Python 爬虫进阶篇——Selenium教程(2)

欢迎关注微信公众号:Python知识学堂
上次推文简单的介绍了Selenium工具,安装以及连接浏览器等相关操作。本次推文依然介绍Selenium工具的一些用法。
上次推文介绍了元素定位的问题,不知道的可以查看之前的文章,这里就不赘述了。
一、元素等待
如今,绝大部分的Web程序都使用AJAX技术。当页面加载时,该页面中的元素可能会以不同的时间间隔加载。这使定位元素变得困难,如果DOM中尚不存在元素,则定位函数将引发ElementNotVisibleException 异常。
必须等待元素加载完成后才可以使用定位函数,Selenium工具提供两种等待方式,可以解决此问题。
显示等待
显示等待指的是在某个条件成立后,再去执行相关代码。如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver=webdriver.Firefox()
# 用get打开百度页面
driver.get("http://www.baidu.com")
element=WebDriverWait(driver,5).until(
EC.presence_of_element_located((By.ID, "su"))
)
driver.find_element_by_id("kw").send_keys('python 知识学堂')
driver.find_element_by_id("su").click()使用WebDriverWait方法设置,上述代码表示的意思是,等待5s直到找到id=”su”的元素。
presence_of_element_located()方法是判断元素是否存在。
具体格式如下:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)driver :浏览器驱动。
timeout :最长超时时间,默认以秒为单位。
poll_frequency :检测的间隔(步长)时间,默认为0.5S。
ignored_exceptions :超时后的异常信息,
默认情况下抛NoSuchElementException异常。
WebDriverWait()一般与until()或until_not()方法配合使用。
until()需提供一个返回true的方法;
until_not()需提供一个返回false的方法;
那试一下报错的情况,如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver=webdriver.Firefox()
# 用get打开百度页面
driver.get("http://www.baidu.com")
element=WebDriverWait(driver,5).until(
EC.presence_of_element_located((By.ID, "python知识学堂"))
)
driver.find_element_by_id("kw").send_keys('python 知识学堂')
driver.find_element_by_id("su").click()上面的代码是找一个Id=”python知识学堂”的元素,这个是肯定找不到的。结果如下:
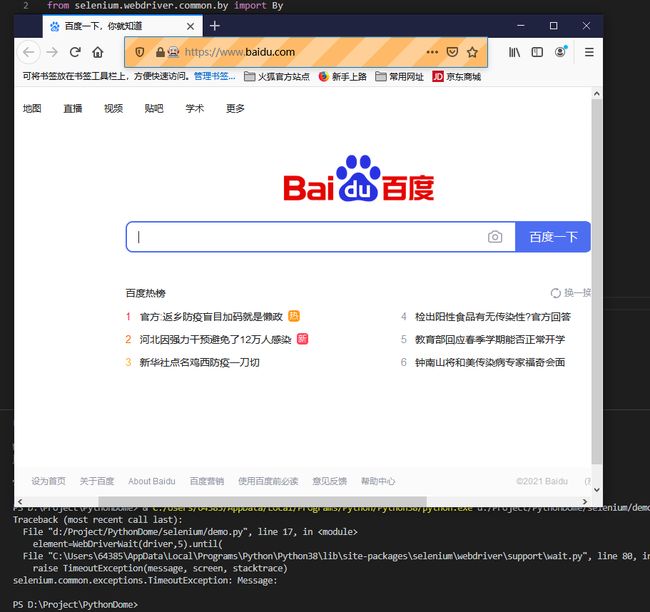
大家可以看到只打开了百度的网站,后面的并没有执行。
查看控制台发现报了TimeOutException的错误,表示的是在指定时间内没有找到指定的元素。
隐式等待
WebDriver提供了implicitly_wait()方法来实现隐式等待,默认设置为0。它的用法相对来说要简单得多。如下:
from selenium import webdriver
driver=webdriver.Firefox()
driver.implicitly_wait(10)
# 用get打开百度页面
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys('python 知识学堂')
driver.find_element_by_id("su").click()在browser.get('xxx')前就设置,针对所有元素有效,在查找所有元素时,如果尚未被加载,则等10秒。
那么我们来试一下错误的情况,如下:
from selenium import webdriver
driver=webdriver.Firefox()
driver.implicitly_wait(10)
# 用get打开百度页面
driver.get("http://www.baidu.com")
driver.find_element_by_id("python 知识学堂")
driver.find_element_by_id("kw").send_keys('python 知识学堂')
driver.find_element_by_id("su").click()结果如下:

显然也会报错——NoSuchElementException,提示找不到指定的元素。
显然隐式等待的方法要比显式等待的方式简便的多。
二、操作JavaScript
有些页面指令是无法通过Selenium Api实现的。webdriver提供了执行javascript的方法——execute_script()。如下:
from selenium import webdriver
driver=webdriver.Firefox()
# 用get打开百度页面
driver.get("http://www.baidu.com")
driver.execute_script("alert('python 知识学堂')")execute_script中执行的是弹出一个浏览器弹框,结果如下:

可以使用此方法来执行一些 Selenium Api执行不了的操作,比如滚动条等。不过你得对javaScript非常熟悉。
三、获取页面数据
我们之前操作了那么多无非是想要等到网站的html代码,便于我们分析等到想要的内容。WebDriver提供了page_source属性,可以等到当前页面的源码,如下:
from selenium import webdriver
driver=webdriver.Firefox()
# 用get打开百度页面
driver.get("http://www.baidu.com")
html=driver.page_source
print(html)通过page_source属性可以得到当前页面的源码,然后再通过一些解析库(如正则表达式、Beautiful Soup、Lxml等)来提取信息。
在公众号中可以查看正则表达式、Beautiful Soup、Lxml等相关教程。
四、总结
本次推文介绍了Selenium工具中的元素等待、调用javascript脚本以及获取页面的代码等操作。在实际中都有重要的作用。