win10java配置环境变量msi_win10安装java+hadoop+spark
前言
操作系统win10
安装时间2018年12月
java版本jdk1.8.0_191
hadoop版本hadoop-2.8.5
spark版本spark-2.3.1-bin-hadoop2.7
Java安装
方法一
下载
这时有两种JDK可以选择,如下两图,选其中一种即可:(疑问,这两种有什么区别?)
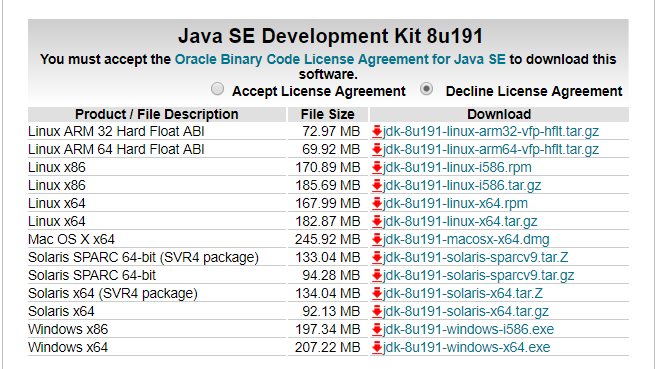
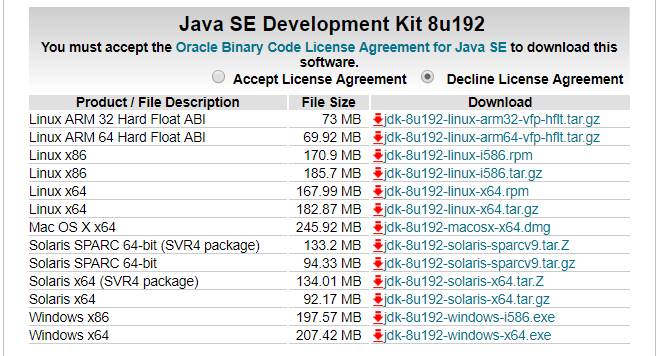
配置环境变量
选择两种JDK其中一种下载好,开始安装,,完成之后,环境变量配置:
操作
变量名
变量值
新建
JAVA_HOME
安装路径jdk
新建
CLASSPATH
.;安装路径jdk\bin;安装路径jdk\lib\dt.jar;安装路径jdk\lib\tools.jar;
增加
PATH
安装路径jdk\bin;安装路径jdk\jre\bin;
方法二
下载
选择对应的exe文件进行下载:
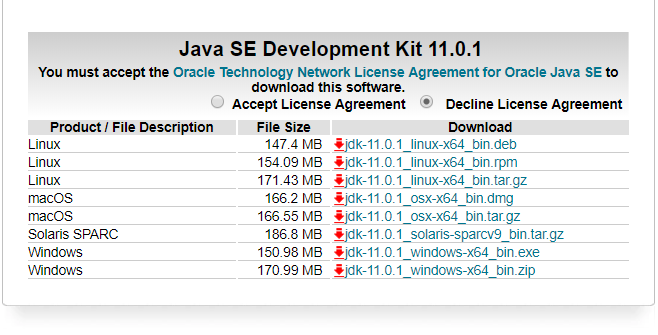
配置环境变量
开始安装,完成之后,环境变量配置:
操作
变量名
变量值
新建
JAVA_HOME
安装路径
新建
CLASSPATH
安装路径\lib
增加
PATH
安装路径\lib
测试
C:\Users\yun>java -version
java version "11.0.1" 2018-10-16 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.1+13-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.1+13-LTS, mixed mode)
C:\Users\yun>javac -version
javac 11.0.1
hadoop安装
下载
最新几个版本的hadoop 网址,如下图所示:
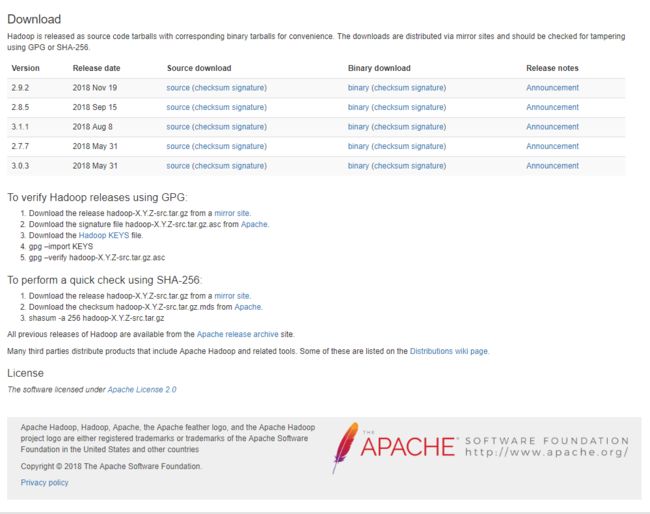
选择'Source download'或或者'Binary download'进入如下页面,下载文件:

配置环境变量
解压文件,环境变量配置:
操作
变量名
变量值
新建
HADOOP_HOME
解压路径
增加
PATH
解压路径\bin
Scala安装
下载
Scala 官网
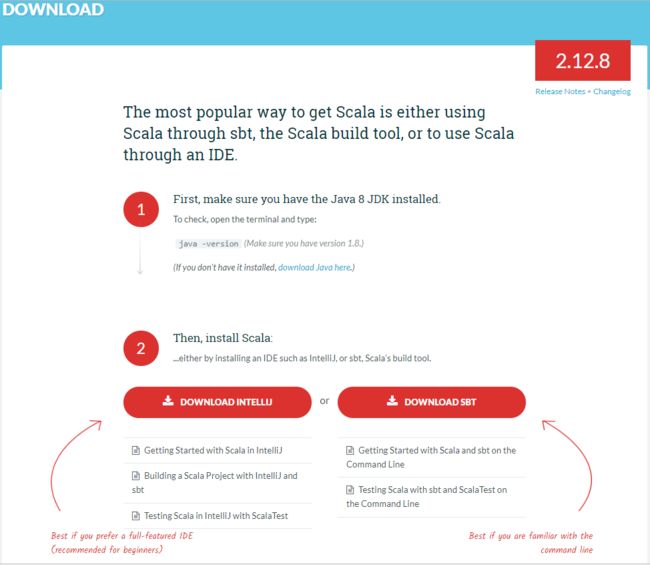
浏览到网址最下面(选msi文件安装更省事哦):

配置环境变量
开始安装,完成之后,环境变量配置(使用msi文件安装默认会配置好,如果没有配置,如下表配置):
操作
变量名
变量值
增加
PATH
安装路径\bin
测试
C:\Users\yun>scala -version
Scala code runner version 2.12.8 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
Spark安装
方法一
下载
Apache Spark™ 官网
按照网址提示步骤,'Choose a Spark release'-->'Choose a package type'-->'Download Spark':
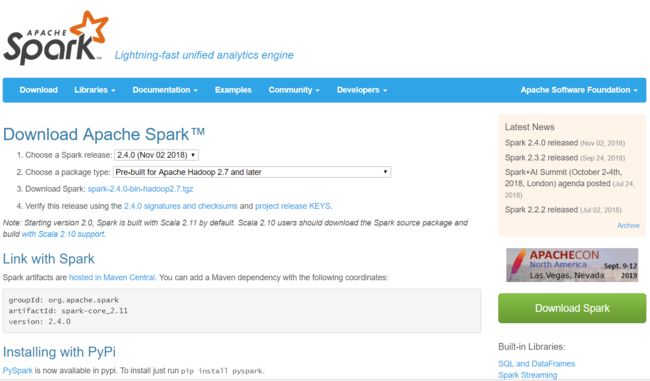

复制文件
配置环境变量
解压文件
把'解压路径\python\pyspark'文件夹复制到'python安装路径\Lib\site-packages'文件夹里面
环境变量配置:
操作
变量名
变量值
新建
SPARK_HOME
解压路径
增加
PATH
解压路径\bin
测试
(退出spark-shell时提示“ERROR ShutdownHookManager:91 - Exception while deleting Spark temp dir:.....(省略)”,未解决)
C:\Users\yun>spark-shell
......(省略)
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://10.135.110.114:4040
Spark context available as 'sc' (master = local[*], app id = local-1544323487923).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 11.0.1)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
方法二
(疑问:选择这种方法可以不需要安装Scala?)
下载
pip install pyspark
测试
C:\Users\yun>pyspark
Python 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
......(省略)
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 3.7.0 (default, Jun 28 2018 08:04:48)
SparkSession available as 'spark'.
>>>
两种方法的区别
方法一:
'spark-shell'命令和'pyspark'命令位于'spark解压路径\lib'中
把'解压路径\python\pyspark'文件夹复制到'python安装路径\Lib\site-packages'文件夹里面
方法二:
'spark-shell'命令和'pyspark'命令位于'python安装路径\Scripts'中
执行的文件'是pip install pyspark'命令时安装在'python安装路径\Lib\site-packages'中的包
说明:
疑问:环境变量是按照顺序来执行的吗?
如果是,那就没什么问题了,哈哈
安装完Hadoop之后运行spark相关命令('spark-shell'命令和'pyspark'命令)时出现‘Could not locate executable null\bin\winutils.exe in the Hadoop binaries.’
从github下载winutils,然后把对应版本的hadoop目录下的bin文件夹中的winutils.exe做复制就不会报这个错误了哦
疑问:'spark-shell'命令可以根据输出信息中的'Spark context Web UI available at...'一行进入网址查看spark的UI界面,pip安装的'pyspark'命令如何查看spark的UI界面呢?
已解决:'pyspark'命令进入默认网址'localhost:4040'或者‘127.0.0.1:4040'可以查看spark的UI界面哇waha
配置pyspark启动时自动启动jupyter notebook(建议在用户变量中操作):
操作
变量名
变量值
新建
PYSPARK_DRIVER_PYTHON
jupyter
新建
PYSPARK_DRIVER_PYTHON_OPTS
notebook