle)--->title is not null
exists
exists(R column)
exists(boolean condition, R column)
效果和功能等价于上面的isNotNull,主要是为了照顾es原生语法习惯的用户
in
in(R column, Collection value)
in(boolean condition, R column, Collection value)
- 字段 in (value.get(0), value.get(1), ...)
- 例: in("age",{1,2,3})--->age in (1,2,3)
in(R column, Object... values)
in(boolean condition, R column, Object... values)
- 字段 in (v0, v1, ...)
- 例: in("age", 1, 2, 3)--->age in (1,2,3)
groupBy
groupBy(R... columns)
groupBy(boolean condition, R... columns)
- 分组:GROUP BY 字段, ...
- 例: groupBy(Document::getId,Document::getTitle)--->group by id,title
orderByDesc
orderByDesc(R... columns)
orderByDesc(boolean condition, R... columns)
- 排序:ORDER BY 字段, ... DESC
- 例: orderByDesc(Document::getId,Document::getTitle)--->order by id DESC,title DESC
limit
limit(Integer n);
limit(Integer m, Integer n);
- limit n 最多返回多少条数据,相当于MySQL中limit n 中的n,用法一致.
- limit m,n 跳过m条数据,最多返回n条数据,相当于MySQL中的limit m,n 或 offset m limit n
- 例: limit(10)--->最多只返回10条数据
- 例: limit(2,5)--->跳过前2条数据,从第3条开始查询,总共查询5条数据
温馨提示
n参数若不指定,则其默认值是10000 ,如果你单次查询超过1W条,建议采用分页(参考后面分页章节),万不得已非要在这里指定超过1w,比如指定2w,需要在查询的实体类上加上注解@IndexName(maxResultWindow=20000) 指定其maxResultWindow,并重建索引,否则es会报错,这是es的规则,它作此限制应该是为了保护你的内存防止溢出. 如果你单次查询,不想要太多得分较低的数据,需要手动指定n去做限制. 另外此参数作用与Es中的size,from一致,只是为了兼容MySQL语法而引入,使用者可以根据自身习惯二选一,当两种都用时,只有一种会生效,后指定的会覆盖先指定的
from
from(Integer from)
- 从第几条数据开始查询,相当于MySQL中limit (m,n)中的m.
- 例: from(10)--->从第10条数据开始查询
size
size(Integer size)
- 最多返回多少条数据,相当于MySQL中limit (m,n)中的n 或limit n 中的n
- 例: size(10)--->最多只返回10条数据
温馨提示
如果你单次查询,不想要太多得分较低的数据,需要手动指定size去做限制
minScore
minScore(Float score)
- 查询得分不低于score的数据,如果得分低于此值,则不被命中
trackScores
trackScores();
- 开启计算得分 默认值为关闭状态 查询得分可以用于排序等场景
index
index(String indexName)
index(boolean condition, String indexName)
温馨提示
可通过wrapper.index(String indexName)指定本次查询作用于哪个索引,如果本次查询要从多个索引上查询,那么索引名称可以用逗号隔开,例如wrapper.index("index1","indexe2"...) wrapper中指定的索引名称优先级最高,如果不指定则取实体类中配置的索引名称,如果实体类也未配置,则取实体名称小写作为当前查询的索引名 针对insert/delete/update等接口中无wrapper的情况,如果你需要指定索引名,可直接在对应接口的入参中添加索引名称,可参考下面示例:
Document document = new Document();
// 省略为document赋值的代码
String indexName = "laohan";
insert(document,indexName);
and
and(Consumer consumer)
and(boolean condition, Consumer consumer)
- AND
- 例: and(i -> i.eq(Document::getTitle, "Hello").eq(Document::getCreator, "Guy"))--->and (title ='Hello' and creator = 'Guy' )
or
or()
or(boolean condition)
- 拼接 OR 注意事项: 主动调用or表示紧接着下一个方法不是用and连接!(不调用or则默认为使用and连接)
- 例: eq("Document::getId",1).or().eq(Document::getTitle,"Hello")--->id = 1 or title ='Hello'
or(Consumer consumer)
or(boolean condition, Consumer consumer)
-
嵌套 OR
-
例: or(i -> i.eq(Document::getTitle, "Hello").ne(Document::getCreator, "Guy"))--->or (title ='Hello' and status != 'Guy' )
-
特殊情况
-
例: eq(Document::getTitle,"Hello") .and(i->i.eq(Document::getCreator,"Bob").or().eq(Document::getCreator,"Tom"))---> title="Hello" and(creator="Bob" or creator="Tom")
filter
and和filter的选择,它们在功能上类似,都是表示必须满足的条件,不同之处在于filter不计算得分,性能表现更好,但不支持根据得分排序.
filter()
filter(boolean condition)
- 拼接 filter 注意事项: 主动调用filter表示紧接着下一个方法不是用and连接!(不调用filter则默认为使用and连接)
- 例: eq("Document::getId",1).filter().eq(Document::getTitle,"Hello")--->id = 1 and title ='Hello'
filter(Consumer consumer)
filter(boolean condition, Consumer consumer)
- 嵌套 filter
- 例: filter(i -> i.eq(Document::getTitle, "Hello").eq(Document::getCreator, "Guy"))--->or (title ='Hello' and status = 'Guy' )
not
not()
not(boolean condition)
- 拼接 not 注意事项: 主动调用not表示紧接着下一个方法不是用and连接!(不调用not则默认为使用and连接)
- 例: eq("Document::getId",1).not().eq(Document::getTitle,"Hello")--->id = 1 and title !='Hello'
4,更新条件构造器
LambdaEsUpdateWrapper
此条件构造器主要用于更新数据时所需更新字段及其值或查询条件的封装
其中查询条件的封装与LambdaEsQueryWrapper中提供的方法一致,不一样的只有set方法
set
set(String column,Object val)
set(boolean condition,String column,Object val)
- SQL SET 字段
- 例: set("name", "老李头")
- 例: set("name", "")--->数据库字段值变为空字符串
- 例: set("name", null)--->数据库字段值变为null
使用案例:
/**
* LambdaEsUpdateWrapper 使用案例-根据条件更新数据
*/
@Test
public void testUpdate() {
// case1: 根据条件更新和实体对象更新
LambdaEsUpdateWrapper wrapper = new LambdaEsUpdateWrapper<>();
wrapper.eq(Document::getTitle, title1);
Document document = new Document();
document.setTitle("隔壁老王王");
document.setContent("推*技术过软");
document.setCustomField("乌拉巴拉中魔仙");
documentMapper.update(document, wrapper);
// case2 另一种省略实体的简单写法,语法与MP一致
LambdaEsUpdateWrapper wrapper1 = new LambdaEsUpdateWrapper<>();
wrapper1.eq(Document::getTitle, title1);
wrapper1.set(Document::getContent,"推*技术过软")
.set(Document::getCustomField,"乌拉巴拉中魔仙");
documentMapper.update(null,wrapper1);
}
二,索引CRUD
1,索引托管模式
前言
ES难用,索引首当其冲,索引的创建和更新不仅复杂,而且难于维护,一旦索引有变动,就必须面对索引重建带来的服务停机和数据丢失等问题... 尽管ES官方提供了索引别名机制来解决问题,但门槛依旧很高,步骤繁琐,在生产环境中由人工操作非常容易出现失误带来严重的问题. 为了解决这些痛点,Easy-Es提供了多种策略,将用户彻底从索引的维护中解放出来,我们提供了多种索引处理策略,来满足不同用户的个性化需求. 通过对索引的初体验,相信您也可以更深体会到EE的成熟度和易用性. 其中全自动平滑模式,首次采用全球领先的"哥哥你不用动,EE我全自动"的模式,索引的创建,更新,数据迁移等所有全生命周期均无需用户介入,由EE全自动完成,过程零停机,连索引类型都可智能自动推断,一条龙服务,包您满意.是全球开源首创,充分借鉴了JVM垃圾回收算法思想,史无前例,尽管网上已有平滑过渡方案,但并非全自动,过程依旧靠人工介入,我为EE代言,请放心将索引托管给EE,索引只有在彻底迁移成功才会删除旧索引,否则均不会对原有索引和数据造成影响,发生任何意外均能保留原索引和数据,所以安全系数很高.
温馨提示: 新手上路可尽量选择手动挡一键模式,老司机(熟悉每种模式的原理及源码)您请随意~ 追求生产环境稳定性,建议您采用手动挡模式,我们手动挡也提供了非常友好的一键创建功能,使用起来也是甜甜的. 自动挡模式,建议您在充分了解其运作原理和源码后再上生产,否则不少小白在没弄明白原理和如何正确配置就无脑上生产,容易被自己坑到,弄明白了请随便,我们的平滑模式实际上也是非常安全的.
自动托管之平滑模式(自动挡-雪地模式) 默认开启此模式
在此模式下,索引的创建更新数据迁移等全生命周期用户均不需要任何操作即可完成,过程零停机,用户无感知,可实现在生产环境的平滑过渡,类似汽车的自动档-雪地模式,平稳舒适,彻底解放用户,尽情享受自动驾驶的乐趣! 需要值得特别注意的是,在自动托管模式下,系统会自动生成一条名为ee-distribute-lock的索引,该索引为框架内部使用,用户可忽略,若不幸因断电等其它因素极小概率下发生死锁,可删除该索引即可.另外,在使用时如碰到索引变更,原索引名称可能会被追加后缀_s0或_s1,不必慌张,这是全自动平滑迁移零停机的必经之路,索引后缀不影响使用,框架会自动激活该新索引.关于_s0和_s1后缀,在此模式下无法避免,因为要保留原索引数据迁移,又不能同时存在两个同名索引,凡是都是要付出代价的,如果您不认可此种处理方式,可继续往下看,总有一种适合您
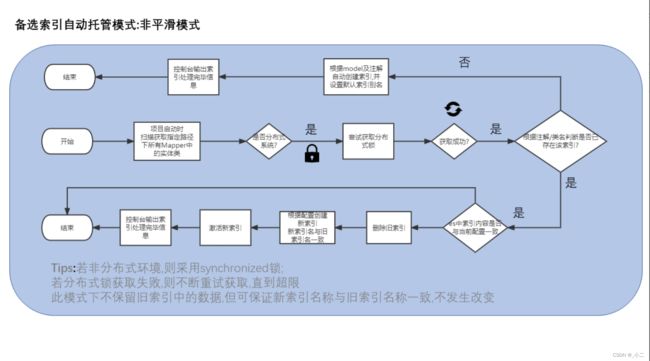
其核心处理流程梳理如下图所示,不妨结合源码看,更容易理解:

自动托管之非平滑模式(自动挡-运动模式)
在此模式下,索引额创建及更新由EE全自动异步完成,但不处理数据迁移工作,速度极快类似汽车的自动挡-运动模式,简单粗暴,弹射起步! 适合在开发及测试环境使用,当然如果您使用logstash等其它工具来同步数据,亦可在生产环境开启此模式,在此模式下不会出现_s0和_s1后缀,索引会保持原名称.
提示
以上两种自动模式中,索引信息主要依托于实体类,如果用户未对该实体类进行任何配置,EE依然能够根据字段类型智能推断出该字段在ES中的存储类型,此举可进一步减轻开发者负担,对刚接触ES的小白更是福音.
当然,仅靠框架自动推断是不够的,我们仍然建议您在使用中尽量进行详细的配置,以便框架能自动创建出生产级的索引.举个例子,例如String类型字段,框架无法推断出您实际查询中对该字段是精确查询还是分词查询,所以它无法推断出该字段到底用keyword类型还是text类型,倘若是text类型,用户期望的分词器是什么? 这些都需要用户通过配置告诉框架,否则框架只能按默认值进行创建,届时将不能很好地完成您的期望.
自动推断类型的优先级 < 用户通过注解指定的类型优先级
自动推断映射表:
| JAVA | ES |
|---|---|
| byte | byte |
| short | short |
| int | integer |
| long | long |
| float | float |
| double | double |
| BigDecimal | keyword |
| char | keyword |
| String | keyword_text |
| boolean | boolean |
| Date | date |
| LocalDate | date |
| LocalDateTime | date |
| List | text |
"自动挡"模式下的最佳实践示例:
@Data
@IndexName(shardsNum = 3,replicasNum = 2) // 可指定分片数,副本数,若缺省则默认均为1
public class Document {
/**
* es中的唯一id,如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize,如此id便支持任意数据类型)
*/
@IndexId(type = IdType.CUSTOMIZE)
private Long id;
/**
* 文档标题,不指定类型默认被创建为keyword_text类型,可进行精确查询
*/
private String title;
/**
* 文档内容,指定了类型及存储/查询分词器
*/
@HighLight(mappingField="highlightContent")
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String content;
/**
* 作者 加@TableField注解,并指明strategy = FieldStrategy.NOT_EMPTY 表示更新的时候的策略为 创建者不为空字符串时才更新
*/
@IndexField(strategy = FieldStrategy.NOT_EMPTY)
private String creator;
/**
* 创建时间
*/
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private String gmtCreate;
/**
* es中实际不存在的字段,但模型中加了,为了不和es映射,可以在此类型字段上加上 注解@TableField,并指明exist=false
*/
@IndexField(exist = false)
private String notExistsField;
/**
* 地理位置经纬度坐标 例如: "40.13933715136454,116.63441990026217"
*/
@IndexField(fieldType = FieldType.GEO_POINT)
private String location;
/**
* 图形(例如圆心,矩形)
*/
@IndexField(fieldType = FieldType.GEO_SHAPE)
private String geoLocation;
/**
* 自定义字段名称
*/
@IndexField(value = "wu-la")
private String customField;
/**
* 高亮返回值被映射的字段
*/
private String highlightContent;
}
手动模式(手动挡)
在此模式下,索引的所有维护工作EE框架均不介入,由用户自行处理,EE提供了开箱即用的索引CRUD相关API,您可以选择使用该API手动维护索引,由于API高度完善,尽管是手动挡,但使用起来依旧简单到爆,一行代码搞定索引创建.当然您亦可通过es-head等工具来维护索引,总之在此模式下,您拥有更高的自由度,比较适合那些质疑EE框架的保守用户或追求极致灵活度的用户使用,类似汽车的手动挡
手动挡模式下,EE提供了如下API,供用户进行便捷调用:
- indexName需要用户手动指定
- 对象 Wrapper 为 条件构造器
// 获取索引信息
GetIndexResponse getIndex();
// 获取指定索引信息
GetIndexResponse getIndex(String indexName);
// 是否存在索引
Boolean existsIndex(String indexName);
// 根据实体及自定义注解一键创建索引
Boolean createIndex();
// 创建索引
Boolean createIndex(LambdaEsIndexWrapper wrapper);
// 更新索引
Boolean updateIndex(LambdaEsIndexWrapper wrapper);
// 删除指定索引
Boolean deleteIndex(String indexName);

上述API,我们仅演示创建索引,其它过于简单,不在这里赘述,如有需要可移步至源码test模块查看. 通过API手动创建索引,我们提供了两种方式
方式一:根据实体类及自定义注解一键创建(推荐),99.9%场景适用
/**
* 实体类信息
**/
@Data
@IndexName(shardsNum = 3, replicasNum = 2, keepGlobalPrefix = true)
public class Document {
/**
* es中的唯一id,如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize或直接在全局配置文件中指定,如此id便支持任意数据类型)
*/
@IndexId(type = IdType.CUSTOMIZE)
private String id;
/**
* 文档标题,不指定类型默认被创建为keyword类型,可进行精确查询
*/
private String title;
/**
* 文档内容,指定了类型及存储/查询分词器
*/
@HighLight(mappingField = "highlightContent")
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String content;
// 省略其它字段...
}
@Test
public void testCreateIndexByEntity() {
// 然后通过该实体类的mapper直接一键创建,非常傻瓜级
documentMapper.createIndex();
}
提示
实体类中的注解用法可参考注解章节,整体比较傻瓜级,和MP中的注解用法高度相似.
方式二:通过api创建,每个需要被索引的字段都需要处理,比较繁琐,但灵活性最好,支持所有es能支持的所有索引创建,供0.01%场景使用(不推荐)
@Test
public void testCreatIndex() {
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
// 此处简单起见 索引名称须保持和实体类名称一致,字母小写 后面章节会教大家更如何灵活配置和使用索引
wrapper.indexName(Document.class.getSimpleName().toLowerCase());
// 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型,可缺省
// 支持分词查询,内容分词器可指定,查询分词器也可指定,,均可缺省或只指定其中之一,不指定则为ES默认分词器(standard)
wrapper.mapping(Document::getTitle, FieldType.KEYWORD)
.mapping(Document::getContent, FieldType.TEXT,Analyzer.IK_MAX_WORD,Analyzer.IK_MAX_WORD);
// 如果上述简单的mapping不能满足你业务需求,可自定义mapping
// wrapper.mapping(Map);
// 设置分片及副本信息,3个shards,2个replicas,可缺省
wrapper.settings(3,2);
// 如果上述简单的settings不能满足你业务需求,可自定义settings
// wrapper.settings(Settings);
// 设置别名信息,可缺省
String aliasName = "daily";
wrapper.createAlias(aliasName);
// 创建索引
boolean isOk = documentMapper.createIndex(wrapper);
Assert.assertTrue(isOk);
}
温馨提示
实体类中,id字段不需要创建索引,否则会报错.
由于ES索引改动自动重建的特性,因此本接口设计时将创建索引所需的mapping,settings,alias信息三合一了,尽管其中每一项配置都可缺省,但我们仍建议您在创建索引前提前规划好以上信息,可以规避后续修改带来的不必要麻烦,若后续确有修改,您仍可以通过别名迁移的方式(推荐,可平滑过渡),或删除原索引重新创建的方式进行修改
配置启用模式
以上三种模式的配置,您只需要在您项目的配置文件application.properties或application.yml中加入一行配置即可:
easy-es:
socketTimeout: 600000 # 请求通信超时时间 单位:ms 默认值600000ms 在平滑模式下,由于要迁移数据,用户可根据数据量大小调整此参数值大小,否则请求容易超时导致索引托管失败,建议您尽量给大不给小,跟那玩意一样,大点没事,太小你懂的!
global-config:
process_index_mode: smoothly #smoothly:平滑模式, not_smoothly:非平滑模式, manual:手动模式
async-process-index-blocking: true # 异步处理索引是否阻塞主线程 默认阻塞
distributed: false # 项目是否分布式环境部署,默认为true, 如果是单机运行可填false,将不加分布式锁,效率更高.
reindexTimeOutHours: 72 # 重建索引超时时间 单位小时,默认72H 根据迁移索引数据量大小灵活指定
若缺省此行配置,则默认开启平滑模式.
温馨提示
- 自动挡模式下,如果索引托管成功,则会在控制台打印 Congratulations auto process index by Easy-Es is done !
- 自动挡模式下,如果索引托管失败,则会在控制台打印 Unfortunately, auto process index by Easy-Es failed... 以及异常日志,可根据异常日志信息去排查
- 如果索引托管失败,此时用户调用了insert相关API插入数据,由于索引不存在,es(非框架)会自动为用户创建默认索引,创建的索引字段类型为keyword_text类型,并非用户通过注解指定的,因此出现这种情况别问我为啥没生效,因为索引托管因为你的配置或环境原有问题失败了.
- 运行测试模块时强烈建议开启异步处理索引阻塞主线程,否则测试用例跑完后,主线程退出,但异步线程可能还没跑完,可能出现死锁,若不幸出现死锁,删除ee-distribute-lock即可.
- 生产环境或迁移数据量比较大的情况下,可以配置开启非阻塞,这样服务启动更快.
- 以上三种模式,用户可根据实际需求灵活选择,自由体验,在使用过程中如有任何意见或建议可反馈给我们,我们将持续优化和改进,
- EE在索引托管采用了策略+工厂设计模式,未来如果有更多更优模式,可以在不改动原代码的基础上轻松完成拓展,符合开闭原则,也欢迎各路开源爱好者贡献更多模式PR!
- 我们将持续秉承把复杂留给框架,把易用留给用户这一理念,砥砺前行.
2,索引CRUD
提示
EE的索引在前面索引托管章节已有介绍,是支持自动化处理的.但仍有个别场景,用户期望自己来操作索引,也就是前面索引托管章节提到的手动挡模式, 此篇重点介绍手动挡模式下提供的所有API能力,帮助用户快速上手手动挡CRUD索引
前置配置
索引CRUD相关的API都属于手动挡范畴,因此我们执行下述所有API前必须先配置开启手动挡,以免和自动挡冲突.
easy-es:
global-config:
process_index_mode: manual # 手动挡模式
创建索引
API介绍
// 1.根据当前mapper对应实体类信息及其注解配置生成索引信息 适用于大多数场景
Boolean createIndex();
// 2.根据当前mapper对应实体类信息及其注解配置生成索引信息 可指定索引名进行创建 适用于定时任务按日期创建索引场景
Boolean createIndex(String indexName);
// 3.根据自定义条件创建索引
Boolean createIndex(Wrapper wrapper);
创建索引一共提供了上述三种方式,使用难度: 方式1 <= 方式2 < 方式3 , 灵活度 方式3 > 方式2 >= 方式1
使用案例:
/**
* 方式1
*/
@Test
public void testCreateIndexByEntity() {
// 绝大多数场景推荐使用 简单至上
documentMapper.createIndex();
}
/**
* 方式2
*/
@Test
public void testCreateIndexByEntity() {
// 适用于定时任务按日期创建索引场景
String indexName = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd"));
documentMapper.createIndex(indexName);
}
/**
* 方式3
*/
@Test
public void testCreateIndex() {
// 复杂场景使用
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
// 此处简单起见 索引名称须保持和实体类名称一致,字母小写 后面章节会教大家更如何灵活配置和使用索引
wrapper.indexName(Document.class.getSimpleName().toLowerCase());
// 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型(支持分词查询)
wrapper.mapping(Document::getTitle, FieldType.KEYWORD, 2.0f)
.mapping(Document::getLocation, FieldType.GEO_POINT)
.mapping(Document::getGeoLocation, FieldType.GEO_SHAPE)
.mapping(Document::getContent, FieldType.TEXT, Analyzer.IK_SMART, Analyzer.IK_MAX_WORD);
// 0.9.8+版本,增加对符串字段名称的支持,Document实体中须在对应字段上加上@Tablefield(value="wu-la")用于映射此字段值
wrapper.mapping("wu-la", FieldType.TEXT, Analyzer.IK_MAX_WORD, Analyzer.IK_MAX_WORD);
// 设置分片及副本信息,可缺省
wrapper.settings(3, 2);
// 设置别名信息,可缺省
String aliasName = "daily";
wrapper.createAlias(aliasName);
// 设置父子信息,若无父子文档关系则无需设置
wrapper.join("joinField", "document", "comment");
// 创建索引
boolean isOk = documentMapper.createIndex(wrapper);
Assertions.assertTrue(isOk);
}
/**
* 方式3 变体,使用难度最高,但灵活性也最高
*/
@Test
public void testCreateIndexByMap() {
// 演示通过自定义map创建索引,最为灵活 可支持es本身能支持的所有索引场景
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
wrapper.indexName(Document.class.getSimpleName().toLowerCase());
wrapper.settings(3, 2);
Map map = new HashMap<>();
Map prop = new HashMap<>();
Map field = new HashMap<>();
field.put("type", FieldType.KEYWORD.getType());
prop.put("this_is_field", field);
map.put("properties", prop);
wrapper.mapping(map);
boolean isOk = documentMapper.createIndex(wrapper);
Assertions.assertTrue(isOk);
}
查询索引
API介绍
// 是否存在索引
Boolean existsIndex(String indexName);
// 获取当前mapper对应索引信息
GetIndexResponse getIndex();
// 获取指定索引信息
GetIndexResponse getIndex(String indexName);
使用案例:
@Test
public void testExistsIndex() {
// 测试是否存在指定名称的索引
String indexName = Document.class.getSimpleName().toLowerCase();
boolean existsIndex = documentMapper.existsIndex(indexName);
Assertions.assertTrue(existsIndex);
}
@Test
public void testGetIndex() {
GetIndexResponse indexResponse = documentMapper.getIndex();
// 这里打印下索引结构信息 其它分片等信息皆可从indexResponse中取
indexResponse.getMappings().forEach((k, v) -> System.out.println(v.getSourceAsMap()));
}
更新索引
API介绍
// 根据条件更新索引
Boolean updateIndex(Wrapper wrapper);
使用案例:
/**
* 更新索引
*/
@Test
public void testUpdateIndex() {
// 测试更新索引
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
// 指定要更新哪个索引
String indexName = Document.class.getSimpleName().toLowerCase();
wrapper.indexName(indexName);
wrapper.mapping(Document::getCreator, FieldType.KEYWORD);
wrapper.mapping(Document::getGmtCreate, FieldType.DATE);
boolean isOk = documentMapper.updateIndex(wrapper);
Assertions.assertTrue(isOk);
}
3,动态索引
尽管我们的每个mapper已经可以决定当前CRUD作用的索引,用户根据不同的mapper就可以操作到不同的索引,这点和MP中不同mapper对应不同的表是一样的. 但是在ES中有一种场景,需要动态索引.例如某公司日志存放在ES中,但日志量极其庞大,并且使用方通常也只关注近三个月内的日志,因此按照年或者月建立索引, 不仅可以提升查询速度和性能,而且可以更好的归类数据.但是EE中的索引是通过@IndexName注解写在代码中的,这就导致用户在想切换索引时还需要重新改代码 并重启项目,这显然不是一个好的解决方案,因此我们额外提供了对动态索引的支持.
-
方式1 直接设置当前mapper对应的索引名 简单粗暴
-
@Test public void testActiveIndex(){ // 设置当前mapper对应的索引 比如原索引名叫document, 设置以后 documentMapper对应的所有CRUD作用的索引将变更为指定的索引名,例如 '2023-03-11' String indexName = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd")); documentMapper.setCurrentActiveIndex(indexName); }
提示
此方案虽然简单粗暴又省事,但有两个细节需要注意:
- 不支持分布式环境,因为每个mapper作用的索引是存在jvm缓存中,当前设置操作仅能作用于当前机器,如果要支持分布式环境,则需要用户对每台机器都执行此方法
- 不保证原子性,该操作在执行索引变更时若有其它线程在执行数据的CRUD,并不会阻塞其它线程执行CRUD,因此在高并发场景下,无法保证原子性.
-
方式2 通过wrapper或mapper中具体的方法传入索引名 粒度最细
-
@Test public void testSelect() { // 支持设置多个查询的索引,用逗号隔开即可 LambdaEsQueryWrapperwrapper = new LambdaEsQueryWrapper<>(); wrapper.eq(Document::getTitle, "老汉") .index("你要查询的索引名1","你想查询的索引名2"); Document document = documentMapper.selectOne(wrapper); System.out.println(document); } @Test public void testInsert() { // 像插入,更新等一些没有wrapper的情况,在mapper中都有提供方法重载,可以直接传入索引名 Document document = new Document(); document.setEsId("5"); document.setTitle("老汉"); // 支持设置多个查询的索引,用逗号隔开即可 int successCount = documentMapper.insert(document,"你想插入的索引名1","你想插入的索引名2"); Assertions.assertEquals(successCount, 1); } 落地方案
前面章节我们介绍了手动挡创建索引的API,配合此处提供的索引激活方案就可以轻而易举实现动态索引了
@Test
public void testCreateIndexByEntity() {
// 适用于定时任务按日期创建索引场景
String indexName = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd"));
documentMapper.createIndex(indexName);
}
-
1.写定时任务调用创建索引API创建索引,索引名以你想要的日期格式进行生成并将索引名置入redis缓存
-
2.生成完成后,全局设置当前mapper对应索引名为redis中存入的最新索引名 或者在CRUD时从redis去取最新索引名
当然上面仅是提供一种可行的参考方案,用户还可以根据API提供的能力结合自己项目的特性去设计个性化解决方案.
4,数据同步方案
背景
有不少小伙伴在社区答疑群问我怎么把数据从MySQL同步到ES?想回答好这个问题,需要结合具体的业务场景和数据量以 及具体的开发人数,不同的情况有不同的方案, 就像做菜撒盐一样,我没法直接回答你们,我只能给出一些可行性的方案, 用户可结合自己公司情况,综合考虑
全量同步
顾名思义,就是把现有数据库中的数据全部同步到ES中,通常用是在首次接入ES时,需要初始化全量数据.全量同步可以 考虑 ES官方的Logstash,以及阿里开源的DataX,当然如果你数据量少于千万级别,且数据本身也比较小,想图个简单 省事,使用Easy-Es提供的insertBatch(Collection data)方法批量插入也未尝不可
增量同步
当数据全量同步完成后,用户开始使用ES,此后伴随这数据的CRUD,我们需要把这些数据的变化同步到ES,以确保ES中 的数据实效性,谓之增量同步. 比较成熟的解决方案有阿里开源的Canal,当然你也可以用MQ,甚至本地消息事件(例如 Guava的Event-Bus,springboot自带的Event),根据你的业务数量以及部署机器是否分布式环境等综合考虑选择 适合的方案,上述解决方案原理都类似,基本上都是有MySQL数据变更(增/删/改)时发布消息,然后订阅方订阅到该消 息事件后,将数据变更同步至ES,如此便可以解耦.如果你们并发不算太高,数据量变动也不大的话,用Easy-Es提供的 批量CRUD方法也可以,你可以从MP查出来变更的数据让后调用下方的API完成数据变更,下面API和MP一致,不再介绍.
Integer updateBatchByIds(Collection entityList);
Integer deleteBatchIds(Collection idList);
Integer insertBatch(Collection entityList);
Integer delete(Wrapper wrapper);
提示
在正式同步前,请务必先规划和设计好你的索引结构,分片及副本等索引信息, 由于ES索引发生改变后就得重建索引, 重迁数据,耗时耗力,所以千万不要操之过急,否则你可能一夜回到解放前!
另外上述方案都是一些参考方案,如果你们有找到更好的解决方案也欢迎尝试,而且我这里并不会介绍每种方案具体的 实现,都是成熟的开源组件,大家不会请问度娘或者ChatGPT.
5,数据CRUD
Mapper CRUD 接口
说明
- 通用 CRUD 封装BaseEsMapper (opens new window)接口,为 Easy-Es 启动时自动解析实体对象关系映射转换为 EE 内部对象注入容器
- 泛型 T 为任意实体对象
- insert接口需要区别于MP,具体可看下面insert文档
- 参数 Serializable 为任意类型主键 Easy-Es 不推荐使用复合主键约定每个索引都有自己的唯一 id 主键
- 对象 Wrapper 为 条件构造器
- 针对实体对象T中的
get和set方法,我们推荐您使用Lombok (opens new window)插件生成,若您采用IDEA自带插件生成,通过Lambda风格获取的字段名称时,会导致部分驼峰命名的字段无法获取正确的字段名. 比如有字段名称叫eName,采用Lombok生成的的get方法为getEName(),但IDEA生成的为geteName(),如此框架底层解析字段名称时就会报错,MP也存在同样问题.
Insert
// 插入一条记录,默认插入至当前mapper对应的索引
Integer insert(T entity);
// 插入一条记录 可指定具体插入的索引,多个用逗号隔开
Integer insert(T entity, String... indexNames);
// 批量插入多条记录
Integer insertBatch(Collection entityList)
// 批量插入多条记录 可指定具体插入的索引,多个用逗号隔开
Integer insertBatch(Collection entityList, String... indexNames);
特别注意
- 如果您在insert时传入的entity有id并且该id对应数据已存在,则此次insert实际效果为更新该id对应的数据,并且更新不计入insert接口最后返回的成功总条数.
- 当insert接口如上所述,触发了数据更新逻辑,本次更新字段和全局配置的策略(如NOT_NULL/NOT_EMPTY)等均不生效,若您期望策略生效,可以调用update接口而非insert接口.
- 插入后如需id值可直接从entity中取,用法和MP中一致,批量插入亦可直接从原对象中获取插入成功后的数据id,以上接口返回Integer为成功条数.
Delete
// 根据 ID 删除
Integer deleteById(Serializable id);
// 根据 ID 删除 可指定具体的索引,多个用逗号隔开
Integer deleteById(Serializable id, String... indexNames);
// 根据 entity 条件,删除记录
Integer delete(LambdaEsQueryWrapper wrapper);
// 删除(根据ID 批量删除)
Integer deleteBatchIds(Collection idList);
// 删除(根据ID 批量删除)可指定具体的索引,多个用逗号隔开
Integer deleteBatchIds(Collection idList, String... indexNames);
Update
//根据 ID 更新
Integer updateById(T entity);
//根据 ID 更新 可指定具体的索引,多个用逗号隔开
Integer updateById(T entity, String... indexNames);
// 根据ID 批量更新
Integer updateBatchByIds(Collection entityList);
//根据 ID 批量更新 可指定具体的索引,多个用逗号隔开
Integer updateBatchByIds(Collection entityList, String... indexNames);
// 根据动态条件 更新记录
Integer update(T entity, LambdaEsUpdateWrapper updateWrapper);
Select
// 获取总数
Long selectCount(LambdaEsQueryWrapper wrapper);
// 获取总数 distinct为是否去重 若为ture则必须在wrapper中指定去重字段
Long selectCount(Wrapper wrapper, boolean distinct);
// 根据 ID 查询
T selectById(Serializable id);
// 根据 ID 查询 可指定具体的索引,多个用逗号隔开
T selectById(Serializable id, String... indexNames);
// 查询(根据ID 批量查询)
List selectBatchIds(Collection idList);
// 查询(根据ID 批量查询)可指定具体的索引,多个用逗号隔开
List selectBatchIds(Collection idList, String... indexNames);
// 根据动态查询条件,查询一条记录 若存在多条记录 会报错
T selectOne(LambdaEsQueryWrapper wrapper);
// 根据动态查询条件,查询全部记录
List selectList(LambdaEsQueryWrapper wrapper);
提示
- CRUD接口用法基本与MP一致
- 用户需要继承的Mapper为BaseEsMapper,而非BaseMapper
- EE没有提供Service层,而是把MP中一些Service层的方法直接下沉到Mapper层了,用户用起来会更方便
6,四大嵌套查询
背景
MySQL和ES在嵌套查询这块有非常大的差异,所以在2.0版本中特地梳理此章节,帮助各位主公快速了解它们之间的差异并上手
提示
其中MP中已经有的在Easy-Es中用法和功能和它保持一致,降低用户学习及使用成本,只需要学习MP中没有,ES中独有的即可
ES四大嵌套查询
| MySQL | Mybatis-Plus | ES | Easy-Es |
|---|---|---|---|
| and 嵌套 | and(Consumer) | must | and(Consumer) |
| or 嵌套 | or (Consumer) | should | or (Consumer) |
| 无 | 无 | filter | filter(Consumer) |
| 无 | 无 | must_not | not(Consumer) |
ES四大拼接查询
| MySQL | Mybatis-Plus | ES | Easy-Es |
|---|---|---|---|
| and 拼接 | 默认 | must | 默认 |
| or 拼接 | or() | should | or() |
| 无 | 无 | filter | filter() |
| 无 | 无 | must_not | not() |
提示
如果您有用过MP,理解上面的差异就比较简单,如果您尚未用过MP也没关系,咱只需要搞清楚嵌套类型与拼接类型的差异即可. 另外关于must和filter的选择,它们在功能上类似,都是表示必须满足的条件,不同之处在于filter不计算得分,性能表现更好,但不支持根据得分排序
嵌套与拼接如何理解和使用
简单来说,嵌套就是有括号的,拼接就是无括号的,或者说嵌套就是里面有东西的,拼接是里面没东西的,怎么理解这段话呢?以大家熟悉的MySQL中的一段SQL为例:
// 这里面的or就是拼接or
where name = '老汉' or name = '痴汉';
// 用MP或EE来写就是
wrapper.eq(name,"老汉").or().eq(name,"老汉");
// 这里面的or是嵌套or
where name = '老汉' or (age = 18 and size = 18)
// 用MP或EE来写就是
wrapper.eq(name,"老汉").or(i->i.eq(age,18).eq(size,18));
通过上面的例子大家应该很好理解拼接和嵌套的差异了,对应到es中,嵌套就是把嵌套中的所有查询条件封装进一个新创建的boolQuery中,然后拼接至根boolQuery,而拼接则是把查询条件直接拼接进根boolQuery中. 在EE中条件与条件直接默认的拼接方式是以and拼接,由于95%的使用场景都是and拼接,所以直接省略了and这种拼接,这点和MP一样
// sql
where name = '老汉' and size = 18
// 用EE或者MP可以直接写为
wrapper.eq(name,"老汉").eq(size,18)
如果你需要改写默认的拼接方式只需要加上对应的拼接类型即可,例如:
// sql
where name = '老汉' or size = 18
// 用EE直接写为
wrapper.eq(name,"老汉").or().eq(size,18);
// sql
where name = '老汉' and age != 18
// 用EE写为
wrapper.eq(name,"老汉").not().eq(age,18);
// 所有表'非'的条件都可以用not()来拼接
wrapper.eq(name,"老汉").not().eq(age,18).not().match(desc,'是个纯洁的好男人');
优势对比
相比MySQL只有2中类型嵌套,ES一共有4种,并且在封装方式上差异也非常大,MySQL中的查询条件是以FIFO队列的形式进行封装 但ES中是以树形结构的形式进行封装,在层级比较深的查询中,其难度和复杂程度就算是ES老手也容易搞错,好在有了Easy-Es, 您又可以重回MP时代,大幅减少开发负担和出错的可能,为了保持和MP一样的语法,又要屏蔽ES和MySQL之间巨大的差异,这块 内容我花了近一年的碎片时间才完成,是整个框架中最难啃的一块骨头,不过一切都是值得的,不信咱们接着往下看.
下面我们以一段具体的复杂查询使用案例来对比,优势一目了然:
// MySQL语法
where business_type = 1
and (state = 9 or (state = 8 and bidding_sign = 1))
or (business_type = 2 and state in (2,3));
// Easy-Es及Mybatis-Plus语法
wrapper.eq("business_type", 1)
.and(a -> a.eq("state", 9).or(b -> b.eq("state", 8).eq("bidding_sign", 1)))
.or(i -> i.eq("business_type", 2).in("state", 2, 3));
// ES原生的RestHighLevel语法
List values = Arrays.asList(2, 3);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termQuery("business_type", 1));
boolQueryBuilder.must(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("state", 9))
.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("state", 8))
.must(QueryBuilders.termQuery("bidding_sign", 1))));
boolQueryBuilder.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("business_type", 2))
.must(QueryBuilders.termsQuery("state", values)));
上面的例子树的最大深度仅为2,如果深度超过2以后ES原生语法就很难看得懂了,更别说正确编码,就算您是ES老手也容易栽坑里,但使用EASY-ES则可以1:1轻松又简单还原复杂SQL
使用示例:
/**
* 场景一: 嵌套and的使用
*/
@Test
public void testNestedAnd() {
// 下面查询条件等价于MySQL中的 select * from document where star_num in (1, 2) and (title = '老汉' or title = '推*')
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.in(Document::getStarNum, 1, 2)
.and(w -> w.eq(Document::getTitle, "老汉").or().eq(Document::getTitle, "推*"));
List documents = documentMapper.selectList(wrapper);
}
/**
* 场景二: 拼接and的使用
*/
@Test
public void testAnd(){
// 下面查询条件等价于MySQL中的 select * from document where title = '老汉' and content like '推*'
// 拼接and比较特殊,因为使用场景最多,所以条件与条件之间默认就是拼接and,所以可以直接省略,这点和MP是一样的
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
List documents = documentMapper.selectList(wrapper);
}
/**
* 场景二: 嵌套or的使用
*/
@Test
public void testNestedOr() {
// 下面查询条件等价于MySQL中的 select * from document where star_num = 1 or (title = '老汉' and creator = '糟老头子')
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getStarNum, 1)
.or(i -> i.eq(Document::getTitle, "老汉").eq(Document::getCreator, "糟老头子"));
List documents = documentMapper.selectList(wrapper);
}
/**
* 场景三: 拼接or的使用
*/
@Test
public void testOr() {
// 下面查询条件等价于MySQL中的 select * from document where title = '老汉' or title = '痴汉'
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.or()
.eq(Document::getTitle, "痴汉");
List documents = documentMapper.selectList(wrapper);
}
/**
* 场景四: 嵌套filter的使用 其实和场景一一样,只不过filter中的条件不计算得分,无法按得分排序,查询性能稍高
*/
@Test
public void testNestedFilter() {
// 下面查询条件等价于MySQL中的 select * from document where star_num in (1, 2) and (title = '老汉' or title = '推*')
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.in(Document::getStarNum, 1, 2)
.filter(w -> w.eq(Document::getTitle, "老汉").or().eq(Document::getTitle, "推*"));
List documents = documentMapper.selectList(wrapper);
}
/**
* 场景五: 拼接filter的使用 filter中的条件不计算得分,无法按得分排序,查询性能稍高
*/
@Test
public void testFilter() {
// 下面查询条件等价于MySQL中的 select * from document where title = '老汉'
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.filter().eq(Document::getTitle, "老汉");
List documents = documentMapper.selectList(wrapper);
}
/**
* 场景六: 嵌套mustNot的使用
*/
@Test
public void testNestedNot() {
// 下面查询条件等价于MySQL中的 select * from document where title = '老汉' and (size != 18 and age != 18)
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.not(i->i.eq(size,18).eq(age,18));
List documents = documentMapper.selectList(wrapper);
}
/**
* 场景六: 拼接not()的使用
*/
@Test
public void testNot() {
// 下面查询条件等价于MySQL中的 select * from document where title = '老汉' and size != 18
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.not()
.eq(size,18);
List documents = documentMapper.selectList(wrapper);
}
7,链式调用
链式优势
- 代码整洁,可读性高,易于维护.
- 显著减少代码量,"代码逼格高",隔壁老汉在年度述职时得意地说:那年我双手插兜,略微出手,一行代码就搞定所有!
- 编码爽,对于开发者而言,链式有一个非常明显的优势就是写代码很爽,配合编辑器的友好提示可以快速通过下拉+回车完成编码,这种感觉就像领导都喜欢做选择题而不是填空题!
链式构造
条件构造器及其中的方法本就是支持Lambda+链式调用的,但为了进一步提高链式程度,让隔壁老汉能实现在年会上装13的需求, 我们针对每一种条件构造器都提供了链式构造的方法
// 索引链式构造器
LambdaEsIndexChainWrapper lambdaChainIndex(BaseEsMapper baseEsMapper);
// 查询链式构造器
LambdaEsQueryChainWrapper lambdaChainQuery(BaseEsMapper baseEsMapper);
// 更新(含删除)链式构造器
LambdaEsUpdateChainWrapper lambdaChainUpdate(BaseEsMapper baseEsMapper);
使用案例
@Test
public void testOne() {
// 隔壁老汉写的链式调用
Document document = EsWrappers.lambdaChainQuery(documentMapper).eq(Document::getTitle, "隔壁老汉").one();
}
@Test
public void testSelectOne() {
// 隔壁老王写的半吊子链式调用
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "隔壁老王")
.limit(1);
Document document = documentMapper.selectOne(wrapper);
}
三,扩展功能
1,何为混合查询?
简单理解,就是一半采用EE的语法,一半采用RestHighLevelClient的语法,类似"油电混动",相信你会爱上这种"油电混动"模式,因为它结合了两种模式的优点!
2,为什么要有混合查询?
因为EE目前还没有做到对RestHighLevelClient的功能100%覆盖,目前经过一年多的发展,我们覆盖了RestHighLevelClient约90%左右的API,和99.9%的核心高频使用功能,如此就不可避免的会出现个别场景下,EE不能满足某个特殊需求,此时对EE框架进行二次开发或直接将该需求提给EE作者,在时间上都无法满足开发者需求,有些需求可能产品经理要的比较紧,那么此时,您就可以通过混合查询来解决窘境. 其次,在API设计上其实支持的功能越多越复杂,用户使用起来就越难,这两者是鱼与熊掌,很难兼得,RestHighLevelClient并非有意把API设计的如此难用,他们也非常不容易,复杂的地方光是参数就有上千种排列组合方式,所以我们也无法通过方法重载来简化API使用,即便我们支持了,届时API也会极度臃肿,找一个您想调用的方法更是难上加难,一样会被您无情吐槽,因此我们只简化了99.9%的高频核心API, 其它的低频API,需要您通过混合查询来实现
3,如何使用混合查询?
在我没提供此篇文档时,尽管我提供了混合查询的API和简单介绍,但很多人还不知道有此功能,更不知道该如何使用,所以这里我以一个具体的案例,给大家演示如何使用混合查询,供大家参考,主公们别担心篇幅多,其实非常非常简单,只是我教程写的细.
以上面打车的场景为例,我们来看下用EE怎么查询?上面查询可以分为两部分
- EE支持的常规查询:如周围3公里内,司机性别为女,查询驾龄>=3年...
- EE不支持的非常规查询:按照复杂的排序规则排序(写此篇文档时是不支持的,现已支持,但这不重要,本篇仅以此来演示混合查询的使用)
对于支持的部分,我们可以直接调用EE,由EE先构建一个SearchSourceBuilder出来
// 假设该乘客所在位置经纬度为 31.256224D, 121.462311D
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.geoDistance(Driver::getLocation, 3.0, DistanceUnit.KILOMETERS, new GeoPoint(31.256224D, 121.462311D))
.eq(Driver::getGender,"女")
.ge(Driver::getDriverAge,3)
.eq(Driver::getCarModel,"商务车");
SearchSourceBuilder searchSourceBuilder = driverMapper.getSearchSourceBuilder(wrapper);
对于不支持的语句,可以继续用RestHighLevelClient的语法进行封装,封装好了,直接调用EE提供的混合查询接口,就可以完成整个查询.
// 此处的searchSourceBuilder由上面EE构建而来,我们继续对其追加排序参数
searchSourceBuilder.sort(
new GeoDistanceSortBuilder("location", 31.256224D, 121.462311D)
.order(SortOrder.DESC)
.unit(DistanceUnit.KILOMETERS)
.geoDistance(GeoDistance.ARC)
);
wrapper.setSearchSourceBuilder(searchSourceBuilder);
List drivers = driverMapper.selectList(wrapper);
4,混合查询的几种正确使用姿势
使用案例:
/**
* 正确使用姿势0(最实用,最简单,最推荐的使用姿势):EE满足的语法,直接用,不满足的可以构造原生QueryBuilder,然后通过wrapper.mix传入QueryBuilder
* @since 2.0.0-beta2 2.0.0-beta2才正式引入此方案,此方案为混合查询的最优解决方案,由于QueryBuilder涵盖了ES中全部的查询,所以通过此方案
* 理论上可以处理任何复杂查询,并且可以和EE提供的四大嵌套类型无缝衔接,彻底简化查询,解放生产力!
*/
@Test
public void testMix0(){
// 查询标题为老汉,内容匹配 推*,且最小匹配度不低于80%的数据
// 当前我们提供的开箱即用match并不支持设置最小匹配度,此时就可以自己去构造一个matchQueryBuilder来实现
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
QueryBuilder queryBuilder = QueryBuilders.matchQuery("content", "推*").minimumShouldMatch("80%");
wrapper.eq(Document::getTitle,"老汉").mix(queryBuilder);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 混合查询正确使用姿势1: EE提供的功能不支持某些过细粒度的功能,所有查询条件通过原生语法构造,仅利用EE提供的数据解析功能
*/
@Test
public void testMix1() {
// RestHighLevelClient原生语法
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("content", "推*").minimumShouldMatch("80%"));
// 仅利用EE查询并解析数据功能
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.setSearchSourceBuilder(searchSourceBuilder);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 混合查询正确使用姿势2: 其它都能支持,仅排序器不支持,这种情况可以只按ES原生语法构造所需排序器SortBuilder,其它用EE完成
*/
@Test
public void testMix2() {
// EE满足的语法
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
// RestHighLevelClient原生语法
Script script = new Script("doc['star_num'].value");
ScriptSortBuilder scriptSortBuilder = SortBuilders.scriptSort(script,ScriptSortBuilder.ScriptSortType.NUMBER).order(SortOrder.DESC);
// 利用EE查询并解析数据
wrapper.sort(scriptSortBuilder);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 混合查询正确使用姿势3: 其它功能都能支持,但需要向SearchSourceBuilder中追加非query参数
*/
@Test
public void testMix3() {
// EE满足的语法
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
SearchSourceBuilder searchSourceBuilder = documentMapper.getSearchSourceBuilder(wrapper);
// 追加或者设置一些SearchSourceBuilder支持但EE暂不支持的参数 不建议追加query参数,因为如果追加query参数会直接覆盖上面EE已经帮你生成好的query,以最后set的query为准
searchSourceBuilder.timeout(TimeValue.timeValueSeconds(3L));
wrapper.setSearchSourceBuilder(searchSourceBuilder);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 查询条件中可以利用大多数基本查询,但EE提供的聚合功能不能满足需求的情况下,需要自定义聚合器
*/
@Test
public void textMix4() {
// EE满足的语法
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
SearchSourceBuilder searchSourceBuilder = documentMapper.getSearchSourceBuilder(wrapper);
// RestHighLevelClient原生语法
AggregationBuilder aggregation = AggregationBuilders.terms("titleAgg")
.field("title");
searchSourceBuilder.aggregation(aggregation);
wrapper.setSearchSourceBuilder(searchSourceBuilder);
SearchResponse searchResponse = documentMapper.search(wrapper);
// TODO 聚合后的信息是动态的,框架无法解析,需要用户根据聚合器类型自行从桶中解析,参考RestHighLevelClient官方Aggregation解析文档
}
5,混合查询错误的使用姿势
EE支持的混合查询使用方案我已经全部列在上面正确的使用姿势中了,已经能涵盖任何一种使用场景了, 请勿凭空捏造凭空想象然后按自己认为没问题的方式来写.
下面就演示两种典型的不支持场景:
/**
* 不支持的混合查询1: 追加覆盖问题
*/
@Test
public void textNotSupportMix() {
// EE满足的语法
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
SearchSourceBuilder searchSourceBuilder = documentMapper.getSearchSourceBuilder(wrapper);
// 用户又想在上面的基础上,再追加一些个性化的查询参数进去 但实际上此时执行查询时,查询条件仅仅是最后设置的title=隔壁老王,前面的老汉推*会被覆盖
searchSourceBuilder.query(QueryBuilders.matchQuery("title", "隔壁老王"));
wrapper.setSearchSourceBuilder(searchSourceBuilder);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
// 思考: 为什么会被覆盖? 因为目前技术上做不到,查询树已经建立好了,es底层并没有提供向树的指定层级上继续追加查询条件的API
}
/**
* 不支持的混合查询2: 脱裤子放P 自欺欺人系列
*/
@Test
public void testNotSupportMix2() {
// EE满足的语法
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
// SearchSourceBuilder的构造是自己new出来的,不是通过mapper.getSearchSourceBuilder(wrapper)构造 相当于脱裤子放P,那么上面的查询条件老汉推*自然不会生效
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.minScore(10.5f);
wrapper.setSearchSourceBuilder(searchSourceBuilder);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
6,原生查询
API
// 半原生查询(也可以归于混合查询,通常在自定义聚合Aggregation时使用)
SearchResponse search(LambdaEsQueryWrapper wrapper) throws IOException;
// 标准原生查询 可指定 RequestOptions
SearchResponse search(SearchRequest searchRequest, RequestOptions requestOptions) throws IOException;
温馨提示
对于混合查询仍无法解决的场景,您可以调用我们提供的标准原生查询方法进行查询,入参和返回均为RestHighLevelClient原生,和直接使用RestHighLevelClient查询一致 如果您需要在代码中用到RestHighLevelClient,您可以直接使用@Autowired注解注入使用,EE已经帮您自动配置了该bean.
@Service
public class xxxService{
// 在需要的地方直接注入即可
@Autowried
private RestHighLevelClient restHighLevelClient;
}
如果您连EE自动装配的RestHighLevelClient都需要自定义,那我们也是支持的,因为我们在自动装配的类上加了@ConditionalOnClass(RestHighLevelClient.class)注解, 如果您已经自己配置了RestHighLevelClient,那么框架则以您配置的RestHighLevelClient为准,EE为您提供了极致的灵活度和拓展性,确保用得放心.
7,分页查询
关于分页,我们支持了ES的三种分页模式,大家可参考下表,按需选择.
| 分页方式 | 性能 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| from+size 浅分页 | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll 滚动查询 | 中 | 解决了深度分页问题 | 无法反应数据的实时性 | 海量数据的导出需要查询海量结果集的数据 |
| search_after | 高 | 性能最好,不存在深度分页问题,能够反应数据的实时变化 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果,它不适用于大幅度跳页查询 | 海量数据的分页 |
浅分页
// 物理分页
EsPageInfo pageQuery(LambdaEsQueryWrapper wrapper, Integer pageNum, Integer pageSize);
温馨提示
无需集成任何插件,即可使用分页查询,本查询属于物理分页,基于size+from的浅分页模式,适用于查询数据量少于1万的情况,如您需要 在一些高阶语法的使用场景中,目前已知的有聚合字段的返回,我们分页器尚不能支持,需要您自己封装分页,其它场景基本都能完美支持,用起来无比简单. 注意PageInfo是由本框架提供的,如果你项目中已经有目前最受欢迎的开源分页插件PageHelper,请在引入包的时候注意别引入错误了,EE采用和PageHelper一样的返回字段,您无需担心字段名称不统一带来的额外工作量.
使用示例:
@Test
public void testPageQuery() {
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getTitle, "老汉");
EsPageInfo documentPageInfo = documentMapper.pageQuery(wrapper,1,10);
System.out.println(documentPageInfo);
}
滚动查询
// 滚动查询
SearchResponse scroll(SearchScrollRequest searchScrollRequest, RequestOptions requestOptions) throws IOException;
提示
若您有需要进行超大量的数据查询和分页需求,可以采用滚动查询来实现,关于滚动查询,我们实际上已经提供了getSearchSourceBuilderAPI用于快速构造出SearchSourceBuilder,配合上面提供的滚动查询API,助力您快速实现滚动查询 当然我们更建议您使用下面searchAfter方式分页,不仅API封装得更好,使用更简单,而且具有其它天然优势。
searchAfter
使用示例
@Test
public void testSearchAfter() {
LambdaEsQueryWrapper lambdaEsQueryWrapper = EsWrappers.lambdaQuery(Document.class);
lambdaEsQueryWrapper.size(10);
// 必须指定一种排序规则,且排序字段值必须唯一 此处我选择用id进行排序 实际可根据业务场景自由指定,不推荐用创建时间,因为可能会相同
lambdaEsQueryWrapper.orderByDesc(Document::getId);
SAPageInfo saPageInfo = documentMapper.searchAfterPage(lambdaEsQueryWrapper, null, 10);
// 第一页
System.out.println(saPageInfo);
Assertions.assertEquals(10, saPageInfo.getList().size());
// 获取下一页
List 8,嵌套类型
前言
在MySQL以及其它关系型数据库中,表与表之间相互关联可以用JOIN来实现,但ES中并没有JOIN,所以想要处理这种关联关系就需要了解嵌套类型和大宽表.
ES底层是Lucene,由于Lucene实际上是不支持嵌套类型的,所有文档都是以扁平的结构存储在Lucene中,ES对嵌套文档的支持,实际上也是采取了一种投机取巧的方式实现的.
嵌套的文档均以独立的文档存入,然后添加关联关系,这就会导致,一条嵌套类型的文档,底层实际上存储了N条数据,而且更新时会株连九族式更新,导致效率低下.
对于嵌套类型, 我们并不建议您使用,除非万不得已,因为引入嵌套类型后,您后续的CRUD都会变得非常复杂,如果有嵌套+聚合的需求,其编码复杂度会让你怀疑人生.
ES本身更适合"大宽表"模式,不要带着传统关系型数据库那种思维方式去使用ES,我们完全可以通过把多张表中的字段和内容合并到一张表(一个索引)中,来完成期望功能,尽可能规避嵌套类型的使用,不仅效率高,功能也更强大.
当然存在即合理,也确实有个别场景下,不可避免的会用到嵌套类型,作为全球首屈一指的ES-ORM框架,我们对此也提供了支持,用户可以不用,但我们不能没有
嵌套类型创建索引
-
自动挡模式:
按照下述配置,配置完成后直接启动项目,框架自动完成索引创建/更新
public class Document{
// 省略其它字段...
/**
* 嵌套类型
*/
@IndexField(fieldType = FieldType.NESTED, nestedClass = User.class)
private List users;
}
注意
务必像上面示例一样指定类型为fieldType=NESTED及其nestedClass,否则会导致框架无法正常运行
-
手动挡模式
方式一:按照自动挡模式,配置好注解,然后直接调用一键生成API生成索引
documentMapper.createIndex();
方式二:纯手工打造,所有字段自己安排一遍,不推荐,麻烦得很
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
// 省略其它代码
wrapper.mapping(Document::getUsers, FieldType.NESTED);
注意
在手动挡模式下,除了要通过注解@TableField指定nestedClass外,还需要通过wrapper指定该嵌套字段,然后完成索引创建/更新
嵌套类型 CRUD
nested(String path, Consumer consumer);
nested(String path, Consumer consumer, ScoreMode scoreMode);
nested(boolean condition, String path, Consumer consumer);
nested(boolean condition, String path, Consumer consumer, ScoreMode scoreMode);
提示
其中path为当前查询对象字段名,例如我在Document对象中嵌套了User数组,字段名为users,又在User对象中嵌套了Faq数组,当我需要去查询User中满足 某些指定条件的数据时,传入的path就为字符串"users" 当我需要查询Faq中满足某些指定条件的数据时,则传入的path为字符串"users.faq" 另外字段的获取方式如果要采取Lambda方式获取,可以使用FieldUtils.val(R column)工具类获取.
查询示例:
@Test
public void testNestedMatch() {
// 嵌套查询 查询年龄等于18或8,且密码等于123的数据
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.nested("users", w ->
w.in(FieldUtils.val(User::getAge), 18, 8)
.eq(FieldUtils.val(User::getPassword), "123"));
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
// 嵌套查询 查询年龄满足18或者问题名称匹配'size也18吗'的全部数据
LambdaEsQueryWrapper wrapper2 = new LambdaEsQueryWrapper<>();
wrapper2.nested("users", w -> w.in("age", 18))
.or()
.nested("users.faqs", w -> w.match("faq_name", "size也18吗"));
List documents2 = documentMapper.selectList(wrapper2);
}
9,Join父子类型
前言
ES底层是Lucene,由于Lucene实际上是不支持嵌套类型的,所有文档都是以扁平的结构存储在Lucene中,ES对父子文档的支持,实际上也是采取了一种投机取巧的方式实现的.
父子文档均以独立的文档存入,然后添加关联关系,且父子文档必须在同一分片,由于父子类型文档并没有减少文档数量,而且增加了父子绑定关系,会导致查询效率低下,因此我们并不建议您在实际开发中使用父子类型.
ES本身更适合"大宽表"模式,不要带着传统关系型数据库那种思维方式去使用ES,我们完全可以通过把多张表中的字段和内容合并到一张表(一个索引)中,来完成期望功能,尽可能规避父子类型的使用,不仅效率高,功能也更强大.
当然存在即合理,也确实有个别场景下,不可避免的会用到父子类型,作为全球首屈一指的ES-ORM框架,我们对此也提供了支持,用户可以不用,但我们不能没有!
关于父子类型和嵌套类型的选择:如果对文档的写多于读,那么建议你选择父子类型,如果文档读多于写, 那么请选择嵌套类型
父子类型创建索引
-
自动挡模式:
/**
* 父文档
*/
@IndexName(childClass = Comment.class)
public class Document{
// 省略其它字段...
/**
* 须通过注解在父文档及子文档的实体类中指明其类型为Join,及其父名称和子名称,这里的JoinField类框架已内置,无需重复造轮子
* JoinField类全路径为cn.easyes.common.params.JoinField,如果你非要自己造轮子,也支持,那么需要在@TableField注解中指明joinFieldClass=你造的轮子
*/
@IndexField(fieldType = FieldType.JOIN, parentName = "document", childName = "comment")
private JoinField joinField;
}
/**
* 子文档
*/
@IndexName(child = true)
public class Comment {
// 省略其它字段...
/**
* 父子关系字段 须通过注解在父文档及子文档的实体类中指明其类型为Join,子文档中的父子关系可省略
*/
@IndexField(fieldType = FieldType.JOIN)
private JoinField joinField;
}
注意: 务必像上面示例一样,在父文档的类上加注解@TableName指明其子文档类,在子文档的类上加注解@TableName,指明child=true,并在JoinField类的@TableField注解中指定类型为fieldType=JOIN及其parentName,childName,否则会导致框架无法正常工作
-
手动挡模式
-
方式一: 按照自动挡模式,配置好注解,然后直接调用一键生成API生成索引
documentMapper.createIndex();
-
方式二: 纯手工打造,所有字段自己安排一遍,不推荐,麻烦得很
LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
// 省略其它代码
wrapper.join("joinField", "document", "comment");
注意
在手动挡模式下,主类上的注解依然不能少,框架运行时需要用到父子关系,在方式二还需要通过wrapper指定该嵌套字段,然后完成索引创建/更新
父子类型 CRUD
注意父子类型由于都是独立的文档,独立的实体类,所以各自都需要有各自的mapper
CRUD示例
@Test
public void testInsert() {
// 测试新增父子文档,此处开启自动挡模式,父子类型索引已被自动处理
// 新新增父文档,然后再插入子文档
Document document = new Document();
document.setId("1");
document.setTitle("父文档的标题");
document.setContent("父文档的内容");
JoinField joinField = new JoinField();
joinField.setName("document");
document.setJoinField(joinField);
documentMapper.insert(document);
// 插入子文档
Comment comment = new Comment();
comment.setId("2");
comment.setCommentContent("文档的评论1");
// 这里特别注意,子文档必须指定其父文档的id,否则找不到父文档别怪我没提醒
joinField.setParent("1");
joinField.setName("comment");
comment.setJoinField(joinField);
commentMapper.insert(comment);
// 插入子文档2
Comment comment1 = new Comment();
comment1.setId("3");
comment1.setCommentContent("文档的评论2");
comment1.setJoinField(joinField);
commentMapper.insert(comment1);
}
@Test
public void testSelect() {
// 温馨提示,下面wrapper中的type实际上就是JoinField字段注解@TableField中指定的parentName和childName,与原生语法是一致的
// case1: hasChild查询,返回的是相关的父文档 所以查询用父文档实体及其mapper
LambdaEsQueryWrapper documentWrapper = new LambdaEsQueryWrapper<>();
documentWrapper.hasChild("comment", FieldUtils.val(Comment::getCommentContent), "评论");
List documents = documentMapper.selectList(documentWrapper);
System.out.println(documents);
// case2: hasParent查询,返回的是相关的子文档 所以查询用子文档实体及其mapper
LambdaEsQueryWrapper commentWrapper = new LambdaEsQueryWrapper<>();
// 字段名称你也可以不用FieldUtils.val,直接传入字符串也行
commentWrapper.hasParent("document", "content", "内容");
List comments = commentMapper.selectList(commentWrapper);
System.out.println(comments);
// case3: parentId查询,返回的是相关的子文档,与case2类似,所以查询用子文档实体及其mapper
commentWrapper = new LambdaEsQueryWrapper<>();
commentWrapper.parentId("1", "comment");
List commentList = commentMapper.selectList(commentWrapper);
System.out.println(commentList);
}
@Test
public void testUpdate() {
// case1: 父文档/子文档 根据各自的id更新
Document document = new Document();
document.setId("1");
document.setTitle("父标题");
documentMapper.updateById(document);
// case2: 父文档/子文档 根据各自条件更新
Comment comment = new Comment();
comment.setCommentContent("更新后的评论");
LambdaEsUpdateWrapper wrapper = new LambdaEsUpdateWrapper<>();
wrapper.match(Comment::getCommentContent, "评论");
commentMapper.update(comment, wrapper);
}
@Test
public void testDelete() {
// case1: 父文档/子文档 根据各自的id删除
documentMapper.deleteById("1");
//case2: 父文档/子文档 根据各自条件删除
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Comment::getCommentContent, "评论");
commentMapper.delete(wrapper);
}
10,获取DSL语句
API
// 获取通过本框架生成的查询参数 可用于检验本框架生成的查询参数是否正确以及其它用途
String getSource(LambdaEsQueryWrapper wrapper);
温馨提示
如果您获取DSL语句仅仅是为了打印,您无需再手动调用此接口获取DSL语句,DSL语句默认会在控制台打印,生产环境如需关闭请在配置文件中配置print-dsl=false,配置可参考配置章节.
11,执行DSL语句
有个别用户期望使用RestLowLevelClient的功能执行已有DSL语句,实现类似在xpack或者es-head等插件上执行DSL的效果, 所以我们对此封装了开箱即用的执行DSL-API
API
// 执行静态dsl语句 不传索引名,默认为当前mapper对应索引
String executeDSL(String dsl);
// 执行静态dsl语句 可指定作用的索引
String executeDSL(String dsl, String indexName);
使用
@Test
public void testDSL() {
String dsl = "{\"size\":10000,\"query\":{\"bool\":{\"must\":[{\"term\":{\"title.keyword\":{\"value\":\"测试文档2\",\"boost\":1.0}}}],\"adjust_pure_negative\":true,\"boost\":1.0}}\"track_total_hits\":2147483647}";
String jsonResult = documentMapper.executeDSL(dsl);
// 注意,执行后是以JSON格式返回,由用户按需自行解析
System.out.println(jsonResult);
}
12,执行SQL语句
有个别用户期望使用RestLowLevelClient的功能执行已有SQL语句,实现类似在xpack或者es-head等插件上执行DSL的效果, 所以我们对此封装了开箱即用的执行SQL-API
// 执行静态SQL语句 索引名以SQL中where条件中指定的为准
String executeSQL(String dsl);
使用
@Test
public void testSQL() {
// 注意 sql中的from后面跟的是要被查询的索引名,也可以是索引别名(效果一样) 由于索引名可能会变,所以此处我采用别名ee_default_alias进行查询
String sql = "select count(*) from ee_default_alias where star_num > 0";
String jsonResult = documentMapper.executeSQL(sql);
// 注意,执行后是以JSON格式返回,由用户按需自行解析
System.out.println(jsonResult);
}
温馨提示
尽管ES提供了对SQL的支持,但功能比较简单,用过的都懂,此功能仅是为了满足少数用户的需求场景,就好比MP已经支持了开箱即用的简单SQL查询,用户基本上很少会再去 手写SQL了,何况它这个SQL支持的功能过于简单,拓展性也很差,不太建议使用.
四,高阶用法
1,查询字段过滤
正向过滤(只查询指定字段)
@Test
public void testFilterField() {
// 测试只查询指定字段
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
String title = "老汉";
wrapper.eq(Document::getTitle, title);
wrapper.select(Document::getTitle);
Document document = documentMapper.selectOne(wrapper);
System.out.println(document);
}
反向过滤(不查询指定字段)
@Test
public void testNotFilterField() {
// 测试不查询指定字段 (推荐)
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
String title = "老汉";
wrapper.eq(Document::getTitle, title);
wrapper.notSelect(Document::getTitle);
Document document = documentMapper.selectOne(wrapper);
System.out.println(document);
// 另外一种与mp一致语法的Lambda写法
LambdaEsQueryWrapper wrapper1 = new LambdaEsQueryWrapper<>();
wrapper1.select(Document.class, d -> !Objects.equals(d.getColumn(), "title"));
Document document1 = documentMapper.selectOne(wrapper);
System.out.println(document1);
}
温馨提示
正向过滤和反向过滤你只能选择其中一种,如果同时使用两种过滤规则,会导致冲突字段失去过滤效果
2,排序
EE内置排序
针对字段的排序,EE提供了一些内置开箱即用的API,用于支持升序排序和降序排序:
// 降序排列
wrapper.orderByDesc(排序字段,支持多字段)
// 升序排列
wrapper.orderByAsc(排序字段,支持多字段)
// 根据得分排序(此功能0.9.7+版本支持;不指定SortOrder时默认降序,得分高的在前,支持升序/降序)
wrapper.sortByScore(boolean condition,SortOrder sortOrder)
// 排序入参由前端传入, 字符串格式,有点类似之前MySQL那种
wrapper.orderBy(boolean condition, OrderByParam orderByParam);
// 排序入参由前端传入,多字段情形
wrapper.orderBy(boolean condition, List orderByParams);
// 根据距离由近及远排序
wrapper.orderByDistanceAsc(boolean condition, R column, Geopoint...geoPoints);
// 根据距离由远及近排序
wrapper.orderByDistanceDesc(boolean condition, R column, Geopoint...geoPoints);
使用示例:
@Test
public void testSort(){
// 测试排序 为了测试排序,我们在Document对象中新增了创建时间字段,更新了索引,并新增了两条数据
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.likeRight(Document::getContent,"推");
wrapper.select(Document::getTitle,Document::getGmtCreate);
List before = documentMapper.selectList(wrapper);
System.out.println("before:"+before);
wrapper.orderByDesc(Document::getGmtCreate);
List desc = documentMapper.selectList(wrapper);
System.out.println("desc:"+desc);
}
@Test
public void testSortByScore(){
// 测试根据得分升序排列(分数低的排前面)
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent,"技术");
wrapper.sortByScore(SortOrder.ASC);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testOrderByParams(){
// 此处模拟参数由前端通过xxQuery类传入,排序根据标题降序,根据内容升序
String jsonParam = "[{\"order\":\"title\",\"sort\":\"DESC\"},{\"order\":\"creator\",\"sort\":\"ASC\"}]";
List orderByParams = JSON.parseArray(jsonParam, OrderByParam.class);
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent,"技术")
.orderBy(orderByParams);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testOrderByDistanceAsc() {
// 测试给定中心点, 查询出中心点168.8km范围内的数据,并按照距中心点距离由近及远排序
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
GeoPoint centerPoint = new GeoPoint(41.0, 116.0);
wrapper.match(Document::getCreator, "老汉")
.geoDistance(Document::getLocation, 168.8, centerPoint)
.orderByDistanceAsc(Document::getLocation, centerPoint);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testOrderByDistanceAsc() {
// 测试给定中心点, 查询出中心点168.8km范围内的数据,并按照距中心点距离由远及近排序
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
GeoPoint centerPoint = new GeoPoint(41.0, 116.0);
wrapper.match(Document::getCreator, "老汉")
.geoDistance(Document::getLocation, 168.8, centerPoint)
.orderByDistanceDesc(Document::getLocation, centerPoint);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
自定义排序
// API
wrapper.sort(boolean condition, SortBuilder sortBuilder)
使用示例:
@Test
public void testSort(){
// 测试复杂排序,SortBuilder的子类非常多,这里仅演示一种, 比如有用户提出需要随机获取数据
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent,"技术");
Script script = new Script("Math.random()");
ScriptSortBuilder scriptSortBuilder = new ScriptSortBuilder(script, ScriptSortBuilder.ScriptSortType.NUMBER);
wrapper.sort(scriptSortBuilder);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
SortBuilder类的子类非常多,也非常灵活,所以能支撑和覆盖的排序场景也足够多,其它各种类型的查询,如果您在使用过程中有碰到,可以参考上面的例子去写
3,聚合查询
前言
聚合可以算得上ES中最难用的一部分了,其API也是最反人类的,懂的都懂。对聚合的支持,SpringData-ElasticSearch直接放弃了,EE对其ES的聚合的简化也比较有限,尽管如此,也算得上目前市面上开源框架中对ES聚合支持得最好的框架了,大家在用得时候请轻喷,在聚合方式排列组合有上千种,以及灵活多变的树形桶得数据解析上,我们真的尽力了,奉劝大家抛弃幻想,准备迎接挑战,这不是MySQL。ES的聚合和MySQL的Group By聚合完全是两种不同的东西。 您现在看到的聚合也绝对不是EE对聚合支持的最终形态,我们还会持续探索进一步简化聚合,来减轻用户使用ES聚合功能的烦恼
常规聚合
在MySQL中,我们可以通过指定字段进行group by聚合,EE同样也支持类似聚合
@Test
public void testGroupBy() {
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.likeRight(Document::getContent,"推");
wrapper.groupBy(Document::getCreator);
// 支持多字段聚合
// wrapper.groupBy(Document::getCreator,Document::getCreator);
SearchResponse response = documentMapper.search(wrapper);
System.out.println(response);
}
温馨提示
尽管语法与MP一致,但实际上,ES的聚合结果是放在单独的对象中的,格式如下所示,因此我们高阶语法均需要用SearchResponse来接收返回结果,这点需要区别于MP和MySQL.
"aggregations":{"sterms#creator":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"老汉","doc_count":2},{"key":"老王","doc_count":1}]}}
其它聚合:
// 求最小值
wrapper.min();
// 求最大值
wrapper.max();
// 求平均值
wrapper.avg();
// 求和
wrapper.sum();
如果需要先groupBy,再根据groupBy聚合后桶中的数据进行求最值,均值之类的,也是支持的,会按照您在wrapper中指定的顺序,管道聚合(pipeline aggregation).
示例
@Test
public void testAgg() {
// 根据创建者聚合,聚合完在该桶中再次根据点赞数聚合
// 注意:指定的多个聚合参数为管道聚合,就是第一个聚合参数聚合之后的结果,再根据第二个参数聚合,对应Pipeline聚合
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.groupBy(Document::getCreator)
.max(Document::getStarNum);
SearchResponse response = documentMapper.search(wrapper);
System.out.println(response);
}
另外EE还提供了可以配置是否开启管道聚合的参数,默认为开启,如果你想让多个字段聚合的结果出现在各自的桶中,那么你可以指定enablePipeline参数为false即可.
@Test
public void testAggNotPipeline() {
// 对于下面两个字段,如果不想以pipeline管道聚合,各自聚合的结果在各自的桶中展示的话,我们也提供了支持
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
// 指定启用管道聚合为false
wrapper.groupBy(false, Document::getCreator, Document::getTitle);
SearchResponse response = documentMapper.search(wrapper);
System.out.println(response);
}
去重聚合
为了方便用户去重,我们针对字段的去重提供了极为友好的方式,解决用户根据字段进行去重及分页要写大量代码来实现的烦恼,使用ee单字段去重仅需1行即可搞定
API
// 去重,入参为去重列
wrapper.distinct(R column);
@Test
public void testDistinct() {
// 查询所有标题为老汉的文档,根据创建者去重,并分页返回
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.distinct(Document::getCreator);
PageInfo pageInfo = documentMapper.pageQuery(wrapper, 1, 10);
System.out.println(pageInfo);
}
坏味道
对于多字段的去重支持,没有上述这么简单,因为多字段去重无法通过折叠去实现,数据会被置入桶中返回,桶中数据的解析,需要哪些字段,排序规则,覆盖规则是怎样的过于灵活,我们无法通过框架来帮用户屏蔽这些,市面上目前也无任何框架能够支撑,因此,我们对多字段的去重仅支持到了查询条件的封装,数据解析部分需用户自行完成,敬请谅解.好在多字段去重的场景并不是太多,用户如果有用到多字段去重,可参见本篇开头对groupBy的介绍,可通过groupBy对多字段实现去重
4,分词&模糊匹配
分词匹配相关功能API
match(boolean condition, R column, Object val);
matchPhase(boolean condition, R column, Object val, Float boost);
matchAllQuery();
matchPhrasePrefixQuery(boolean condition, R column, Object val, int maxExpansions, Float boost);
multiMatchQuery(boolean condition, Object val, Operator operator, int minimumShouldMatch, Float boost, R... columns);
queryStringQuery(boolean condition, String queryString, Float boost);
prefixQuery(boolean condition, R column, String prefix, Float boost);
注意
注意:涉及需要分词匹配的字段索引类型必须为text或keyword_text(不指定时默认为此类型),并为其指定分词器,所需分词器需提前安装,否则将使用es默认分词器,对中文支持不好
模糊匹配相关功能API
// 注意 like底层对应es的wildcard查询,传入的值会被默认拼接上*号通配符 例如 *老汉*
like(boolean condition, String column, Object val, Float boost);
// likeLeft会在值左侧拼接通配符* 例如 *老汉
likeLeft(boolean condition, String column, Object val, Float boost);
// likeRight会在值右侧拼接通配符* 例如老汉*
likeRight(boolean condition, String column, Object val, Float boost);
查询API及字段索引类型参考
| ES原生 | Easy-Es | keyword类型 | text类型 | 是否支持分词 |
|---|---|---|---|---|
| term | eq | 完全匹配 | 查询条件必须都是text分词中的,且不能多余,多个分词时必须连续,顺序不能颠倒 |
否 |
| wildcard | like/likeLeft/likeRight | 根据api模糊匹配 like全模糊,likeLeft左模糊,likeRight右模糊 | 不支持 | 否 |
| match | match | 完全匹配 | match分词结果和text的分词结果有相同的即可,不考虑顺序 |
是 |
| matchPhrase | matchPhrase | 完全匹配 | matchPhrase的分词结果必须在text字段分词中都包含且顺序必须都相同,而且必须都是连续的. |
是 |
| matchPhrasePrefixQuery | matchPhrasePrefixQuery | 不支持 | matchPhrasePrefix与matchPhrase相同,除了它允许在文本的最后一个词上的前缀匹配. |
是 |
| multiMatchQuery | multiMatchQuery | 完全匹配 | 全字段分词匹配,可实现全文检索功能 | 是 |
| queryStringQuery | queryStringQuery | 完全匹配 | queryString中的分词结果至少有一个在text字段的分词结果中,不考虑顺序 | 是 |
| prefixQuery | prefixQuery | 完全匹配 | 只要分词后的词条中有词条满足前缀条件即可 | 是 |
- 分词匹配
- 例: match("content", "老王")--->content 包含关键词 '老王' 如果分词粒度设置的比较细,老王可能会被拆分成"老"和"王",只要content中包含"老"或"王",均可以被搜出来,其它api可参考下面代码示例
代码示例
@Test
public void testMatch(){
// 会对输入做分词,只要所有分词中有一个词在内容中有匹配就会查询出该数据,无视分词顺序
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent,"技术");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents.size());
}
@Test
public void testMatchPhrase() {
// 会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样,否则就无法查询出结果
// 例如es中数据是 技术过硬,如果搜索关键词为过硬技术就无法查询出结果
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.matchPhrase(Document::getContent, "技术");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testMatchAllQuery() {
// 查询所有数据,类似mysql select all.
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.matchAllQuery();
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testMatchPhrasePrefixQuery() {
// 前缀匹配查询 查询字符串的最后一个词才能当作前缀使用
// 前缀 可能会匹配成千上万的词,这不仅会消耗很多系统资源,而且结果的用处也不大,所以可以提供入参maxExpansions,若不写则默认为50
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.matchPhrasePrefixQuery(Document::getCustomField, "乌拉巴拉", 10);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void testMultiMatchQuery() {
// 从多个指定字段中查询包含老王的数据
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.multiMatchQuery("老王", Document::getTitle, Document::getContent, Document::getCreator, Document::getCustomField);
// 其中,默认的Operator为OR,默认的minShouldMatch为60% 这两个参数都可以按需调整,我们api是支持的 例如:
// 其中AND意味着所有搜索的Token都必须被匹配,OR表示只要有一个Token匹配即可. minShouldMatch 80 表示只查询匹配度大于80%的数据
// wrapper.multiMatchQuery("老王",Operator.AND,80,Document::getCustomField,Document::getContent);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents.size());
System.out.println(documents);
}
@Test
public void queryStringQuery() {
// 从所有字段中查询包含关键词老汉的数据
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.queryStringQuery("老汉");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void prefixQuery() {
// 查询创建者以"隔壁"打头的所有数据 比如隔壁老王 隔壁老汉 都能被查出来
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.prefixQuery(Document::getCreator, "隔壁");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void like() {
// 等价于MySQL中 like %汉推% 像老汉推...就可以被查出来
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.like(Document::getTitle, "汉推");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void likeLeft() {
// 等价于MySQL中 like %汉 像老汉就可以被查出来
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.likeLeft(Document::getTitle, "汉");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
@Test
public void likeRight() {
// 等价于MySQL中 like 老% 像老汉就可以被查出来
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.likeRight(Document::getTitle, "老");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
queryString 妙用
由于queryString可以检索keyword和text两种类型,所以有一部分使用场景是如下图这样的,所有查询字段,查询类型,匹配规则等都是不固定的,由用户自由来选,这种情况下,您除了可以使用我们提供的四大嵌套查询中的or()来实现,还可以通过queryStringQuery API来解决
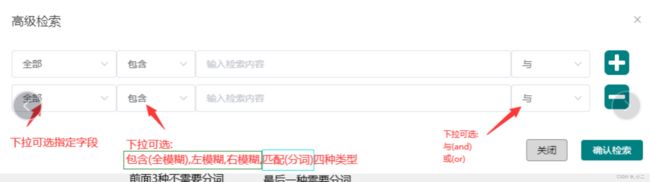
我们可以用StringBuilder把查询字段和值拼接进去,组装成最终的查询语句. 以上图为例,我演示一个场景,请忽略场景合理性,因为是我瞎xx选的:假设我的查询条件是:字段:创建者 等于老王,且创建者分词匹配"隔壁"(比如:隔壁老汉,隔壁老王),或者创建者包含大猪蹄子,对应的代码如下:
@Test
public void testQueryString() {
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
StringBuilder sb = new StringBuilder();
sb.append("(")
.append("(")
.append("creator.keyword")
.append(":")
.append("老王")
.append(")")
.append("AND")
.append("(")
.append("creator")
.append(":")
.append("隔壁")
.append(")")
.append(")")
.append("OR")
.append("(")
.append("creator.keyword")
.append(":")
.append("*大猪蹄子*")
.append(")");
// sb最终拼接为:((creator.keyword:老王)AND(creator:隔壁))OR(creator.keyword:*大猪蹄子*) ,可以说和MySQL语法非常相似了
wrapper.queryStringQuery(sb.toString());
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
前端参数页面每传递一行查询参数,我们往sb中append对应参数就完事了,是不是很简单,没错,但是代码不优雅,可咋整? 老汉已经给你们想好出路了,我们提供了工具类,其全路径为:cn.easyes.core.toolkit.QueryUtils 我们用使用该工具类重构上面的代码,如下:
@Test
public void testQueryStringQueryMulti() {
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
String queryStr = QueryUtils.combine(Link.OR,
QueryUtils.buildQueryString(Document::getCreator, "老王", Query.EQ, Link.AND),
QueryUtils.buildQueryString(Document::getCreator, "隔壁", Query.MATCH))
+ QueryUtils.buildQueryString(Document::getCreator, "*大猪蹄子*", Query.EQ);
wrapper.queryStringQuery(queryStr);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
是不是优雅了很多,其中的枚举Query和Link我也已经为你们封装好了,直接使用即可
5,权重
API
function(字段, 值, Float 权重值)
代码示例
@Test
public void testWeight() throws IOException {
// 测试权重
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
String keyword = "过硬";
float contentBoost = 5.0f;
wrapper.match(Document::getContent,keyword,contentBoost);
String creator = "老汉";
float creatorBoost = 2.0f;
wrapper.eq(Document::getCreator,creator,creatorBoost);
SearchResponse response = documentMapper.search(wrapper);
System.out.println(response);
}
温馨提示
如果你需要得分,则通过SearchResponse返回,如果不需要得分,只需要按照得分高的排名靠前返回,则直接用
List接收即可.
6,高亮查询
提示
高亮字段通过自定义注解@HighLight即可实现,将该注解添加在需要被高亮的字段上即可
@HighLight
- 描述:高亮注解
- 使用位置:实体类中需要高亮的被查询字段
- 使用场景举例:比如输入关键词"老汉"进行查询,期望内容中包含"老汉"的部分被展示为红色或加粗
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| mappingField | String | 否 | "" | 高亮内容映射字段的名称,比如我想把高亮内容"老汉"赋值到字段pushCar上,就可以指定此属性值为pushCar |
| fragmentSize | int | 否 | 100 | 高亮字段截取长度,默认为100 |
| numberOfFragments | int | 否 | -1 | 搜索返回的高亮片段数量,默认全部返回 |
| preTag | String | 否 | < em > | 高亮标签,高亮内容将处于preTag之后 |
| postTag | String | 否 | < /em > | 高亮标签,高亮内容将处于postTag之前 |
| highLightType | HighLightTypeEnum | 否 | UNIFIED | 高亮类型 |
提示
HighLightTypeEnum
- UNIFIED: 通用高亮策略,缺省配置时,默认采用此策略. 此高亮策略将文本分解成句子,并使用BM25算法对单个句子进行评分,支持精确的短语和多术语(模糊、前缀、正则表达式)突出显示.
- PLAIN: 普通高亮策略,其使用的是Lucene的standard Lucene highlighter
- FVH: Fast vector highlighter(快速向量策略)
注解使用示例
public class Document{
/**
* 需要被高亮的字段
*/
@HighLight
private String content;
// 省略其它无关字段...
}
温馨提示
如果你不想原来的字段值被高亮字段覆盖,那么你需要在@HighLight注解中指定mappingField,并将该字段添加至对应实体类中,这样配置以后,高亮内容在highlightContent字段中返回,原content字段的值依旧返回它本身的值.
例如:
public class Document{
/**
* 需要被高亮的字段
*/
@HighLight(mappingField = "highlightContent")
private String content;
/**
* 高亮返回值被映射的字段
*/
private String highlightContent;
// 省略其它无关字段...
}
其它
- 高亮注解支持设置高亮返回内容截取的长度fragmentSize,默认值为100
- 高亮注解支持设置高亮内容的标签,默认为标签 em
7,GEO地理位置查询
提示
地理位置查询,与Es官方提供的功能完全一致,共支持4种类型的地理位置查询:
- GeoBoundingBox
- GeoDistance
- GeoPolygon
- GeoShape
通过这4类查询,可以实现各种强大实用的功能
应用场景
- 外卖类APP 附近的门店
- 社交类APP 附近的人
- 打车类APP 附近的司机
- 区域人群画像类APP 指定范围内的人群特征提取
- 健康码等
- ...
EE对ES地理位置相关功能支持覆盖100%,且使用更为简单.
注意事项
- 在使用地理位置查询API之前,需要提前创建或更新好索引
- 划重点:其中前三类API(GeoBoundingBox,GeoDistance,GeoPolygon)字段索引类型必须为geo_point
- GeoShape字段索引类型必须为geo_shape,否则将导致功能无法正常使用,具体可参考下图
- 字段类型推荐使用String,因为wkt文本格式就是String,非常方便,至于字段名称,见名知意即可.

public class Document {
// 省略其它字段...
@IndexField(fieldType = FieldType.GEO_POINT)
private String location;
@IndexField(fieldType = FieldType.GEO_SHAPE)
private String geoLocation;
}
数据录入
数据插入es方法非常多,这里仅介绍如何使用EE开箱即用API将地理位置数据插入es
@Test
public void testInsert() {
// 省略其它无关字段...
Document document = new Document();
// GEO POINT
document.setLocation("40.171975,116.587105");
// 上面也可以写为下面这样,效果是一样的:
GeoPoint geoPoint = new GeoPoint(40.171975,116.587105);
document.setLocation(geoPoint.toString());
// GEO SHAPE
Rectangle rectangle = new Rectangle(39.084509D, 41.187328D, 70.610461D, 20.498353D);
document.setGeoLocation(rectangle.toString());
int successCount = documentMapper.insert(document);
}
插入的数据必须是String,其格式可以直接是经纬度,也可以先创建具体的GeoPoint或Geometry对象,然后调用它的toString方法将其转换为wkt坐标字符串后再插入, 如果直接插入GeoPoint或Geometry对象,会导致插入失败,提示UnknownSource
GeoBoundingBox
GeoBoundingBox: 直译为地理边界盒,由左上点和右下点构成的矩形范围,在此范围内的点均可以被查询出来,实际使用的并不多,可参考下图:

API
// 在矩形内
geoBoundingBox(R column, GeoPoint topLeft, GeoPoint bottomRight);
// 不在矩形内 (0.9.7+版本支持)
notInGeoBoundingBox(R column, GeoPoint topLeft, GeoPoint bottomRight);
使用示例
@Test
public void testGeoBoundingBox() {
// 查询位于左上点和右下点坐标构成的长方形内的所有点
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
// 假设左上点坐标
GeoPoint leftTop = new GeoPoint(41.187328D, 115.498353D);
// 假设右下点坐标
GeoPoint bottomRight = new GeoPoint(39.084509D, 117.610461D);
wrapper.geoBoundingBox(Document::getLocation, leftTop, bottomRight);
// 查不在此长方形内的所有点
// wrapper.notInGeoBoundingBox(Document::getLocation, leftTop, bottomRight);
List documents = documentMapper.selectList(wrapper);
documents.forEach(System.out::println);
}
温馨提示
- 上面使用示例仅演示了其中一种,实际上本框架中坐标点的语法支持非常多种,ElasticSearch官方提供的几种数据格式都支持,用户可按自己习惯自行选择对应的api进行查询参数构造:
- GeoPoint:上面Demo中使用的经纬度表示方式
- 经纬度数组: [116.498353, 40.187328],[116.610461, 40.084509]
- 经纬度字符串: "40.187328, 116.498353","116.610461, 40.084509"
- 经纬度边界框WKT: "BBOX (116.498353,116.610461,40.187328,40.084509)"
- 经纬度GeoHash(哈希): "xxx"
GeoDistance
GeoDistance:直译为地理距离,实际上就是以给定的点为圆心,给定的半径画个圆,处在此圆内的点都能被查出来,使用较为高频,比如像我们用的外卖软件,查询周围3公里内的所有店铺,就可以用此功能去实现,没错你还可以用来写YP软件,查询下附近三公里内的PLMM...
API
// 查圆形内的所有点
geoDistance(R column, Double distance, DistanceUnit distanceUnit, GeoPoint centralGeoPoint);
// 查不在圆形内的所有点 (0.9.7+ 版本支持)
notInGeoDistance(R column, Double distance, DistanceUnit distanceUnit, GeoPoint centralGeoPoint);
使用示例
@Test
public void testGeoDistance() {
// 查询以经度为41.0,纬度为115.0为圆心,半径168.8公里内的所有点
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
// 其中单位可以省略,默认为km
wrapper.geoDistance(Document::getLocation, 168.8, DistanceUnit.KILOMETERS, new GeoPoint(41.0, 116.0));
//查询不在圆形内的所有点
// wrapper.notInGeoDistance(Document::getLocation, 168.8, DistanceUnit.KILOMETERS, new GeoPoint(41.0, 116.0));
// 上面语法也可以写成下面这几种形式,效果是一样的,兼容不同用户习惯而已:
// wrapper.geoDistance(Document::getLocation,"1.5km",new GeoPoint(41.0,115.0));
// wrapper.geoDistance(Document::getLocation, "1.5km", "41.0,115.0");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
温馨提示
- 同样的对于坐标点的表达形式也支持多种,和GeoBondingBox中的Tips介绍的一样,这里不再赘述.
- 对于宠粉的EE来说,兼容各种用户的不同习惯是理所当然的,所以你在使用时会发现大量方法重载,选一种最符合你使用习惯或符合指定使用场景的api进行调用即可.
GeoPolygon
GeoPolygon:直译为地理多边形,实际上就是以给定的所有点构成的多边形为范围,查询此范围内的所有点,此功能常被用来做电子围栏,使用也较为高频,像共享单车可以停放的区域就可以通过此技术实现,可参考下图:

API
geoPolygon(R column, List geoPoints)
使用示例
@Test
public void testGeoPolygon() {
// 查询以给定点列表构成的不规则图形内的所有点,点数至少为3个
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
List geoPoints = new ArrayList<>();
GeoPoint geoPoint = new GeoPoint(40.178012, 116.577188);
GeoPoint geoPoint1 = new GeoPoint(40.169329, 116.586315);
GeoPoint geoPoint2 = new GeoPoint(40.178288, 116.591813);
geoPoints.add(geoPoint);
geoPoints.add(geoPoint1);
geoPoints.add(geoPoint2);
wrapper.geoPolygon(Document::getLocation, geoPoints);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
温馨提示
- 同样的,关于坐标点的入参形式,也支持多种,与官方一致,可以参考GeoBoundingBox中的Tips,这里不赘述.值得注意的是多边形的点数不能少于3个,否则Es无法勾勒出多边形,本次查询会报错.
- 索引类型和字段类型与GeoBondingBox中的Tips介绍的一样
GeoShape
GeoShape:直译为地理图形,怎么理解?乍一看好像和GeoPolygon很像,但实际上,前面三种类型查询的都是坐标点,而此方法查询的是图形,比如一个园区,从世界地图上看可以把它当做一个点,但如果放得足够大,比如把地图具体到杭州市滨江区,园区就可能变成若干个点构成的一个区域,在一些特殊的场景中,需要查询此完整的区域,以及两个区域的交集之类的,就需要用到GeoShape了,如果你还不理解,不妨先接着往下看,以杭州为例,我举一个健康码的例子,假设黑色圈内区域为中风险地区,我现在要查出ES中所有在市民中心且处于中风险区域的人,把他们的健康码统统变成橙色,那实际上我要找的就是下图中橙色那块区域,此时红色箭头所构成的区域是整个市民中心,我可以把整个市民中心作为一个地理图形,然后把黑色大圆作为查询的图形,找出它们的交集即可.
上图对应的ShapeRelation为INTERSECTS,看以看下面API
API
// 查询符合已索引图形的图形
geoShape(R column, String indexedShapeId);
// 查询不符合已索引图形的图形 (0.9.7+ 版本支持)
notInGeoShape(R column, String indexedShapeId);
// 查询符合指定图形和图形关系的图形列表
geoShape(R column, Geometry geometry, ShapeRelation shapeRelation);
// 查询不符合指定图形和图形关系的图形列表
notInGeoShape(R column, Geometry geometry, ShapeRelation shapeRelation);
使用示例
此API不常用,也可直接跳过看下面通过图形查询的
/**
* 已知图形索引ID(不常用)
* 在一些高频场景下,比如一个已经造好的园区,其图形坐标是固定的,因此可以先把这种固定的图形先存进es
* 后续可根据此图形的id直接查询,比较方便,故有此方法,但不够灵活,不常用
*/
@Test
public void testGeoShapeWithShapeId() {
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
// 这里的indexedShapeId为用户事先已经在Es中创建好的图形的id
wrapper.geoShape(Document::getGeoLocation, "edu");
// 不符合的情况
// wrapper.notInGeoShape(Document::getGeoLocation, "edu");
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
此API相较上面方式更常用,即用户可以自行指定要查询的图形是矩形,圆形,还是多边形...(具体看代码中注释):
/**
* 图形由用户自定义(常用),本框架支持Es所有支持的图形:
* (Point,MultiPoint,Line,MultiLine,Circle,LineaRing,Polygon,MultiPolygon,Rectangle)
*/
@Test
public void testGeoShape() {
// 注意,这里查询的是图形,所以图形的字段索引类型必须为geoShape,不能为geoPoint,故这里用geoLocation字段而非location字段
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
// 这里以圆形为例演示,其中x,y为圆心坐标,r为半径. 其它图形请读者自行演示,篇幅原因不一一演示了
Circle circle = new Circle(13,14,100);
// shapeRelation支持多种,如果不传则默认为within
wrapper.geoShape(Document::getGeoLocation, circle, ShapeRelation.INTERSECTS);
// 不符合的情况
// wrapper.notInGeoShape(Document::getGeoLocation, circle, ShapeRelation.INTERSECTS);
List documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
上述地图中的 市民中心(多边形)的WKT(Well-Known Text)坐标(模拟的数据,真实数据可从高德地图/百度地图等通过 调用它们提供的开放API获取):
"POLYGON((108.36549282073975 22.797566864832092,108.35974216461182 22.786093175673713,108.37265968322754 22.775963875498206,108.4035587310791 22.77600344454008,108.41003894805907 22.787557113881462,108.39557647705077 22.805360509802284,108.36549282073975 22.797566864832092))";
已经存储在Es中了,实际上我们在项目中都会把可能用到的数据或业务数据都事先存入Es了,否则查询也就无意义了,查个空气? 所以上面API根据GeoShape查询时,需要传入的参数的仅是你圈定的范围的图形(上面该参数是圆).
温馨提示
GeoShape容易和GeoPolygon混淆,需要特别注意,它俩其实是两种不同的东西,其索引类型也需要区别,前者为geo_point,后者为geo_shape。
8,IP查询
提示
ES本身对IP查询作了非常友好的支持,所以很适合用来存储和查询IP,需要值得注意的是,IP对应的字段其索引类型必须建立为ip类型,不可以 是text,keyword或者默认类型,否则在后面的查询中你会发现实现不了你想要的IP范围检索.
最佳实践
public class Document{
// 省略其它字段...
@IndexField(fieldType = FieldType.IP)
private String ipAddress;
}
增删改与其它类型字段并无二致,不再演示,假设我已经录入一条ip地址为"192.168.1.1"至es中
@Test
public void testIp(){
// 精确查询
LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getIpAddress,"192.168.1.1");
List documents = documentMapper.selectList(wrapper);
// 范围检索
LambdaEsQueryWrapper wrapper1 = new LambdaEsQueryWrapper<>();
wrapper1.eq(Document::getIpAddress,"192.168.0.0/16");
List documents1 = documentMapper.selectList(wrapper);
// ip模糊匹配 es不支持
}
对于上面的IPv4的IP地址含有4个bytes,而每个byte含有8个digits,在上面的/16即表示前面的16位的digits,即192.168,因此只要位于192.168.0.0 至 192.168.255.255 的IP都可以被上面的检索条件检索出来