IDA Pro 反汇编器使用详解,适合逆向新人和老人的权威指南(一)
一、前言 IDA背景知识
反汇编和反编译
在谈论IDA的使用之前,我们先探讨一下 什么是反汇编和反编译?
我们都知道编程过程,就是将源程序通过编译器转化为汇编语言,或者直接转换成机器语言(或某种大致的等价形式,如字节码)。而为了对程序进行逆向工程,我们使用各种工具来撤销汇编和编译过程;这里的工具分别是反汇编器和反编译器,反汇编将目标代码转换成汇编语言,反编译将汇编语言或是机器语言转换为我们较为熟知的高级语言。
谈论反汇编,就不得不说到最主要的俩种反汇编算法--线性扫描算法和递归下降算法。
线性扫描算法
线性扫描算法采用一种非常简单的方法确定需要反汇编的指令位置:一条指令结束、另一条指令开始的地方。因此,确定起始位置最为困难,常用的解决方法是,假设程序中标注为代码的节所包含的全部是机器语言代码。反汇编从一个代码段的第一个字节开始,以线性模式扫描整个代码段,逐条反汇编每条指令,直到完成整个代码段,这种算法并不会通过识别分支等非线性指令来了解程序的控制流。
优点:能够完全覆盖程序所有代码段。
缺点:没有考虑代码中可能混有数据,即无法正确地将嵌入的数据和代码区分开。
递归下降算法
递归下降采取另外一种不同的方法来定位指令。递归下载算法强调控制流的概念。控制流根据一条指令是否被另一条指令引用来决定是否对其进行反汇编。
指令对CPU指令指针的影响可以分为五类:
1.顺序流指令:顺序流指令将执行权传递给紧随其后的下一条指令。顺序流指令的例子包括简单算术指令如 add; 寄存器与内存之间的传输指令,如 mov; 栈操作指令,如 push 和 pop。这些指令的反汇编过程以线性扫描方式进行。
2.条件分支指令:条件分支指令(如 x86 jnz) 提供两条可能的执行路径。如果条件为真,则执行分支,并目必须修改指令指针,使其指向分支的目标。但是,如果条件为假,则继续以线性模式执行指令,并使用线性扫描方法反汇编下一条指令。
3.无条件分支指令:无条件分支并不遵循线性流模式,因此,它由递归下降算法以不同的方式处理。与顺序流指令一样,执行权只能传递给一条指令,但那条指令不需要紧接在分支指令后面。递归下降反汇编器将尝试确定无条件跳转的目标,并将目标地址添加到要反汇编的地址列表中。
4.函数调用指令:函数调用指令的运行方式与无条件跳转指令非常相似,唯一的不同在于,一旦函数完成,执行权将返回给紧跟在调用指令后面的指令。在这方面,它们与条件分支指令类似,因为它们都生成两条执行路径。调用指令的目标地址被添加到推迟进行反汇编的地址列表中,而紧跟在调用后面的指令则以类似于线性扫描的方式进行反汇编。从被调用函数返回时,如果程序的运行出现异常,递归下降就有可能失败。例如,函数中的代码可能会有意窜改该函数的返回地址,这样,在函数完成时,控制权将返回到一个反汇编器无法预知的地址。 5.返回指令:有时,递归下降算法访问了所有的路径。而且,函数返回指令(如 x86 ret) 没有提供接下来将要执行的指令的信息。这时,如果程序确实正在运行,则可以从运行时栈顶部获得一个地址并从这个地址开始恢复执行指令。但是,反汇编器并不具备访问栈的能力,因此反汇编过程会突然终止。这时,递归下降反汇编器会转而处理前面搁置在一旁的延迟反汇编地址列表。反汇编器从这个列表中取出一个地址,并从这个地址开始继续反汇编过程。递归下降反汇编算法正是因此而得名。
主要优点:它具有区分代码与数据的强大能力。
主要缺点:它无法处理间接代码路径,如利用指针表来查找目标地址的跳转或调用。
(了解反汇编算法对逆向工程是有用滴~)
IDA Pro
交互式反汇编器专业版 (Interactive Disassembler Professional),人们常称为 IDA Pro,或简称为DA,是总部位于比利时列目市 (Lige)的 Hex-Rays"公司销售的一款产品。开发IDA的编程天才名叫 Ilfak Guilfanov,人们常叫他 Ilfak。十多年前诞生时,IDA 还是一个基于控制台的 MS-DOS 应用程序,这一点很重要,因为它有助于我们理解 IDA 用户界面的本质。除其他内容外,IDA的非 GUI版本是针对所有 IDA 支持的平台发布的,并且继续采用源于最初DOS 版本的控制台形式的界面。
就其本质而言,IDA 是一种递归下降反汇编器。但是,为了提高递归下降过程的效率,IDA的开发者付出了巨大的努力,来为这个过程开发逻辑。为了克服递归下降的一个最大的缺点,IDA应用大量启发式技术来识别那些在递归下降过程中遗漏的代码。除反汇编过程本身外,IDA 在区分数据与代码的同时,还设法确定这些数据的类型。虽然你在 IDA 中看到的是汇编语言形式的代码,但 IDA 的主要目标之一在于,呈现尽可能接近源代码的代码。此外,IDA 不仅使用数据类型信息,而且通过派生的变量和函数名称来尽其所能地注释生成的反汇编代码。这些注释将原始十六进制代码的数量减到最少,并显著增加了向用户提供的符号化信息的数量。
二、IDA基本用法
IDA启动

双击IDA后,会显示一个初始欢迎界面,上面是你的许可证信息,界面消失后会显示上图的对话框,若是你不想每次都看到它,可以取消勾选底部的Display at startup;
这里New是新建,将会启动一个file open对话框来选择将要分析的文件;Go是运行,打开一个空白的工作区;Previous是打开其下方最近用过的文件中的一个。
打开File - Open会加载一个对话框

顶部是最适合处理选定文件的IDA加载器,分别是Windows PE加载器和MS-DOS EXE加载器,Binary file 是二进制文件。这里默认OK就好。
关闭IDA
当你关闭IDA或是切换到另外一个database'时,都会显示一个save database对话框

初次保存一个新建的数据库时,IDA会用扩展名.idb替换输入文件的扩展名。
选项:
Don't pack database(不打包数据库)。在关闭桌面时不创建idb文件,不建议选择。
Pack datase(Store)[打包数据库(存储)]。选择Store会将四个数据库组件文件存入一个IDB文件中。
Pack datase(Deflate)[打包数据库(压缩)]。区别在于会将四个数据库组件文件压缩到idb文件中。
Collect farbage(收集垃圾)。选择后IDA会在关闭数据库之前,删除数据库中没有用的内存页面。
DON'T SAVE the database(不保存数据库)。顾名思义。
IDA桌面简介 IDA数据窗口

这是一个IDA桌面,
工作栏区域包含与IDA的常用操作对应的工具,可以用View-Toolbars命令显示或隐藏工具栏。
彩色的水平带是IDA的概况导航栏。它是被加载文件地址空间的线性视图。
反汇编窗口
反汇编视图是主要数据显示视图,它有俩种不同的形式,图形视图(默认)和列表视图。可以在Options-General菜单打开IDA Options复选框,取消Graph选项卡下的Use graph view default(默认使用图形视图)复选框。
IDA图形视图
图形视图会让人联想到流程图,因为它将一个函数分解成许多基本块,以生动的显示一个块到了另一个块的控制流程。
在屏幕上你会发现不同颜色的箭头,绿色的箭头是执行,不执行的是红色,只有一个后继块的会用一个蓝色的箭头。
在面对一些窗口显示不完全的复杂的图形视图,可以用ctrl+鼠标滚轮或者ctrl+加减号来缩放图形视图,也可以对图形视图进行分组或折叠,通过右击块的标题栏,点击Group Nodes

IDA文本视图
反汇编窗口显示的是完整的汇编代码。
文本视图最左侧的是箭头窗口,用于描述函数中的非线性流程;中间的声明是ida对函数栈桢布局的最准确估计。

输出窗口
输出窗口是显示IDA输出的信息。当你打开一个新文件时,IDA工作区底部的输出窗口与其他窗口一起组成了IDA的默认窗口输出窗口是IDA的输出控制台,从中可以找到与IDA所执行的任务有关的信息。例如,当你初次打开一个二进制文件时,IDA将生成消息,指出它在某个时刻所处的分析阶段,以及它为创建新数据库而执行的操作。当你使用数据库时,输出窗口将输出你所执行的各种操作的状态。你可以将输出窗口中的内容复制到系统剪贴板中,也可以右击窗口的任何位置,并在出现的菜单中选择相应的操作而完全删除输出窗口的内容。通常,输出窗口是显示你为IDA开发的任何脚本和插件的输出的主要窗口。

函数窗口
函数窗口用于举例IDA在数据库中识别的每一个函数。与其他显示窗口一样,双击Functions窗口中的一个条目,反汇编窗口将跳转到选定函数所在的位置。
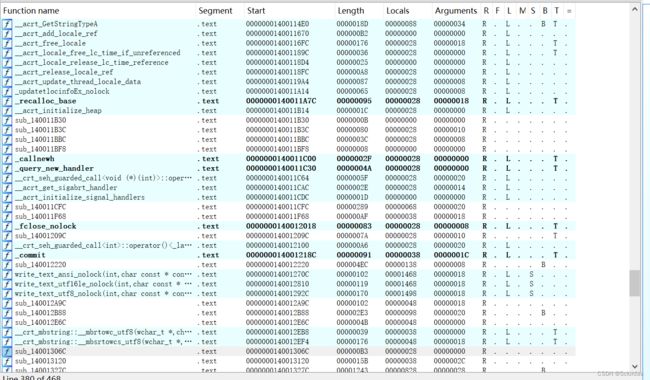
这里信息特别指出:用户可以在二进制文件中虚拟地址为Start的segment部分找到某个函数;该函数长为length字节(十六进制为180字节),它返回调用方(R),并调用了某寄存器(最后面几行,如R,B) 引用它的局部变量。如需了解更多有关用于描述函数的标记(如上面的R和B)的信息,请参阅IDA 的内部帮助文档(或右击一个函数并选择Properties,标记将以可编辑的复选框显示)。
String窗口
Strings窗口中显示的是从二进制文件中提取出的一组字符串,以及每个字符串所在的地址。,双击Strings窗口中的任何字符串,反汇编窗口将跳转到 该字符串所在的地址。将Strings窗口与交叉引用相结合,可迅速定位你感兴趣的字符串,并追踪到程序中任何引用该字符串的位置。
按shift+F12 或者通过View-Open Subviews-Strings命令打开该窗口。

未完待续....
本文摘自《IDA Pro权威指南》。