初识Java 14-2 测试
目录
测试驱动开发(TDD)
日志
调试
使用JDB进行调试
基准测试
微基准测试
Java微基准测试工具(JMH)
分析和优化
重构
本笔记参考自: 《On Java 中文版》
测试驱动开发(TDD)
测试驱动开发的前提:如果在设计和编写代码时考虑到测试,我们不仅可以创建可测试的代码,而且代码的设计也会变得更好。
通常来说,“可测试”的代码“可用性”也越高。
这里还有一个测试优先开发的概念:在实现新功能前为该功能编写测试。
JUnit 5带来了一些新的特性,其中包括了动态测试生成:我们可以编写代码,在运行时生成测试。这就取代了原本手动编写每个测试的模式。它为程序员处理巨大而又完整的测试集提供了遍历(下面的例子会用到它,因此这里要多说几句)。
JUnit 5提供了许多用来动态生成测试的方法。这里介绍其中的DynamicTest.stream()。

该方法的参数依次可概括为:
- inputGenerator:一组对象的迭代器,每组测试的对象都是不同的。迭代器生成的对象可以是任何类型,但每次只能生成一个对象。
- displayNameGenerator:从迭代器中获取对象,并生成一个字符串来描述这个测试。
- testExecutor:接受来自迭代器的对象,并包含了基于该对象的测试代码。
【例子:反转字符串中字符的大小写】
我们需要为这个例子添加一些约束:①字符串必须小于或等于30个字符,并且②只能包含字母、空格、逗号和句点。
为了接受StringInverter的不同实现(这一点和标准的TDD不同),我们会将StringInverter定义成一个interface:
public interface StringInverter {
String invert(String str); // 一个函数式接口,之后可以使用lambda表达式
}我们会一步步添加新功能,直到满足所有的测试需求:
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.DynamicTest;
import org.junit.jupiter.api.TestFactory;
import static org.junit.jupiter.api.Assertions.*;
import validating.*;
import java.util.Arrays;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class DynamicStringInverterTests {
// 通过组合操作,我们将原本会重复的代码合并到了testVersions中
Stream testVersions(String id,
Function test) {
List versions = Arrays.asList(
new Inverter1(), new Inverter2()
, new Inverter3(), new Inverter4());
return DynamicTest.stream(
versions.iterator(),
inverter -> inverter.getClass().getSimpleName(),
inverter -> {
System.out.println(
inverter.getClass().getSimpleName() +
": " + id);
try {
if (test.apply(inverter) != "fail")
System.out.println("成功");
} catch (Exception | Error e) {
System.out.println("Exception: " + e.getMessage());
}
}
);
}
String isEqual(String lval, String rval) {
if (lval.equals(rval))
return "成功";
System.out.println("失败:" + lval + " != " + rval);
return "fail";
}
@BeforeAll
static void startMsg() {
System.out.println(">>> 开始测试");
}
@AfterAll
static void endMsg() {
System.out.println(">>> 测试结束");
}
@TestFactory
Stream basicInversion1() {
String in = "Exit";
String out = "eXIT";
return testVersions("基本的测试(应该成功)",
inverter -> isEqual(inverter.invert(in), out));
}
@TestFactory
Stream basicInversion2() {
return testVersions("基本的测试(应该失败)",
inverter -> isEqual(inverter.invert("X"), "X"));
}
@TestFactory
Stream disallowedCharacters() {
String disallowed = ";-_()*&^%$#@!~`0123456789";
return testVersions("不被允许的字符",
stringInverter -> { // 第二个参数是Function类型
String result = disallowed.chars() // 根据disallowed生成一个char类型的IntStream流
.mapToObj(c -> { // 对流中的元素进行处理,再返回流
String cc = Character.toString((char) c);
try {
stringInverter.invert(cc);
return "";
} catch (RuntimeException e) {
return cc;
}
}).collect(Collectors.joining("")); // 将流中的元素收集成一个String
if (result.length() == 0)
return "成功";
System.out.println("错误的字符:" + result);
return "fail";
});
}
@TestFactory
Stream allowdeCharacters() {
String lowcase = "abcdefghijklmnopqrstuvwxyz ,.";
String upcase = "ABCDEFGHIJKLMNOPQRSTUVWXYZ ,.";
return testVersions("允许的字符(应该成功)",
stringInverter -> {
assertEquals(stringInverter.invert(lowcase), upcase);
assertEquals(stringInverter.invert(upcase), lowcase);
return "成功";
});
}
@TestFactory
Stream lengthNoGreaterThan30() {
String str = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
assertTrue(str.length() > 30);
return testVersions("字符串长度必须小于31(来自异常)",
stringInverter -> stringInverter.invert(str));
}
@TestFactory
Stream lengthLessThan31() {
String str = "xxxxxxxxxxxxxxxxxxxxxx";
assertTrue(str.length() < 31);
return testVersions("字符串长度必须小于31(应该成功)",
stringInverter -> stringInverter.invert(str));
}
} 我们设定,在遇到异常后系统会报告问题,但是继续进行测试。
通过testVersions(),我们用@TestFactory注解标注过的每个方法都会生成一个DynamicTest对象的流。接下来开始实现StringInverter。先从一个没有什么功能的类开始:
public class Inverter1 implements StringInverter {
@Override
public String invert(String str) {
return str; // 直接返回传入的参数,不做任何操作
}
}Inverter2将会实现反转操作:
import static java.lang.Character.*;
public class Inverter2 implements StringInverter {
@Override
public String invert(String str) {
String result = "";
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i); // 返回str中下标为i的字符
result += isUpperCase(c) ?
toLowerCase(c) :
toUpperCase(c);
}
return result;
}
}Inverter3在Inverter2的基础上,还需要确保字符串长度不会超过30个字符:

Inverter4在此基础上,还需要抛出不允许的字符:

运行测试,可以发现我们的Inverter越来越接近通过所有测试。
DynamicStringInverterTests用于展示不同StringInverter的开发过程。但一般不需要这么麻烦,只需要编写一个测试,并不断修改单个的StringInverter,直到它满足我们的所有需求即可:
import org.junit.jupiter.api.*;
import static org.junit.jupiter.api.Assertions.*;
import validating.Inverter4;
import validating.StringInverter;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StringInverterTests {
StringInverter inverter = new Inverter4();
@BeforeAll
static void startMsg() {
System.out.println(">>> 开始测试 <<<");
}
@AfterAll
static void endMsg() {
System.out.println(">>> 测试结束 <<<");
}
@Test
void basicInversion1() {
String in = "Exit";
String out = "eXIT";
assertEquals(inverter.invert(in), out);
}
@Test
void basicInversion2() {
assertThrows(Error.class, () -> {
assertEquals(inverter.invert("X"), "X");
});
}
@Test
void disallowedCharacters() {
String disallowed = ";-_()*&^%$#@!~`0123456789";
String result = disallowed.chars() // 根据disallowed生成一个char类型的IntStream流
.mapToObj(c -> { // 对流中的元素进行处理,再返回流
String cc = Character.toString((char) c);
try {
inverter.invert(cc);
return "";
} catch (RuntimeException e) {
return cc;
}
}).collect(Collectors.joining("")); // 将流中的元素收集成一个String
assertEquals(result, disallowed);
}
@Test
void allowdeCharacters() {
String lowcase = "abcdefghijklmnopqrstuvwxyz ,.";
String upcase = "ABCDEFGHIJKLMNOPQRSTUVWXYZ ,.";
assertEquals(inverter.invert(lowcase), upcase);
assertEquals(inverter.invert(upcase), lowcase);
}
@Test
void lengthNoGreaterThan30() {
String str = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
assertTrue(str.length() > 30);
assertThrows(RuntimeException.class,
() -> inverter.invert(str));
}
@Test
void lengthLessThan31() {
String str = "xxxxxxxxxxxxxxxxxxxxxx";
assertTrue(str.length() < 31);
inverter.invert(str);
}
}可以先在测试用例中指名所有要实现的功能,再以此为基础,在代码中实现所有的相关功能。
测试驱动与测试优先
可以将未通过的测试作为书签。这样当我们暂时离开工作后,下一次就可以通过这些书签回到上次工作暂停的地方。
纯测试优先编程同样存在问题,因为它假设我们预先了解正在解决的问题的一切。
日志
||| 日志:用以报告正在运行的程序的相关信息。
在可调试的程序中,日志可以是显示程序进度的普通状态数据。而在调试的过程中,日志为可以为我们提供许多必要的信息,通过它们,我们可以破译程序的行为。
Java编译器会优化未被调用的代码,例如:
static final boolean debug = false;
if(debug) { // 因为此时debug为false,所以编译器会删除大括号内的代码
System.out.println("Debug的信息");
}因此,代码不使用就不会对运行造成负担。在日志包(logging package)可用前,程序员可以根据这一点进行编程。
但上述这种方式需要手动修改,并重新编译文件,这就太麻烦了(而且此时标准Java发行版日志包的设计并不怎么被接受)。SLF4J的出现改变了这些,它为多个日志框架提供了一个统一的门面(facade),例如java.util.logging、logback和log4j。
SLF4J允许最终用户在部署时再插入所需的日志框架。
SLF4J只提供接口,需要配合其他包进行使用。
【例子:使用SLF4J提供的工具报告程序信息】
import org.slf4j.*;
public class SLF4JLogging {
private static Logger log =
LoggerFactory.getLogger(SLF4JLogging.class);
public static void main(String[] args) {
log.info("Hello logging");
}
}程序执行的结果如下:
![]()
输出中的格式和信息,甚至输出的内容是正常的还是错误的,这些都取决于连接到SLF4J的后端包。在上面的示例中,它连接到了logback库。
可以修改配置文件来改变后端的日志包(具体操作取决于使用的项目构建工具)。
日志系统会检测日志消息来源的类名和方法名,但系统不会保证其的正确性。因此不要依赖它们。
日志级别
SLF4J提供了多个级别的报告,按照“严重性”递增的顺序可分为:
①TRACE ②DEBUG ③INFO ④WARN ⑤ERROR
根据不同的级别设置,我们可以查看某个级别的信息。
【例子:】
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JLevels {
private static Logger log =
LoggerFactory.getLogger(SLF4JLevels.class);
public static void main(String[] args) {
log.trace("Hello");
log.debug("Logging");
log.info("Using");
log.warn("the SLF4J");
log.error("Facade");
}
}程序执行的结果如下:

(或许是笔者使用的logback版本的原因,TRACE级别的log并未显示)
这些级别通常会被设置在单独的配置文件中, 因此无需重新编译即可重新配置(配置文件格式取决于使用的后端日志实现)。
调试
对于复杂的问题而言,使用日志等查看信息会变得过于繁琐。此时,使用调试器是一个更好的选择。调试器有几个优点,除了更容易显示信息外,调试器还能够设置断点、显示程序状态、查看变量的值、逐行执行程序……
在构建巨大的系统时,熟悉调试器是值得的。
使用JDB进行调试
Java调试器(JDB)是JDK附带的命令行工具,在一些概念上可以说继承自GDB。只要安装了JDK,就可以使用JDB。
【例子:JDB的调试】
先写一个程序:
public class SimpleDebugging {
private static void foo1() {
System.out.println("在方法foo1中");
foo2();
}
private static void foo2() {
System.out.println("在方法foo1中");
foo3();
}
private static void foo3() {
System.out.println("在方法foo3中");
int j = 1;
j--;
int i = 5 / j; // 除0,会引发错误
}
public static void main(String[] args) {
foo1();
}
}若要运行JDB,我们首先需要在编译时添加-g标志。这样才能生成调试信息:
javac -g SimpleDebugging.java然后我们就可以使用命令行开始调试程序了:
jdb SimpleDebugging我们可以进行交互式调试跟踪:

上述命令会在任何抛出异常的地方设置一个断点(不过即使没有设置,调试器也会在遇到异常时停止)。接下来,通过run指令,我们可以尝试运行我们的程序:

在运行到异常时程序没有退出,而是显示了导致异常的代码行(int i = 5 / j;)。可以使用list命令列出程序源码中停止的地方:

恢复执行后,会从指针(即“=>”)处继续执行。可以使用cont(continue)命令恢复执行:

此时会退出JDB,并打印栈信息。
除此之外还有一些常用命令:
- locals:转储所有局部变量的值。

- wherei:打印当前线程的方法栈中压入的栈帧。
其中pc是程序计数器,用来表示调用返回的点。
可以尝试使用IntelliJ IDEA等IDE,这种图形调试器更方便学习。
基准测试
过早地优化在大多情况下是不好的。通常,简单直接的编程方法更为实用。若进行了不必要的优化,会使代码变得复杂而难以理解。
基准测试意味着对代码或算法进行计时,以此来比较运行的速度。
微基准测试
一个简单的方式是编写一个计时用程序来比较不同代码段的运行速度。
【例子:计时程序及其的使用】
先写一个简单的计时方法:
package onjava;
import static java.util.concurrent.TimeUnit.*;
public class Timer {
private long start = System.nanoTime();
public long duration() {
return NANOSECONDS.toMillis(
System.nanoTime() - start);
}
public static long duration(Runnable test) {
Timer timer = new Timer();
test.run();
return timer.duration();
}
}需要注意的是,有许多因素可以影响运行的结果,甚至会产生相反的指标。
接下来的示例会测试Arrays类中的两个方法,setAll()和parallelSetAll():
import onjava.Timer;
import java.util.Arrays;
public class BadMicroBenchmark {
static final int SIZE = 250_000_000;
public static void main(String[] args) {
try { // 若内存不足
long[] la = new long[SIZE];
System.out.println("setAll: " +
Timer.duration(() ->
Arrays.setAll(la, n -> n)));
System.out.println("parallelSetAll: " + // setAll()的并行版本
Timer.duration(() ->
Arrays.parallelSetAll(la, n -> n)));
} catch (OutOfMemoryError error) {
System.out.println("内存不足");
System.exit(0);
}
}
}程序执行的结果如下:
![]()
上述程序中的每个操作都是独立的,但若操作依赖于公共资源,并行版本最终可能会慢得多(因为会有其他任务来抢占资源):
import onjava.Timer;
import java.util.Arrays;
import java.util.Random;
import java.util.SplittableRandom;
// 假若依赖于某一公共资源
public class BadMicroBenchmark2 {
static final int SIZE = 5_000_000;
public static void main(String[] args) {
long[] la = new long[SIZE];
Random r = new Random();
System.out.println("parallelSetAll: " +
Timer.duration(() ->
Arrays.parallelSetAll(la, n -> r.nextLong())));
System.out.println("setAll: " +
Timer.duration(() ->
Arrays.setAll(la, n -> r.nextLong())));
SplittableRandom sr = new SplittableRandom(); // 这个Random就是为并行计算设计的
System.out.println("parallelSetAll: " +
Timer.duration(() ->
Arrays.parallelSetAll(la, n -> sr.nextLong())));
System.out.println("setAll: " +
Timer.duration(() ->
Arrays.setAll(la, n -> sr.nextLong())));
}
}程序执行的结果如下:

尽管SplittableRandom是为并行算法设计的,但我们得出的结论似乎并不这么认为。无论如何,通过这样一个简单的测试,我们无法了解到更多信息。
JVM存在Hotspot技术,它对性能的影响恨很大。JVM可能会因为某个程序运行的较为频繁,而为其预热,这就会让程序的运行速度提升。反之,若没有触发预热,或许就难以获得想要的结果。
优化器也可能优化我们的测试代码,使我们得到不怎么正确的结果。
Java微基准测试工具(JMH)
Java微基准测试工具(JMH)是一个Java微基准测试系统。我们可以编写JMH代码,并通过命令行来运行它,但更好的方式是让JMH系统为我们允许测试。
若要使用JMH,需要下载jmh-core和jmh-generator-annprocess。
JMH系统同样存在注解,这里先简单介绍一些用得到的(参考lang20150928的博客):
1. 主要使用的就是两个注解:
- @State:用于配置在测试中用到的对象(变量)的作用域。
- @Benchmark:表示的是基准测试的方法。
2. 其余的辅助性注解:
- @BenchmarkMode:用于指定基准测试执行模式。
- @OutputTimeUnit:用于指定基准测试结果输出的单位时间。
- @Folk:控制每个测试集的运行次数(默认数量是10)。
- @Warmup:控制预热迭代的次数(默认是20次)。
- @Measurement:控制测量迭代的次数(默认也是20次)。
- @Setup:用于指定基准测试执行前需要进行的准备工作,包括各种资源的初始化等(这个注解应该和@State同时出现)。
- @Param:会将它的每个值插入到它注解的变量中。
【例子:JMH测试】
import org.openjdk.jmh.annotations.*;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime) // AverageTime表示计算每次执行的总时间,并取平均值
@OutputTimeUnit(TimeUnit.MICROSECONDS) // 指定微秒作为时间单位
// 可以使用以下三个注解提高精度
@Warmup(iterations = 5) // 预热迭代5次
@Measurement(iterations = 5) // 测量迭代5次
@Fork(1) // 测试集运行1次
public class JMH1 {
private long[] la;
@Setup
public void setup() {
la = new long[250_000_000];
}
@Benchmark
public void setAll() {
Arrays.setAll(la, n -> n);
}
@Benchmark
public void parallelSetAll() {
Arrays.parallelSetAll(la, n -> n);
}
}(因为笔者在写这部分笔记时使用的是Intellij IDEA,因此这里推荐插件JMH Java Microbenchmark Harness来辅助进行运行)
运行上述程序可能需要几分钟。最终得到的结果输出的是绝对时间,因此结果会因为及其和操作系统而异。不过我们需要的是比较两种算法,因此这已经足够。下面是一个供参考的输出结果:

其中,Mode的avgt表示数据是平均时间。而Units的单位us/op,表示的是“每次运行花费的微秒数”,数字越小,性能越高。
即使拥有成熟的基准测试工具,我们也应该认真对待测试的过程。上述测试产生的结果似乎是反直觉的:并行版本和非并行版本的setAll()花费的时间大致相同。换句话说,我们没有得到我们测试到想要的测试内容。
这里就需要提到影响测试的其他因素了:
- C:执行操作的客户线程数。
- P:并行算法使用的并行量。
- N:数组的大小。
- Q:setter操作的成本。
C/P/Q/N模型在JDK 8的Lambda中就有所体现,Stream中的大部分并行操作符合以下结论:
- N*Q(基本上就是工作量)对并行性能很重要。若工作量减少,并行算法实际上可能运行得更慢。
- 若操作对资源的竞争很激烈,那么无论N*Q多大,并行性能都不会高。
- 当C较高时,P的相关性会降低很多(在一些情况下,对于C大小相同的用户而言,并行分解带来的成本会使得运行并行算法更慢)。
基于以上信息,我们使用不同的N值(即不同大小的数组)重新运行测试:

测试后得到的结果如下:

大约在100 000个元素之后,parallelSetAll()的速度落回平均标准,和setAll()相差不大。这似乎也不能证明parallelSetAll()存在的合理性。
上述的示例中,我们仅仅是让N变大了,但N*Q或许仍然不够好,并不足以提供足够的并行机会。接下来我们继续尝试让任务变得复杂,以提高并行的可能:

f()提供了更加复杂的操作,因为setAll()和parallelSetAll()现在有更多事需要做,所以结果会受到影响:
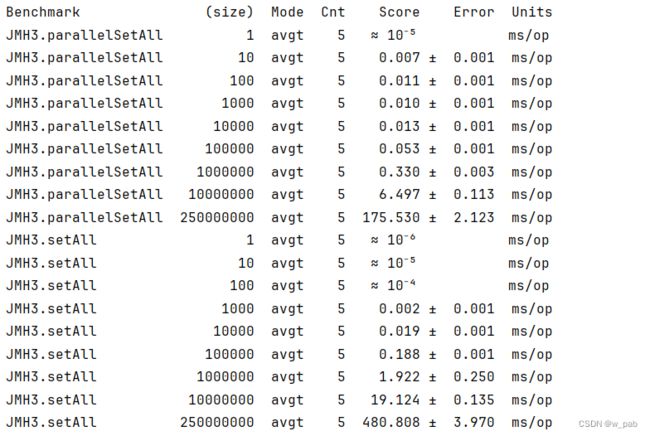
在这里,parallelSetAll()显示出了其的优势。从这里可以粗略地得出一个结论:parallelSetAll()的结果很大程度上取决于计算的复杂度和数组的大小。
大多情况下,简单的JMH应用已经足够。但不会总是如此,若想要入门JMH,可以查看官方的示例。
分析和优化
分析器可以为我们找到耗时的部分。若我们想要检测自己的程序把运行时间都花在了哪里,或者我们想要提高自己程序的运行效率,就可以使用分析器。
另外,分析器也有助于发现程序中的线程死锁。
分析和基准测试的区别:
- 分析的对象是处理数据的完整程序。
- 基准测试的对象是程序中的一个独立片段(通常是为了优化算法)。
JDK原本附带了一个可视化分析器VisualVM,但现在这个分析器已经作为一个独立的工具在GitHub上发布,可以前往GitHub获取它:
VisualVM https://visualvm.github.io/另外,该工具是开源的,因此可以可以在各大IDE上找到它的插件。
https://visualvm.github.io/另外,该工具是开源的,因此可以可以在各大IDE上找到它的插件。
若使用的是从官网下载的VisualVM,那么需要手动配置环境变量。若VisualVM无法找到JDK,可以使用命令:
visualvm --jdkhome /这是JDK/路径来指定使用的JDK(可以参考官方指导进行使用)。
优化建议:
- 不应该为了性能牺牲代码的可读性。
- 不要孤立地看待性能,应该在成本与好处之间进行权衡。
- 程序的大小很重要。性能优化往往只对大型项目有价值。
- 让程序先正常工作才是上策。一旦程序可以运行,我们就能通过调试去进行优化。
- 不要猜测问题在哪,运行分析器来获取数据。
- JVM会优化static final变量来提高程序速度。因此,程序常量应该声明为static和final的。
其他工具(可在IDE的插件中找到):
- 样式检查器CheckStyle
- 静态错误分析工具Findbugs
重构
一些持续更新的软件会积累快速而肮脏的解决方案,它们通常被称为技术债务。一般可以通过重构处理技术债务。其中的关键在于,重构会改变代码设计、结构和可读性,但它不会改变代码的行为。
但有时我们也很难说服管理层在必要的时候进行重构。
重构的基础
重构代码需要三个支持系统:
- 测试(至少是JUnit测试),用来保证重构不会改变代码的行为。
- 构建自动化,例如Gradle构建系统等。
- 版本控制,用来随时退回到可以工作的版本,并跟踪在这个过程中的所有操作。例如git版本控制系统。