使用kubeadm安装单master节点的k8s集群
环境准备
准备2台干净的虚拟机,如果之前安装过docker或者k8s,需要卸载干净。
2台机器网络能够相互连通,操作系统centos7以上,root权限
系统规划
2台虚拟机分别命名为kube1,kube2
kube1作为控制平面(master)节点,kube2作为工作(worker)节点
修改/etc/hosts文件,2台都需要操作,在文件最后添加域名解析,类似下面这样
192.168.1.101 kube1 192.168.1.102 kube2
以上命令实际上只是修改了本地的dns,hostname使用下面的命令再修改一下
hostname kube1 #在第一台机器上执行
hostname kube2 #在第二台机器上执行
安装前准备
所有机器都需要满足要求,包括master和worker
确保每个节点上mac地址和product_uuid的唯一性
查看mac地址
ip link
查看product_uuid
cat /sys/class/dmi/id/product_uuid
允许 iptables 检查桥接流量
使用以下代码使br_netfilter被加载,使 iptables 能够正确地查看桥接流量
cat <开放所需端口
以下端口是k8s集群需要用到的端口,要确保开放
master节点
协议 方向 端口范围 作用 使用者 TCP 入站 6443 Kubernetes API 服务器 所有组件 TCP 入站 2379-2380 etcd 服务器客户端 API kube-apiserver, etcd TCP 入站 10250 Kubelet API kubelet 自身、控制平面组件 TCP 入站 10251 kube-scheduler kube-scheduler 自身 TCP 入站 10252 kube-controller-manager kube-controller-manager 自身 使用命令:
firewall-cmd --permanent --zone=public --add-port=6443/tcp --add-port=2379-2380/tcp --add-port=10250/tcp --add-port=10251/tcp --add-port=10252/tcp firewall-cmd --reloadworker节点
协议 方向 端口范围 作用 使用者 TCP 入站 10250 Kubelet API kubelet 自身、控制平面组件 TCP 入站 30000-32767 NodePort 服务 所有组件 firewall-cmd --permanent --add-port=10250/tcp --add-port=30000-32767/tcp firewall-cmd --reload安装docker
安装yum辅助工具
yum install -y yum-utils添加docker软件源
yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo查看可用的docker版本,安装docker时,建议加上docker版本,以便于以后维护
yum list docker-ce --showduplicates | sort -r选择一个docker版本进行安装,我选择了docker-ce 3:19.03.9-3.el7,对应docker-ce-cli 1:19.03.9-3.el7,官方给出的安装命令如下,所以containerd.io不需要指定版本
yum install docker-ce-
docker-ce-cli- containerd.io 执行以下命令进行安装
yum install docker-ce-19.03.9 docker-ce-cli-19.03.9 containerd.io安装完成后启动docker,并将docker设置为开机启动
如果不将docker设置为开机启动,kubeadm init时会报错
systemctl start docker systemctl enable docker测试docker是否安装成功
docker run hello-world如果出现如下字样,说明docker应该安装成功了
Hello from Docker! This message shows that your installation appears to be working correctly.
设置docker国内下载源
tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://docker.mirrors.ustc.edu.cn","https://registry.docker-cn.com"] } EOF关闭swap分区
swapoff -a #临时关闭swap分区 vim /etc/fstab #注释swap的那一行 free -m #检查swap分区是否已关闭关闭selinux
setenforce 0 #临时关闭 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config #永久关闭安装 kubeadm、kubelet 和 kubectl
你需要在每台机器上安装以下的软件包:
kubeadm:用来初始化集群的指令。kubelet:在集群中的每个节点上用来启动 Pod 和容器等。kubectl:用来与集群通信的命令行工具。官方使用了google的镜像,但是国内很难下载到,所以我们将它换成中科大的镜像(其他的镜像站也可以用,个人觉得还是中科大的最好用),但是中科大的镜像站没有找到gpg的key,所以就不做gpgcheck了。
cat <启动之后,kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。
组建集群
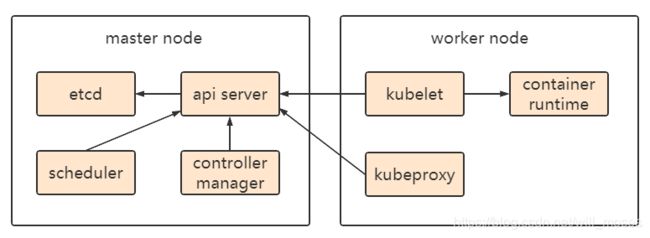
简单介绍一下master节点和worker节点的组成。
master节点就是控制平面节点(官方文档中直译过来的叫法),worker node代表工作节点,从图中可以看到,master节点包含:apiserver、coltroller-manager、scheduler、etcd四个组件,worker节点包含:container-runtime、kubeproxy、kubelet三个组件。
但是master节点也可以同时也是worker节点,所以安装的时候,master节点也包含:kubelet、kuberproxy、container runtime。container runtime大多数情况下使用docker。
kubeadm init之前的准备工作
下载kubeadm init时需要用到的docker image
因为默认的配置是从google下载,而且镜像名称中带有k8s.gcr.io,使用国内源直接下载可能会出现问题,所以,我们先降需要用到的docker images下载好
使用以下命令查看需要用到的docker images,因为kubeadm、kubectl、kubelet都使用了1.19.8的版本,所以kubernetes也使用1.19.8版本了官网说: kubelet 的版本不可以超过 API server的版本,可以理解为kubernetes的版本高于kubelet是没有问题的,版本相同应该是最好的。
kubeadm --kubernetes-version 1.19.8 config images list返回结果:
k8s.gcr.io/kube-apiserver:v1.19.8 k8s.gcr.io/kube-controller-manager:v1.19.8 k8s.gcr.io/kube-scheduler:v1.19.8 k8s.gcr.io/kube-proxy:v1.19.8 k8s.gcr.io/pause:3.2 k8s.gcr.io/etcd:3.4.13-0 k8s.gcr.io/coredns:1.7.0从国内镜像站将这些docker image全部下载好。
我的办法是从https://hub.docker.com/search?q=&type=image这个网站上逐个去搜
kube-apiserver、kube-controller-manager、kube-scheduler、kube-proxy、pause、etcd、coredns
下面以kube-apiserver为例说明
从docker hub上搜到这个镜像之后,使用docker pull下载下来,类似下面这个例子
docker pull k8smx/kube-apiserver:v1.19.8使用docker images可以看到已经下载到了这个docker images
[root@brdev1 ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE aiotceo/kube-apiserver v1.20.5 d7e24aeb3b10 3 weeks ago 122MB k8s.gcr.io/kube-apiserver v1.20.5 d7e24aeb3b10 3 weeks ago 122MB aiotceo/kube-controller-manager v1.20.5 6f0c3da8c99e 3 weeks ago 116MB hello-world latest d1165f221234 4 weeks ago 13.3kB k8smx/kube-apiserver v1.19.8 9ba91a90b7d1 7 weeks ago 119MB然后将其重命名为k8s.gcr.io/kube-apiserver:v1.19.8
[root@brdev1 ~]# docker tag k8smx/kube-apiserver:v1.19.8 k8s.gcr.io/kube-apiserver:v1.19.8 [root@brdev1 ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE aiotceo/kube-apiserver v1.20.5 d7e24aeb3b10 3 weeks ago 122MB k8s.gcr.io/kube-apiserver v1.20.5 d7e24aeb3b10 3 weeks ago 122MB aiotceo/kube-controller-manager v1.20.5 6f0c3da8c99e 3 weeks ago 116MB hello-world latest d1165f221234 4 weeks ago 13.3kB k8smx/kube-apiserver v1.19.8 9ba91a90b7d1 7 weeks ago 119MB k8s.gcr.io/kube-apiserver v1.19.8 9ba91a90b7d1 7 weeks ago 119MB可以看到我们需要的k8s.gcr.io/kube-apiserver:v1.19.8已经在本地了,用相同的方法下载其余docker image
这个下载地址的docker image挺全的:https://hub.docker.com/u/k8smx,大家可以从这里下载。
我也已经将所需要的docker images全部放到腾讯微云上了,有需要的小伙伴可以直接下载,使用方法会在下文中说到。
微云地址:https://share.weiyun.com/s93S1fWw
执行kubeadm init并安装pod网络组件
kubeadm init初始化集群
kubeadm init之前规划好service和pod的网络空间,找一个跟现有网络不冲突的网络段即可,我随便选了两个网段
service网络空间 --service-cidr=10.18.0.0/16
pod网络空间 --pod-network-cidr=10.19.0.0/16
kubeadm所在机器的IP --apiserver-advertise-address=192.168.1.101
kubernetes版本 --kubernetes-version=1.19.8
执行kubeadm init
kubeadm init --kubernetes-version=1.19.8 \ --apiserver-advertise-address=192.168.1.101 \ --service-cidr=10.18.0.0/16 \ --pod-network-cidr=10.19.0.0/16大概2分钟左右,就执行成功了。
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.1.101:6443 --token 73vi27.3gndl08t126iaba0 \ --discovery-token-ca-cert-hash sha256:9bf4639635b62b347d76d0fbb43dc31cf72973c3fa2b358cd9101e422ec851a7按照提示所述,执行以下命令
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config按照提示所述,在worker节点执行以下命令就可以加入集群了
kubeadm join 192.168.1.101:6443 --token 73vi27.3gndl08t126iaba0 \ --discovery-token-ca-cert-hash sha256:9bf4639635b62b347d76d0fbb43dc31cf72973c3fa2b358cd9101e422ec851a7安装pod网络组件
下面的pod网络安装方法是参考了calico的快速开始,后来在实际部署中发现了更完善的部署方式,会在后续文章中介绍。
pod网络组件的功能是使pod之间能够像独立的设备一样通信。官方说: 目前 Calico 是 kubeadm 项目中执行 e2e 测试的唯一 CNI 插件。那么我们就选择calico吧。
安装pod网络组件很简单,要搞懂它的原理稍微复杂一点,我们这里只讲安装,复杂的原理以后有时间再说
kubectl create -f https://docs.projectcalico.org/manifests/tigera-operator.yamlwget https://docs.projectcalico.org/manifests/custom-resources.yaml打开 custom-resources.yaml文件,文件内容很少,把cdir改成kubeadm init使所用到的--pod-network-cidr=10.19.0.0/16中的10.19.0.0/16,然后执行
kubectl create -f custom-resources.yaml等待一段时间(这个过程也是需要下载docker image的),使用以下命令查看calico的相关的3个pod状态都为running,就代表calico安装成功了。
[root@brdev1 ~]# kubectl get pods -n calico-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-7b498688c4-djwrc 1/1 Running 0 71m calico-node-bvbcq 1/1 Running 0 71m calico-typha-fdd8c8f74-5qx8j 1/1 Running 0 71m然后再检查一下所有的pod是否都处于running状态
[root@brdev1 ~]# kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE calico-system calico-kube-controllers-7b498688c4-djwrc 1/1 Running 0 76m calico-system calico-node-bvbcq 1/1 Running 0 76m calico-system calico-typha-fdd8c8f74-5qx8j 1/1 Running 0 76m kube-system coredns-f9fd979d6-gfc45 1/1 Running 0 17h kube-system coredns-f9fd979d6-q8hjd 1/1 Running 0 17h kube-system etcd-brdev1 1/1 Running 1 17h kube-system kube-apiserver-brdev1 1/1 Running 0 17h kube-system kube-controller-manager-brdev1 1/1 Running 4 17h kube-system kube-proxy-hcm5k 1/1 Running 0 17h kube-system kube-scheduler-brdev1 1/1 Running 4 17h tigera-operator tigera-operator-675ccbb69c-z2459 1/1 Running 3 78mkubeadm join加入集群
上面介绍过worker node的组成包含:kubelet、kubeproxy、runtime,其中kubelet和runtime(也就是docker)已经安装好了,还差kubeproxy,kubeadm join的时候会自动去下载kubeproxy,还是老问题,google下载不到,所以要提前为worker node准备好kubeproxy配套的docker image,启动kubeproxy需要用到的docker image除了k8s.gcr.io/kube-proxy,还需要k8s.gcr.io/pause。
除了kubeproxy,每一个节点(包括master和worker)都需要calico,calico是能从网上下载到的,但是为了更快启动,直接从master节点上k8s相关的docker images全部导到worker中。
1、在master node上将与k8s相关的docker images全部导出
docker save -o k8s.1.19.8.tar k8s.gcr.io/kube-apiserver:v1.19.8 k8s.gcr.io/kube-proxy:v1.19.8 k8s.gcr.io/kube-controller-manager:v1.19.8 k8s.gcr.io/kube-scheduler:v1.19.8 k8s.gcr.io/etcd:3.4.13-0 k8s.gcr.io/coredns:1.7.0 k8s.gcr.io/pause:3.2 calico/node:v3.18.1 calico/typha:v3.18.1 calico/pod2daemon-flexvol:v3.18.1 calico/cni:v3.18.1 calico/kube-controllers:v3.18.12、在worker上导入k8s.1.19.8.tar
docker load < k8s.1.19.8.tar3、执行kubeadm join
kubeadm join 192.168.1.101:6443 --token 73vi27.3gndl08t126iaba0 \ --discovery-token-ca-cert-hash sha256:9bf4639635b62b347d76d0fbb43dc31cf72973c3fa2b358cd9101e422ec851a7等待一段时间查看各node状态,可以看到都已经ready了。
[root@brdev1 ~]# kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME kube1 Ready master 18h v1.19.8 192.168.1.101CentOS Linux 7 (Core) 3.10.0-514.2.2.el7.x86_64 docker://19.03.9 kube2 Ready 96m v1.19.8 192.168.1.102 CentOS Linux 7 (Core) 3.10.0-957.12.2.el7.x86_64 docker://19.03.9 到此为止,单控制平面节点的k8s集群就搭建完成了。
后续知识点学习
1、增加worker节点、网络插件flannel和calico对比
2、通过部署服务来学习k8s的各种概念和使用方式
3、k8s证书概念以及证书续期的两种方式
4、高可用k8s集群介绍和使用kubespray安装高可用k8s集群