MySQL数据库(四)
文章目录
- MySQL数据库
-
- 一、外键
-
- 外键前戏
- 外键关系
- 外键字段的建立
- 建立外键时注意事项
- 二、表关系多对多
- 三、表关系一对一
- 四、多表查询思路
- 五、连表查询操作
- 六、Navicat可视化软件
MySQL数据库
一、外键
外键前戏
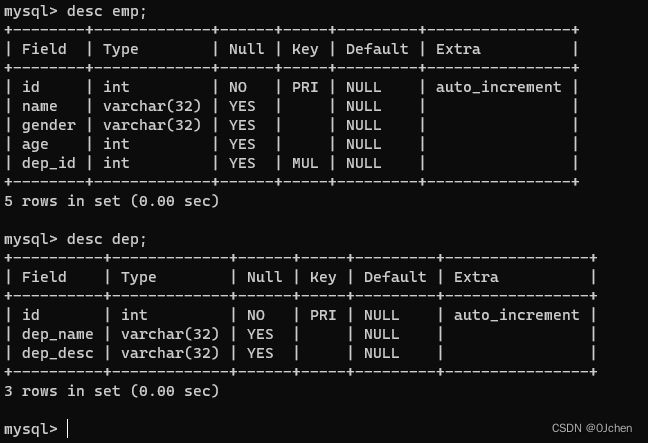
我们建立一张员工表
id name age dep_name dep_desc
'''
1.表不清晰(现在到底是员工表还是部门表) 可以忽略
2.表中相关字段一直在重复存储,浪费资源 可以忽略
3.扩展性、兼容性极差,牵一发而动全身 不能忽略
'''
'那么以上问题该如何解决呢?'
解决方式:
将上述一张表拆分成两张表
emp和dep
'但是表拆分之后,最大的问题就是两张表没有了任何关系'
'''
而这就需要用到外键了
外键:
其实就是用来标识表与表之间的数据关系
简单的理解为通过该字段可以让你查询到另外一张表的数据
'''
外键关系
外键字段主要是用来记录与表与表之间数据的关系,而数据的关系又分为四种:
一对多关系 多对多关系 一对一关系 没有关系
'''那么如何判断表关系呢?(换位思考)'''
以员工表和部门表为例
1.站在员工表角度
问:一个员工数据能否对应多条部门数据?
答:不能
2.站在部门表的角度
问:一个部门数据能否拥有多位员工?
答:能
'结论:换位思考之后得出的答案是一个不可以,一个可以,那么这种的关系就是一对多'
针对一对多的关系,外键字段是只能创建在多的那一方(员工表)(没有多对一,统称为一对多)
外键字段的建立
如何在SQL层面建立一对多的关系:先把基础表中的基础字段建立出来,然后在考虑写外键字段
'部门表'
create table dep(
id int primary key auto_increment, # id 配置主键自增
dep_name varchar(32), # 部门名
dep_desc varchar(32) # 部门描述
);
'当配置好部门表后再来配置建立外键的员工表'
'员工表'
create table emp(
id int primary key auto_increment, # id 配置主键自增
name varchar(32), # 姓名
gender varchar(32), # 性别
age int, # 年龄
dep_id int, # 用于关联部门表
foreign key(dep_id) references dep(id) #让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade # 级联删除
);
建立外键时注意事项
- 在创建表的时候 需要先创建呗关联表(没有建立外键字段的表)
- 在插入新数据的时候,应该确保被关联表中有数据
- 在插入新数据的时候,外键字段只能填写被关联表中已经存在的数据
- 在修改和删除被关联表中的数据的时候,无法直接操作,
需要添加级联更新(on update cascade)、级联删除(on delete cascade)配置
(被关联的数据一旦变动 关联的数据同步变动)
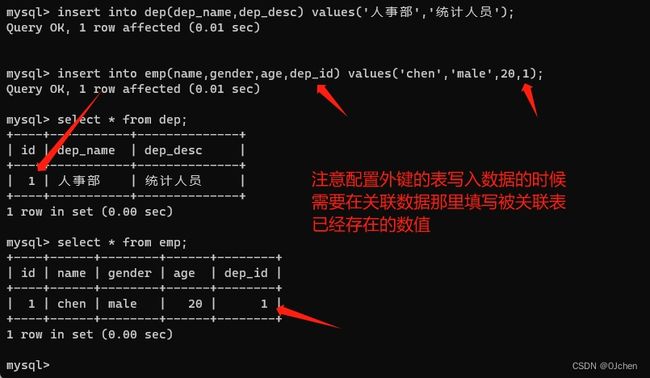
可以录入数据试试
'记住先录入被关联表的数据哦!(没有配置外键的表)'
insert into dep(dep_name,dep_desc) values('人事部','统计人员');
insert into emp(name,gender,age,dep_id) values('chen','male',20,1);
'''可以看到已经配置成功了'''
在实际工作中外键也可能不会使用,因为外键会消耗额外的资源,并且会增加表的复杂度。
表很多的情况下,我们也可以通过SQL语句的形式建立逻辑意义上的表关系
二、表关系多对多
我们就以图书表盒作者表引入
1.我们站在图书表的角度
问:一本图书能不能有多个作者?
答:可以
2.我们再站在作者表的角度
问:一个作者能不能有多本书?
答:可以
'换位思考之后得出答案,两边都可以,那么表的数据关系就是多对多(针对多对多关系,外键字段不能建在任意一表)'
'针对多对多关系 我们需要单独在开设第三张表来专门存储双方的外键关系'
在SQL层面建立多对多的表关系,还是如一对多一样,先把基础表中的基础字段建立出来,然后在考虑写外键字段
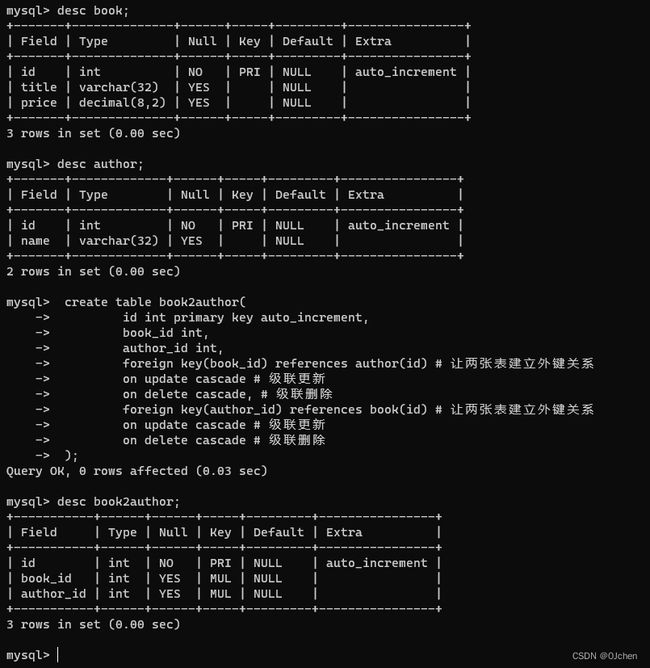
'图书表'
create table book(
id int primary key auto_increment,
title varchar(32),
price decimal(8,2)
);
'作者表'
create table author(
id int primary key auto_increment,
name varchar(32)
);
'开设的第三张表(存储关系)'
create table book2author(
id int primary key auto_increment,
book_id int,
author_id int,
foreign key(book_id) references author(id) # 让两张表建立外键关系
on update cascade # 级联更新
on delete cascade, # 级联删除
foreign key(author_id) references book(id) # 让两张表建立外键关系
on update cascade # 级联更新
on delete cascade # 级联删除
);
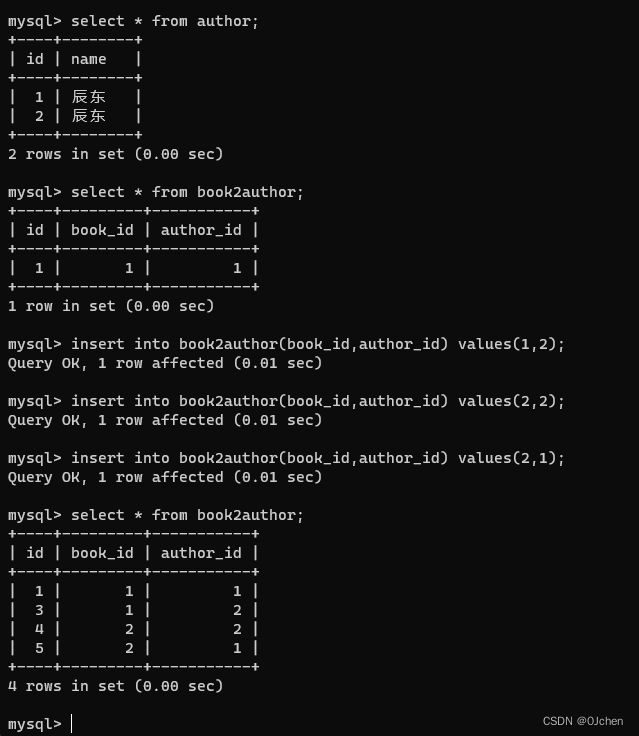
可以录入数据试试
insert into book(title,price) values('完美世界',200);
insert into author(name) values('辰东');
insert into book(title,price) values('遮天',300);
insert into author(name) values('辰东');
'同一对多一样先录入呗关联表的数据'
insert into book2author(book_id,author_id) values(1,1);
insert into book2author(book_id,author_id) values(1,2);
insert into book2author(book_id,author_id) values(2,1);
insert into book2author(book_id,author_id) values(2,2);
'''
针对多对多关系
两张基础表内的数据没有在第三张表内绑定关系的情况下随意新增修改删除
'''
三、表关系一对一
我们以作者表和作者详情表为例引入
1.先站在用户表的角度
问:一个用户能否对应多个用户详情?
答:不可以
2.再站在用户详情表的角度
问:一个用户详情能否对应多个用户?
答:不可以
'换位思考之后得出答案,两边都不可以,那么就先考虑是不是没有关系 如果是有逻辑上的关系那么肯定是一对一'
'针对一对一关系,外键字段可以建在任何一方表中,但是推荐建在查询频率较高的表中,便于后续查询'
在SQL层面建立一对一的表关系,一样先建立基础表,在考虑写外键字段
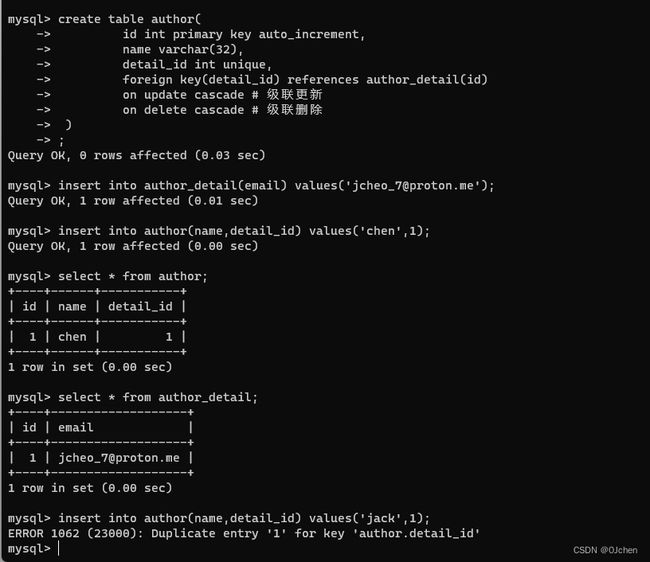
'作者详情表'
create table author_detail(
id int primary key auto_increment,
email varchar(32)
);
'作者表'
create table author(
id int primary key auto_increment,
name varchar(32),
detail_id int unique,
foreign key(detail_id) references author_detail(id)
on update cascade # 级联更新
on delete cascade # 级联删除
);
'与多对一不同的就是多一个unique唯一约束条件,使用过就不能再次使用'
也可以录入数据试试
insert into author_detail(email) values('[email protected]');
insert into author(name,detail_id) values('chen',1);
四、多表查询思路
多表查询的思路共两种:
1.子查询
将一条SQL语句的查询结果加括号当做另外一条SQL语句的查询条件
就相当于我是我们日常生活中解决问题的方式
第一步做什么,第二步在第一步基础上再做操作(分步操作)
2.连表查询
先将多张表拼接到一起,形成一张大的虚拟表表,连接出来的虚拟表不是实际存在的,
它是在内存中存储的,然后基于单表查询获取数据
专业的连表语法:
inner join # 内连接,查询的是两张表中都有的数据
left join # 左连接,以左表为基准,查询左表中所有的数据,右表没有的数据使用NULL填充
right join # 右连接,以右表为基准,查询右表中所有的数据,左表没有的数据使用NULL填充
union # 连接两个SQL语句的结果
创建表
create table dep(
id int primary key auto_increment,
name varchar(32)
);
create table emp(
id int primary key auto_increment,
name varchar(32),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
'如果两张表没有建立强制的约束关系,就使用逻辑意义上的关联'
添加数据
insert into dep values(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'安保');
insert into emp(name,sex,age,dep_id) values('jason','male',18,200),
('dragon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
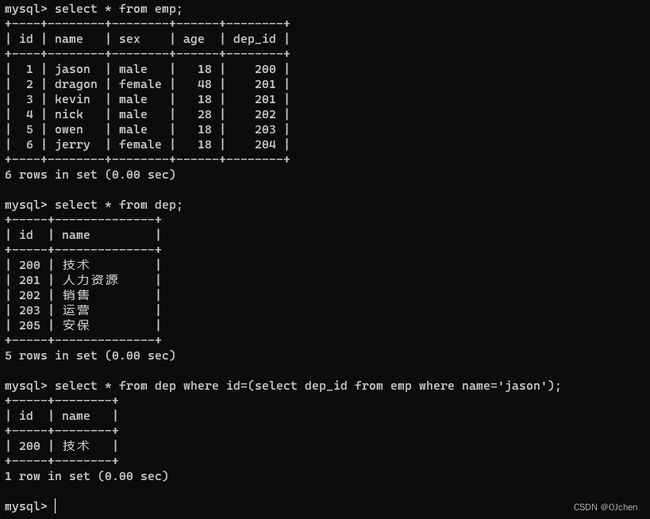
获取jason的部门名称
正常步骤:先查jason所在的部门编号,在根据部门编号去部门表中查找部门名称
select dep_id from emp where name='jason';
select name from dep where id=200;
子查询方式
select * from dep where id=(select dep_id from emp where name='jason')
五、连表查询操作
eg:还是以上面的员工表和部门表为例
连表查询步骤:
1.先将员工表和部门表按照某个字段拼接到一起
2.基于单表查询
我们正常的想法就是将两个表一起倒入就好了 但是我们看一下结果
select * from emp,dep;
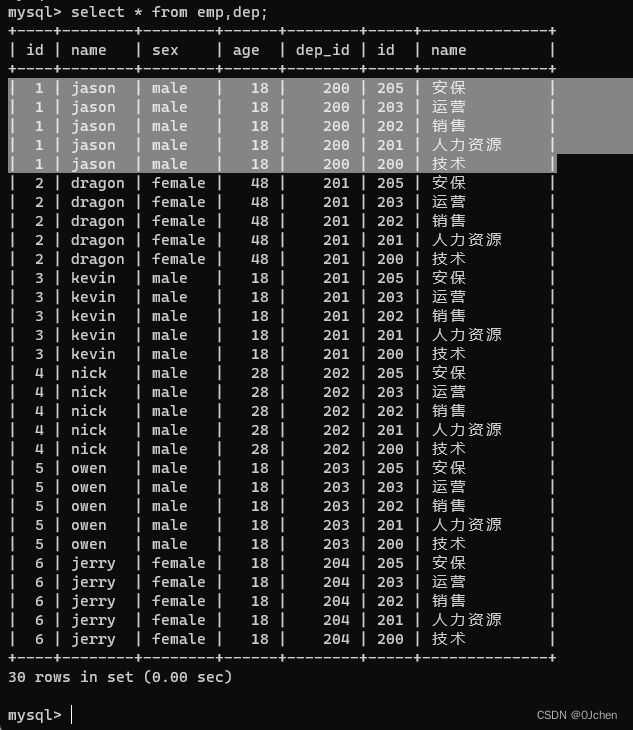
每个emp表都匹配了所有的dep表的数据,这是因为中间产生了笛卡尔积现象
会将几个表里面的数据全部匹配一遍,匹配多少遍取决于表里面的内容
我们不会使用笛卡尔积来求数据,效率太低,连表有专门的语法
select * from emp,dep where emp.dep_id=dep.id;
select * from emp,dep where dep.id=emp.dep.id;
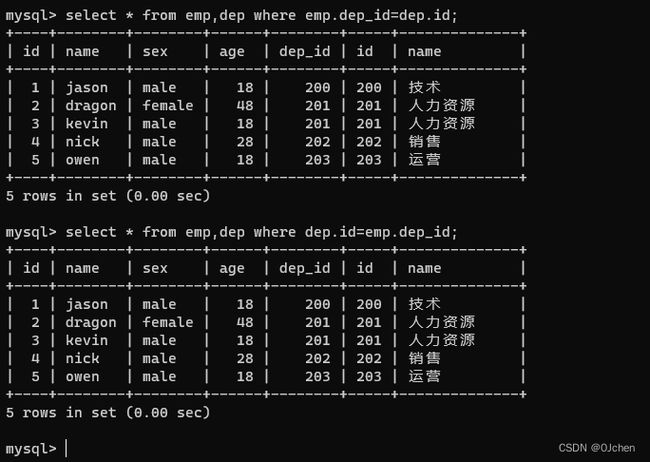
以上的方法不推荐使用,应该使用连表专门的方式总共四种
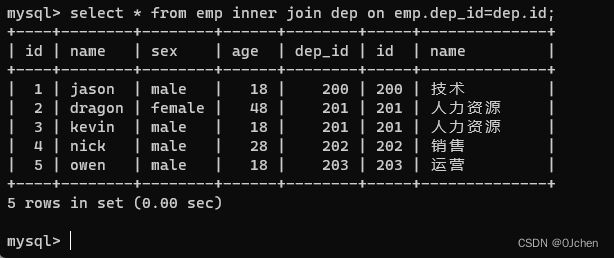
1.内连接 inner join (查询的是两张表中都有的数据)
select * from emp inner join dep on emp.dep_id=dep.id;
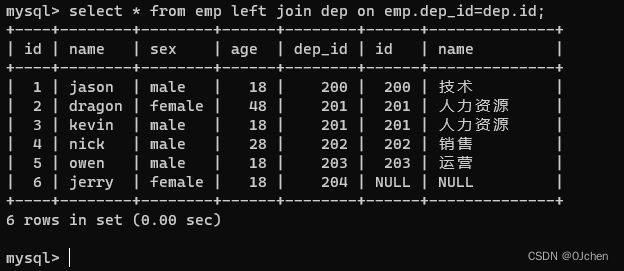
2.左连接 left join(以左表为基准,查询左表中所有的数据,右表没有的数据使用NULL填充)
select * from emp left join dep on emp.dep.id=dep.id;
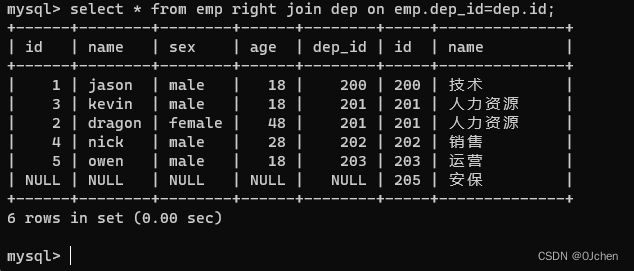
3.右连接 right join(以右表为基准,查询右表中所有的数据,左表没有的数据使用NULL填充)
select * from emp right join dep on emp.dep_id=dep.id;
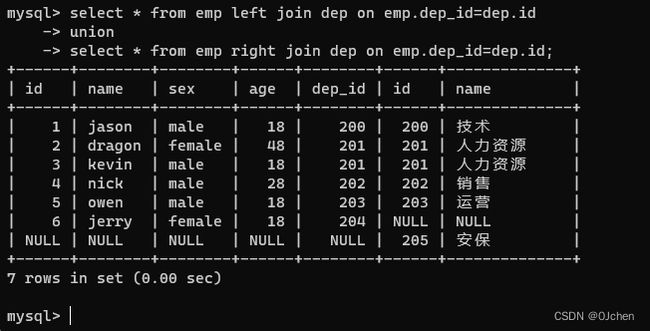
4.全连接 union(连接两个SQL语句的结果)
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
六、Navicat可视化软件
Navicat可以充当很多数据库软件的客户端,提供了图形化界面能够让我们更加快读的操作数据库
具体下载方式自行搜索引擎即可
使用:
内部封装了SQL语句 用户只需要鼠标点点点就可以快速操作
连接数据库、创建库和表 录入数据 操作数据
外键 SQL文件 逆向数据库到模型 查询(自己写的SQL语句)
# 使用navicat编写SQL 如果自动补全语句 那么关键字都会变大写
SQL语句注释语法(快捷键于pycharm中的一致 ctrl+?)