语音转文本一
百度云语音转文本
文章目录
-
- 百度云语音转文本
- 一、创建应用
- 二、调用方式一
- 三、调用方式二
- 四、音频转码工具
- 五、ffmpeg安装
- 六、ffmpeg 使用说明
- 七、ffmpeg命令
- 八、查看音频格式ffprobe使用
- 九、pcm文件音频时长计算
- 十、转换为m4a格式(AAC编码)
一、创建应用
https://console.bce.baidu.com/ai/?_=1665651969389#/ai/speech/overview/index

 打开应用列表就可以看到自己创建的应用,有对应的app_id,api_key和secret_key
打开应用列表就可以看到自己创建的应用,有对应的app_id,api_key和secret_key

二、调用方式一
安装包
pip install baidu-aip
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 复制一个16000采样频率、16bit位、单声道、小于60秒的wav语音(output.wav),放在在代码同级目录下。
# 调用百度aip 实现语音识别,对音频文件的要求如下:
# 1、支持音频格式:pcm、wav、amr、m4a
# 2、音频编码要求:采样率 16000、8000,16 bit 位深,单声道
# 3、录音文件时长不超过 60 秒
# 读取音频文件
with open('data/record/nls-sample-16k.wav', 'rb') as fp:
au = fp.read()
# wav格式,16000采样频率,1537表示普通话。 这3个要和语音文件的内容保持一致。
res = client.asr(au, 'wav', 16000, {'dev_pid': 1537})
print(res)
print('识别结果:' + ''.join(res['result']))
三、调用方式二
import sys
import json
import base64
import time
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
timer = time.perf_counter
else:
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
if sys.platform == "win32":
timer = time.clock
else:
# On most other platforms the best timer is time.time()
timer = time.time
API_KEY = ''
SECRET_KEY = ''
# 需要识别的文件
AUDIO_FILE = './audio/16k.pcm' # 只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
# 文件格式
FORMAT = AUDIO_FILE[-3:] # 文件后缀只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
CUID = '123456PYTHON'
# 采样率
RATE = 16000 # 固定值
# 普通版
DEV_PID = 1537 # 1537 表示识别普通话,使用输入法模型。根据文档填写PID,选择语言及识别模型
ASR_URL = 'http://vop.baidu.com/server_api'
SCOPE = 'audio_voice_assistant_get' # 有此scope表示有asr能力,没有请在网页里勾选,非常旧的应用可能没有
#测试自训练平台需要打开以下信息, 自训练平台模型上线后,您会看见 第二步:“”获取专属模型参数pid:8001,modelid:1234”,按照这个信息获取 dev_pid=8001,lm_id=1234
# DEV_PID = 8001 ;
# LM_ID = 1234 ;
# 极速版 打开注释的话请填写自己申请的appkey appSecret ,并在网页中开通极速版(开通后可能会收费)
# DEV_PID = 80001
# ASR_URL = 'http://vop.baidu.com/pro_api'
# SCOPE = 'brain_enhanced_asr' # 有此scope表示有极速版能力,没有请在网页里开通极速版
# 忽略scope检查,非常旧的应用可能没有
# SCOPE = False
class DemoError(Exception):
pass
""" TOKEN start """
TOKEN_URL = 'http://aip.baidubce.com/oauth/2.0/token'
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode( 'utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
print(SCOPE)
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
if __name__ == '__main__':
token = fetch_token()
speech_data = []
with open(AUDIO_FILE, 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
raise DemoError('file %s length read 0 bytes' % AUDIO_FILE)
speech = base64.b64encode(speech_data)
if (IS_PY3):
speech = str(speech, 'utf-8')
params = {'dev_pid': DEV_PID,
#"lm_id" : LM_ID, #测试自训练平台开启此项
'format': FORMAT,
'rate': RATE,
'token': token,
'cuid': CUID,
'channel': 1,
'speech': speech,
'len': length
}
post_data = json.dumps(params, sort_keys=False)
# print post_data
req = Request(ASR_URL, post_data.encode('utf-8'))
req.add_header('Content-Type', 'application/json')
try:
begin = timer()
f = urlopen(req)
result_str = f.read()
print ("Request time cost %f" % (timer() - begin))
except URLError as err:
print('asr http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = str(result_str, 'utf-8')
print(result_str)
with open("result.txt","w") as of:
of.write(result_str)
四、音频转码工具
短语音识别接口不支持MP3格式
可以使用ffmpeg工具转换下音频格式,音频格式可通过ffprobe工具查看,参考:
https://ai.baidu.com/ai-doc/SPEECH/7k38lxpwf#%E6%9F%A5%E7%9C%8B%E9%9F%B3%E9%A2%91%E6%A0%BC%E5%BC%8Fffprobe%E4%BD%BF%E7%94%A8
本文描述如何从其它格式的音频转成符合语音识别输入要求格式的音频文件。即4种格式的音频文件:
pcm(不压缩),也称为raw格式。音频输入最原始的格式,不用再解码。
wav(不压缩,pcm编码):在pcm文件的开头出上加上一个描述采样率,编码等信息的字节。
amr(有损压缩格式),对音频数据进行有损压缩,类似mp3文件。
m4a(有损压缩格式,AAC编码),对音频数据进行有损压缩,通常仅供微信小程序使用的格式。自行转换比较复杂。
由于底层识别使用的是pcm,因此推荐直接上传pcm文件。如果上传其它格式,会在服务器端转码成pcm,调用接口的耗时会增加。
音频参数概念
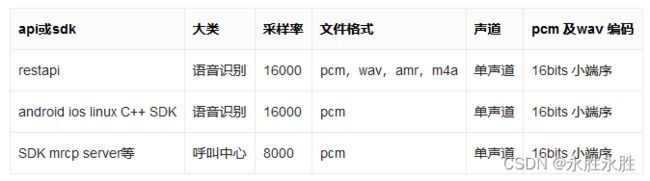
采样率: 百度语音识别一般仅支持16000的采样率。即1秒采样16000次。
位深: 无损音频格式pcm和wav可以设置,百度语音识别使用16bits 小端序 ,即2个字节记录1/16000 s的音频数据。
声道: 百度语音识别仅支持单声道。
以16000采样率 16bits 编码的pcm文件为例,每个16bits(=2bytes)记录了 1/16000s的音频数据。即1s的音频数据为 2bytes * 16000 = 32000B
以下表格的的格式要求仅供参考,具体以调用的api或sdk的文档为准。
音频播放
pcm 播放 ,使用AudioAudition ,选择 16000采样率 ;16位PCM;Little-Endian(即默认字节序)
wav, m4a 播放, 使用AudioAudition 或 完美解码
amr 播放, 使用完美解码
转换命令示例
wav 文件转 16k 16bits 位深的单声道pcm文件
ffmpeg -y -i 16k.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
44100 采样率 单声道 16bts pcm 文件转 16000采样率 16bits 位深的单声道pcm文件
ffmpeg -y -f s16le -ac 1 -ar 44100 -i test44.pcm -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
mp3 文件转 16K 16bits 位深的单声道 pcm文件
ffmpeg -y -i aidemo.mp3 -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
// -acodec pcm_s16le pcm_s16le 16bits 编码器
// -f s16le 保存为16bits pcm格式
// -ac 1 单声道
// -ar 16000 16000采样率
正常输出如下:
Input #0, mp3, from 'aaa.mp3':
Metadata:
encoded_by : Lavf52.24.1
Duration: 00:02:33.05, start: 0.000000, bitrate: 128 kb/s
Stream #0:0: Audio: mp3, 44100 Hz, stereo, s16p, 128 kb/s
// 输入音频, MP3格式, 44100采样率,stereo-双声道, 16bits 编码
Output #0, s16le, to '16k.pcm':
Metadata:
encoded_by : Lavf52.24.1
encoder : Lavf57.71.100
Stream #0:0: Audio: pcm_s16le, 16000 Hz, mono, s16, 256 kb/s
// 输入音频, MP3格式, 16000采样率,mono-单声道, 16bits
// 256 kb/s = 32KB/s = 32B/ms
五、ffmpeg安装
1、去官网 https://ffmpeg.org/download.html
2、找到windows版本

3、点击下载
或者直接通过这个地址下载
https://www.gyan.dev/ffmpeg/builds/ffmpeg-git-full.7z
4、添加环境 变量
进入cmd检验
六、ffmpeg 使用说明
简介
ffmpeg 的一个功能是转换不同的音频格式,其它简介请至http://ffmpeg.org/
linux 版本:http://www.ffmpeg.org/download.html#build-linux linux 静态编译版本:https://www.johnvansickle.com/ffmpeg/ windows 版本 :http://ffmpeg.org/download.html#build-windows
ffmpeg官方文档地址:http://ffmpeg.org/ffmpeg.html
编译参数与支持格式
ffmpeg默认支持pcm与wav(pcm编码)格式,额外的编译参数如下:
--enable-libopencore-amrnb 支持amr-nb(8000 采样率) 读写
--enable-libopencore-amrwb 支持amr-wb(16000 采样率) 读取
--enable-libvo-amrwbenc 支持amr-wb(16000 采样率) 写入
--enable-libmp3lame 支持mp3 写入
--enable-libfdk-aac 使用libfdk作为aac的编码和解码格式
ffmpeg -codecs 可以查看所有的格式:
D..... = Decoding supported # 读取
.E.... = Encoding supported # 写入
..A... = Audio codec # 音频编码
....L. = Lossy compression # 有损
.....S = Lossless compression # 无损
DEA..S pcm_s16le PCM signed 16-bit little-endian
DEA.LS wavpack WavPack
DEA.L. mp3 MP3 (MPEG audio layer 3)
DEA.L. amr_nb AMR-NB (Adaptive Multi-Rate NarrowBand)
DEA.L. amr_wb AMR-WB (Adaptive Multi-Rate WideBand)
DEA.L. aac AAC (Advanced Audio Coding) (decoders: aac aac_fixed )
或
DEA.L. aac AAC (Advanced Audio Coding) (decoders: aac aac_fixed libfdk_aac ) (encoders: aac libfdk_aac )
七、ffmpeg命令
ffmpeg {通用参数} {输入音频参数} {输出音频参数}
ffmpeg -y -i aidemo.mp3 -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
通用参数: -y
输入音频mp3文件参数: -i aidemo.mp3
输出音频 16000采样率 单声道 pcm 格式: -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
示例: 输入是 32000HZ的单声道 16bits pcm文件。查询下文的输入参数为 “ -f s16le -ac 1 -ar 32000 -i test32.pcm” 输出是 16000HZ的单声道 16bits pcm文件。查询下文的输出参数为 “-f s16le -ac 1 -ar 16000 16k.pcm” 常用参数选择 -y
合并如下:
ffmpeg -y -f s16le -ac 1 -ar 32000 -i test32.pcm -f s16le -ac 1 -ar 16000 16k.pcm
输入音频参数
wav、amr、 mp3及m4a格式都自带头部, 含有采样率 编码 多声道等信息。而pcm为原始音频信息,没有类似头部。 wav(pcm编码)格式,仅仅在同样参数的pcm文件加了个几个字节的文件头。
输入 wav、amr、mp3及m4a 等格式:
-i test.wav # 或test.mp3 或者 test.amr
输入 pcm格式: pcm需要额外告知编码格式,采样率,单声道信息
-acodec pcm_s16le -f s16le -ac 1 -ar 16000 -i 8k.pcm
// 单声道 16000 采样率 16bits编码 pcm文件
// s16le s(signied)16(16bits)le(Little-Endian)
-acodec pcm_s16le:使用s16le进行编码
-f s16le 文件格式是s16le的pcm
-ac 1 :单声道
-ar 16000 : 16000采样率
输出音频参数
在原始采样率 大于或者接近16000的时候,推荐使用16000的采样率。 8000的采样率会降低识别效果。 输出wav和amr格式时,如果不指定输出编码器,ffmpeg会选取默认编码器。
输出pcm音频:
-f s16le -ac 1 -ar 16000 16k.pcm
// 单声道 16000 采样率 16bits编码 pcm文件
输出wav 音频:
-ac 1 -ar 16000 16k.wav
// 单声道 16000 采样率 16bits编码 pcm编码的wav文件
输出amr-nb 音频 :
全称是:Adaptive Multi-Rate,自适应多速率,是一种音频编码文件格式,专用于有效地压缩语音频率。在带宽不是瓶颈的情况下,不建议选择这种格式,解压需要百度服务器额外的耗时 amr-nb格式只能选 8000采样率。bit rates越高音质越好,但是文件越大。 bit rates 4.75k, 5.15k, 5.9k, 6.7k, 7.4k, 7.95k, 10.2k or 12.2k
8000的采样率及有损压缩会降低识别效果。如果原始采样率大于16000,请使用 amr-wb格式。
-ac 1 -ar 8000 -ab 12.2k 8k-122.amr
// 8000 采样率 12.2 bitRates
输出 amr-wb 格式,采样率 16000。 bit rates越高音质越好,但是文件越大。 6600 8850 12650 14250 15850 18250 19850 23050 23850
-acodec amr_wb -ac 1 -ar 16000 -ab 23850 16k-23850.amr
输出m4a文件
m4a文件一般来源于微信小程序录音(见restapi文档中微信录音小程序的参数说明)。不建议其它格式转为m4a;推荐转为amr有损压缩格式调用restapi。
如果您一定要转为百度支持的m4a格式,见后文的m4a文件转码
常用参数
-y 覆盖同名文件
-v 日志输出基本 如 -v ERROR -v quiet 等
八、查看音频格式ffprobe使用
查看语音合成生成的MP3格式信息:
ffprobe -v quiet -print_format json -show_streams aidemo.mp3
返回如下
{
"streams": [
{
"index": 0,
"codec_name": "mp3", // mp3 格式
"codec_long_name": "MP3 (MPEG audio layer 3)",
"codec_type": "audio",
"codec_time_base": "1/16000",
"codec_tag_string": "[0][0][0][0]",
"codec_tag": "0x0000",
"sample_fmt": "s16p",
"sample_rate": "16000", // 16000采样率
"channels": 1, // 单声道
"channel_layout": "mono",
"bits_per_sample": 0,
"r_frame_rate": "0/0",
"avg_frame_rate": "0/0",
"time_base": "1/14112000",
"start_pts": 0,
"start_time": "0.000000",
"duration_ts": 259096320,
"duration": "18.360000",
"bit_rate": "16000",
"disposition": {
"default": 0,
"dub": 0,
"original": 0,
"comment": 0,
"lyrics": 0,
"karaoke": 0,
"forced": 0,
"hearing_impaired": 0,
"visual_impaired": 0,
"clean_effects": 0,
"attached_pic": 0,
"timed_thumbnails": 0
}
}
]
}
九、pcm文件音频时长计算
同图像bmp文件一样,pcm文件保存的是未压缩的音频信息。 16bits 编码是指,每次采样的音频信息用2个字节保存。可以对比下bmp文件用分别用2个字节保存RGB颜色的信息。 16000采样率 是指 1秒钟采样 16000次。常见的音频是44100HZ,即一秒采样44100次。 单声道: 只有一个声道。
根据这些信息,我们可以计算: 1秒的16000采样率音频文件大小是 216000 = 32000字节 ,约为32K 1秒的8000采样率音频文件大小是 28000 = 16000字节 ,约为 16K
如果已知录音时长,可以根据文件的大小计算采样率是否正常。
十、转换为m4a格式(AAC编码)
推荐使用amr有损压缩格式,m4a格式用于微信小程序的录音。
需要下载MP4Box,用于转换brand 为mp42:0, mini Version 0 。 restapi不支持brand M4A。点此下载,选Current release里的下载链接。
ffmpeg 官方推荐使用libfdk_aac 库,但这个库需要按照官方文档自行编译。如果使用静态版本的话,也可以使用ffmpeg自带的aac库。
编译过libfdk_aac ffmpeg 示例
ffmpeg -y -f s16le -ac 1 -ar 16000 -i 16k_57test.pcm -c libfdk_aac -profile:a aac_low -b:a 48000 -ar 16000 -ac 1 16k.m4a
MP4Box -brand mp42:0 16k.m4a #这步不能忽略
静态版本自带的aac库示例
ffmpeg -y -f s16le -ac 1 -ar 16000 -i 16k_57test.pcm -c aac -profile:a aac_low -b:a 48000 -ar 16000 -ac 1 16k.m4a
MP4Box -brand mp42:0 16k.m4a #这步不能忽略
输出参数
-c 选编码库 libfdk_aac或者aac
-profile:a profile固定选aac_low(AAC-LC),restapi不支持 例如HE-AAC ,LD,ELD等
-b:a bitrates , 16000采样率对应的bitrates CBR 范围为 24000-96000。越大的话,失真越小,但是文件越大
-ar 采样率,一般固定16000
-ac 固定1,单声道
查看 m4a 格式
> ffprobe 16k.m4a