【Elasticsearch】es脚本编程使用详解
目录
一、es脚本语言介绍
1.1 什么是es脚本
1.2 es脚本支持的语言
1.3 es脚本语言特点
1.4 es脚本使用场景
二、环境准备
2.1 docker搭建es过程
2.1.1 拉取es镜像
2.1.2 启动容器
2.1.3 配置es参数
2.1.4 重启es容器并访问
2.2 docker搭建kibana过程
2.2.1 拉取kibana镜像
2.2.2 启动kibana容器
2.2.3 修改配置文件
2.2.4 重启容器并访问
三、Scripting 使用详解
3.1 数据准备
3.1.1 创建索引
3.1.2 添加测试数据
3.2 es脚本常用CRUD操作
3.2.1 修改id为1001数据的价格
3.2.2 修改id为1005数据的tag
3.2.3 删除id为1005数据
3.2.4 upsert操作
3.2.5 使用expression查询
3.3 参数化脚本使用
3.3.1 修改1005这条数据的字段值
3.3.2 对字段值进行计算
3.3.3 对字段值进行计算并输出多个结果
3.4 参数化脚本的存储
3.4.1 自定义一个参数脚本
3.4.2 查询脚本模板
3.4.3 使用自定义脚本模板
四、Scripting 函数式编程
4.1 函数式编程格式
4.2 函数式编程使用
4.2.1 同时操作多个字段
4.2.2 条件表达式
4.2.3 数据统计与聚合
五、写在文末
一、es脚本语言介绍
1.1 什么是es脚本
Elasticsearch的 Scripting 是es支持的一种专门用于复杂场景下实现可编程的强大脚本功能。通过Scripting 脚本编程,可以实现更复杂的查询、数据处理、数据定制统计聚合以及柔性调整索引结构等。
1.2 es脚本支持的语言
es支持多种脚本语言,比如Painless,这是 Elasticsearch 自家开发的一种安全、高效并且易于学习的语言,其语法与Java很类似,编程中,也有注释、关键字、类型、变量、函数等,相较于其他支持的脚本语言性能更高,并且安全可靠,可以用于内联和存储脚本。
除了 Painless,Elasticsearch 也支持其他几种脚本语言,如 Lucene 的表达式语言,但 Painless 是推荐和默认的选项。具体来说,常用的支持语言如下:
-
groovy,ES1.4X~5.0默认的脚本语言;
-
Painless,JavaEE使用java语言开发,.net使用C#语言开发,Flutter使用Dart语言开发,ES5.X之后的Scripting 使用的默认语法就是Painless,Painless是一种专门用于es的脚本语法,是ES5.0+的默认脚本语言,其语法与Java很类似;
-
expression:每个文档的开销较低,表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还要快,支持javascript语法的子集。缺点:只能访问数字,布尔值,日期和geo_point字段,存储的字段不可用;
-
mustache:提供模板参数化查询。
1.3 es脚本语言特点
使用es脚本语言进行编程具有如下特点
-
语法简单,学习成本较低;
-
灵活度高,可编程能力强;
-
性能相对于其他脚本语言高;
-
安全性好;
-
独立语言,虽然易学但是仍需单独学习;
-
相较于DSL语言性能低;
-
不适用于复杂的业务场景;
1.4 es脚本使用场景
在下面的一些场景下可以考虑使用es脚步。
计算字段
你可以使用脚本在查询时动态地改变或添加字段的值,这对于数据分析的场景下具有重要的作用。
脚本查询
在查询中使用脚本进行复杂的条件判断。es脚本语言很灵活,其中painless类型下,其语法格式和java非常相似,支持各类条件查询。
脚本聚合
使用脚本进行更复杂的聚合计算。
二、环境准备
为了后面的操作和演示方便,使用docker 快速搭建起es的操作环境。
搭建的服务包括 es+kibana。使用的版本为7.6.2.
2.1 docker搭建es过程
2.1.1 拉取es镜像
docker pull elasticsearch:7.6.22.1.2 启动容器
使用下面的命令启动es的容器
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name es7.6 -d elasticsearch:7.6.2重点需要注意这个配置,ES_JAVA_OPTS="-Xms512m -Xmx512m",这个配置参数的值最好根据你的服务器配置来决定,一般最好不要低于512m即可;
2.1.3 配置es参数
进入到es容器内部,然后找到下面的这个文件
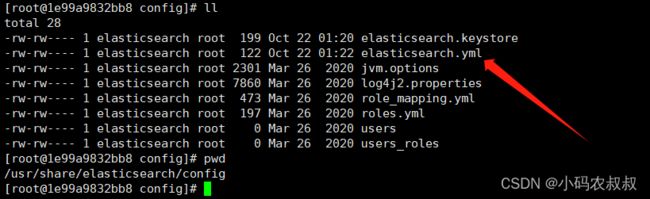
然后将下面的配置参数配置进去
cluster.name: "docker-cluster"
http.cors.enabled: true
network.host: 0.0.0.0
http.port: 9200
http.cors.allow-origin: "*"2.1.4 重启es容器并访问
配置完成后重启docker容器,重启成功后,开放9200的端口,然后浏览器可以访问IP:9200,看到如下信息,说明es的搭建完成
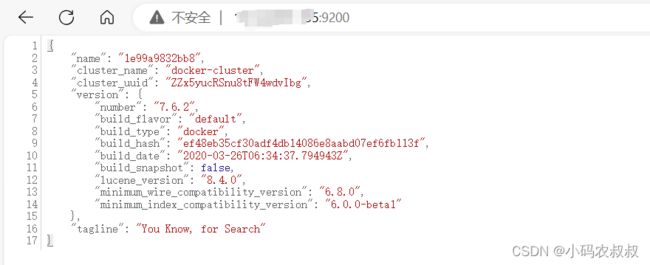
2.2 docker搭建kibana过程
2.2.1 拉取kibana镜像
为了减少后面的配置麻烦和一些问题,建议kibana版本与es版本一致
docker pull kibana:7.6.22.2.2 启动kibana容器
这里的IP,如果是云服务器,注意使用内网的IP地址
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://es服务IP:9200 -p 5601:5601 -d kibana:7.6.22.2.3 修改配置文件
进入到kibana容器中,进入到下面的目录中
cd /usr/share/kibana/config
vi kibana.yml 
将如下的配置信息配置进去(es的IP地址如果是云服务器建议使用内网IP)
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://es服务IP:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: zh-CN2.2.4 重启容器并访问
上述配置信息配置完成后,重启容器,开放5601端口,浏览器就可以直接访问,IP:5601,看到下面的效果说明kibana搭建完成
三、Scripting 使用详解
3.1 数据准备
3.1.1 创建索引
使用下面的语句创建一个book的索引
PUT books
3.1.2 添加测试数据
添加如下测试数据
PUT /books/_doc/1001
{
"id":"1001",
"title":"Java technology fans",
"category":"Java",
"price":129,
"from":"shanghai"
}
PUT /books/_doc/1002
{
"id":"10034",
"title":"Python data analysis",
"category":"Python",
"price":98,
"from":"hangzhou",
"tags":["python","analysis"]
}
PUT /books/_doc/1003
{
"id":"1003",
"title":"Js vue",
"category":"web",
"price":68,
"from":"wuhan",
"barcode":["js","web"]
}
PUT /books/_doc/1004
{
"id":"1004",
"title":"Mysql dba",
"category":"mysql",
"price":88,
"from":"hangzhou",
"barcode":["mysql","analysis"]
}
PUT /books/_doc/1005
{
"id":"1005",
"title":"Python official ",
"category":"Python",
"price":108,
"from":"hangzhou",
"barcode":["python","analysis"]
}测试其中一条添加数据效果

全部添加之后,可以检查下是否添加成功

3.2 es脚本常用CRUD操作
操作语法
ctx._source.
参数说明
-
ctx,表示当前操作对象的上下文环境;
-
_source,表示包裹数据对象的标识;
-
field-name,具体操作的某个字段
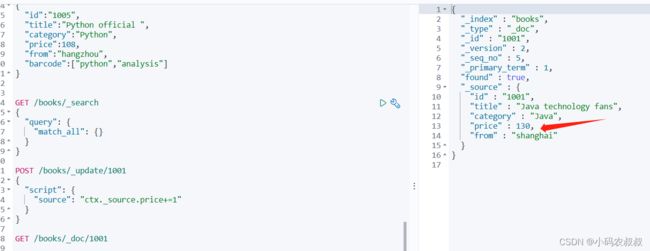
3.2.1 修改id为1001数据的价格
将id为1001的数据的价格加1元,操作语法如下
POST /books/_update/1001
{
"script": {
"source": "ctx._source.price+=1"
}
}
操作完成后,再次查看这条数据,发现价格加1了
上面的语法也可以简写为下面这样
POST /books/_update/1001
{
"script": "ctx._source.price+=1"
}3.2.2 修改id为1005数据的tag
给id为1005的这条数据中的barcode字段的值再增加一个service的值

执行下面的语句
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source": "ctx._source.barcode.add('service')"
}
}执行完成后再次查询,可以看到barcode中就多了一个service的值

3.2.3 删除id为1005数据
执行下面的语句进行数据删除
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source": "ctx.op='delete'"
}
}执行完成后再次查询这条数据,已经查不到了

3.2.4 upsert操作
upsert为更新或新增,当操作的这条数据不存在的时候,执行新增;如果已存在,则执行修改操作,以上面的1005这条被删除的数据,当执行下面的语句时,由于1005不存在,所以会新增一条数据,而其他已存在的数据的price会加10;
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source": "ctx._source.price += 10"
},
"upsert": {
"id":"1005",
"title":"Python official ",
"category":"Python",
"price":108,
"from":"hangzhou",
"barcode":["python","analysis"]
}
}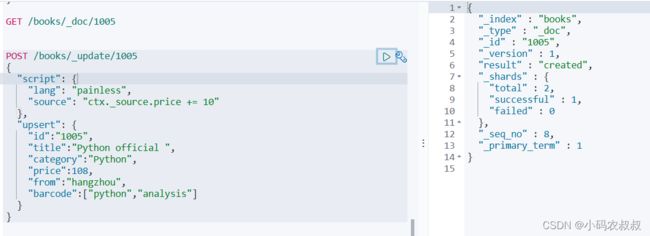
执行上面的语句之后,查询一下看到新增了一条100的数据

如果再执行一次,通过右侧执行结果,这一次就是修改操作了
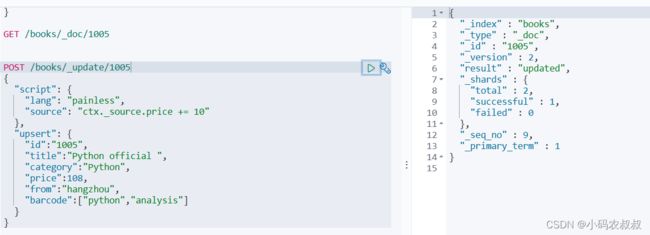
3.2.5 使用expression查询
在上文讲到,es5之后默认的脚本语言是Painless,在某些场景下也可以使用expression来操作,注意的是,使用expression类型查询时,语法格式将有所变化,需要以script_fields开头,这个在kibana中会有提示,如下为查询数据的price字段的值
GET /books/_search
{
"script_fields": {
"get_price": {
"script": {
"lang": "expression",
"source": "doc['price'].value"
}
}
}
}
也可以基于某个值进行计算操作,比如将price的值*10

3.3 参数化脚本使用
在很多编程语言中都支持外部参数的传入,在es的painless脚本编程中,也支持参数化使用,参数化脚本可以让脚本程序的灵活性和可扩展性更好。
3.3.1 修改1005这条数据的字段值
比如在上面的案例中,为id为1005的这条数据的barcode字段中添加一个service的值,如果使用参数化的方式来做,可以修改为下面这样
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source": "ctx._source.barcode.add(params.barcode_name)",
"params":{
"barcode_name":"service"
}
}
}
执行上面的语句之后再次查询这条数据,barcode字段中就多了一个service的值

3.3.2 对字段值进行计算
使用下面的这段脚本对price进行计算
GET /books/_search
{
"script_fields": {
"get_price": {
"script": {
"lang": "painless",
"source": "doc['price'].value * params.num",
"params":{
"num":10
}
}
}
}
}得到如下结果

当然也可以使用expression来做,执行语句如下
GET /books/_search
{
"script_fields": {
"get_price": {
"script": {
"lang": "expression",
"source": "doc['price'].value * num",
"params":{
"num":10
}
}
}
}
}3.3.3 对字段值进行计算并输出多个结果
也可以自定义多个参数,根据需要输出多个参数的计算结果值,如下,为一个书本打折扣的场景,分别输出在9折,8折,7折下的价格
GET /books/_search
{
"script_fields": {
"get_price": {
"script": {
"lang": "painless",
"source": "[doc['price'].value * params.num_9,doc['price'].value * params.num_8,doc['price'].value * params.num_7]",
"params":{
"num_9":0.9,
"num_8":0.8,
"num_7":0.7
}
}
}
}
}执行结果如下

3.4 参数化脚本的存储
有些脚本可能在后续经常被使用到,就可以考虑将这些脚本存储到es的内存中,这就有点像mysql中的存储过程或函数一样。下面来看具体的操作流程。
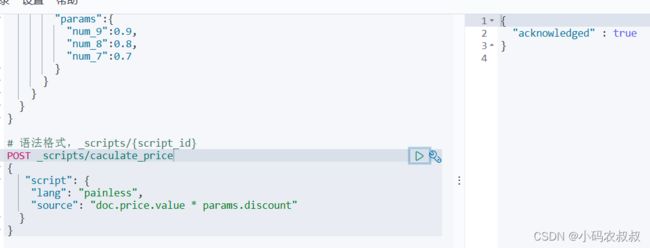
3.4.1 自定义一个参数脚本
自定义如下参数化脚本
# 语法格式,_scripts/{script_id}
POST _scripts/caculate_price
{
"script": {
"lang": "painless",
"source": "doc.price.value * params.discount"
}
}执行之后,将会在内存中存储一个参数化脚本的模板
3.4.2 查询脚本模板
使用下面的语句可以查询内存中存储的脚本模板

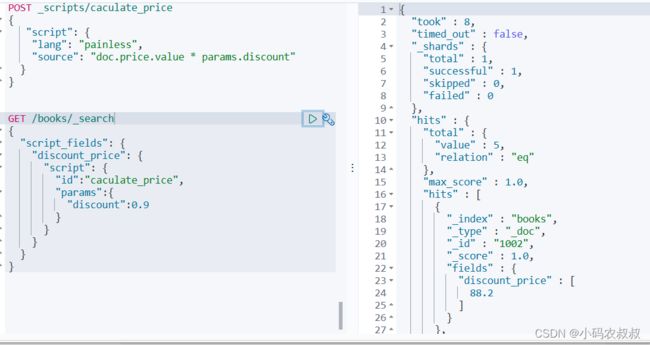
3.4.3 使用自定义脚本模板
在查询数据的时候,为了计算折扣后的值,就可以直接使用上面定义的脚本模板
GET /books/_search
{
"script_fields": {
"discount_price": {
"script": {
"id":"caculate_price",
"params":{
"discount":0.9
}
}
}
}
}得到如下的结果
四、Scripting 函数式编程
在上文通过实际案例演示了使用es的脚本编程的能力,细心的同学会发现,其实在上面的操作中,都是针对一些比较简单的场景进行使用,大多数基本上一行代码搞定,如果是更复杂的操作呢?比如既要更新字段的数据,同时也要对对数据进行计算等更复杂的操作呢,这时候就需要使用Scripting 的函数式编程了。官方文档地址: 官方文档
4.1 函数式编程格式
以上面的某个案例为例,如下是对1005数据的字段进行修改
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source": "ctx._source.barcode.add(params.barcode_name)",
"params":{
"barcode_name":"service"
}
}
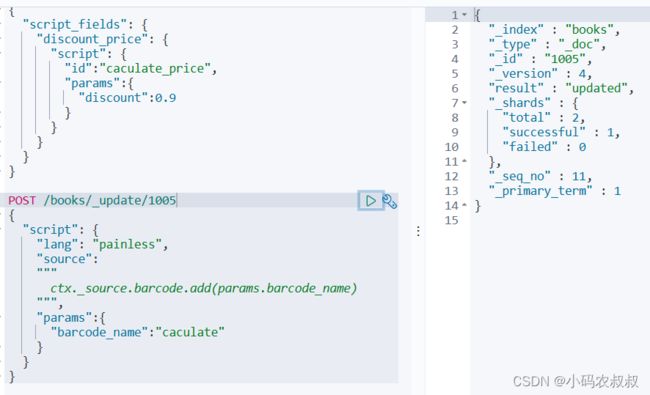
}如果使用函数式编程的,在上面的脚本中,需要对 source这里做如下调整,即source后面的表达式使用3个引号包裹起来,如下所示
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source":
"""
ctx._source.barcode.add(params.barcode_name)
""",
"params":{
"barcode_name":"caculate"
}
}
}那么在做业务编码时,只需在3个引号中做即可,执行上面的脚本,效果类似
4.2 函数式编程使用
进入es官方文档:https://www.elastic.co/guide/en/elasticsearch/painless/7.10/painless-lang-spec.html ,可以看到更多关于函数式编程的操作使用,可以结合这些示例进行使用,比如在官方文档中看到可以支持更多的语法,像if,try等

下面结合上述的books这个索引中的相关数据进行操作说明
4.2.1 同时操作多个字段
对当前索引中的id为1005的数据price值+10,同时给每条数据的barcode添加一个新的标签mark,参考如下的语句;
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source":
"""
ctx._source.barcode.add(params.barcode_name);
ctx._source.price += 10
""",
"params":{
"barcode_name":"mark"
}
}
}
检查是否执行成功

4.2.2 条件表达式
在script脚本中,也支持对条件表达式的使用,比如在某些情况下需要结合业务对字段进行判断,就可以使用if来处理,如下,是对1005这条数据的操作
POST /books/_update/1005
{
"script": {
"lang": "painless",
"source":
"""
if(ctx._source.price > 100){
ctx._source.price = 100;
}
""",
"params":{
"barcode_name":"mark"
}
}
}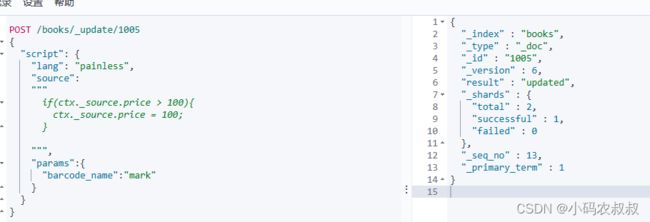
执行成功后,确认数据是否修改成功

4.2.3 数据统计与聚合
统计数据中price大于100的数据,如下
GET /books/_search
{
"aggs": {
"big100_total_count": {
"cardinality": {
"script": {
"source":
"""
if(doc['price'].value < 100) { return null ; } else { return doc['_id'].value}
"""
,
"lang": "painless"
}
}
}
}
}执行结果如下,当前查到了2条数据

五、写在文末
es脚本编程在某些特殊的场景下可以发挥很大的用场,也算是es众多高级功能中一个重要的组成部分,合理使用es的脚步语言编程,可以给实际工作带来意想不到的效果,感兴趣的同学可以深入学习。