【数据可视化】通过使用网络爬虫对数据爬取并进行可视化分析
文章目录
- 项目介绍
- 一、Python网络爬虫介绍
- 二、数据爬取
-
- 1.引入所需的库
- 2.网页解析
- 3.网页内容爬取
- 三、数据分析与可视化
-
- 1.分析学院历年创建课程数
- 2.分析学院历年课程点击量
- 3.分析学院每月课程创建数量
- 4.学院课程词云图
- 总结
项目介绍
本次项目所爬取的网页为柳州职业技术学院电子信息工程学院的超星学习通课程中心。在该网页中可以查看到电子信息工程学院历年的超星课程创建情况,还可以进入到课程界面查看相应的教学资源。
在该网页中,详细记录了课程序号、课程名称、课程链接、所属院系、课程负责人、课程点击量、课程创建时间等信息,本次项目采用爬虫针对这些网页信息进行获取,数据清理和数据分析,进行简单的数据可视化处理,挖掘出数据的价值,并在一定的条件下对数据进行应用。

一、Python网络爬虫介绍
在学习python网络爬虫中,我们常用的对网页数据进行爬取的方法主要有以下几种。
1.使用正则表达式对网页数据进行提取。
2.使用xpath查询网页节点,提取出网页有用的信息。
3.使用Beautiful Soup解析和提取网页中信息。
4.使用json,解析使用AJAX技术通过json格式传输数据的网页。
5.通过网页自动化工具,对网页数据进行自动化提取。
二、数据爬取
1.引入所需的库
源代码:
import requests
from lxml import etree
import pandas as pd
本次项目首先导入requests 库来获取网页内容,导入 lxml 库来解析网页内容,导入 pandas 库来创建表格并将数据存入Excel文件中。
2.网页解析
源代码:
# 定义函数用来爬取网站的课程信息
def get_lzzy_dzxx():
# 初始化结果列表,并添加列名
result=[['序号','课程链接','课程名称','所属院系','负责人','点击量','创建日期']]
# 循环访问网站的每一页
for i in range(65):
# 构造网站的URL
url = f'http://lzzy.fanya.chaoxing.com/portal/courseNetwork/list?pageSize=10&keyword=&departmentId=2262486&order=0&sort=createTime&pageNum={i+1}'
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
# 获取网页内容
res = requests.get(url=url, headers=headers)
# 解析网页内容
html = etree.HTML(res.text)
定义了一个函数 get_lzzy_dzxx,该函数用来爬取网站的课程信息。函数中使用了一个循环,用来访问网站中的每一页。每一次循环时,通过构造特定的url并使用 requests 库来获取网页内容,然后使用 lxml 库的 etree.HTML 函数来解析网页。
3.网页内容爬取
源代码:
# 获取所有tr
tr_list = html.xpath('//table//tr')
# 循环每一行并获取行内信息
for tr in tr_list[1:]:
#序号
xuhao = tr.xpath('./td[1]/text()')[0]
#课程链接
course_url=tr.xpath('./td[3]/a/@href')[0]
#课程名称
name=tr.xpath('./td[3]/a/text()')[0].strip()
#所属院系
college=tr.xpath('./td[4]/text()')[0]
#负责人
teacher=tr.xpath('./td[5]/text()')[0]
#点击量
click=tr.xpath('./td[6]/text()')[0]
#创建日期
create_date=tr.xpath('./td[7]/text()')[0]
# 将信息加入结果列表
course_list=[xuhao,course_url,name,college,teacher,click,create_date]
print(course_list)
result.append(course_list)
# 创建表格并将数据存入Excel文件中
df=pd.DataFrame(result)
df.to_excel('电子信息工程学院课程中心.xlsx',header=None,index=False)
使用xpath语法来提取网页中的课程信息。xpath语法是一种用来提取网页中特定元素的方法。例如,//table//tr 表示在网页中查找所有的tr元素(即表格中的每一行),接着循环每一行并用xpath语法获取当前节点下的内容。
包括行内的序号、课程链接、课程名称、所属院系、课程负责人、课程点击量和课程创建时间。最后将课程信息存进结果列表中,并用pandas 库创建表格将数据存进excel文件中,至此完成了网页数据爬虫代码的编写。
三、数据分析与可视化
1.分析学院历年创建课程数
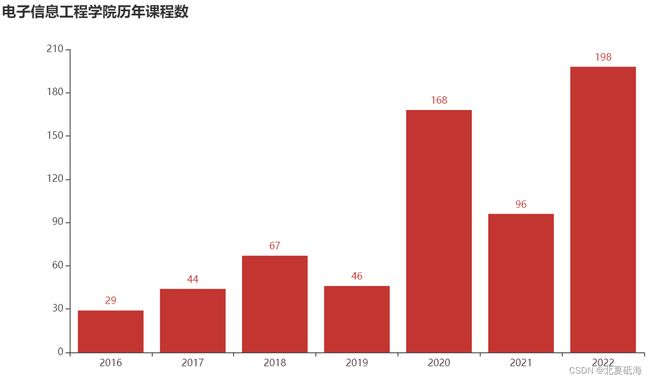
通过pandas将爬取到的数据进行预处理后和分析之后,我们使用pyechart将分析的结果绘制出来。我们可以看到电子信息工程学院的课程中心课程创建数量在逐年增长,从2020年开始,之后每年创建课程数量都特别多。
通过分析说明了学院不断提供更多的学习课程,和在线学习资源。对于使用线上学习平台的需求量也逐年上升,学院在不断满足学生和教师的需求,并且愿意投入更多的资源来支持在线学习。
2.分析学院历年课程点击量

在对历年各课程点击量总数进行汇总后,我们发现,2020年达到了一个非常高的峰值,原因可能是2020年口罩事件,学校无法组织线下学习,从而通过线上学习平台进行学习。进而导致2020年课程点击量剧增。
在随后的两年,由于措施的严密落实,学校能够恢复线下教学,学习平台的访问量较为稳定。同时2022年访问量和2021年相比,也实现了200万的增长。
3.分析学院每月课程创建数量

在对课程平台每月的课程创建数量进行统计分析时发现,3月和9月为两个高峰,课程创建数量最多。出现这种现象的原因有可能是,3月和9月为学校的开学季,很多教师可能会在课程平台上创建新的课程,以便更好地帮助学生学习。
4.学院课程词云图

通过爬取的课程名称绘制了电子信息工程学院课程词云图,通过词云图我们能够清晰的了解该学院的主要课程,哪些课程最热门,能够帮助学生加深对本学院的了解,同时在招生过程中也是给要进入该学院学习的学生很好的介绍材料。
总结
在本次课程中心数据爬取与分析项目中,在爬取数据方面,使用到了Python网络爬虫技术对数据进行获取,在数据分析方面采用了Pandas和pyecharts对数据进行处理分析和数据可视化。
在完成项目过程中,应用了之前课程所学习的知识,在爬虫代码编写过程中,适当添加简洁注释,注重代码的封装和调用,在数据分析过程中注重代码的数据量和数据价值,并通过所学知识进一步挖掘出其应用价值。通过这次项目练习,不仅提升了自己的技能水平,还为今后的工作或学习打下良好的基础。