【MySql】9- 实践篇(七)
文章目录
-
- 1. 一主多从的主备切换
-
- 1.1 基于位点的主备切换
- 1.2 GTID
- 1.3 基于 GTID 的主备切换
- 1.4 GTID 和在线 DDL
- 2. 读写分离问题
-
- 2.1 强制走主库方案
- 2.2 Sleep 方案
- 2.3 判断主备无延迟方案
- 2.4 配合 semi-sync方案
- 2.5 等主库位点方案
- 2.6 GTID 方案
- 3. 如何判断数据库是否出问题了
-
- 3.1 select 1 判断
- 3.2 查表判断
- 3.3 更新判断
- 3.4 内部统计
1. 一主多从的主备切换
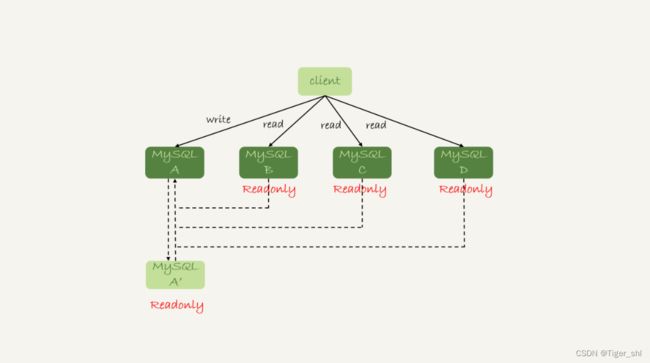
图 1 一主多从基本结构
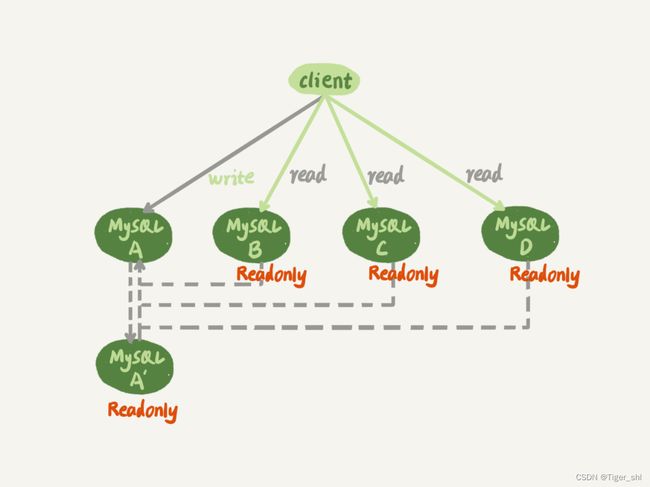
虚线箭头表示的是主备关系,也就是 A 和 A’互为主备, 从库 B、C、D 指向的是主库 A。
一主多从的设置,一般用于读写分离,主库负责所有的写入和一部分读,其他的读请求则由从库分担。
如图 2 所示,就是主库发生故障,主备切换后的结果。
图 2 一主多从基本结构 – 主备切换
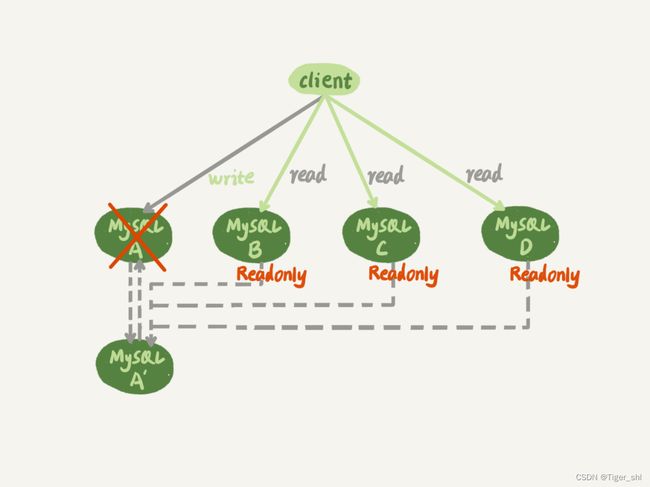
一主多从结构在切换完成后,A’会成为新的主库,从库 B、C、D 也要改接到 A’。正是由于多了从库 B、C、D 重新指向的这个过程,所以主备切换的复杂性也相应增加了。
1.1 基于位点的主备切换
把节点 B 设置成节点 A’的从库的时候,需要执行一条 change master 命令:
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
MASTER_LOG_FILE=$master_log_name
MASTER_LOG_POS=$master_log_pos
命令有这么 6 个参数:
- MASTER_HOST、MASTER_PORT、MASTER_USER 和 MASTER_PASSWORD 四个参数,分别代表了主库 A’的 IP、端口、用户名和密码。
- 最后两个参数 MASTER_LOG_FILE 和 MASTER_LOG_POS 表示,要从主库的 master_log_name 文件的 master_log_pos 这个位置的日志继续同步。而这个位置就是我们所说的同步位点,也就是主库对应的文件名和日志偏移量。
原来节点 B 是 A 的从库,本地记录的也是 A 的位点。但是相同的日志,A 的位点和 A’的位点是不同的。因此,从库 B 要切换的时候,就需要先经过“找同步位点”这个逻辑。这个位点很难精确取到,只能取一个大概位置。
考虑到切换过程中不能丢数据,所以找位点的时候,总是要找一个“稍微往前”的,然后再通过判断跳过那些在从库 B 上已经执行过的事务。
取同步位点的方法:
- 等待新主库 A’把中转日志(relay log)全部同步完成;
- 在 A’上执行 show master status 命令,得到当前 A’上最新的 File 和 Position;
- 取原主库 A 故障的时刻 T;
- 用 mysqlbinlog 工具解析 A’的 File,得到 T 时刻的位点。
mysqlbinlog File --stop-datetime=T --start-datetime=T
 图中,end_log_pos 后面的值“123”,表示的就是 A’这个实例,在 T 时刻写入新的 binlog 的位置。
图中,end_log_pos 后面的值“123”,表示的就是 A’这个实例,在 T 时刻写入新的 binlog 的位置。
然后,我们就可以把 123 这个值作为 $master_log_pos ,用在节点 B 的 change master 命令里。
当然这个值并不精确。
可以设想有这么一种情况,假设在 T 这个时刻,主库 A 已经执行完成了一个 insert 语句插入了一行数据 R,并且已经将 binlog 传给了 A’和 B,然后在传完的瞬间主库 A 的主机就掉电了。
这时候系统的状态是这样的:
- 在从库 B 上,由于同步了 binlog, R 这一行已经存在;
- 在新主库 A’上, R 这一行也已经存在,日志是写在 123 这个位置之后的;
- 我们在从库 B 上执行 change master 命令,指向 A’的 File 文件的 123 位置,就会把插入 R 这一行数据的 binlog 又同步到从库 B 去执行。
这时候,从库 B 的同步线程就会报告 Duplicate entry ‘id_of_R’ for key ‘PRIMARY’ 错误,提示出现了主键冲突,然后停止同步。
通常情况下,我们在切换任务的时候,要先主动跳过这些错误,有两种常用的方法
- 主动跳过一个事务
set global sql_slave_skip_counter=1;
start slave;`
因为切换过程中,可能会不止重复执行一个事务,所以我们需要在从库 B 刚开始接到新主库 A’时,持续观察,每次碰到这些错误就停下来,执行一次跳过命令,直到不再出现停下来的情况,以此来跳过可能涉及的所有事务。
- 设置 slave_skip_errors 参数,直接设置跳过指定的错误。
执行主备切换时,是经常会遇到的1062 (插入数据时唯一键冲突)和1032 (删除数据时找不到行)
因此,我们可以把 slave_skip_errors 设置为 “1032,1062”,这样中间碰到这两个错误时就直接跳过
注意
这种直接跳过指定错误的方法,针对的是主备切换时,由于找不到精确的同步位点,所以只能采用这种方法来创建从库和新主库的主备关系。
在主备切换过程中,直接跳过 1032 和 1062 这两类错误是无损的,所以才可以这么设置 slave_skip_errors 参数。等到主备间的同步关系建立完成,并稳定执行一段时间之后,我们还需要把这个参数设置为空,以免之后真的出现了主从数据不一致,也跳过了。
1.2 GTID
通过 sql_slave_skip_counter 跳过事务和通过 slave_skip_errors 忽略错误的方法,虽然都最终可以建立从库 B 和新主库 A’的主备关系,但这两种操作都很复杂,而且容易出错。
所以,MySQL 5.6 版本引入了 GTID,彻底解决了这个困难。
GTID 的全称是 Global Transaction Identifier,也就是全局事务 ID,是一个事务在提交的时候生成的,是这个事务的唯一标识。它由两部分组成,格式是:
GTID=server_uuid:gno
server_uuid 是一个实例第一次启动时自动生成的,是一个全局唯一的值;
gno 是一个整数,初始值是 1,每次提交事务的时候分配给这个事务,并加 1。
在 MySQL 的官方文档里,GTID 格式是这么定义的:
GTID=source_id:transaction_id
source_id 就是 server_uuid;而后面的这个 transaction_id,就是 gno。
GTID 模式的启动只需要在启动一个 MySQL 实例的时候,加上参数 gtid_mode=on 和 enforce_gtid_consistency=on 就可以。
在 GTID 模式下,每个事务都会跟一个 GTID 一一对应。这个 GTID 有两种生成方式,而使用哪种方式取决于 session 变量 gtid_next 的值。
- 如果 gtid_next=automatic,代表使用默认值。这时,MySQL 就会把 server_uuid:gno 分配给这个事务。
a. 记录 binlog 的时候,先记录一行 SET @@SESSION.GTID_NEXT=‘server_uuid:gno’;
b. 把这个 GTID 加入本实例的 GTID 集合。 - 如果 gtid_next 是一个指定的 GTID 的值,比如通过 set gtid_next='current_gtid’指定为 current_gtid,那么就有两种可能:
a. 如果 current_gtid 已经存在于实例的 GTID 集合中,接下来执行的这个事务会直接被系统忽略;
b. 如果 current_gtid 没有存在于实例的 GTID 集合中,就将这个 current_gtid 分配给接下来要执行的事务,也就是说系统不需要给这个事务生成新的 GTID,因此 gno 也不用加 1。
一个 current_gtid 只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行 set 命令,把 gtid_next 设置成另外一个 gtid 或者 automatic。
每个 MySQL 实例都维护了一个 GTID 集合,用来对应“这个实例执行过的所有事务”。
用一个简单的例子,来和你说明 GTID 的基本用法。
实例 X 中创建一个表 t
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t values(1,1);
图 4 初始化数据的 binlog
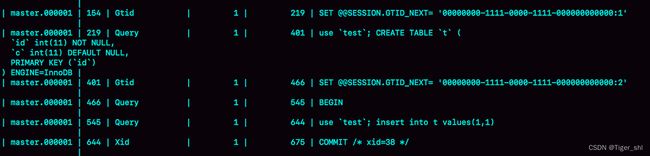
可以看到,事务的 BEGIN 之前有一条 SET @@SESSION.GTID_NEXT 命令。这时,如果实例 X 有从库,那么将 CREATE TABLE 和 insert 语句的 binlog 同步过去执行的话,执行事务之前就会先执行这两个 SET 命令, 这样被加入从库的 GTID 集合的,就是图中的这两个 GTID。
假设,现在这个实例 X 是另外一个实例 Y 的从库,并且此时在实例 Y 上执行了下面这条插入语句:
insert into t values(1,1);
并且,这条语句在实例 Y 上的 GTID 是 “aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10”。
那么,实例 X 作为 Y 的从库,就要同步这个事务过来执行,显然会出现主键冲突,导致实例 X 的同步线程停止。
处理方法就是,可以执行下面的这个语句序列:
set gtid_next='aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10';
begin;
commit;
set gtid_next=automatic;
start slave;
其中,前三条语句的作用,是通过提交一个空事务,把这个 GTID 加到实例 X 的 GTID 集合中。
如图 5 所示,就是执行完这个空事务之后的 show master status 的结果。
图 5 show master status 结果
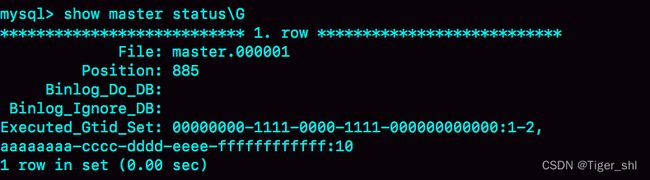
可以看到实例 X 的 Executed_Gtid_set 里面,已经加入了这个 GTID。
再执行 start slave 命令让同步线程执行起来的时候,虽然实例 X 上还是会继续执行实例 Y 传过来的事务,但是由于“aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10”已经存在于实例 X 的 GTID 集合中了,所以实例 X 就会直接跳过这个事务,也就不会再出现主键冲突的错误。
上面的这个语句序列中,start slave 命令之前还有一句 set gtid_next=automatic。这句话的作用是“恢复 GTID 的默认分配行为”,也就是说如果之后有新的事务再执行,就还是按照原来的分配方式,继续分配 gno=3。
1.3 基于 GTID 的主备切换
GTID 模式下,备库 B 要设置为新主库 A’的从库的语法如下:
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
master_auto_position=1
master_auto_position=1 就表示这个主备关系使用的是 GTID 协议。
现在,实例 A’的 GTID 集合记为 set_a,实例 B 的 GTID 集合记为 set_b,看看现在的主备切换逻辑。
在实例 B 上执行 start slave 命令,取 binlog 的逻辑是这样的:
- 实例 B 指定主库 A’,基于主备协议建立连接。
- 实例 B 把 set_b 发给主库 A’。
- 实例 A’算出 set_a 与 set_b 的差集,也就是所有存在于 set_a,但是不存在于 set_b 的 GTID 的集合,判断 A’本地是否包含了这个差集需要的所有 binlog 事务。
a. 如果不包含,表示 A’已经把实例 B 需要的 binlog 给删掉了,直接返回错误;
b. 如果确认全部包含,A’从自己的 binlog 文件里面,找出第一个不在 set_b 的事务,发给 B; - 之后就从这个事务开始,往后读文件,按顺序取 binlog 发给 B 去执行。
这个逻辑里面包含了一个设计思想:
在基于 GTID 的主备关系里,系统认为只要建立主备关系,就必须保证主库发给备库的日志是完整的。因此,如果实例 B 需要的日志已经不存在,A’就拒绝把日志发给 B。
这跟基于位点的主备协议不同。基于位点的协议,是由备库决定的,备库指定哪个位点,主库就发哪个位点,不做日志的完整性判断。
引入 GTID 后,一主多从的切换场景下,主备切换是如何实现的。
由于不需要找位点了,所以从库 B、C、D 只需要分别执行 change master 命令指向实例 A’即可。
严谨地说,主备切换不是不需要找位点了,而是找位点这个工作,在实例 A’内部就已经自动完成了
之后这个系统就由新主库 A’写入,主库 A’的自己生成的 binlog 中的 GTID 集合格式是:server_uuid_of_A’:1-M。
如果之前从库 B 的 GTID 集合格式是 server_uuid_of_A:1-N, 那么切换之后 GTID 集合的格式就变成了 server_uuid_of_A:1-N, server_uuid_of_A’:1-M。
当然,主库 A’之前也是 A 的备库,因此主库 A’和从库 B 的 GTID 集合是一样的。
1.4 GTID 和在线 DDL
假设,这两个互为主备关系的库还是实例 X 和实例 Y,且当前主库是 X,并且都打开了 GTID 模式。这时的主备切换流程可以变成下面这样:
- 在实例 X 上执行 stop slave。
- 在实例 Y 上执行 DDL 语句。注意,这里并不需要关闭 binlog。
- 执行完成后,查出这个 DDL 语句对应的 GTID,并记为 server_uuid_of_Y:gno。
- 到实例 X 上执行以下语句序列:
set GTID_NEXT="server_uuid_of_Y:gno";
begin;
commit;
set gtid_next=automatic;
start slave;
这样做的目的在于,既可以让实例 Y 的更新有 binlog 记录,同时也可以确保不会在实例 X 上执行这条更新。
- 接下来,执行完主备切换,然后照着上述流程再执行一遍即可。
思考
在 GTID 模式下设置主从关系的时候,从库执行 start slave 命令后,主库发现需要的 binlog 已经被删除掉了,导致主备创建不成功。这种情况下,可以怎么处理呢?
- 如果业务允许主从不一致的情况,那么可以在主库上先执行 show global variables like ‘gtid_purged’,得到主库已经删除的 GTID 集合,假设是 gtid_purged1;然后先在从库上执行 reset master,再执行 set global gtid_purged =‘gtid_purged1’;最后执行 start slave,就会从主库现存的 binlog 开始同步。binlog 缺失的那一部分,数据在从库上就可能会有丢失,造成主从不一致。
- 如果需要主从数据一致的话,最好还是通过重新搭建从库来做。
- 如果有其他的从库保留有全量的 binlog 的话,可以把新的从库先接到这个保留了全量 binlog 的从库,追上日志以后,如果有需要,再接回主库。
- 如果 binlog 有备份的情况,可以先在从库上应用缺失的 binlog,然后再执行 start slave。
2. 读写分离问题
图 1 读写分离基本结构
读写分离的目标 ⇒ 分摊主库的压力
图 1 中的结构是客户端(client)主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。也就是说,由客户端来选择后端数据库进行查询。
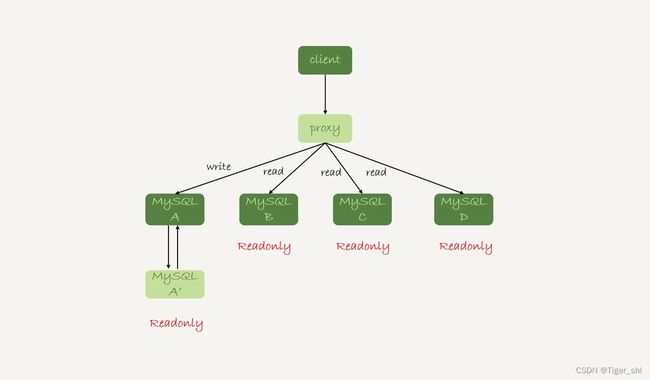
还有一种架构是,在 MySQL 和客户端之间有一个中间代理层 proxy,客户端只连接 proxy, 由 proxy 根据请求类型和上下文决定请求的分发路由。
图 2 带 proxy 的读写分离架构
客户端直连和带 proxy 的读写分离架构的特点分析:
- 客户端直连方案,因为少了一层 proxy 转发,所以查询性能稍微好一点儿,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。你可能会觉得这样客户端也太麻烦了,信息大量冗余,架构很丑。其实也未必,一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如 Zookeeper,尽量让业务端只专注于业务逻辑开发。
- 带 proxy 的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由 proxy 完成的。但这样的话,对后端维护团队的要求会更高。而且,proxy 也需要有高可用架构。因此,带 proxy 架构的整体就相对比较复杂。
问题:
由于主从可能存在延迟,客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库的话,就有可能读到刚刚的事务更新之前的状态。
这种“在从库上会读到系统的一个过期状态”的现象,暂且称之为“过期读”
处理过期读问题的方案
- 强制走主库方案;
- sleep 方案;
- 判断主备无延迟方案;
- 配合 semi-sync 方案;
- 等主库位点方案;
- 等 GTID 方案。
2.1 强制走主库方案
强制走主库方案其实就是,将查询请求做分类。通常情况下,可以将查询请求分为这么两类:
- 对于必须要拿到最新结果的请求,强制将其发到主库上。比如,在一个交易平台上,卖家发布商品以后,马上要返回主页面,看商品是否发布成功。那么,这个请求需要拿到最新的结果,就必须走主库。
- 对于可以读到旧数据的请求,才将其发到从库上。在这个交易平台上,买家来逛商铺页面,就算晚几秒看到最新发布的商品,也是可以接受的。那么,这类请求就可以走从库。
这个方案看似有点畏难和取巧的意思,但其实这个方案是用得最多的。
当然,这个方案最大的问题在于,有时候会碰到“所有查询都不能是过期读”的需求,比如一些金融类的业务。这样的话,就要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性。
有哪些可以支持读写分离的场景下,有哪些解决过期读的方案?下面讨论
2.2 Sleep 方案
主库更新后,读从库之前先 sleep 一下。
具体的方案:
类似于执行一条 select sleep(1) 命令。
这个方案的假设是,大多数情况下主备延迟在 1 秒之内,做一个 sleep 可以有很大概率拿到最新的数据。
这个方案给的第一感觉,很可能是不靠谱儿,并且,直接在发起查询时先执行一条 sleep 语句,用户体验很不友好。但,这个思路确实可以在一定程度上解决问题。为了看起来更靠谱儿,我们可以换一种方式。
以卖家发布商品为例,商品发布后,用 Ajax(Asynchronous JavaScript + XML,异步 JavaScript 和 XML)直接把客户端输入的内容作为“新的商品”显示在页面上,而不是真正地去数据库做查询。
这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了 sleep 的目的,进而也就解决了过期读的问题。
从严格意义上来说,这个方案存在的问题就是不精确。这个不精确包含了两层意思:
- 如果这个查询请求本来 0.5 秒就可以在从库上拿到正确结果,也会等 1 秒;
- 如果延迟超过 1 秒,还是会出现过期读。
2.3 判断主备无延迟方案
要确保备库无延迟,通常有三种做法。
-
每次从库执行查询请求前,先判断 seconds_behind_master 是否已经等于 0。如果还不等于 0 ,那就必须等到这个参数变为 0 才能执行查询请求。
-
对比位点确保主备无延迟:
图 3 show slave status 结果

- Master_Log_File 和 Read_Master_Log_Pos,表示的是读到的主库的最新位点;
- Relay_Master_Log_File 和 Exec_Master_Log_Pos,表示的是备库执行的最新位点。
如果 Master_Log_File 和 Relay_Master_Log_File、Read_Master_Log_Pos 和 Exec_Master_Log_Pos 这两组值完全相同,就表示接收到的日志已经同步完成。
- 对比 GTID 集合确保主备无延迟:
- Auto_Position=1 ,表示这对主备关系使用了 GTID 协议。
- Retrieved_Gtid_Set,是备库收到的所有日志的 GTID 集合;
- Executed_Gtid_Set,是备库所有已经执行完成的 GTID 集合。
如果这两个集合相同,也表示备库接收到的日志都已经同步完成。
在执行查询请求之前,先判断从库是否同步完成的方法,相比于 sleep 方案,准确度确实提升了不少,但还是没有达到“精确”的程度。为何?
回顾下,一个事务的 binlog 在主备库之间的状态:
- 主库执行完成,写入 binlog,并反馈给客户端;
- binlog 被从主库发送给备库,备库收到;
- 在备库执行 binlog 完成。
上面判断主备无延迟的逻辑,是“备库收到的日志都执行完成了”。但是,从 binlog 在主备之间状态的分析中,不难看出还有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态。
如图 4 所示就是这样的一个状态。
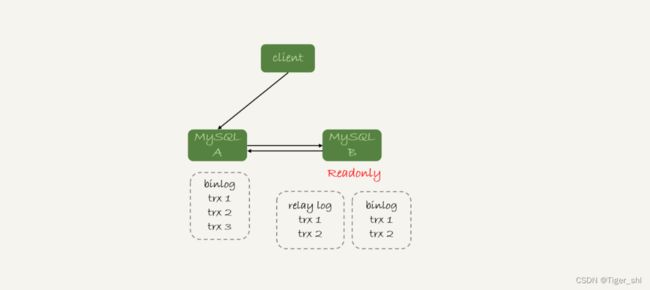
这时,主库上执行完成了三个事务 trx1、trx2 和 trx3,其中:
- trx1 和 trx2 已经传到从库,并且已经执行完成了;
- trx3 在主库执行完成,并且已经回复给客户端,但是还没有传到从库中。
如果这时候你在从库 B 上执行查询请求,按照我们上面的逻辑,从库认为已经没有同步延迟,但还是查不到 trx3 的。严格地说,就是出现了过期读。
如何解决呢?
2.4 配合 semi-sync方案
要解决这个问题,就要引入半同步复制,也就是 semi-sync replication。
semi-sync 做了这样的设计:
- 事务提交的时候,主库把 binlog 发给从库;
- 从库收到 binlog 以后,发回给主库一个 ack,表示收到了;
- 主库收到这个 ack 以后,才能给客户端返回“事务完成”的确认。
也就是说,如果启用了 semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志。
semi-sync 配合前面关于位点的判断,就能够确定在从库上执行的查询请求,可以避免过期读。
但是,semi-sync+ 位点判断的方案,只对一主一备的场景是成立的。
在一主多从场景中,主库只要等到一个从库的 ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
- 如果查询是落在这个响应了 ack 的从库上,是能够确保读到最新数据;
- 但如果是查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题。
其实,判断同步位点的方案还有另外一个潜在的问题,即:
如果在业务更新的高峰期,主库的位点或者 GTID 集合更新很快,那么上面的两个位点等值判断就会一直不成立,很可能出现从库上迟迟无法响应查询请求的情况。
当发起一个查询请求以后,要得到准确的结果,其实并不需要等到“主备完全同步”。
来看一下这个时序图。
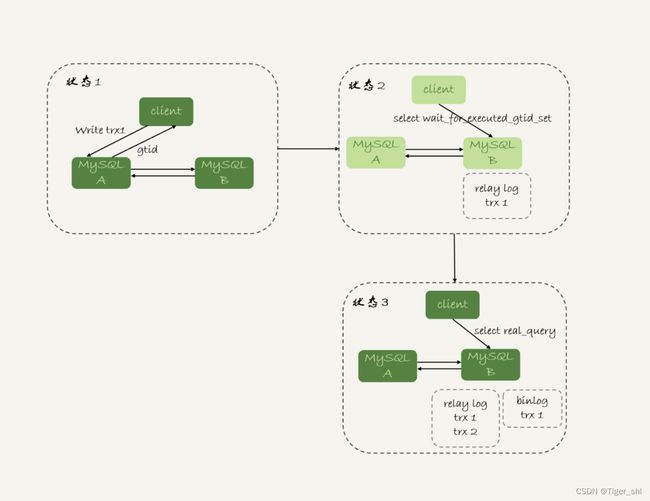
图 5 主备持续延迟一个事务

图 5 所示,就是等待位点方案的一个 bad case。图中备库 B 下的虚线框,分别表示 relaylog 和 binlog 中的事务。可以看到,图 5 中从状态 1 到状态 4,一直处于延迟一个事务的状态。
备库 B 一直到状态 4 都和主库 A 存在延迟,如果用上面必须等到无延迟才能查询的方案,select 语句直到状态 4 都不能被执行。
但是,其实客户端是在发完 trx1 更新后发起的 select 语句,我们只需要确保 trx1 已经执行完成就可以执行 select 语句了。也就是说,如果在状态 3 执行查询请求,得到的就是预期结果了。
semi-sync 配合判断主备无延迟的方案,存在两个问题:
- 一主多从的时候,在某些从库执行查询请求会存在过期读的现象;
- 在持续延迟的情况下,可能出现过度等待的问题。
2.5 等主库位点方案
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
- 它是在从库执行的;
- 参数 file 和 pos 指的是主库上的文件名和位置;
- timeout 可选,设置为正整数 N 表示这个函数最多等待 N 秒。
这个命令正常返回的结果是一个正整数 M,表示从命令开始执行,到应用完 file 和 pos 表示的 binlog 位置,执行了多少事务。
除了正常返回一个正整数 M 外,这条命令还会返回一些其他结果,包括:
- 如果执行期间,备库同步线程发生异常,则返回 NULL;
- 如果等待超过 N 秒,就返回 -1;
- 如果刚开始执行的时候,就发现已经执行过这个位置了,则返回 0。
对于图 5 中先执行 trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,我们可以使用这个逻辑:
4. trx1 事务更新完成后,马上执行 show master status 得到当前主库执行到的 File 和 Position;
5. 选定一个从库执行查询语句;
6. 在从库上执行 select master_pos_wait(File, Position, 1);
7. 如果返回值是 >=0 的正整数,则在这个从库执行查询语句;
8. 否则,到主库执行查询语句。
图 6 master_pos_wait 方案

假设,这条 select 查询最多在从库上等待 1 秒。
那么,如果 1 秒内 master_pos_wait 返回一个大于等于 0 的整数,就确保了从库上执行的这个查询结果一定包含了 trx1 的数据。
步骤 5 到主库执行查询语句,是这类方案常用的退化机制。因为从库的延迟时间不可控,不能无限等待,所以如果等待超时,就应该放弃,然后到主库去查。
2.6 GTID 方案
如果数据库开启了 GTID 模式,对应的也有等待 GTID 的方案。
MySQL 中同样提供了一个类似的命令:
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑是:
- 等待,直到这个库执行的事务中包含传入的 gtid_set,返回 0;
- 超时返回 1。
在前面等位点的方案中,执行完事务后,还要主动去主库执行 show master status。
而 MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端,这样等 GTID 的方案就可以减少一次查询。
这时,等 GTID 的执行流程就变成了:
- trx1 事务更新完成后,从返回包直接获取这个事务的 GTID,记为 gtid1;
- 选定一个从库执行查询语句;
- 在从库上执行 select wait_for_executed_gtid_set(gtid1, 1);
- 如果返回值是 0,则在这个从库执行查询语句;
- 否则,到主库执行查询语句
跟等主库位点的方案一样,等待超时后是否直接到主库查询,需要业务开发同学来做限流考虑。
图 7 wait_for_executed_gtid_set 方案
在上面的第一步中,trx1 事务更新完成后,从返回包直接获取这个事务的 GTID。只需要将参数 session_track_gtids 设置为 OWN_GTID,然后通过 API 接口 mysql_session_track_get_first 从返回包解析出 GTID 的值即可。
思考
假设你的系统采用了文中介绍的最后一个方案,也就是等 GTID 的方案,现在要对主库的一张大表做 DDL,可能会出现什么情况呢?为了避免这种情况,你会怎么做呢?
假设,这条语句在主库上要执行 10 分钟,提交后传到备库就要 10 分钟(典型的大事务)。那么,在主库 DDL 之后再提交的事务的 GTID,去备库查的时候,就会等 10 分钟才出现。这样,这个读写分离机制在这 10 分钟之内都会超时,然后走主库。
这种预期内的操作,应该在业务低峰期的时候,确保主库能够支持所有业务查询,然后把读请求都切到主库,再在主库上做 DDL。等备库延迟追上以后,再把读请求切回备库。
3. 如何判断数据库是否出问题了
在一主一备的双 M 架构里,主备切换只需要把客户端流量切到备库;
而在一主多从架构里,主备切换除了要把客户端流量切到备库外,还需要把从库接到新主库上。
主备切换有两种场景,一种是主动切换,一种是被动切换。而其中被动切换,往往是因为主库出问题了,由 HA 系统发起的。怎么判断一个主库出问题了?
3.1 select 1 判断
select 1 成功返回,只能说明这个库的进程还在,并不能说明主库没问题。
来看一下这个场景。
set global innodb_thread_concurrency=3;
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t values(1,1)
图 1 查询 blocked

设置 innodb_thread_concurrency 参数的目的是,控制 InnoDB 的并发线程上限。
一旦并发线程数达到这个值,InnoDB 在接收到新请求的时候,就会进入等待状态,直到有线程退出。
把 innodb_thread_concurrency 设置成 3,表示 InnoDB 只允许 3 个线程并行执行。而在我们的例子中,前三个 session 中的 sleep(100),使得这三个语句都处于“执行”状态,以此来模拟大查询。
上图可以看到, session D 里面,select 1 是能执行成功的,但是查询表 t 的语句会被堵住。也就是说,如果这时候用 select 1 来检测实例是否正常的话,是检测不出问题的。
在 InnoDB 中,innodb_thread_concurrency 这个参数的默认值是 0,表示不限制并发线程数量。但是,不限制并发线程数肯定是不行的。因为,一个机器的 CPU 核数有限,线程全冲进来,上下文切换的成本就会太高。通常情况下,建议把 innodb_thread_concurrency 设置为 64~128 之间的值。
并发连接和并发查询
- show processlist 的结果里,看到的几千个连接,指的就是并发连接。并发连接数达到几千个影响并不大,就是多占一些内存而已。
- 而“当前正在执行”的语句,才是所说的并发查询。并发查询太高占用CPU 资源越多。
**在线程进入锁等待以后,并发线程的计数会减一,**也就是说等行锁(也包括间隙锁)的线程是不算在 innodb_thread_concurrency 里面的
MySQL 这样设计是非常有意义的。因为,进入锁等待的线程已经不吃 CPU 了;更重要的是,必须这么设计,才能避免整个系统锁死。
假设处于锁等待的线程也占并发线程的计数,你可以设想一下这个场景:
- 线程 1 执行 begin; update t set c=c+1 where id=1, 启动了事务 trx1, 然后保持这个状态。这时候,线程处于空闲状态,不算在并发线程里面。
- 线程 2 到线程 129 都执行 update t set c=c+1 where id=1; 由于等行锁,进入等待状态。这样就有 128 个线程处于等待状态;
- 如果处于锁等待状态的线程计数不减一,InnoDB 就会认为线程数用满了,会阻止其他语句进入引擎执行,这样线程 1 不能提交事务。而另外的 128 个线程又处于锁等待状态,整个系统就堵住了。
图 2 显示的就是这个状态。
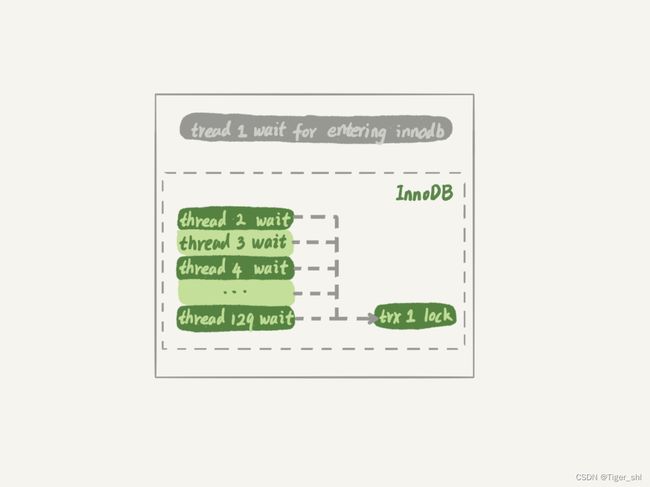
这时候 InnoDB 不能响应任何请求,整个系统被锁死。而且,由于所有线程都处于等待状态,此时占用的 CPU 却是 0,这显然是不合理的。所以说 InnoDB 在设计时,遇到进程进入锁等待的情况时,将并发线程的计数减 1 的设计,是合理而且是必要的。
3.2 查表判断
为了能够检测 InnoDB 并发线程数过多导致的系统不可用情况,我们需要找一个访问 InnoDB 的场景。
一般的做法是,在系统库(mysql 库)里创建一个表,比如命名为 health_check,里面只放一行数据,然后定期执行:
mysql> select * from mysql.health_check;
使用这个方法,可以检测出由于并发线程过多导致的数据库不可用的情况。
问题:空间满了以后,这种方法又会变得不好使。
更新事务要写 binlog,而一旦 binlog 所在磁盘的空间占用率达到 100%,那么所有的更新语句和事务提交的 commit 语句就都会被堵住。但是,系统这时候还是可以正常读数据的。
3.3 更新判断
既然要更新,就要放个有意义的字段,常见做法是放一个 timestamp 字段,用来表示最后一次执行检测的时间。
mysql> update mysql.health_check set t_modified=now();
节点可用性的检测都应该包含主库和备库。如果用更新来检测主库的话,那么备库也要进行更新检测。
但,备库的检测也是要写 binlog 的。一般会把数据库 A 和 B 的主备关系设计为双 M 结构,所以在备库 B 上执行的检测命令,也要发回给主库 A。
如果主库 A 和备库 B 都用相同的更新命令,就可能出现行冲突,也就是可能会导致主备同步停止。所以, mysql.health_check 这个表不能只有一行数据。
为了让主备之间的更新不产生冲突,我们可以在 mysql.health_check 表上存入多行数据,并用 A、B 的 server_id 做主键。
mysql> CREATE TABLE `health_check` (
`id` int(11) NOT NULL,
`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
/* 检测命令 */
insert into mysql.health_check(id, t_modified) values (@@server_id, now()) on duplicate key update t_modified=now();
由于 MySQL 规定了主库和备库的 server_id 必须不同(否则创建主备关系的时候就会报错),这样就可以保证主、备库各自的检测命令不会发生冲突。
更新判断是一个相对比较常用的方案了,不过依然存在一些问题—“判定慢”。
这里涉及到的是服务器 IO 资源分配的问题。
首先,所有的检测逻辑都需要一个超时时间 N。执行一条 update 语句,超过 N 秒后还不返回,就认为系统不可用。
可以设想一个日志盘的 IO 利用率已经是 100% 的场景。这时候,整个系统响应非常慢,已经需要做主备切换了。IO 利用率 100% 表示系统的 IO 是在工作的,每个请求都有机会获得 IO 资源,执行自己的任务。而我们的检测使用的 update 命令,需要的资源很少,所以可能在拿到 IO 资源的时候就可以提交成功,并且在超时时间 N 秒未到达之前就返回给了检测系统。检测系统一看,update 命令没有超时,于是就得到了“系统正常”的结论。
之所以会出现这个现象,根本原因是我们上面说的所有方法,都是基于外部检测的。外部检测天然有一个问题,就是随机性。
3.4 内部统计
针对磁盘利用率这个问题,如果 MySQL 可以告诉我们,内部每一次 IO 请求的时间,那判断数据库是否出问题的方法就可靠得多了。
MySQL 5.6 版本以后提供的 performance_schema 库,就在 file_summary_by_event_name 表里统计了每次 IO 请求的时间。
ile_summary_by_event_name 表里有很多行数据,先来看看 event_name='wait/io/file/innodb/innodb_log_file’这一行。
图 3 performance_schema.file_summary_by_event_name 的一行
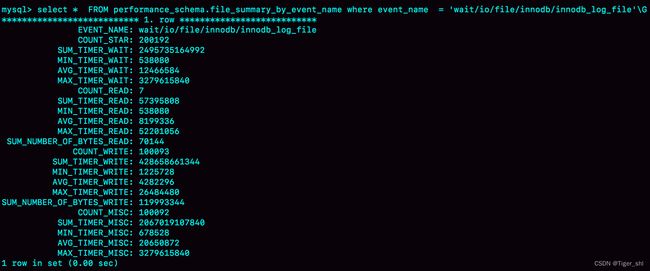
图中这一行表示统计的是 redo log 的写入时间,第一列 EVENT_NAME 表示统计的类型。
接下来的三组数据,显示的是 redo log 操作的时间统计。
第一组五列,是所有 IO 类型的统计。其中,COUNT_STAR 是所有 IO 的总次数,接下来四列是具体的统计项, 单位是皮秒;前缀 SUM、MIN、AVG、MAX,顾名思义指的就是总和、最小值、平均值和最大值。
第二组六列,是读操作的统计。最后一列 SUM_NUMBER_OF_BYTES_READ 统计的是,总共从 redo log 里读了多少个字节。
第三组六列,统计的是写操作。
最后的第四组数据,是对其他类型数据的统计。在 redo log 里,可以认为它们就是对 fsync 的统计。
在 performance_schema 库的 file_summary_by_event_name 表里,binlog 对应的是 event_name = "wait/io/file/sql/binlog"这一行。各个字段的统计逻辑,与 redo log 的各个字段完全相同。
每一次操作数据库,performance_schema 都需要额外地统计这些信息,所以打开这个统计功能是有性能损耗的。打开所有的 performance_schema 项,性能大概会下降 10% 左右。
可以通过下面的方法打开或者关闭某个具体项的统计。
如果要打开 redo log 的时间监控,可以执行这个语句:
mysql> update setup_instruments set ENABLED='YES', Timed='YES' where name like '%wait/io/file/innodb/innodb_log_file%';
假设,现在已经开启了 redo log 和 binlog 这两个统计信息,那要怎么把这个信息用在实例状态诊断上呢?
可以通过 MAX_TIMER 的值来判断数据库是否出问题了。比如,你可以设定阈值,单次 IO 请求时间超过 200 毫秒属于异常,然后使用类似下面这条语句作为检测逻辑。
mysql> select event_name,MAX_TIMER_WAIT FROM performance_schema.file_summary_by_event_name where event_name in ('wait/io/file/innodb/innodb_log_file','wait/io/file/sql/binlog') and MAX_TIMER_WAIT>200*1000000000;
发现异常后,取到你需要的信息,再通过下面这条语句:
mysql> truncate table performance_schema.file_summary_by_event_name;
把之前的统计信息清空。这样如果后面的监控中,再次出现这个异常,就可以加入监控累积值了。
思考
业务系统一般也有高可用的需求,在你开发和维护过的服务中,你是怎么判断服务有没有出问题的呢?
- 服务状态和服务质量的监控。其中,服务状态的监控,一般都可以用外部系统来实现;而服务的质量的监控,就要通过接口的响应时间来统计
- 服务中使用了 healthCheck 来检测
- 按照监控的对象,将监控分成了基础监控、服务监控和业务监控,并分享了每种监控需要关注的对象。
来自林晓斌《MySQK实战45讲》