redis高可用
文章目录
-
- redis高可用概述
- 哨兵模式
-
- 原理
- 配置
- 流程
- 使用
- 缺点
- cluster集群
-
- 原理
- 特征
- 流程
- 缺点
- 故障转移
-
- 故障检测
- 故障转移
- 集群配置和管理
-
- 主要命令
- 搭建集群
- 创建集群
- 查看集群配置信息
- 测试集群
- 主从切换
- 扩容
- 缩容
redis高可用概述
1、高可用是分布式的概念。 Redis的高可用性是指在Redis集群中,当主节点宕机了,通过切换备用节点顶替它继续运行,保持系统正常运行且数据可靠性不受影响。
2、通过实现Redis的高可用性,可以提供以下几个主要优势:
1)避免单点故障:通过配置和设置多个Redis节点,如果其中一个节点发生故障,其他节点可以接替工作,避免了单点故障对整个系统的影响。
2)数据冗余和复制:通过数据的复制和持久化备份,Redis能够在主节点出现故障时,自动切换到备用节点,并恢复数据,确保数据的持久性和可用性。
3)故障自动检测和故障转移:Redis的高可用方案通常具备故障检测和自动故障转移的功能,能够监控节点的健康状态,并在节点故障时自动将从节点升级为主节点。
3、因此,redis的高可用主要完成以下工作:
1)数据同步。主节点和从节点(备用节点)之间的数据需要进行同步。
2)主从切换。若主节点宕机,需要有一种机制可以切换从节点变成主节点。
哨兵模式
原理
哨兵模式是 Redis 可用性的解决方案,它由一个或多个 sentinel实例构成 sentinel 系统。该系统通过 ping-pong心跳检测的方法监视任意多个主库以及这些主库所属的从库。当主库处于下线状态,自动将该主库所属的某个从库升级为新的主库,从而实现高可用。
客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 sentinel 索要主库地址,sentinel会将最新的主库地址告诉客户端。通过这样客户端无须重启即可自动完成节点切换。
Sentinel 节点个数是奇数,不存储数据,用来监控节点的状态和选举主节点,只提供一个数据节点服务。Sentinel 节点不仅监控 Redis 主从节点,同时还互相监控,形成多哨兵模式。
Sentinel 模式当中涉及的多个选举流程采用的是 raft 一致性算法。
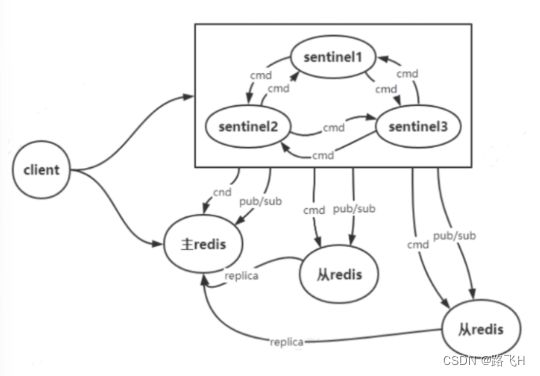
说明:
哨兵作用:
-
监控数据节点的状态,自身不存储具体业务的数据,只存储redis节点的状态信息。
-
选主节点,通常部署奇数个哨兵节点,主要是为了选主。
-
只提供一个数据节点服务。
根据什么来选举?
- 数据最新的选举为主库。 如何判断最新? 根据数据偏移量,偏移量从0加到64位最大值。
为什么需要奇数个哨兵节点呢?
- 因为要半数以上认为某个节点可以为主节点才会选取该节点为主节点。如果是偶数个,那就可能平票。
配置
# sentinel.cnf
# sentinel 只需指定检测主节点就行了,通过主节点自动发现从节点
sentinel monitor mymaster 127.0.0.1 6379 2
# 判断主观下线时长
sentinel down-after-milliseconds mymaster 30000
# 指定可以有多少个Redis服务同步新的主机,一般而言,
# 这个数字越小同步时间越长,而越大,则对网络资源要求越高
sentinel parallel-syncs mymaster 1
# 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟
sentinel failover-timeout mymaster 180000
流程
1)主观下线 sentinel 会以每秒一次的频率向所有节点(其他sentinel、主节点、以及从节点)发送 ping 消息,然后通过接收返回判断该节点是否下线。如果在配置指定 down-after-milliseconds 时间内则被判断为主观下线。
2)客观下线 当一个 sentinel 节点将一个主节点判断为主观下线之后,为了确认这个主节点是否真的下线,它会向其他 sentinel 节点进行询问,如果收到一定数量(半数以上)的已下线回复,sentinel 会将主节点判定为客观下线,并通过领头 sentinel 节点对主节点执行故障转移。
3)故障转移 主节点被判定为客观下线后,开始领头 sentinel 选举。按照谁发现谁处理的原则选举领头 sentinel,需要半数以上的 sentinel 支持。选举领头 sentinel 后,开始执行对主节点故障转移:
-
从从节点中选举一个从节点作为新的主节点
-
通知其他从节点复制连接新的主节点
-
若故障主节点重新连接,将作为新的主节点的从节点
使用
**1)**连接哨兵节点 —— 连接一个哨兵节点,并且获取主节点信息:SENTINEL GET-MASTER-ADDR-BY-NAME 。
**2)**获取主节点地址并连接 —— 验证当前获取的主节点:ROLE 或者 INFO REPLICATION。
**3)**发起发布订阅连接,监听主节点迁移信息 —— 为当前连接的哨兵节点,添加发布订阅(PUB/SUB)连接,并且订阅 +switch-master 频道,以此互相感知,互相连接,组成哨兵集群。
缺点
redis 采用异步复制的方式,意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息将丢失。如果主从延迟特别大,那么丢失可能会特别多。sentinel 无法保证消息完全不丢失,但是可以通过配置来尽量保证少丢失。
# 主库必须有一个从节点在进行正常复制,否则主库就停止对外
# 写服务,此时丧失了可用性
min-slaves-to-write 1
# 这个参数用来定义什么是正常复制,该参数表示如果在10s内
# 没有收到从库反馈,就意味着从库同步不正常;
min-slaves-max-lag 10
总结来说:
1)部署麻烦:哨兵模式的配置相对复杂,需要管理和维护多个哨兵节点以及与它们关联的 Redis 服务器。调试和故障排除也可能变得更加困难。
2)数据一致性:哨兵模式下的故障转移是异步进行的,这意味着在发生主服务器故障时,可能会有一段时间内的数据丢失。因此,在一些对数据一致性要求非常高的场景下,哨兵模式可能无法满足需求。
3)难以在线扩容的缺点,Redis的容量受限于单机配置
4)延迟增加:当主服务器故障时,哨兵节点需要通过选举机制选择新的主服务器,并通知其他从服务器切换到新的主服务器。这个过程需要时间(至少十几秒),会导致系统的延迟增加。
5)单点故障:哨兵节点是集群的核心,,它们负责监控主服务器和从服务器的状态,并执行故障转移操作。然而,如果哨兵节点本身发生故障,整个系统的可用性将会受到影响。
cluster集群
原理
Redis cluster 将所有数据划分为 16384( 2^14)个槽位,每个 redis 节点负责其中一部分槽位。cluster 集群是一种去中心化的集群方式;

如图,该集群由三个 redis 节点组成,每个节点负责整个集群的 一部分数据,每个节点负责的数据多少可能不一样。这三个节点相互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议交互集群信息;

当 redis cluster 的客户端来连接集群时,会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到目标节点。
客户端为了可以直接定位(对 key 通过 crc16 进行 hash 再对2^14取余)某个具体的 key 所在节点,需要缓存槽位相关信息, 这样才可以准确快速地定位到相应的节点。同时因为可能会存在客户端与服务器存储槽位的信息不一致的情况,还需要纠正机制(通过返回 -MOVED 3999 127.0.0.1:6479,客户端收到 后需要立即纠正本地的槽位映射表)来实现槽位信息的校验调整。
说明:
为什么要对2^14取余?
-
增大样本数,让数据均衡的落在节点当中;
-
固定算法,增加节点和删除节点不会让原来的映射关系失效。
另外,redis cluster 的每个节点会将集群的配置信息持久化到配置文件中,这就要求确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
特征
1)去中心化,主节点关系对等
2)解决了数据扩容
3)客户端与服务端缓存槽位信息,以服务端为准,客户节点缓存主要为了避免连接切换
4)可人为迁移数据
5)主节点处理读写命令
流程
1)连接集群中任意一个节点
2)若数据不在该节点,将收到连接切换的命令,继而连接到目标节点
3)故障转移(主节点下移)
- 集群结点间互相监控,交换节点的状态信息
- 若某主节点下线,将会被其他主节点标记下线
- 接着从下线主节点的从节点中选择一个数据最新的从节点作为主节点
- 从节点继承下线主节点的槽位信息,并广播该消息给集群中的其他节点
缺点
主从异步复制在故障转移时仍存在数据丢失的问题。
故障转移
cluster 集群中节点分为主节点和从节点,其中主节点用于处理槽,而从节点则用于复制该主节点,并在主节点下线时,代替主节点继续处理命令请求。
故障检测
集群中每个节点都会定期地向集群中的其他节点发送 ping 消息,如果接收 ping 消息的节点没有在规定时间内回复 pong消息,那么这个没有回复 pong消息的节点会被标记为 PFAIL(probable fail)。
集群中各个节点会通过互相发送消息的方式来交换集群中各个节点的状态信息;如果在一个集群中,半数以上负责处理槽的主节点都将某个主节点 A 报告为疑似下线,那么这个主节点 A将被标记为下线( FAIL );标记主节点 A 为下线状态的主节点会广播这条消息,其他节点(包括A节点的从节点)也会将A节点标识为FAIL;
故障转移
当从节点发现自己的主节点进入 FAIL 状态,从节点将开始对下线主节点进行故障转移:
- 从数据最新的从节点中选举为主节点;
- 该从节点会执行 replica no one 命令,称为新的主节点;
- 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己;
- 新的主节点向集群广播一条
pong消息,这条pong消息可以让集群中的其他节点立即知道这个节点已经由从节点变成主节点,并且这个主节点已经接管了之前下线的主节点; - 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移结束
集群配置和管理
主要命令
redis-cli --cluster help
# 创建集群
create <ip>:<port>
--cluster-replicas <num> # 创建集群的同时,为每个主节点配备的从节点个数
# 查看集群的信息,群中任意节点地址作为参数,后面同理
info <ip>:<port>
# 检查集群的配置
check <ip>:<port>
# 重分片,将指定数量的槽从源节点迁移至目标节点,由目标节点负责迁移的槽和
# 槽中数据
reshared <ip>:<port>
--cluster-from # 源节点的ID
--cluster-to # 目标节点的ID
--cluster-slots <num> # 需要迁移的槽数量
# 添加节点,添加新节点 new 集群 existing,默认添加主节点
add-node <new_host>:<port> <existing_host>:<port>
# 添加从节点,需要以下两个子命令
--cluster-slave
--cluster-master-id <id> # 设置从节点要复制的主节点
# 移除节点
del-node <ip>:<port> <id>
搭建集群
设置启动配置文件
# 创建文件夹
mkdir -p 7001 7002 7003 7004 7005 7006
cd 7001
vi 7001.conf
# 输入内容
pidfile "/home/jtz/redis-data/7001/7001.pid"
logfile "/home/jtz/redis-data/7001/7001.log"
dir /home/mark/redis-data/7001/
port 7001
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
# 复制配置
cp 7001/7001.conf 7002/7002.conf
cp 7001/7001.conf 7003/7003.conf
cp 7001/7001.conf 7004/7004.conf
cp 7001/7001.conf 7005/7005.conf
cp 7001/7001.conf 7006/7006.conf
# 修改配置
sed -i 's/7001/7002/g' 7002/7002.conf
sed -i 's/7001/7003/g' 7003/7003.conf
sed -i 's/7001/7004/g' 7004/7004.conf
sed -i 's/7001/7005/g' 7005/7005.conf
sed -i 's/7001/7006/g' 7006/7006.conf
# 创建启动脚本
vi start.sh
# 输入内容
#!/bin/bash
redis-server 7001/7001.conf
redis-server 7002/7002.conf
redis-server 7003/7003.conf
redis-server 7004/7004.conf
redis-server 7005/7005.conf
redis-server 7006/7006.conf
# 创建停止脚本
vi stop.sh
redis-cli -p 7001 shutdown
redis-cli -p 7002 shutdown
redis-cli -p 7003 shutdown
redis-cli -p 7004 shutdown
redis-cli -p 7005 shutdown
redis-cli -p 7006 shutdown
创建集群
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003
127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
说明:
需要先执行./start.sh启动6个redis服务器再执行创建集群的命令才能让6个服务器成为集群。
查看集群配置信息
搭建成功,查看集群配置信息
redis-cli --cluster check 127.0.0.1:7001
# 集群配置信息
M: 6d67700c3a40ea80488a48c232f9459e664bf899 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 9a66a88e4b4da0edeb2767d55dbd4623f0f2ec52 127.0.0.1:7004
slots: (0 slots) slave
replicates 8b8339a497d07237b1fce6abef45d251132fc594
S: 3171812cc5b5e956c142321d6d31e68fa8708872 127.0.0.1:7006
slots: (0 slots) slave
replicates e4da2884848793a8deb973fe623097d5089a8031
S: be0058062baca91b2a27f884c6cebd59f24f0cd2 127.0.0.1:7005
slots: (0 slots) slave
replicates 6d67700c3a40ea80488a48c232f9459e664bf899
M: 8b8339a497d07237b1fce6abef45d251132fc594 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: e4da2884848793a8deb973fe623097d5089a8031 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
测试集群
redis-cli -c -p 7001
127.0.0.1:7001> set name mark
-> Redirected to slot [5798] located at 127.0.0.1:7002 # 分配到其他主
# 节点存储
OK
redis-cli -c -p 7003
127.0.0.1:7003> get name
-> Redirected to slot [5798] located at 127.0.0.1:7002 # 重定向到存储
# 该key的节点
"mark"
127.0.0.1:7002>
主从切换
# 主节点宕机,发生主从切换
redis-cli -p 7003 shutdown
# 主节点重启
redis-server 7003/7003.conf
# 配置信息变化
# 初始状态
M: 8b8339a497d07237b1fce6abef45d251132fc594 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
# 主从切换后,从节点7004替换宕机的主节点7003
M: 9a66a88e4b4da0edeb2767d55dbd4623f0f2ec52 127.0.0.1:7004
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
replicates 6d67700c3a40ea80488a48c232f9459e664bf899
# 节点7003上线后,成为其他节点的从节点
S: 8b8339a497d07237b1fce6abef45d251132fc594 127.0.0.1:7003
slots: (0 slots) slave
扩容
先添加节点,再分配槽位
# 1、先添加节点
# 添加主节点,新添加的节点默认作为主节点
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
# 添加从节点
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001
--cluster-slave --cluster-master-id 5043e35b99e3c3e45241dd7b748502
aa8daf544c
# 2、再分配槽
# 重分片,将主节点 7001 的 1000 个槽迁移至新的主节点 7007
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from
6d67700c3a40ea80488a48c232f9459e664bf899 --cluster-to
5043e35b99e3c3e45241dd7b748502aa8daf544c --cluster-slots 1000
# 对比迁移前后的集群配置
# 迁移前
M: 6d67700c3a40ea80488a48c232f9459e664bf899 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
2 additional replica(s)
M: 5043e35b99e3c3e45241dd7b748502aa8daf544c 127.0.0.1:7007
slots: (0 slots) master
# 迁移后
M: 6d67700c3a40ea80488a48c232f9459e664bf899 127.0.0.1:7001
slots:[1000-5460] (4461 slots) master
1 additional replica(s)
M: 5043e35b99e3c3e45241dd7b748502aa8daf544c 127.0.0.1:7007
slots:[0-999] (1000 slots) master
1 additional replica(s)
缩容
先移动槽位,再删除节点
# 1、先移动槽位
# 将主节点 7007 的所有槽迁移至主节点 7001
redis-cli --cluster reshard 127.0.0.1:7007 --cluster-from
5043e35b99e3c3e45241dd7b748502aa8daf544c --cluster-to
6d67700c3a40ea80488a48c232f9459e664bf899 --cluster-slots 1000
# 迁移后的集群配置
M: 6d67700c3a40ea80488a48c232f9459e664bf899 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
2 additional replica(s)
M: 5043e35b99e3c3e45241dd7b748502aa8daf544c 127.0.0.1:7007
slots: (0 slots) master
# 2、删除节点
# 删除节点 7007
redis-cli --cluster del-node 127.0.0.1:7007
5043e35b99e3c3e45241dd7b748502aa8daf544c
# 此时7008成为其他节点的从节点
M: 6d67700c3a40ea80488a48c232f9459e664bf899 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
2 additional replica(s)
S: 1d5f5827cdb9f294de702f4247d1471fce9545df 127.0.0.1:7008
slots: (0 slots) slave
replicates 6d67700c3a40ea80488a48c232f9459e664bf89
# 删除从节点7008
redis-cli --cluster del-node 127.0.0.1:7008
1d5f5827cdb9f294de702f4247d1471fce9545df