《零基础学Python》——极客时间——学习笔记
第二章 Python基础语法
Python程序的书写规则
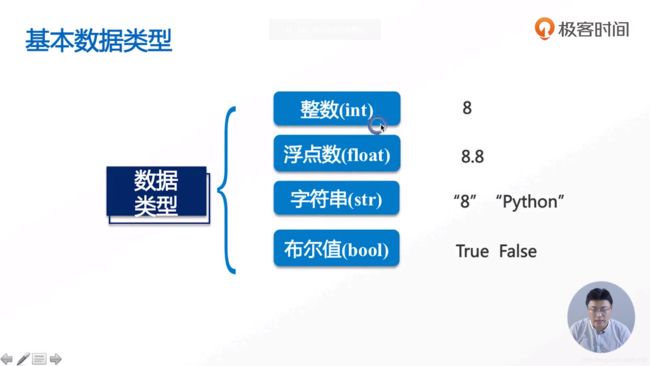
基础数据类型
类型判断
type()

强制类型转换
目标类型(要转换的数据)

变量的定义和常用操作




习题
题目:
练习一 变量的定义和使用
- 定义两个变量分别为美元和汇率
- 通过搜索引擎找到美元兑人民币汇率
- 使用Python计算100美元兑换的人民币数量并用print( )进行输出
代码:

第三章 序列
序列的概念
案例

概念

代码

字符串的定义和使用

字符串的常用操作
序列的基本操作

成员关系操作符

连接操作符

重复操作符

元组的定义和常用操作
元组中数字大小的比较
单个数字:

两个数字:
可当成是两个数字的叠加
![]()
120 < 220,故而结果为False。
列表和元组的区别
- 列表是中括号[],元组是小括号()
- 列表中的内容可变更,元组中的内容不可变更
fliter的功能
格式:
filter(lambda x: x < b, a)
取出a中小于b的元素
展示取出的元素
list(filter(lambda x: x < b, a))
例子:

统计取出元素的个数:
格式:
len (list (filter(lambda x: x < b, a)))
取出a中小于b的元素的个数
例子:

实现生肖查找功能
列表的定义和常用操作
基本操作:
- 增加一个元素
- 移除一个元素


习题
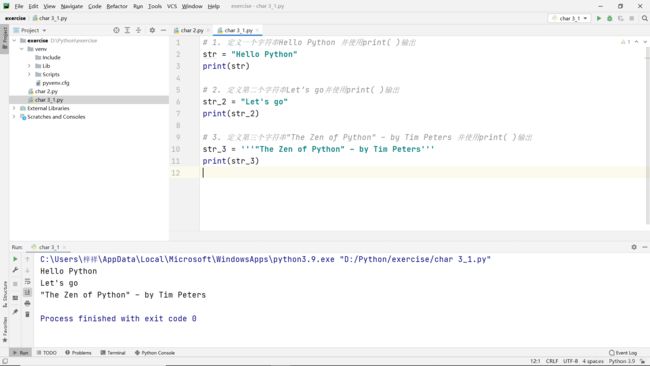
练习一 字符串
题目:
- 定义一个字符串Hello Python 并使用print( )输出
- 定义第二个字符串Let‘s go并使用print( )输出
- 定义第三个字符串"The Zen of Python" – by Tim Peters 并使用print( )输出
代码:
练习二 字符串基本操作
题目:
- 定义两个字符串分别为 xyz 、abc
- 对两个字符串进行连接
- 取出xyz字符串的第二个和第三个元素
- 对abc输出10次
- 判断a字符(串)在 xyz 和 abc 两个字符串中是否存在,并进行输出
代码:

练习三 列表的基本操作
- 定义一个含有5个数字的列表
- 为列表增加一个元素 100
- 使用remove()删除一个元素后观察列表的变化
- 使用切片操作分别取出列表的前三个元素,取出列表的最后一个元素
练习四 元组的基本操作
题目:
- 定义一个任意元组,对元组使用append() 查看错误信息
- 访问元组中的倒数第二个元素
- 定义一个新的元组,和 1. 的元组连接成一个新的元组
- 计算元组元素个数
代码:

第四章 条件与循环
条件语句
语法

代码


for循环

用途:
经常用for循环遍历序列
代码:

while循环

用法
通常和if条件判断语句连用
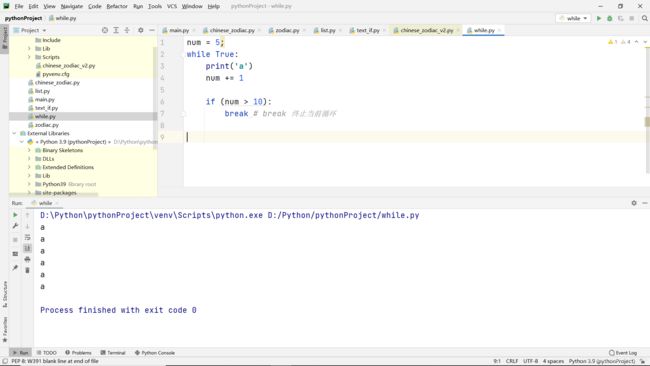
break语句
功能:
终止当前循环
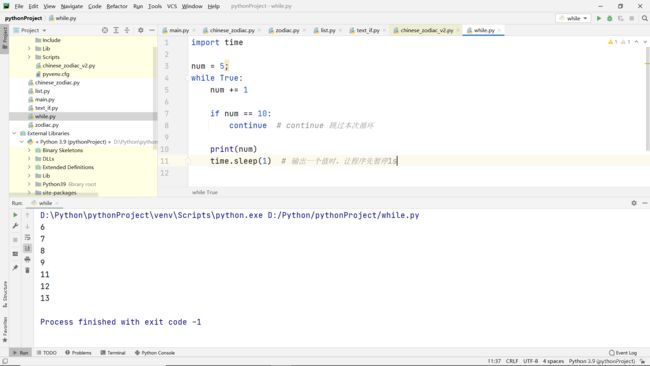
continue语句
功能:
跳过本次循环
总结
for语句中的if嵌套
用for循环实现的判断星座:
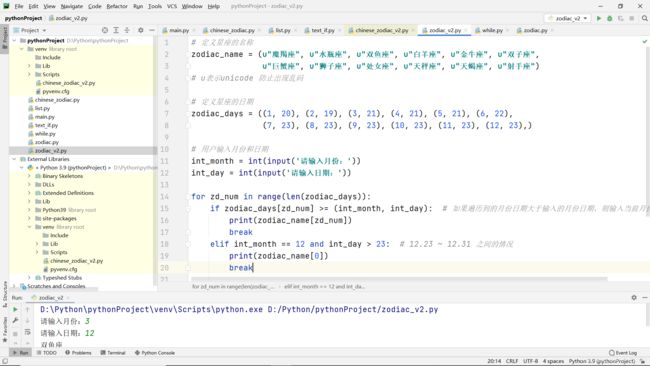
while循环语句中的if嵌套

习题
练习一 条件语句的使用
题目:
- 使用if语句判断字符串的长度是否等于10,根据判断结果进行不同的输出
- 提示用户输入一个1-40之间的数字,使用if语句根据输入数字的大小进行判断,如果输入的数字在 1-10,11-20,21-30,31-40,分别进行不同的输出
代码:

练习二 循环语句的使用
题目:
- 使用for语句输出1-100之间的所有偶数
- 使用while语句输出1-100之间能够被3整除的数字
代码:

第五章:映射与字典
字典的定义和常用操作

定义和添加元素

生肖与星座案例完善
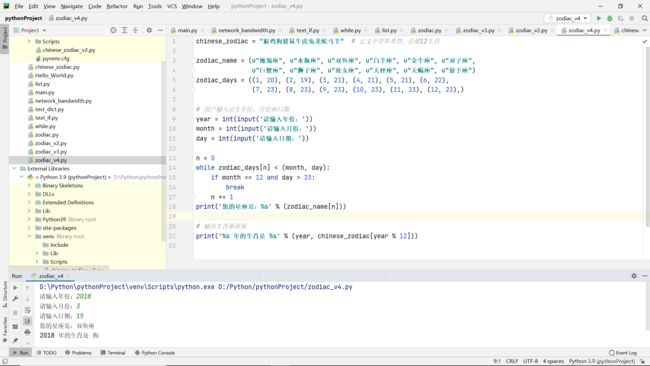
代码:
chinese_zodiac = "猴鸡狗猪鼠牛虎兔龙蛇马羊" # 定义字符串类型,存储12生肖
zodiac_name = (u"魔羯座", u"水瓶座", u"双鱼座", u"白羊座", u"金牛座", u"双子座",
u"巨蟹座", u"狮子座", u"处女座", u"天秤座", u"天蝎座", u"射手座")
zodiac_days = ((1, 20), (2, 19), (3, 21), (4, 21), (5, 21), (6, 22),
(7, 23), (8, 23), (9, 23), (10, 23), (11, 23), (12, 23),)
# 定义字典
cz_num = {
}
z_num = {
}
# 初始化关键字
for i in chinese_zodiac:
cz_num[i] = 0 # 将chinese_zodiac关键字依次赋值为0
for i in zodiac_name:
z_num[i] = 0 # 将zodiac_name关键字依次赋值为0
while True:
# 用户输入出生年份、月份和日期
year = int(input('请输入年份:'))
month = int(input('请输入月份:'))
day = int(input('请输入日期:'))
n = 0
while zodiac_days[n] < (month, day):
if month == 12 and day > 23:
break
n += 1
# 输出生肖和星座
print('您的星座是:%s' % (zodiac_name[n]))
print('%s 年的生肖是 %s' % (year, chinese_zodiac[year % 12]))
# 将值赋给初始化的字典
cz_num[chinese_zodiac[year % 12]] += 1 # 用户当前的生肖, 出现一次就加一,生肖的名字对应的值加一
z_num[zodiac_name[n]] += 1 # 用户当前的星座,出现一次就加一,星座的名字对应的值加一
# 输出生肖和星座的统计信息
for each_key in cz_num.keys(): # .keys() 取出字典中所有的key
print('生肖 %s 有 %d 个' % (each_key, cz_num[each_key]))
for each_key in z_num.keys():
print('星座 %s 有 %d 个' % (each_key, z_num[each_key]))
结果:
请输入年份:2018
请输入月份:1
请输入日期:3
您的星座是:魔羯座
2018 年的生肖是 狗
生肖 猴 有 0 个
生肖 鸡 有 0 个
生肖 狗 有 1 个
生肖 猪 有 0 个
生肖 鼠 有 0 个
生肖 牛 有 0 个
生肖 虎 有 0 个
生肖 兔 有 0 个
生肖 龙 有 0 个
生肖 蛇 有 0 个
生肖 马 有 0 个
生肖 羊 有 0 个
星座 魔羯座 有 1 个
星座 水瓶座 有 0 个
星座 双鱼座 有 0 个
星座 白羊座 有 0 个
星座 金牛座 有 0 个
星座 双子座 有 0 个
星座 巨蟹座 有 0 个
星座 狮子座 有 0 个
星座 处女座 有 0 个
星座 天秤座 有 0 个
星座 天蝎座 有 0 个
星座 射手座 有 0 个
请输入年份:2021
请输入月份:3
请输入日期:25
您的星座是:白羊座
2021 年的生肖是 牛
生肖 猴 有 0 个
生肖 鸡 有 0 个
生肖 狗 有 1 个
生肖 猪 有 0 个
生肖 鼠 有 0 个
生肖 牛 有 1 个
生肖 虎 有 0 个
生肖 兔 有 0 个
生肖 龙 有 0 个
生肖 蛇 有 0 个
生肖 马 有 0 个
生肖 羊 有 0 个
星座 魔羯座 有 1 个
星座 水瓶座 有 0 个
星座 双鱼座 有 0 个
星座 白羊座 有 1 个
星座 金牛座 有 0 个
星座 双子座 有 0 个
星座 巨蟹座 有 0 个
星座 狮子座 有 0 个
星座 处女座 有 0 个
星座 天秤座 有 0 个
星座 天蝎座 有 0 个
星座 射手座 有 0 个
请输入年份:
列表推导式与字典推导式

习题
练习一 字典的使用
题目:
- 定义一个字典,分别使用a、b、c、d作为字典的关键字,值为任意内容
- 为该字典增加一个元素‘c’:'cake’后,将字典输出到屏幕
- 取出字典中关键字为d的值
代码:

练习二 集合的使用
题目:
- 将字符串hello中每个字符赋值给一个集合,将这个集合输出到屏幕’
代码:

第六章 文件的输入输出

文件的内建函数


文件的常用操作
代码:
# # 将小说的主要人物记录在文件中
#
# # 写入文件 的 基本流程:open() -> write() -> close()
# file1 = open('name.txt', 'w') # 打开的文件名称为"name.txt",模式为"写入模式" 并将其赋值给一个变量
#
# file1.write(u'诸葛亮') # 写入人物
# file1.close() # 关闭并保存
#
# # 读取文件 的 基本流程:open() -> read() -> close()
# file2 = open('name.txt') # mode默认为“mode=r”——只读模式
# print(file2.read())
# file2.close()
#
# # 写入一个新人物
# file3 = open('name.txt', 'a')
# file3.write('刘备')
# file3.close()
# # 读取多行中的一行
# file4 = open('name.txt')
# print(file4.readline())
#
# # 读取每一行同时进行操作(以行的方式读取,逐行操作)
# file5 = open('name.txt')
# for line in file5.readlines(): # readlines 逐行读取
# print(line)
# print('=====')
# 进行一个操作,操作完成后回到文件的开头,然后再次对文件进行操作
file6 = open('name.txt')
file6.tell() # 告诉用户“文件指针”在哪
# 指针的功能:当没有进行人为操作时,程序会记录当前操作的位置,然后继续向后进行操作
print('当前文件指针的位置 %s' % file6.tell())
print('当前读取到了一个字符,字符的内容是 %s' % file6.read(1)) # 只读取文件的 1个字符
print('当前文件指针的位置 %s' % file6.tell())
# 需求:操作完成后,向回到文件的开头,再次进行操作
# 操纵指针
# 第一个参数:偏移位置(偏移量) 第二个参数:0——表示从文件开头偏移 1——表示从当前位置偏移 2——表示从文件结尾偏移
file6.seek(0) # file6.seek(5, 0) 从文件开头 向后偏移 5个位置
print('我们进行了seek操作')
print('当前文件指针的位置 %s' % file6.tell())
# 又一次读取一个字符
print('当前读取到了一个字符,字符的内容是 %s' % file6.read(1)) # 只读取文件的 1个字符
print('当前文件指针的位置 %s' % file6.tell())
file6.close()
结果:
当前文件指针的位置 0
当前读取到了一个字符,字符的内容是 a
当前文件指针的位置 1
我们进行了seek操作
当前文件指针的位置 0
当前读取到了一个字符,字符的内容是 a
当前文件指针的位置 1
练习一 文件的创建和使用
题目:
- 创建一个文件,并写入当前日期
- 再次打开这个文件,读取文件的前4个字符后退出
代码:
# 1. 创建一个文件,并写入当前日期
import datetime
now = datetime.datetime.now() # now变量 存储 现在的时间
new_file = open('date.txt', 'w')
new_file.write(str(now))
new_file.close()
# 2. 再次打开这个文件,读取文件的前4个字符后退出
again_file = open('date.txt')
print(again_file.read(4)) # 打印 读取的4个字符
print(again_file.tell()) # 文件指针,提示 读取了 4个字符
again_file.close()
结果:
2021
4
第七章 错误和异常
异常的检测和处理

常见错误
1. NameError


2. SyntaxError


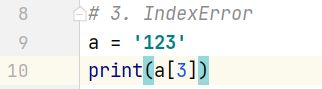
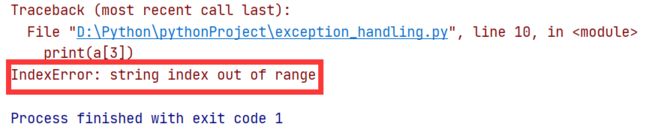
3. IndexError
4. KeyError


5. ValueError


6. AttributeError


7. ZeroDivisionError
![]()
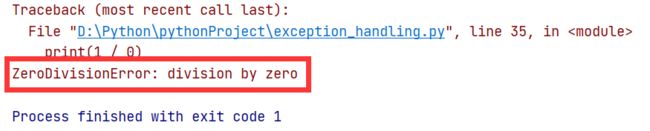
8. TypeError
![]()

捕获所有错误
except Exception

![]()
异常处理


except可捕获多个异常
格式:
![]()
注意:
多个错误,需用圆括号括起来作为一个参数。
捕获成功后显示额外错误信息

![]()
注意:一般在调试程序时使用
手动抛出异常

![]()
Python raise用法
finally
不管是否产生错误都要去执行。

总结

习题
练习一 异常
题目:
- 在Python程序中,分别使用未定义变量、访问列表不存在的索引、访问字典不存在的关键字观察系统提示的错误信息
- 通过Python程序产生IndexError,并用try捕获异常处理
代码:

第八章 函数
函数的定义和常用操作

无函数版:
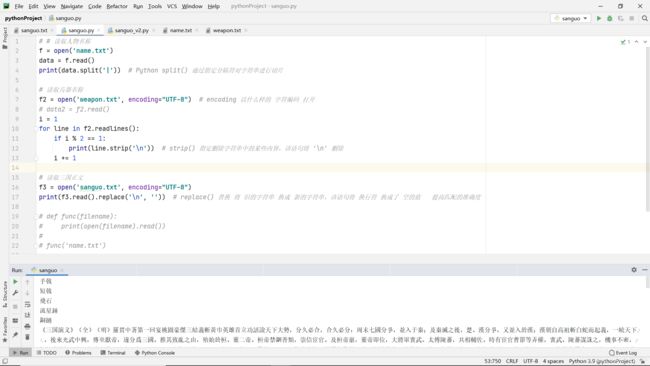
函数版:

完整版:
import re
def find_main_characters(character_name):
with open('sanguo.txt', encoding='UTF-8') as f:
data = f.read().replace("\n", "")
name_num = re.findall(character_name,data)
return character_name, len(name_num)
name_dict = {
}
with open('name.txt') as f:
for line in f:
names = line.split('|')
for n in names:
char_name, char_number = find_main_characters(n)
name_dict[char_name] = char_number
weapon_dict = {
}
with open('weapon.txt', encoding="UTF-8") as f: # 默认按行读取
i = 1
for line in f:
if i % 2 == 1:
weapon_name, weapon_number = find_main_characters(line.strip('\n')) # 读取 删除'\n'的 该行内容
weapon_dict[weapon_name] = weapon_number
i = i + 1
name_sorted = sorted(name_dict.items(), key=lambda item: item[1], reverse=True)
print(name_sorted[0:10])
weapon_sorted = sorted(weapon_dict.items(), key=lambda item: item[1], reverse=True)
print(weapon_sorted[0:10])
结果:
![]()
函数的可变长参数
关键字参数
作用:
当没有按顺序写入参数时调用。
优点:
- 可以不用按顺序写入参数
- 更明确输入的参数究竟是什么含义
代码:


可变长参数

函数的变量作用域
全局变量
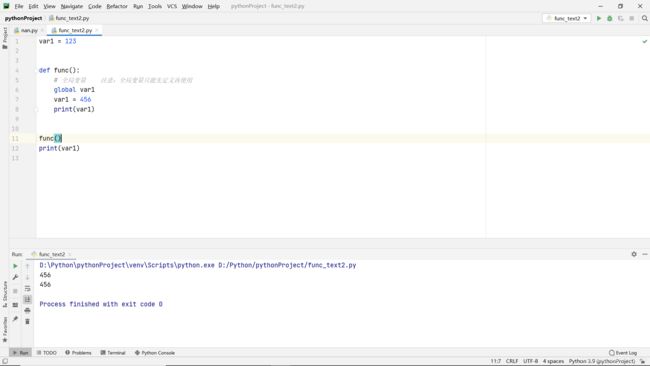
函数的迭代器与生成器
迭代器
功能
取列表当中每一个元素,对每一个元素依次进行处理,这种方法叫做迭代,能实现这种方法的函数,叫迭代器
两种函数(方法)
iter()和next()

生成器
定义
自己制作的迭代器叫生成器。
带yield的迭代器
自定义的迭代器
代码1:
for i in range(10, 20, 0.5):
print(i)
会报错,range()函数不允许令float数作为其步长。
代码2:
# 实现一个支持小数步长增长的range
def frange(start, stop, step):
x = start
while x < stop:
yield x # yield 运行到yield时会进行暂停,并记录当前的位置,当再次调用next()时,它会通过当前位置再去返回一个值
x += step
for i in frange(10, 20, 0.5):
print(i)
结果:
10
10.5
11.0
11.5
12.0
12.5
13.0
13.5
14.0
14.5
15.0
15.5
16.0
16.5
17.0
17.5
18.0
18.5
19.0
19.5
Lambda表达式
作用
简化函数。
代码:
def true():
return True
# 等于
def true():return True
# 等于
lambda: True
def add(x, y):
return x + y
# 等于
def add(x, y):return x + y
# 等于
lambda x, y:x + y # 参数是 x,y 返回是 x+y
lambda返回的是lambda的表达式:
用途
代码1:
lambda x: x <= (month, day) # 参数是:x,返回的是:x <= (month, day)
# 转换成函数
def find(x):
return x <= (month, day)
代码2:
lambda item: item[1] # 参数是:item,返回的是:item[1]
# 转换成函数
def find2(item): # 传入一个字典元素,取字典的值
return item[1]
adict = {
'a': '123', 'b': '456'}
for i in adict.items():
print(find2(i)) # 取字典的值
Python 字典(Dictionary) items() 函数的用法。
Python内建函数
filter
功能:
filter(function, sequence)
过滤 sequence 中满足funciton的数
代码:
a = [1, 2, 3, 4, 5, 6, 7]
b = list(filter(lambda x: x > 2, a)) # 过滤 a 中 满足 大于2的数
print(b)
结果:
[3, 4, 5, 6, 7]
必须转化成list,否则lambda不会被执行
map
功能:
map(function, sequence)
对sequence中的值依次按function处理
代码1:
c = [1, 2, 3]
map(lambda x: x, c) # 将 c 中的值 依次 返回 x
d = list(map(lambda x: x, c))
print(d)
map(lambda x: x + 1, c) # 将 c 中的值 依次+1 返回
e = list(map(lambda x: x + 1, c))
print(e)
结果:
[1, 2, 3]
[2, 3, 4]
代码2:
a = [1, 2, 3]
b = [4, 5, 6]
map(lambda x, y: x + y, a, b)
c = list(map(lambda x, y: x + y, a, b))
print(c)
结果:
[5, 7, 9]
对应项依次相加输出。
reduce
功能:
reduce(function, sequence[, initial])
把序列的元素依次和初始值按照函数的方式做运算。
代码:
from functools import reduce
total = reduce(lambda x, y: x + y, [2, 3, 4], 1) # 1 和 列表中第一个元素 按照 func 进行操作
print(total)
# ((1+2)+3)+4
结果:
10
zip
功能一:纵向整合
代码:
exchange = zip((1, 2, 3), (4, 5, 6))
for i in exchange:
print(i)
# 进行了纵向整合,类比线性代数中的“矩阵转换”
结果:
(1, 4)
(2, 5)
(3, 6)
(1, 2, 3)
(4, 5, 6)
(1, 4)
(2, 5)
(3, 6)
功能二:字典中 key 和 value 对调
代码:
dicta = {
'a': '123', 'b': '456'}
dictb = zip(dicta.values(), dicta.keys())
# ('a', 'b'), ('1', '2') --> ('a', '1'), ('b', '2')
print(dictb)
print(dict(dictb)) # 需将其类型强制转换为 dict
结果:
<zip object at 0x0000016A531F7E40>
{
'123': 'a', '456': 'b'}
闭包的定义
闭包
定义:
外部函数中的变量被内部函数引用,就叫做 “闭包”
代码:
def func