Transformer英语-法语机器翻译实例
依照Transformer结构来实例化编码器-解码器模型。在这里,指定Transformer编码器和解码器都是2层,都使用4头注意力。为了进行序列到序列的学习,我们在英语-法语机器翻译数据集上训练Transformer模型,如图11.2所示。
data_path = "weibo_senti_100k.csv"
data_list = open(data_path,"r",encoding='UTF-8').readlines()[1:]
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
loss 0.030, 5244.8 tokens/sec on cuda:0
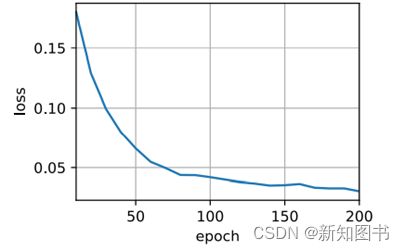
图11.2 在英语-法语机器翻译数据集上训练Transformer模型
训练结束后,使用Transformer模型将一些英语句子翻译成法语,并且计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
结果如下:
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est calme ., bleu 1.000
i'm home . => je suis chez moi ., bleu 1.000
当进行最后一个英语到法语的句子翻译工作时,需要可视化Transformer的注意力权重。编码器自注意力权重的形状为[编码器层数,注意力头数,num_steps或查询的数目,num_steps或“键-值”对的数目]。
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads,
-1, num_steps))
enc_attention_weights.shape
结果如下:
torch.Size([2, 4, 10, 10])在编码器的自注意力中,查询和键都来自相同的输入序列。由于填充词元是不携带信息的,因此通过指定输入序列的有效长度,可以避免查询与使用填充词元的位置计算注意力。接下来,将逐行呈现两层多头注意力的权重。每个注意力头都根据查询、键和值不同的表示子空间来表示不同的注意力,如图11.3所示。
d2l.show_heatmaps(
enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
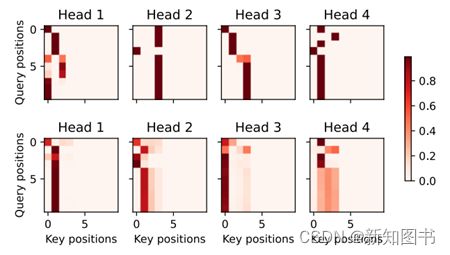
图11.3 4头注意力模型
为了可视化解码器的自注意力权重和编码器-解码器的注意力权重,我们需要完成更多的数据操作工作。
例如,用零填充被遮蔽住的注意力权重。值得注意的是,解码器的自注意力权重和编码器-解码器的注意力权重都有相同的查询,即以序列开始词元(Beginning-Of-Sequence,BOS)打头,再与后续输出的词元共同组成序列。
dec_attention_weights_2d = [head[0].tolist()
for step in dec_attention_weight_seq
for attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(
pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \
dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape
结果如下:
(torch.Size([2, 4, 6, 10]), torch.Size([2, 4, 6, 10]))由于解码器自注意力的自回归属性,查询不会对当前位置之后的键-值对进行注意力计算。结果如图11.4所示。
# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(
dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],
xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))
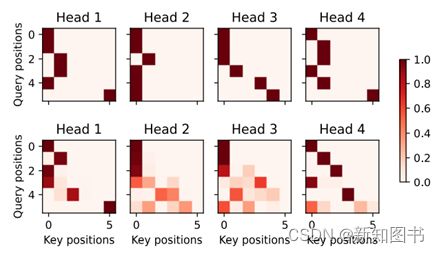
图11.4 查询不会对当前位置之后的键-值对进行注意力计算
与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。结果如图11.5所示。
d2l.show_heatmaps(
dec_inter_attention_weights, xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
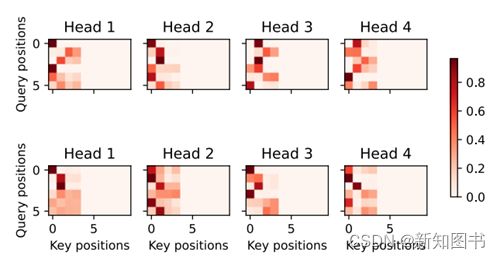
图11.5 指定输入序列的有效长度的4头注意模型
尽管Transformer结构是为了序列到序列的学习而提出的,Transformer编码器或Transformer解码器通常被单独用于不同的深度学习任务中。
节选自《Python深度学习原理、算法与案例》。
