Python3爬虫教程之ADSL拨号爬虫ip池的使用
在我之前做爬虫经常需要维护自己的爬虫ip池,他可以挑选出很多有用的爬虫地址,因为不是专业的而且这些爬虫ip通常是公共爬虫ip,所以可用率不是太高,而且这样类型的地址很大情况下都是多人共用的,被封地址概率很大。另外要说的是这些爬虫ip时效也非常的短,虽然筛选过后但是还是避免不了这样的问题存在。
之前我们也了解了付费爬虫ip的使用,付费爬虫ip的质量相对免费爬虫ip就会好不少,这的确已经是一个相对不错的方案了,但本节要介绍的方案可以使我们既能不断更换爬虫ip,又可以保证爬虫ip的稳定性。
在一些付费爬虫ip套餐中,大家可能会注意到有这样的一个套餐 - 独享爬虫ip或私密爬虫ip,这种其实就是用了专用服务器搞得爬虫ip服务,相对一般的付费爬虫ip来说,其稳定性更好,速度也更快,同时 IP 可以动态变化。这种独享爬虫ip或私密爬虫ip的 IP 切换大多数都是基于ADSL拨号机制来实现的,一台远程桌面每拨号一次就可以换一个 IP,同时远程桌面上搭建了爬虫ip服务,我们就可以直接使用该远程桌面的爬虫ip来进行数据爬取了。
本节我们就来实际操作一下ADSL拨号爬虫ip服务器的使用方法。
1、什么是 ADSL
ADSL,英文全称是 Asymmetric Digital Subscriber Line,即非对称数字用户环路。它的上行和下行带宽不对称,它采用频分复用技术把普通的电话线分成了电话、上行和下行 3 个相对独立的信道,从而避免了相互之间的干扰。
ADSL 通过拨号的方式上网,拨号时需要输入 ADSL 账号和密码,每次拨号就更换一个 IP。IP 分布在多个 A 段,如果 IP 都能使用,则意味着 IP 量级可达千万。如果我们将 ADSL 主机作为爬虫ip,每隔一段时间远程桌面拨号就换一个 IP,这样可以有效防止 IP 被封禁。另外,由于我们是直接使用专有的远程桌面搭建的爬虫ip服务,所以其爬虫ip的稳定性相对更好,爬虫ip响应速度也相对更快。
2、准备工作
在本节开始之前,我们需要先购买几台动态拨号远程桌面,建议2台或以上。因为远程桌面在拨号的一瞬间服务器正在切换 IP,所以拨号之后爬虫ip是不可用的状态,所以需要2台及以上远程桌面来做负载均衡。
首先准备了一台电信同时安装了 CentOS Linux 系统的远程桌面。
开通后我们可以在后台找到服务器的连接 IP、端口、用户名、密码,拨号所用的用户名和密码。

然后找到远程管理面板 − 远程连接的用户名和密码,也就是 SSH 远程连接服务器的信息。比如我使用的 IP 和端口是 zhengjiang.hahado.cn:30042,用户名是 root,命令行下输入如下内容:
ssh root@zhongweidx01.jsq.bz -p 30042
输入连接密码,就可以连接上远程服务器了,如图所示:
登录成功之后,我们便可以开始本节的正式内容了。
3、测试拨号
远程桌面默认已经配置了拨号相关的信息,如宽带用户名和密码等,所以我们无需额外进行配置,只需要调用相应的拨号命令即可实现拨号和IP地址的切换。
我们可以输入如下拨号命令来进行拨号:
pppoe-start
拨号命令成功运行,没有报错信息,耗时约几秒,结束之后整个主机就获得了一个有效的爬虫地址。
如果要停止拨号,可以输入如下命令:
pppoe-stop
运行完该命令后,网络就会断开,之前的地址也会被释放。
注意:不同的远程桌面的拨号命令可能不同,如某些远程桌面的拨号命令为 adsl-start 和 adsl-stop,请以官方文档的说明为准。
所以,如果要想切换地址,我们只需要将上面的两个命令组合起来,先执行 pppoe-stop,再执行 pppoe-start。每次拨号,ifconfig 命令观察主机的 IP,如图所示:
可以看到,这里我们执行了停止和开始拨号的命令之后,通过 ifconfig 命令获取的网卡信息的 IP 地址就变化了,所以我们成功实现了 IP 地址的切换。
好,那如果我们要想将这台远程桌面设置为可以实时变化 IP 的爬虫ip服务器的话,主要就有这几件事情:
在远程桌面上运行爬虫ip服务软件,使之可以提供 HTTP 爬虫ip服务。
实现远程桌面定时拨号更换地址。
实时获取远程桌面的爬虫ip和端口信息。
接下来我们就来完成这几部分内容吧。
4、设置爬虫ip服务器
当前我们使用的远程桌面使用的是 Linux 的 CentOS 系统,目前它是无法作为一个爬虫ip服务来使用的,因为该远程桌面上面目前并没有运行相关的爬虫ip软件。要想让该远程桌面提供HTTP爬虫ip服务,我们需要在其上面安装并运行相关的服务。
那什么软件能提供这种爬虫ip服务呢?目前业界比较流行的有 Squid 和 TinyProxy,配置完成之后它们会在特定端口上运行一个HTTP模式的爬虫ip。知道了该远程桌面当前的IP之后,我们就能使用该远程桌面上 Squid 或 TinyProxy 提供的HTTP爬虫ip了。
这里我们以 Squid 为例来进行一下配置。
首先我们安装一下 Squid,在 CentOS 的安装命令如下:
sudo yum -y update
yum -y install squid
运行完之后,我们便可以成功安装好 Squid 了。
如果要想启动 Squid,可以运行如下命令:
systemctl start squid
如果想配置开机自动启动,可以运行如下命令:
systemctl enable squid
Squid 成功运行之后,我们可以使用如下命令查看当前 Squid 的运行状态:
systemctl status squid
如图所示,我们可以看到 Squid 就成功运行了:
默认情况下,Squid 会运行在 3128 端口,也就是相当于在远程桌面的 127.0.0.1:3128 上启动了爬虫ip服务,接下来我们可以来测试下 Squid 的爬虫ip效果,在该台远程桌面上运行 curl 命令请求 https://httpbin.org,并配置使用远程桌面的爬虫ip:
curl -x http://127.0.0.1:3128 https://httpbin.org/get
这里 curl 的 -x 参数代表设置 HTTP 爬虫ip,由于这是在远程桌面上运行的,所以爬虫ip直接设置为了 http://127.0.0.1:3128。
运行完毕之后,我们再运行下 ifconfig 获取下当前远程桌面的 IP,运行结果如图所示:
可以看到返回结果的 origin 字段的 IP 就和 ifconfig 获取的地址是一致的。
接下来,我们在自己本机上(非远程桌面)运行如下命令测试下爬虫ip的连通情况,这里IP就需要更换为远程桌面本身的地址了,刚才可以看到远程桌面当前拨号的IP是 106.45.104.166,所以需要运行如下命令:
curl -x http://106.45.104.166:3128 https://httpbin.org/get
然而发现并没有对应的输出结果,爬虫ip连接失败。
其实原因在于默认情况下 Squid 并没有开启允许外网访问,我们可以进行 Squid 的相关配置,如更改当前爬虫ip运行端口、允许连接的 IP,配置高匿爬虫ip等等,这些都需要修改 /etc/squid/squid.conf 文件。
要允许公网访问,最简单的方案就是将 /etc/squid/squid.conf 中的该行:
http_access deny all
修改为:
http_access allow all
意思是允许来自所有IP的请求连接。
另外还需要在配置文件的开头acl配置的部分添加该行内容:
acl all src 0.0.0.0/0
另外我们还想将 Squid 配置成高度匿名爬虫ip,这样目标网站就无从通过一些参数如 X-Forwarded-For 来得知爬虫机本身的 IP 了,所以在配置文件中再添加如下配置:
request_header_access Via deny all
request_header_access X-Forwarded-For deny all
另外有的远程桌面厂商可能默认封禁了 Squid 的 3128 端口,建议更换一个端口,比如 3328,修改改行:
http_port 3128
修改为:
http_port 3328
修改完配置之后保存配置文件,然后重新启动 Squid 即可:
systemctl restart squid
这时候在本机上(非远程桌面)重新运行刚才的 curl 命令,同时更改下端口:
curl -x http://106.45.104.166:3328 https://httpbin.org/get
即可得到返回结果:
{
"args": {},
"headers": {
"Accept": "*/*",
"Host": "httpbin.org",
"User-Agent": "curl/7.64.1",
"X-Amzn-Trace-Id": "Root=1-60ea8fc0-0701b1494e4680b95889cdb1"
},
"origin": "106.45.104.166",
"url": "https://httpbin.org/get"
}
这时候我们就可以在本机上直接使用远程桌面的爬虫ip了!
5、动态获取爬虫IP
现在我们已经可以执行命令让主机动态切换地址了,同时也在主机上编辑好爬虫ip服务了,接下来我们只需要知道拨号后的地址就可以使用爬虫ip了。
那怎么动态获取拨号主机的地址呢?又怎么来维护这些爬虫ip呢?怎么保证获取到的爬虫ip一定是可用的呢?这时候我们可能想到一些问题:
如果我们只有一台拨号远程桌面并设置了定时拨号的话,那么在拨号的几秒时间内,该远程桌面提供的爬虫ip服务是不可用的。
如果我们不用定时拨号的方法,而想要在爬虫端控制拨号远程桌面的拨号操作的话,爬虫端还需要单独的逻辑来处理拨号和重连的问题,这会带来额外的开销。
综合考虑下来,一个比较好的解决方案是:
为了不增加爬虫端的逻辑开销,爬虫端应该无需关心拨号远程桌面的拨号操作,我们只需要保证爬虫通过某个接口获取到的爬虫ip是可用的就行了,拨号远程桌面的爬虫ip的维护逻辑和爬虫是毫不相关的。
为了解决一台拨号远程桌面在拨号时爬虫ip不可用的问题,我们需要有多台远程桌面同时提供爬虫ip服务,我们可以将不同远程桌面的拨号时段错开,当一台远程桌面正在拨号时,我们可以用其他远程桌面顶替。
为了更加方便地维护和使用爬虫ip,我们可以像前文介绍的爬虫ip池一样把这些远程桌面的爬虫ip统一维护起来,所有拨号远程桌面的爬虫ip统一存储到一个公共的 Redis 数据库中,可以使用 Redis 的 Hash 存储方式,存好每台远程桌面和对应爬虫ip的映射关系。拨号远程桌面拨号前将自己对应的爬虫ip内容清空,拨号成功之后再将爬虫ip更新,这样 Redis 数据库中的爬虫ip就一定是实时可用的爬虫ip了。
利用这种思路,我们要做的其实就有如下几点:
配置一个可以公网访问的 Redis 数据库,每台远程桌面可以将自己的爬虫ip存储到对应的 Redis 数据库中,由该 Redis 数据库维护这些爬虫ip。
申请多台拨号远程桌面并按照上文所述配置好 Squid 爬虫ip服务,每台远程桌面设置定时拨号来更换 IP。
每台远程桌面在拨号前删除 Redis 数据库中原来的爬虫ip,拨号成功之后测试一下爬虫ip的可用性,将最新的爬虫ip更新到 Redis 数据库中即可。
OK,接下来我们就来操作一下吧。
由于远程桌面要进行 Redis 数据库的操作,所以我们可以使用 Python 来实现,所以先在远程桌面上装下 Python:
yum -y install python3
关于自动拨号、连接 Redis 数据库、获取本机爬虫ip、设置 Redis 数据库的操作,我已经写好了一个 Python 的包并发布到 PyPi 了,我们可以直接使用这个包来完成如上的功能,这个包叫做 adslproxy,可以在远程桌面上使用 pip3 来安装:
pip3 install adslproxy
安装完毕之后,我们可以使用 export 命令设置下环境变量:
export REDIS_HOST=<Redis数据库的地址>
export REDIS_PORT=<Redis数据库的端口>
export REDIS_PASSWORD=<Redis数据库的密码>
export PROXY_PORT=<拨号远程桌面配置的爬虫ip端口>
export DIAL_BASH=<拨号脚本>
export DIAL_IFNAME=<网卡名称>
export CLIENT_NAME=<远程桌面的唯一标识>
export DIAL_CYCLE=<拨号间隔>
这里 REDIS_HOST、REDIS_PORT、REDIS_PASSWORD 就是远程 Redis 的连接信息,就不再赘述了。PROXY_PORT 就是远程桌面上爬虫ip服务的端口,我们已经设置为了 3328。DIAL_BASH 就是拨号的命令,即 pppoe-stop;pppoe-start,当然该脚本的内容不同的远程桌面厂商可能不同,以实际为准。DIAL_IFNAME 即拨号远程桌面上的网卡名称,程序可以通过获取该网卡的信息来获取当前拨号主机的 IP 地址,通过上述操作可以发现,网卡名称叫做 ppp0,当然这个名称也是以实际为准。CLIENT_NAME 就是远程桌面的唯一标识,用来在 Redis 中存储主机和爬虫ip的映射,因为我们有多台远程桌面,所以不同远程桌面的名称应该设置为不同的字符串,比如 adsl1、adsl2 等等。
这里我们设置如图所示:

设置好环境变量之后,我们就可以运行 adslproxy 命令来进行拨号了,命令如下:
adslproxy send
运行结果如下:
2021-07-11 15:30:03.062 | INFO | adslproxy.sender.sender:loop:90 - Starting dial...
2021-07-11 15:30:03.063 | INFO | adslproxy.sender.sender:run:99 - Dial started, remove proxy
2021-07-11 15:30:03.063 | INFO | adslproxy.sender.sender:remove_proxy:62 - Removing adsl1...
2021-07-11 15:30:04.065 | INFO | adslproxy.sender.sender:remove_proxy:69 - Removed adsl1 successfully
2021-07-11 15:30:05.373 | INFO | adslproxy.sender.sender:run:111 - Get new IP 106.45.105.33
2021-07-11 15:30:15.552 | INFO | adslproxy.sender.sender:run:120 - Valid proxy 106.45.105.33:3328
2021-07-11 15:30:16.501 | INFO | adslproxy.sender.sender:set_proxy:82 - Successfully set proxy 106.45.105.33:3328
2021-07-11 15:33:36.678 | INFO | adslproxy.sender.sender:loop:90 - Starting dial...
2021-07-11 15:33:36.679 | INFO | adslproxy.sender.sender:run:99 - Dial started, remove proxy
2021-07-11 15:33:36.680 | INFO | adslproxy.sender.sender:remove_proxy:62 - Removing adsl1...
2021-07-11 15:33:37.214 | INFO | adslproxy.sender.sender:remove_proxy:69 - Removed adsl1 successfully
2021-07-11 15:33:38.617 | INFO | adslproxy.sender.sender:run:111 - Get new IP 106.45.105.219
2021-07-11 15:33:48.750 | INFO | adslproxy.sender.sender:run:120 - Valid proxy 106.45.105.219:3328
...
这里我们就可以看到,因为远程桌面在拨号之后当前爬虫ip就会失效了,所以在拨号之前程序先尝试从 Redis 中删除当前远程桌面的爬虫ip。接下来就开始执行拨号操作,拨号成功之后验证一下爬虫ip是可用的,然后再将该爬虫ip存储到 Redis 数据库中。循环往复运行,我们就达到了定时更换 IP 的效果,同时 Redis 数据库中也是实时可用的爬虫ip。
最后按照同样的配置,我们可以购买多台拨号远程桌面并进行如上同样的设置,这样就有多个稳定的定时更新的爬虫ip可用了,Redis 中会实时更新各台远程桌面的爬虫ip,如图所示。

图中所示是四台 ADSL 拨号远程桌面配置并运行后 Redis 数据库中的内容,其中的爬虫ip都是实时可用的。
6、使用爬虫ip
那怎么使用爬虫ip呢?我们可以在任意可以公网访问的远程桌面上连接刚才的 Redis 数据库并搭建一个 API 服务即可。怎么搭建呢?我们可以同样使用刚才的 adslproxy 库,该库也提供了 API 服务的功能。
为了方便测试,我们在本机进行测试,安装好 adslproxy 包之后,然后设置好 REDIS 相关的环境变量:
export REDIS_HOST=<Redis数据库的地址>
export REDIS_PORT=<Redis数据库的端口>
export REDIS_PASSWORD=<Redis数据库的密码>
然后运行如下命令启动即可:
2020-07-11 16:31:58.651 | INFO | adslproxy.server.server:serve:68 - API listening on http://0.0.0.0:8425
可以看到 API 服务就在 8425 端口上运行了,我们打开浏览器即可访问首页,如图所示:
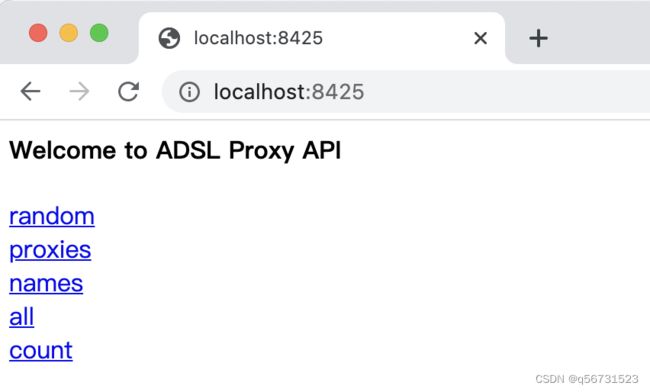
其中最重要的就是 random 接口了,我们使用 random 接口即可获取 Redis 数据库中的一个随机爬虫ip,如图所示:

测试下可用性也没有问题,这样爬虫就可以使用这个爬虫ip来进行数据爬取了。
最后,我们将 API 服务部署一下,这个 ADSL 爬虫ip服务就可以像爬虫ip池一样被使用了,每请求一次API就可以获取一个实时可用爬虫ip,不同的时间段这个爬虫ip就会实时更换,而且连接稳定速度又快,实在是网络爬虫的最佳搭档。
7、总结
本节我们介绍了ADSL拨号爬虫ip的由来。通过这种爬虫ip,我们可以无限次更换IP,而且线路非常稳定,爬虫抓取效果也会好很多。