重复性管理--从泛值到泛型以及泛函(上)--泛型是什么及为什么
在之前, 我们谈论了 计算机科学是什么, 我们知道了计算机科学重点在于复杂性的管理, 然后在 复杂性管理与重复性管理 里我们又谈到了复杂性一个重要来源, 也就是重复性. 软件开发的一个重要主题就是要管理重复性, 或者简单说, 减少重复.
你也许听过所谓的 DRY 原则: Don’t Repeat Yourself. 别重复(你自己)!
之前的一些都是侧重于理论方面, 现在来看一些具体地例子.
泛值
有些重复是比较简单的, 这种重复很容易被我们识别并管理. 取经常用到的"保存 save"为例, 假如我们要保存学生 A, 那么写了个如下的方法:
public void saveStudentA() {
// TODO pseudo code
// insert A into table Student
}
注: 如无特别说明, 均指 Java.
如果又要保存学生 B, 那么又再写一个方法:
public void saveStudentB() {
// TODO pseudo code
// insert B into table Student
}
那么, 即便是初学者, 也能感觉这样写是存在巨大的问题的, 明显有很大的重复以及各种硬编码(hard code).
要保存的学生可能成千上万, 不可能为每存一个学生都写一个单独的方法!
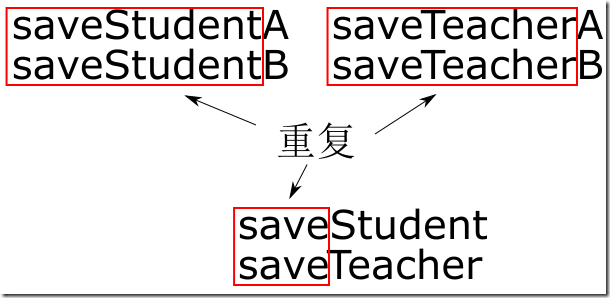
正确的做法应该是把值泛化(generic). 通过抽象出一种模式, 把非常具体化的 saveStudentA 和 saveStudentB 抽象成 saveStudentXXX.
XXX 可谓是一种"泛化"或者说"一般化(general)“, 相当于"某某某”, 泛指某个学生, 而不具体指谁, 以避免硬编码.
所谓的"泛", 就是特殊到一般的过程, 或者说是具体到抽象的过程.
A 和 B 是特殊的, 而 XXX 则是一般的;
又或者说 A 和 B 是具体的, 而 XXX 则是抽象的.
经过泛化后, 也即值被"参数化(parameterized)"了, 最终得到 saveStudent, 如下:
public void saveStudent(Student xxx) {
// TODO pseudo code
// insert xxx into table Student
}
这种做法非常普遍, 以至于我们不觉得这有什么值得说的.
泛型(generic type)
在上一步, 我们得到了 saveStudent, 事情是否结束了呢? 怎么说呢, 这有时要看你站在哪个角度去谈.
假如你和你一个同事在开发一套系统, 你负责"学生模块", 你有一个 saveStudent方法;你的同事负责"教师模块", 他有一个 saveTeacher 方法.
public void saveTeacher(Teacher xxx) {
// TODO pseudo code
// insert xxx into table Teacher
}
对你们个体而言, 重复的问题在各自模块中已经解决了. 但站在一个更高的位置去看, 比如以架构师的角度去看整个系统, 那么他将发现还是存在有重复.
saveStudent 和 saveTeacher 还是有重复, 不是吗? 即便是最直观的角度看, "save"还是重复了.
如果把具体的实现也写出来, 我们会看到更多的重复, 比如可能都要先获取一个数据库连接, 然后是保存后的提交, 还有可能的异常处理的代码等.
还有硬编码吗? 你可能会想, 已经不存在硬编码了呀. 无论是学生还是教师, 都是通过参数传递进来的, 好像没有什么是写死了的? 但当我们仔细观察方法的签名中的参数部分, 不难发现其实**类型是写死的: **

比如 saveStudent 只能接受 Student 类型;
而 saveTeacher 只能接受 Teacher 类型.
那么还能进一步去抽象吗? 比如把类型也泛化? 也像之前那样参数化可以吗? 在进一步阐述之前, 我们轻松一下, 先看个孔子的小故事.
有教无类
孔夫子作为一个大教育家, 曾提出这样一个观点: 有教无类.
所谓"有教无类", 简单地用现在的话说, 大概就是"你们是高富帅也好, 屌丝也罢(无类, 不去管学生的类型是什么), 我都愿意教你们(有教)".
[ ]
]
所以为啥他是大教育家呢? 也许就在于他这种态度, 不让自己局限在类别上, 比如说我只教富家子弟或者说只教贫困学子那样子.
他不挑剔所教人员的类型的, 而我们之前的两个方法则显然不是这样的:
saveStudent 只接受 Student 类型;
而 saveTeacher 则只接受 Teacher 类型.
能不能做到有存无类呢?
泛型方法
回到我们程序设计上的话题, 作为一个保存动作而言, 最好也不要局限在某个特别的类别上, 而是要更具通用性, 从而减少因类型不同而产生的重复. 我们可以这样来写(先不考虑它具体怎么实现):
public <XXX> void save (XXX xxx) {
// TODO pseudo code
// insert xxx into table XXX
}
那么通过这样一个**类型参数(type parameter)**的声明, 那么括号中的类型也被泛化了, 参数化了, 不再是"类型硬编码"了, 它也变成可变的了.
关于 XXX, 通常会写成 T, 表示 Type 的意思. 不过这就是一个类型参数的变量名而已, 所以你也可以随意取, 只要不存在冲突即可.
现在, 我们的值是活的, 类型也是活的, 都没有写死, 没有说你一定得传入什么类型的值才行. 这个方法不再对传入变量有类型约束了, 无论是 Student 还是 Teacher 类的实例都可以往里传. 比如:
// ...
Student s = new Student();
Teacher t = new Teacher();
service.save(s);
service.save(t);
父类型 vs 泛型
有人可能会想, 我用一个接口(或父类)不也能做到这些吗? 比如让 Student 和 Teacher 都实现一个叫 Entity 的接口(或是继承叫 Entity 的父类), 那么 save 方法以 Entity 作为类型:
public void save(Entity e) {
// TODO pseudo code
// insert e into table e.realType
}
不也同样可行吗? 泛型的意义在哪?
泛型返回值
现在让我们考虑更加一般的情况, 比如, 我们还想要返回值, 那么通过泛型方式我们可以这么写, 之前是返回 void, 现在返回 XXX 类型:
public <XXX> XXX save(XXX xxx) {
// TODO pseudo code
// insert xxx into table XXX
return xxx;
}
可以看到, 可以把返回值也用 XXX 来表示. 这就是说返回的值的类型由你传入的值的类型来决定, 它动态跟随传入的类型. 比如:
// ...
Student s = new Student();
Teacher t = new Teacher();
Student ss = service.save(s);
Teacher ts = service.save(t);
如果你用 Entity 接口, 那么你只能返回 Entity 接口, 要么你丢失了子类型:
// ...
// 丢失子类型
Entity ss = service.save(s);
Entity ts = service.save(t);
要么你就不得不做强制类型转换了:
// ...
// 强制类型转换
Student ss = (Student)service.save(s);
Teacher ts = (Teacher)service.save(t);
一个示例
我们通过一个更简单的例子来看下, 一个比较两个值哪个更大, 并返回那个更大的值的方法(bigger, 看谁逼格更高~).
public static <C extends Comparable<C>> C bigger(C c1, C c2) {
return c1.compareTo(c2) > 0 ? c1 : c2;
}
只要实现了 Comparable 接口, 这个类就能比较并返回较大的那个值, 无需做类型转换.
注: 为了简化代码, 这里没有考虑诸如两值相等之类的情况.
如:
String biggerString = bigger("hello", "hi");
Integer biggerInteger = bigger(new Integer(8), new Integer(5));
System.out.println(biggerString);
System.out.println(biggerInteger);
可以看到, bigger 方法既能够接收 String, 也能接收 Integer, 只要都实现了 Comparable 接口即可, 而且返回值的类型随着输入值的类型而变化, 无需做任何的强制类型转换.
你还能定义自己的类:
Bird longerBird = bigger(new Bird("18cm"), new Bird("12cm"));
Ball biggerBall = bigger(new Ball("A Cup"), new Ball("D Cup"));
System.out.println(longerBird);
System.out.println(biggerBall);
只要都实现接口即可:
public class Ball implements Comparable<Ball>{
private String size;
public Ball(String size) {
this.size = size;
}
@Override
public int compareTo(Ball ball) {
return size.compareTo(ball.size);
}
@Override
public String toString() {
return size + " ball";
}
}
public class Bird implements Comparable<Bird>{
private String length;
public Bird(String length) {
this.length = length;
}
@Override
public int compareTo(Bird bird) {
return length.compareTo(bird.length);
}
@Override
public String toString() {
return length + " bird";
}
}
模板(template)
现在, 让我们来总结一下. 泛型(generic type), 通常又叫参数化类型(parameterized type), 也即你可以通过"参数"来指定类型, 不过它与普通的参数不一样, 它是"类型参数", 然后, 突然间你就能简单地定义出能适用于很多不同类型的方法, 它是一个类型模板(template).
其实并没有所谓的"泛值"的说法. 既然泛型可以称之为"参数化类型", 逆推过去, "参数化值"自然也可以称之为"泛值"了. (如果你觉得有点牵强也很正常, 那样子真是的"参数化值"吗? 总之, 要想想出一个准确而又简短的名字去概括某件事情是有些困难的, 暂时只好这样了, 后面的泛函也是如此. )
说到模板你能想到什么呢? JSP? Freemarker? Velocity? 没错, 它与这些东西很相似. 以一个这样的页面模板为例:
你好, ${name}!
那么当 name="狗剩"时, 结果就变成:
你好, 狗剩!
而当 name="丫蛋"时, 结果就变成:
你好, 丫蛋!
如果你搞过动态网页开发, 这些对你来说再熟悉不过了. 现在假如说我们的模板是这样子呢:
public $ {type} bigger($ {type} t1, ${type} t2)
那么当 type="String"时, 你能得到
public String bigger(String t1, String t2)
而当 type="Integer"时, 你能得到
public Integer bigger(Integer t1, Integer t2)
没错, 泛型正是类似这样的模板技术.
这也就是所谓的 元编程(meta-programming) 了, 是代码的代码, 抽象之抽象.
想像一下, 如果没有泛型, 你想让方法能适应多个类型, 那么你只能是不断的重写(overwrite)你的方法:
public static String bigger(String b1, String b2) {
return b1.compareTo(b2) > 0 ? b1 : b2;
}
public static Integer bigger(Integer b1, Integer b2) {
return b1.compareTo(b2) > 0 ? b1 : b2;
}
这里面你可以看到你的方法(具体而言是里面的算法)在不断重复.
从字面上看, 代码完全一样!
更糟糕的是, 它还无法适应用户不断新定义的类, 用户每新定义一个类, 你可能就要再增加一个方法.
// ...
public static Foo bigger(Foo b1, Foo b2) {
return b1.compareTo(b2) > 0 ? b1 : b2;
}
强类型带来了好处, 但有时它也成了合作的阻碍, 明明很相似的东西, 因为类型横亘在那里, 你只能眼巴巴看着代码不断重复而无法去整合. 泛型机制弥补了这样缺陷.
泛型类
前面谈的是方法层面的泛型, 但在类层面, 也可以定义泛型的类型参数.
类型的一个重要作用就是它上面定义的操作, 比如上面的 bigger, 即便是泛型, 还是继承自 Comparable 接口以获取 compareTo 方法.
但有时, 我们完全不关心类型上能执行什么操作, 有时只不过是要"持有它", 然后之后我们可能需要"取回它", 只要它是一个"东西"就行了, 我们完全不关心它是什么类型, 也不希望类型成为我们实现的障碍.
你可能已经想到了, 我说的容器类. 下面定义一个简单的泛型容器类:
public class MyList<XXX> {
private XXX[] arr;
private int i;
// TODO constructor...
public XXX get(int i) {
return arr[i];
}
public void add(XXX xxx) {
arr[i] = xxx;
i++;
}
}
那么当我们声明 MyList strList = new MyList<>(); 时, 就好像我们新定义了一个 ListString 的类那样:
public class ListString {
private String[] arr;``
private int i;
// TODO constructor...
public String get(int i) {
return arr[i];
}
public void add(String xxx) {
arr[i] = xxx;
i++;
}
}
声明的过程就好像用一个具体的类型去实例化它一样, 它里面的 add 和 get 方法也随之成为了能接收 String 参数和返回 String 参数的方法.
自然, 当我们声明 MyList 时, 情形也是与前面说到泛型方法时类似, 就好像我们又定义了一个 ListInteger 的类那样:
public class ListInteger {
private Integer[] arr;
private int i;
// TODO constructor...
public Integer get(int i) {
return arr[i];
}
public void add(Integer xxx) {
arr[i] = xxx;
i++;
}
}
对于自定义的类比如 Foo, 这个原理也是一样的, 这里就不再列举代码了.
此时, 泛型类成为了我们的模板, 是普通类的模板, 是元编程的又一个体现, 是代码的代码, 抽象之抽象!
如果你留心一下容器类里面的方法, 你发现什么了? 这些方法名都很简短, 比如 get, put, add 等, 就像我们的 save 一样, 它没有说是 getString 或者 getInteger 这样的方法, 它们完全是与具体类型解耦的, 是与类型无关的, 是适用于所有类型的.
类型安全问题
在早期没有泛型机制时, 要想让容器类变得通用, 算法只实现一遍, 那么就只能把所有类的老祖宗 Object 请出来作为方法的类型. 这样在拿出来的时候几乎总是要进行类型转换, 而且要冒一些风险, 因为放进去的过程也没有了类型检查.
List list = new ArrayList();
// 放进去是 String
list.add("a string");
// 取出来就只能是 Object
Object obj = list.get(0);
// 或者需要强制类型转换
String s = (String) list.get(0);
所谓的类型安全问题就是这么来的. 但不要误会, 泛型的出现本质上不是为了解决所谓的类型安全问题.
解决安全问题有很简单的方式, 每来一个类型, 我们可以简单重复一遍那些类似的代码, 一样可以带来安全.
就像前面示例的那样, ListString, ListInteger, ListFoo…你每来一个类型, 我就再定义一个与之对应的容器类.
但是我们肯定不愿意这样去做!泛型的出现, 真正的驱动力来自于对重复性的管理, 如何消除重复的代码, 如何让一套算法, 一套代码更具有通用性, 如何使代码得到复用, 而与此同时又能保证类型安全.
甚至说, 我们先让代码用重复的方式解决类型安全的问题, 然后我们观察这些重复的代码, 注意到只有类型的差别, 我们参数化这些差别, 最终出现了泛型这种编程范式.
总结
现在, 让我们来总结一下, 从泛值到泛型, 抽象程度在不断提升, 差异被不断的外部化, 参数化, 最终只剩下一个动词, 与具体值无关, 与具体类型也无关.
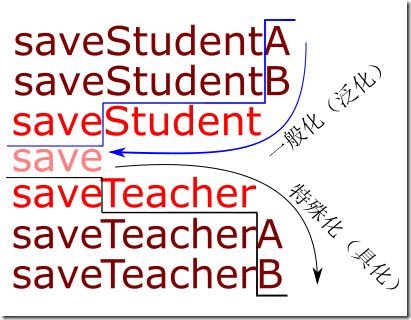
这里的核心就在于模式识别, 标识出相同的与差异的部分, 把差异部分参数化, 保留下相同的部分, 也即是所谓提炼出了模式.


往后, 我们将提炼出越来越大, 也越来越抽象的模式. 由于篇幅问题, 关于泛函的方面, 留到下篇再分析.