Linux学习之进程一
目录
一,什么是进程?
1.何为pcb(process control block)?
2.linux的task_struct
二,了解task_struct的核心字段
标识符
ps指令
getpid指令
ppid(parent process id)
getppid指令
系统调用创建进程---fork
一,什么是进程?
相信大家再没开始学习操作系统时,应该分不清进程与程序之间的关系,那么进程到底是个啥?
首先在我们的操作系统内会存在非常多的进程,那么操作系统如何管理呢?-----先描述,再组织,中心思想就是这六个方法。
先描述:以结构体的形式描述进程的各种属性
再组织:通过数据结构的方式(如添加链接字段)将数据组织起来,形成链表结构。
用官方的话来说:
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行 资源分配 的 基本单位 ,是操作系统结构的基础。 在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。
程序是指令、数据及其组织形式的描述,进程是程序的实体。
理解先描述首先我们先要明白pcb是个啥?
1.何为pcb(process control block)?
通俗的理解,对于一个进程,我们想要描述它,就是将该进程的所有属性放在一个结构体当中,在通过对结构体的链接等形成数据结构形式,而我们将这个包含了进程属性的结构体叫做进程pcb(进程控制块),所以每一个进程都有与之对应的pcb,通过对pcb的管理就可以实现进程的管理。
pcb里存放的是进程的属性:

明白了pcb,那么我们基本上就明白当程序从磁盘加载到内存时,不仅仅需要将磁盘中的文件(可执行程序)拷贝到内存当中,操作系统还会对每一个可执行程序生成一个对应的pcb,且pcb形成链表结构,通过管理pcb链表来管理程序:
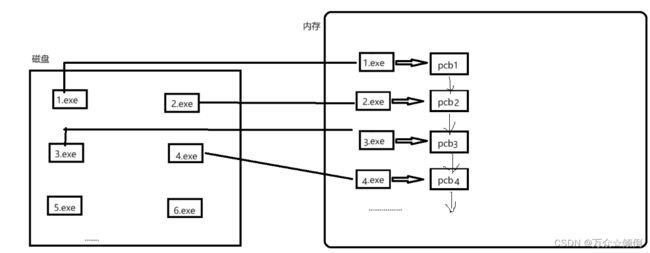
此外,当cpu需要了解某一个程序时也不是去找她的可执行程序,也是看对应pcb里的内容。
总的来说,对进程的管理本质上就是对建模形成的链表做管理(增删查改)。
此时对于进程用我们自己的理解概念就是:进程是可执行程序+内核数据结构(pcb,..)
2.linux的task_struct
通过上文我们大致了解了pcb是什么,之前学习过linxu,我们了解到了shell与bash,我们就知道shell是外壳的统称,bash就是一种具体的外壳,而所谓的task_struct就是一种具体的pcb,是linux操作系统的pcb。
我们可以上网查看一下task_struct:
linux的task_struct大概有6000多行,我们截取一段看看

知道了linux的pcb-task_struct,我们也能大致的解释linux操作系统下进程的管理,对于linux操作系统,我们也可以知道他的pcb是一个链表结构,具体的如下:

二,了解task_struct的核心字段
上述我们大致了解到了task_struct的大致结构,我们也看到了task_struct的源码,我们知道task_struct描述的是是进程的属性,那么具体内容到底指的是什么呢?
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
标识符
进程独一无二的标识符--这里就是pid(process id),通过标识符操作系统知晓你是哪一个进程。
我们可以用我们的虚拟服务器查看:
在此之前我们需要介绍一下查看pid的指令 ps:可以查看进程的信息如pid,ppid等
ps指令
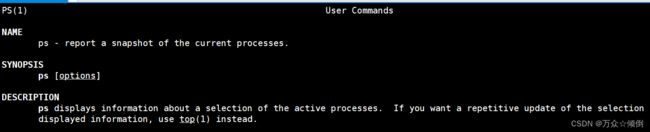
ps指令是用于显示当前系统进程状态的命令,来自于英文词组"process status"的缩写1234。使用ps命令可以查看进程的所有信息:例如进程号码、发起者、系统资源使用占比(处理器与内存)、运行状态等等1345。
ps命令列出的是当前那些进程的快照,就是执行ps命令的那个时刻的那些进程。如果想要动态的显示进程信息,可以使用top命令。
ps ajx //查看当前下的所有进程的信息
ps ajx |grep 文件名 //利用grep过滤查看我们需要查看运行的可执行程序的信息那么具体如何查看呢?
我们创建一个.c文件写一个循环,生成可执行,在加载到内存当中,让它在云服务器上面运行着,之后另开一个ssh窗口,用来查看此时的进程:

此时我们可以观察到当前正在运行的程序的(进程)信息。可是直接看还是不太清楚我们可以组合指令
ps ajx | head -1 //查看进程信息的头行-1 也就是各个信息的名字ps ajx | head-1 &&ps ajx | grep 文件 //过滤出并加上head-1此时进程的信息 此时我们就可以看到进程信息对应的数据:
此时我们就可以看到进程信息对应的数据:
这里有两个进程,我们可以明显看到第一个是我们要查看的进程信息,那么第二个是什么?实际上在我们利用指令grep来过滤时,这个指令也被调用了,也成为了一个进程,所以查看的时候会跟一个grep的进程。
当然我们也可以简介证明此时运行的程序是一个进程,停止我们的程序,结束循环退出,此时再查看就看不到该进程的信息了。
综上我们也可以得出所有在运行的程序,指令,我们自己写的程序都是进程!
getpid指令
我们可以不用ps指令查看,可以直接用getpid获取当前进程的pid:(当然这里需要包含我们的头文件)

之后编写我们的代码可以直接获取pid并让他打印出来:
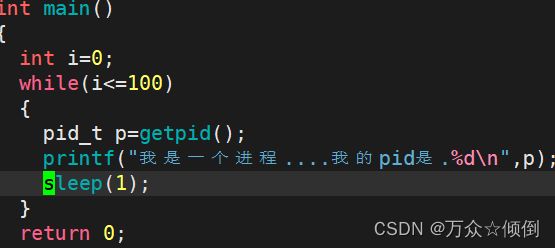
我们知道pid是进程的唯一标识符,那么我们可以通过pid去管理进程。
如我们可以直接通过kill指令杀掉进程:
kill -9 pid //杀掉进程

可以看到出现一个killed,之后跳出运行。
其次我们需要知道每一次启动系统给他分配的pid是不一样的。
ppid(parent process id)
pid是一个进程的唯一标识,在上述查看进程信息时,我们也能看到一个ppid,那么什么是ppid?
ppid其实就是父进程的pid,一个进程除了拥有自己的pid,他还会有父进程的Pid。
而我们刚才了解到进程梅贻琦重分配配到的pid都不一样,但若每次重新启动时,父进程的pid不变,那么我们就可以知晓父进程是bash.

比如说我这里的子进程的ppid不变,查阅之后发现是bash的pid,即命令行解释器的pid。
关闭xshell下次打开时,我们bsah的pid大概率就会变了。
getppid指令
为了更加生动形象的显示进程在运行,我们将我们查看进程信息的指令一直循环着,间隔一秒钟。
while :; do ps ajx |head -1&& ps ajx |grep 文件名 |grep -v "grep";sleep 1; echo "######################";done
//grep -v "grep" //不再显示关于grep的信息
//echo"######################" 主要是为了分隔开每次进程信息的查看
进程的启动就是进程的创建,一般是操作系统以父进程的pcb为模板创建子进程的,命令行解释器启动时所有的子进程的父进程都是bash,我们可以通过getppid来验证,子进程的ppid与getppid是否一样:
通过在代码中打印ppid,运行之后,结束之后再运行,我们发现ppid是不变的。
小扩展:查看进程除了利用ps ajx之外,我们还可以直接找到进程对应的一个目录,在我们的根目录底下有一个proc目录,里面存放就是进程对应的目录:
ls /proc/pid -dl //查看某个是此pid的子进程 只看一行 //proc是一个动态目录![]()
如果我们结束进程,那么对应的目录就会消失,因此每一个进程都有自己的工作目录。
当我们查看此进程的目录时,我们还需要了解到一个概念cwd(当前目录):所谓的当前目录就是在当前进程启动时它会自动地记录对应的目录路径,而这个cwd就是当前目录。这就是为什么创建一个文件不指定路径的时候,默认在当前路径下创建。
![]() 当然当前路径我们也可以改变。
当然当前路径我们也可以改变。
chdir ("路径") //改变当前工作目录为此路径系统调用创建进程---fork
除了父进程创建子进程外,我们还可以自己手动创建一个进程,用代码创建进程。
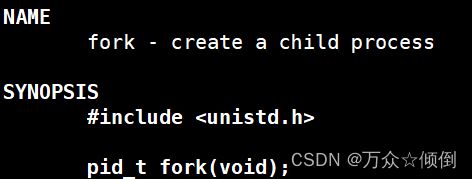
我么可以编写代码并打印信息来观察:

运行之后:

第一个和第二个是同一个进程,第三个是另一个进程,再fork之前调用一次printf打印父进程,之后有两个进程打印该进程,在打印fork创建的进程。
其次fork进程是该程序的子进程,即fork是创建子进程。
除此之外,fork创建成功的话返回子进程Pid给父进程,返回零给子进程。
我们可以通过打印信息来观察fork的返回值:


除了本身的这个进程外,我们创建的子进程也随之执行了我们的打印,并且可以看到当父子进程都执行时,返回值是不一样的,父进程返回子进程的id,子进程返回0.
利用多进程运行可以实现用户的不同需求,让子进程与父进程做不一样的事(通过判断fork的返回值判断谁是父,谁是子,让他们执行不同的代码)。如下:



我们可以同时观察他们的运行情况。
那么fork的原理是什么呢?它的返回值为什么有两个?子返回0,父返回子的pid。

为什么有两个返回值?: 因为此时的代码和数据被共享,因此就会有两个返回值等,对于这里的代码子进程只会执行fork()之后的代码,虽然之前的代码子进程也能看到,但是通过寄存器(pc指针与eip指针)会保存每一次执行的指令位置,执行完之后进行下一个,执行到fork时,子进程也继承了这个pc指针,因此他会知道此事执行的位置,并继续执行。
为什么子进程只从fork后的代码运行?注:PC是指PowerPC架构中的指令计数器,用于存储下一条要执行的指令的地址。 EIP是x86架构中的指令指针寄存器,用于存储下一条要执行的指令的地址。
为什么父返回子的pid?:因为父进程是唯一的,因此我们给返回值是子的pid,用来唯一标识,而子子进程给个0就行。
父子谁先运行?:当我们创建完成后,和其他pcb一起形成processlist,然后在运行队列排队的时候,哪一个pcb被选择调度的时候,哪一个就先运行-----(取决于pcb的调度信息,时间片,调度算法,优先级等)。
最后补充一点:进程运行的时候是具有独立性的,无论是什么关系。他们的独立性首先表现在:它们都有对应的pcb,其次进程之间不会互相影响-(代码共享,数据各自独立)。