华为机试题:HJ102 字符统计(python)
文章目录
- (1)题目描述
- (2)Python3实现
- (3)知识点详解
-
- 1、input():获取控制台(任意形式)的输入。输出均为字符串类型。
-
- 1.1、input() 与 list(input()) 的区别、及其相互转换方法
- 2、print() :打印输出。
- 3、dict字典的常用操作(14+4函数)—— 字典是一个无序可变序列。
- 4、匿名函数 - lambda:对输入参数进行表达式计算
- 5、sorted() :对所有可迭代类型进行排序,不改变原始序列。按照ASCII的大小进行排序(数字 >> 大写字母 >> 小写字母)。
- 6、字符串str() :将参数转换成字符串类型(强转)—— 字符串是有序不可变序列。
- 7、str.join():将序列(字符串、元组、列表、字典)中的元素以指定字符连接,并返回一个新的字符串。
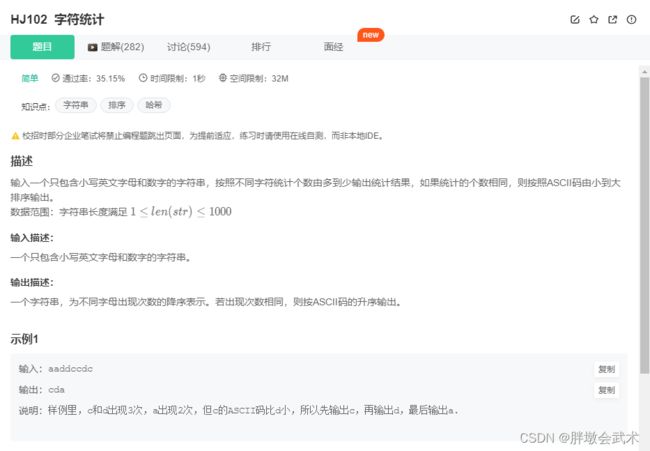
(1)题目描述
(2)Python3实现
while True:
try:
str1 = input()
dic1 = {}
for ii in str1:
if ii not in dic1:
dic1[ii] = 1 # 通过字典的键值对存储元素(统计重合字母的个数)
else:
dic1[ii] += 1
s1 = sorted(dic1.items(), key=lambda x: x[0]) # 按ASCII的升序,排序字母(键)
s2 = sorted(s1, key=lambda x: x[1], reverse=True) # 按ASCII的升序,排序数字(值)
print(''.join(str(ii[0]) for ii in s2)) # 提取列表的字母(键)
except:
break
(3)知识点详解
1、input():获取控制台(任意形式)的输入。输出均为字符串类型。
str1 = input()
print(str1)
print('提示语句:', str1)
print(type(str1))
'''
asd123!#
提示语句: asd123!#
'''
| 常用的强转类型 | 说明 |
|---|---|
int(input()) |
强转为整型(输入必须时整型) |
list(input()) |
强转为列表(输入可以是任意类型) |
1.1、input() 与 list(input()) 的区别、及其相互转换方法
- 相同点:两个方法都可以进行for循环迭代提取字符,提取后都为字符串类型。
- 不同点:
str = list(input())将输入字符串转换为list类型,可以进行相关操作。如:str.append()
- 将列表转换为字符串:
str_list = ['A', 'aA', 2.0, '', 1]
- 方法一:
print(''.join(str))- 方法二:
print(''.join(map(str, str_list)))备注:若list中包含数字,则不能直接转化成字符串,否则系统报错。
- 方法一:
print(''.join([str(ii) for ii in str_list]))- 方法二:
print(''.join(map(str, str_list)))
map():根据给定函数对指定序列进行映射。即把传入函数依次作用到序列的每一个元素,并返回新的序列。
(1) 举例说明:若list中包含数字,则不能直接转化成字符串,否则系统报错。
str = ['25', 'd', 19, 10]
print(' '.join(str))
'''
Traceback (most recent call last):
File "C:/Users/Administrator/Desktop/test.py", line 188, in
print(' '.join(str))
TypeError: sequence item 3: expected str instance, int found
'''
(2)举例说明:若list中包含数字,将list中的所有元素转换为字符串。
str_list = ['A', 'aA', 2.0, '', 1]
print(''.join(str(ii) for ii in str_list))
print(''.join([str(ii) for ii in str_list]))
print(''.join(map(str, str_list))) # map():根据给定函数对指定序列进行映射。即把传入函数依次作用到序列的每一个元素,并返回新的序列。
'''
AaA2.01
AaA2.01
AaA2.01
'''
2、print() :打印输出。
【Python】print()函数的用法
x, y = 1, 9
print('{},{}' .format(x, y)) # 打印方法一
print('*'*10) # 打印分割符
print(x, ',', y) # 打印方法二
'''
1,9
**********
1 , 9
'''
3、dict字典的常用操作(14+4函数)—— 字典是一个无序可变序列。
(2)键必须是唯一的(不可变数据类型),但值可以取任意数据类型。
(3)不支持索引、切片、重复和连接操作。
- 不可变数据类型:
布尔类型(bool)、整型(int)、字符串(str)、元组(tuple)- 可变数据类型:
列表(list)、集合(set)、字典(dict)
| 序号 | 函数 | 说明 |
|---|---|---|
| 0 | dict1 = {} |
创建空字典 |
| 0 | dict1 = dict() |
创建空字典 |
| 1 | dict2 = {key1: value1, key2: value2} |
创建字典 |
| 1 | dict2 = dict({key: value, key2: value2}) |
创建字典 |
| —— | —— | —— |
| 2 | dict.keys() |
查看字典中所有的key值 |
| 3 | dict.values() |
查看字典中所有的value值 |
| 4 | dict.items() |
查看字典中所有的key-value值 |
| 5 | dict(key) |
获取指定key对应的value值。若key值不存在,程序会报错。 |
| 6 | dict.get(key, default=None) |
获取指定key对应的value值。若key不存在,返回设置的default。 |
| 7 | dict.copy() |
浅拷贝 |
| —— | —— | —— |
| 8 | dict(key) = value |
若key存在,更新value值。若不存在,新增key-value值。 |
| 9 | dict1.update(dict2) |
添加元素(可同时添加多对)。若key存在,则更新value值。 |
| 10 | dict.setdefault(key, default=None) |
若key存在,既不新增也不更新value值。若key不存在,将会添加键,并将value值设为default。 |
| —— | —— | —— |
| 11 | dict.pop(key) |
弹出指定的key-value值 |
| 12 | dict.popitem() |
删除最后一个key-value |
| 13 | dict.clear() |
清空字典内容,返回空字典 |
| 14 | del dict[key] |
删除指定的key-value值。 |
| —— | —— | —— |
| (1) | len(dict) |
列表元素个数 |
| (2) | type(dict) |
查看数据类型 |
| (3) | 'key1' in dict or 'key1' in dict.keys |
判断给定值是否在字典的key中(默认:dict.keys()) |
| (4) | 'value1' in dict.values() |
判断给定值是否在字典的value中 |
| (5) | 'dict.has_key('name') |
判断字典中是否有指定的key元素 |
| (5) | for i in dict: |
遍历字典的key值(默认:dict.keys()) |
4、匿名函数 - lambda:对输入参数进行表达式计算
函数说明1:
函数名 = lambda argument_list: expression
函数说明2:函数名 = lambda 参数: 表达式(更容易理解,固定语法)
输入参数:
lambda:Python关键字argument_list:(输入)参数列表,即输入可以是多个参数。expression:变量表达式。只能是单行,而def可以有多个。返回值:变量表达式的计算结果即为lambda函数的返回值。特点1:匿名函数,即没有名字的函数。Python中的lambda
特点2:功能简单:只能单行expression决定了lambda函数不可能完成复杂的逻辑,甚至不需要专门的名字来说明。
❤️ 常用实例
a0 = lambda x: 1 if x > 10 else 0 # 判断输入参数的大小,大于取1,小于取0
a1 = lambda x, y: x*y # 函数输入是x和y,输出是它们的积x*y
a2 = lambda : None # 函数没有输入参数,输出是None
a3 = lambda *args: sum(args) # 输入是任意个数的参数,输出是它们的和(隐性要求是输入参数必须能够进行加法运算)
a4 = lambda **kwargs: 1 # 输入是任意键值对参数,输出是1
print(a0(2))
print(a1(2, 3))
print(a2())
print(a3(2, 3, 4))
print(a4())
"""
0
6
None
9
1
"""
❤️ 四个用法
(1)将lambda函数赋值给一个变量,通过这个变量间接调用该lambda函数。
- 如:
add0 = lambda x, y: x+y,返回两个变量的和。与add(1,2)==3等效。
(2)将lambda函数赋值给其他函数,从而将其他函数用该lambda函数替换。
- 如:
time.sleep = lambda x: None。返回None,即调用标准库time中的sleep函数不执行。
(3)将lambda函数作为其他函数的返回值,返回给调用者。
- 如:
return lambda x, y: x+y,返回一个加法函数。此时lambda函数实际上是定义在某个函数内部的函数,称为嵌套函数或内部函数。
(4)将lambda函数作为参数传递给其他函数。如:sorted()、filter()、map()、reduce()。
11、sorted():此时lambda函数用于对列表中所有元素进行排序。
- 如:
sorted([1, 2, 3, 4, 5], key=lambda x: abs(3-x))。
将列表[1, 2, 3, 4, 5]中元素与3的距离,从小到大进行排序,其结果是列表:[3, 2, 4, 1, 5]。22、filter():此时lambda函数用于过滤列表元素。
- 如:
list(filter(lambda x: x%3==0, [1, 2, 3]))。
将列表[1,2,3]中能够被3整除的元素过滤出来,其结果是列表:[3]。33、map():此时lambda函数用于对列表中每一个元素的共同操作。
- 如:
list(map(lambda x: x+1, [1, 2, 3]))。
将列表[1, 2, 3]中的元素分别加1,其结果是列表:[2, 3, 4]。44、reduce():此时lambda函数用于列表中两两相邻元素的结合。
from functools import reducereduce(lambda a, b: a+b, [1, 2, 3, 4])。
将列表[1, 2, 3, 4]中的元素,从左往右取出2个元素并执行指定函数,然后将输出结果与第3个元素传入指定函数,…,循环到最后一个元素。其结果是整型:10。
备注:reduce函数原本在python2中也是个内置函数,不过在python3中被移到functools模块中。
5、sorted() :对所有可迭代类型进行排序,不改变原始序列。按照ASCII的大小进行排序(数字 >> 大写字母 >> 小写字母)。
函数说明:
sorted(iterable, key=None, reverse=False)
输入参数:
iterable:可迭代的对象(如:字典、列表)。key:可迭代类型中某个属性,对指定函数进行排序。默认=Nonereverse:默认升序(reverse=False)、降序(reverse=Ture)。备注:字符串按照ASCII的大小进行排序。默认先排序数字(0 ~ 9),再排序大写字母(A ~ Z),后排序小写字母(a ~ z)。
lst1 = (5, 4, 3, -2, 1)
L1 = sorted(lst1)
L2 = sorted(lst1, key=abs)
L3 = sorted(lst1, reverse=True)
print(L1) # 【输出结果】[-2, 1, 3, 4, 5]
print(L2) # 【输出结果】[1, -2, 3, 4, 5]
print(L3) # 【输出结果】[5, 4, 3, 1, -2]
###################################################################################
lst2 = ('F', 'D', 'Y', 'e', 'a', 'v', '9', '6')
L4 = sorted(lst2)
L5 = sorted(lst2, key=str.lower) # 对指定函数进行排序(将所有字母转换为小写,然后排序。不改变原字符串。)
print(L4) # 【输出结果】['6', '9', 'D', 'F', 'Y', 'a', 'e', 'v']
print(L5) # 【输出结果】['6', '9', 'e', 'F', 'v', 'Y']
6、字符串str() :将参数转换成字符串类型(强转)—— 字符串是有序不可变序列。
函数说明:
str(x, base=10)
一般来说,有序序列类型都支持索引,切片,相加,相乘,成员操作。
print('返回空字符串:', str())
print('整数转换为字符串:', str(-23))
print('浮点数转换为字符串:', str(1.3e2))
print('列表转换为字符串:', str([12, '-23.1', 'Python']))
print('元组转换为字符串:', str((23, '9we', -8.5)))
print('字典转换为字符串:', str({'Huawei': 'China', 'Apple': 'USA'}))
print('集合转换为字符串:', str({'China', 'Japan', 'UK'}))
'''
返回空字符串:
整数转换为字符串: -23
浮点数转换为字符串: 130.0
列表转换为字符串: [12, '-23.1', 'Python']
元组转换为字符串: (23, '9we', -8.5)
字典转换为字符串: {'Huawei': 'China', 'Apple': 'USA'}
集合转换为字符串: {'China', 'UK', 'Japan'}
'''
7、str.join():将序列(字符串、元组、列表、字典)中的元素以指定字符连接,并返回一个新的字符串。
函数说明:
'Separator'.join(Sequence)
功能说明:以Separator为分隔符,对Sequence所有元素进行逐个分割,并返回一个新的字符串。
输入参数:
Separator:代表分隔符。 可以是单个字符(如:''、','、'.'、'-'、'*'等),也可以是字符串(如:'abc')。Sequence:代表要连接的元素序列。可以是字符串、元组、列表、字典。
备注1:Separator和Sequence都只能是string型,不能是int型和float型,否则系统报错。
备注2:字典的读取是随机的。
a1 = 'I Love China !'
print('字符串: ', ' '.join(a1))
a11 = 'I Love China !'
print('字符串: ', ''.join(a11))
a2 = ['I', 'Love', 'China', '!']
print('列表: ', ' '.join(a2))
a3 = ('I', 'Love', 'China', '!')
print('元祖: ', ' '.join(a3))
a4 = {'I': 1, 'Love': 2, 'China': 3, '!': 4}
print('字典: ', ' '.join(a4))
'''
字符串: I L o v e C h i n a !
字符串: I Love China !
列表: I Love China !
元祖: I Love China !
字典: I Love China !
'''
import os # 导入路径模块
os.getcwd() # 获取当前路径
data_save = os.path.join(os.getcwd(), 'data_save') # 获取当前路径并组合新的路径
print(data_save)