MySQL---表的增查改删(CRUD进阶)
文章目录
- 数据库约束
- 表的设计
-
- 一对一
- 一对多
- 多对多
- 新增
- 查询
-
- 聚合查询
- 分组查询
- 联合查询
-
-
- 内连接
- 外连接
- 自连接
- 子查询
- 合并查询
-
数据库约束
数据库约束就是指:程序员定义一些规则对数据库中的数据进行限制。这样数据库会在新增和修改数据的时候按照这些限制,对数据进行校验。如果校验不通过,则直接报错。
数据库的约束类型有很多,以下我们将一一介绍:
- not null:表示被指定的某列不能为NULL,必须填信息。
//在不加 not null约束时,可以插入空值
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> insert into student values(NULL, NULL);
Query OK, 1 row affected (0.00 sec)
// 重新定义表结构 给 id 字段加上 not null约束
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int not null, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
//有 not null 约束后不能插入空值
mysql> insert into student values (NULL, NULL);
ERROR 1048 (23000): Column 'id' cannot be null
- unique:表示被指定的列该字段的值必须唯一
//创建学生表 使id有unique约束
mysql> create table student (id int unique, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | UNI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
// 不能插入相同值
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(1, '张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'id'
- default:表示未给该字段赋值时,数据库赋予该字段的默认值
//对 id 和 name 分别设置默认值 0 和 未命名
mysql> create table student (id int default 0, name varchar(20) default '未命名');
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+-----------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+-----------+-------+
| id | int(11) | YES | | 0 | |
| name | varchar(20) | YES | | 未命名 | |
+-------+-------------+------+-----+-----------+-------+
2 rows in set (0.00 sec)
// 演示 name 默认值为 未命名
mysql> insert into student (id) values (1);
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+------+-----------+
| id | name |
+------+-----------+
| 1 | 未命名 |
+------+-----------+
1 row in set (0.00 sec)
//演示 id 默认值为 0
mysql> insert into student (name) values ('张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+------+-----------+
| id | name |
+------+-----------+
| 1 | 未命名 |
| 0 | 张三 |
+------+-----------+
2 rows in set (0.00 sec)
注:MySQL给的默认值是 NULL
- primary key:表示主键,即区分该行和其他行的唯一标识,方便定位每一条记录
//对 id 设置为主键
mysql> create table student (id int primary key,name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
//插入数据进行演示,可以看出
//一 主键不能为空
mysql> insert into student values(null, null);
ERROR 1048 (23000): Column 'id' cannot be null
//二 主键的值必须唯一 不能重复
mysql> insert into student values(1,'张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
mysql> insert into student values(1,'张三');
Query OK, 1 row affected (0.00 sec)
- 自增主键:因为主键的值必须要填还不能重复,MySQL就提供了一个功能来自动生成主键的值
//对 id 设置自增主键
mysql> create table student (id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
// 自增主键可以把主键写为空值 因为系统最后会自动赋值
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
+----+--------+
1 row in set (0.00 sec)
//如果给主键填空值,主键会按自增主键自动生成;如果给主键填指定值,主键就是指定值
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
+----+--------+
4 rows in set (0.00 sec)
//如果给主键填空值,主键会按自增主键自动生成;如果给主键填指定值,主键就是指定值
mysql> insert into student values (100,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+-----+--------+
| id | name |
+-----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
| 100 | 张三 |
+-----+--------+
5 rows in set (0.00 sec)
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+-----+--------+
| id | name |
+-----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
| 100 | 张三 |
| 101 | 张三 |
+-----+--------+
6 rows in set (0.00 sec)
注:
- MySQL在自增主键的时候,就必须先记录下目前主键值是多少了然后再+1,当我们手动指定一个主键值使它与记录下的、目前的主键值差距较大后,下次自增会在哪个数值上+1实现自增呢?MySQL里简单粗暴的做法是:选择主键里的最大值,然后在最大值的基础上自增。这样能保证绝对不会重复;
- 如果在多线程情况下,自增主键可能会不安全。于是又提出了一个自增主键的方法:唯一 id = 时间戳(ms) + 机房编号 + 主机编号 + 随机因子(这里的 + 表示字符串拼接),这样就保证了主键的唯一性。
- foreign key:表示外键,即连接该表和其他表的一个媒介,描述了两张表的关联关系
mysql> create table class (classId int primary key,className varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (studentId int primary key, name varchar(20), classId int, foreign key (classId) references class (classId));
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> desc student;
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| studentId | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| classId | int(11) | YES | MUL | NULL | |
+-----------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
注:
- 学生在班级里,即可以理解为学生被班级约束。被约束的表称为子表,约束别人的表称为父表;
- 把所有字段都定义完后,再写外键约束。注意外键约束的写法!
//父表为空时往子表里插入数据就会报错 因为对子表没有产生约束
mysql> insert into student values(1,'张三',1);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`java`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `class` (`classId`))
// 假设已经在父表里插入了三条数据 我们现在往子表里插入外键4
// 也会报错 因为子表超出了父表对它的约束
mysql> insert into student values(1,'张三',4);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`java`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `class` (`classId`))
注:
- 在外键的约束下,每次插入、删除数据的时候,都得对父表进行查询,这是一个低效的操作。为了解决这个问题,MySQL就要求:在建立外键约束时,外键必须是另一张表的主键或者unique,这样会建立索引让查询更高效。
- 父表对子表产生限制,相应的子表也会对父表产生限制。父表对子表的限制是子表不能随意的插入和修改;子表对父表的限制是不能随意的修改和删除。
- check:表示保证插入的值必须符合check条件
//插入的数据只能是 男或女
check (sex ='男' or sex='女')
注:MySQL使用时不报错,但是会忽略该约束。(该约束不起作用)
表的设计
一对一
以教务系统为例,学生表有学号姓名班级等属性,教务系统上的用户表有账号密码等属性,每一个学生有且仅有一个教务系统的账号,并且教务系统上的一个账号仅对应一个学生,像这种关系就是一对一的关系。
那么如何在数据库表示这种一对一的关系呢?
方案1:把学生表与用户表放在一个表中一一对应。
方案2:学生表中增加一列,存放学生在教务系统上的账号,在教务系统用户表增加一列,存放学生的学号。
一对多
还是以教务系统为例,如学生与班级之间的关系就是一个一对多的关系,一个学生原则上只能在一个班级中,一个班级容纳多名学生。
那么如何在数据库表示这种一对多的关系呢?
方案1:在班级表中增加一列,存放一个班里面所有学生的学号。但是MySQL不支持这种方案,因为SQL中没有类似于数组的类型。
方案2:在一个学生表中增加一列,存放学生所在的班级。
多对多
还是以教务系统为例,如学生与课程之间的关系就是一个典型的多对多的关系,一个学生可以学习多门课程,一门课程中有多名学生学习。
那么如何在数据库表示这种多对多的关系呢?
只有一种方案:建立一个关联表,来关联学生表和课程表,这个关联表中有两列,一列用来存放学生学号,另一列存放课程编号,这样两表可以通过这一个关联表来实现多对多的一个关系。
新增
//把查询结果作为新增的数据
insert into 表1 select 列名 from 表2;
//创建表1
mysql> create table student (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student values (1,'张三'),(2,'李四'),(3,'王五');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
//创建表2
mysql> create table student2 (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
//查看表1当前的信息
mysql> select * from student;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)
//明确表2现在为空
mysql> select * from student2;
Empty set (0.00 sec)
//将表1的数据全部插入表2
mysql> insert into student2 select * from student;
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from student2;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)
注:
- 先进行查询操作再进行插入操作。
- 要求表2查询结果的列数、类型 和 表1的列数、类型匹配 不要求列名匹配。
查询
聚合查询
聚合查询依赖于聚合函数,而聚合函数都是针对行与行之间进行计算的,在这里我们先认识一下相关的聚合函数,这些都是SQL的内置函数,即库函数;可以直接使用:
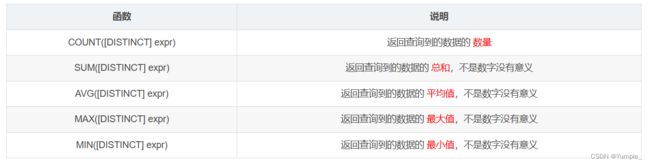
- 使用count函数:
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | zhangsan | 67.0 | 98.0 | 56.0 |
| 2 | lisi | 87.5 | 78.0 | 77.0 |
| 3 | wangwu | 88.0 | 98.5 | 90.0 |
| 4 | zhaoliu | 82.0 | 84.0 | 67.0 |
| 5 | sunqi | 55.5 | 85.0 | 45.0 |
| 6 | zhouba | 70.0 | 73.0 | 78.5 |
| 7 | wujiu | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
//count函数既可以使用count(*) 又可以使用count(列名)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
count(*) 和 count(列名) 的区别:
//插入一条空数据
mysql> insert into exam_result values(null, null, null, null, null);
Query OK, 1 row affected (0.00 sec)
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | zhangsan | 67.0 | 98.0 | 56.0 |
| 2 | lisi | 87.5 | 78.0 | 77.0 |
| 3 | wangwu | 88.0 | 98.5 | 90.0 |
| 4 | zhaoliu | 82.0 | 84.0 | 67.0 |
| 5 | sunqi | 55.5 | 85.0 | 45.0 |
| 6 | zhouba | 70.0 | 73.0 | 78.5 |
| 7 | wujiu | 75.0 | 65.0 | 30.0 |
| NULL | NULL | NULL | NULL | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)
mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
//我们看到 count(*) 和 count(列名) 的查询结果不同
注:count(*)会把NULL值也统计到总行数中;count(列名)不会把NULL值统计到总行数中
- 使用sum函数:
mysql> select sum(english) from exam_result;
+--------------+
| sum(english) |
+--------------+
| 443.5 |
+--------------+
1 row in set (0.00 sec)
//聚合函数也可以结合条件查询
mysql> select sum(english) from exam_result where english < 60;
+--------------+
| sum(english) |
+--------------+
| 131.0 |
+--------------+
1 row in set (0.00 sec)
- 使用avg函数:
mysql> select avg(math) from exam_result;
+-----------+
| avg(math) |
+-----------+
| 83.07143 |
+-----------+
1 row in set (0.00 sec)
- 使用max函数 和 使用min函数
mysql> select max(math) from exam_result;
+-----------+
| max(math) |
+-----------+
| 98.5 |
+-----------+
1 row in set (0.00 sec)
mysql> select min(math) from exam_result;
+-----------+
| min(math) |
+-----------+
| 65.0 |
+-----------+
1 row in set (0.00 sec)
注:
- 在聚合函数中进行计算时,NULL不会参与计算。
- 对于带有条件的聚合查询,先会按照条件进行筛选,再把筛选后得到的结果进行聚合。
分组查询
select 列名 from 表名 where 条件 group by 列名;
mysql> select * from student;
+------+--------+--------+-------+
| id | name | gender | score |
+------+--------+--------+-------+
| 1 | 张三 | 男 | 95 |
| 2 | 李四 | 女 | 75 |
| 3 | 王五 | 男 | 85 |
| 4 | 赵六 | 女 | 65 |
+------+--------+--------+-------+
4 rows in set (0.00 sec)
mysql> select gender, max(score), min(score), avg(score) from student group by gender;
+--------+------------+------------+------------+
| gender | max(score) | min(score) | avg(score) |
+--------+------------+------------+------------+
| 女 | 75 | 65 | 70.0000 |
| 男 | 95 | 85 | 90.0000 |
+--------+------------+------------+------------+
2 rows in set (0.00 sec)
注:
- 分组查询是指:指定某一列作为分组的依据,把列名相同的分为一组,即把表中的若干行分为好几组;
- 分组规则就是:把某些具有相同字段值的行作为一组。
//复杂的查询情况下,对查询的顺序进行理解。
mysql> select gender, avg(score) from student where name != '赵六' group by gender having avg(score) > 80;
+--------+------------+
| gender | avg(score) |
+--------+------------+
| 男 | 90.0000 |
+--------+------------+
1 row in set (0.00 sec)
注:
- 通常情况下,都会把select 后的第一个列名 与 group by 后面的列名保持一致。
- 这个SQL语句的执行顺序是:先对where条件进行筛选,再通过列值进行分组,再对分好的几组进行having条件的筛选,最后显示出要查找的列信息。
联合查询
联合查询也叫多表查询,是把多个表的记录合并在一起,进行综合查询。
联合查询的核心概念是:笛卡尔积。
笛卡尔积就是把俩个表中的所有记录,进行排列组合,穷举出所有可能的结果。
笛卡尔积后的列数就是几张表的列数之和,笛卡尔积后的行数就是几张表的行数之积
笛卡尔积中包含了大量的无效数据,当指定合理的筛选条件时,就可以把有效的数据挑选出来得到一个有用的数据表,这个筛选的过程就是”联合查询“的过程。
内连接
select 列名 from 表1,表2 where 条件 and 其他条件;
select 列名 from 表1 inner join 表2 on 条件 and 其他条件;
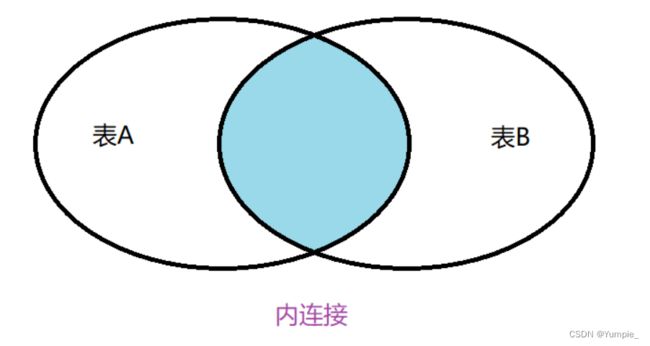
-- 创建部门表
CREATE TABLE department(
did int (4) NOT NULL PRIMARY KEY,
dname varchar(20)
);
-- 创建员工表
CREATE TABLE employee (
eid int (4) NOT NULL PRIMARY KEY,
ename varchar (20),
eage int (2),
departmentid int (4) NOT NULL
);
-- 向部门表插入数据
INSERT INTO department VALUES(1001,'财务部');
INSERT INTO department VALUES(1002,'技术部');
INSERT INTO department VALUES(1003,'行政部');
INSERT INTO department VALUES(1004,'生活部');
-- 向员工表插入数据
INSERT INTO employee VALUES(1,'张三',19,1003);
INSERT INTO employee VALUES(2,'李四',18,1002);
INSERT INTO employee VALUES(3,'王五',20,1001);
INSERT INTO employee VALUES(4,'赵六',20,1004);
//使用join on 查询
select ename,dname from department inner join employee on department.did=employee.departmentid;
//使用where查询
select ename,dname from department,employee where department.did = employee.departmentid;
外连接
外连接分为左外连接和右外连接及全外连接(SQL不支持)
select 列名 from 表1 left join 表2 on 条件; // 左外连接
select 列名 from 表2 right join 表2 on 条件; // 右外连接

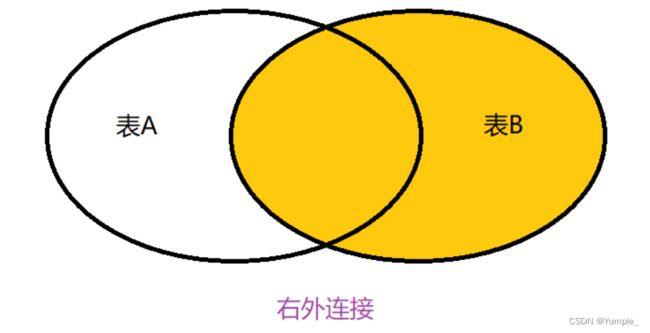
-- 创建班级表
CREATE TABLE class(
cid int (4) NOT NULL PRIMARY KEY,
cname varchar(20)
);
-- 创建学生表
CREATE TABLE student (
sid int (4) NOT NULL PRIMARY KEY,
sname varchar (20),
sage int (2),
classid int (4) NOT NULL
);
-- 向班级表插入数据
INSERT INTO class VALUES(1001,'Java');
INSERT INTO class VALUES(1002,'C++');
INSERT INTO class VALUES(1003,'Python');
INSERT INTO class VALUES(1004,'PHP');
-- 向学生表插入数据
INSERT INTO student VALUES(1,'张三',20,1001);
INSERT INTO student VALUES(2,'李四',21,1002);
INSERT INTO student VALUES(3,'王五',24,1002);
INSERT INTO student VALUES(4,'赵六',23,1003);
INSERT INTO student VALUES(5,'Jack',22,1009);
//左外连接
select cid,cname,sname from class left join student on class.cid=student.classid;
//右外连接
select cid,cname,sname from class right join student on class.cid=student.classid;
自连接
自连接:自己和自己连接,同一张表和自己进行笛卡尔积。
SQL里面指定条件查询都是按照列和列之间进行筛选,难以进行 行和行之间筛选,自连接操作能把按列筛选转化为按行筛选。
//查找哪个学生的3号课程分数高于1号课程
mysql> select s1.student_id from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;
子查询
子查询是指:在select语句中嵌套其他的SQL语句一起进行查询,也叫嵌套查询。
- 单行子查询:返回一行记录的子查询
mysql> select name from student where classes_id = (select classes_id from student where name = 'zhangsan');
注:此处的子查询可以任意级别的嵌套。
- 多行子查询:返回多行记录的子查询
//查询语文或英语课程的成绩信息
mysql> select * from score where course_id in (select id from course where name = '语文' or name = '英文');
合并查询
合并查询:把两个查询的结果集合,合并到一起。可以使用集合操作符 union 和 union all,注意两个结果集合查询的字段应该相同。
- union:该操作符用于取得两个结果集合的并集,会自动去除掉结果集合中的重复行。
//查询 id<3 或者 名字为英文的课程
mysql> select * from course where id < 3 or name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)
mysql> select * from course where id < 3 union select * from course where name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)
- union all:和union的唯一区别是如果有重复记录,union all 不会去重
最后总结一下SQL查询中各个关键字的执行先后顺序:from > on> join > where > group by > with > having >select > distinct > order by > limit