爬虫(22)scrapy登录与middlewares
文章目录
- 第二十章 scrapy登录与middlewares
-
- 1. scrapy携带cookie模拟登录
-
- 1.1 创建项目
- 1.2 修改代码
- 1.3 查看spider的源码
- 1.4 重写start_requests(self)方法
- 1.5 配置settings文件
- 1.6 headers换成cookies
- 2. scrapy发送post请求模拟登录
-
- 2.1 form data里的数据
- 2.2 检查数据是否在源码中
- 2.3 创建一个scrapy项目和spider项目
- 2.4 修改start_url并获取需要的数据
- 2.5 汇总需要提交的数据
- 2.6 提交数据
- 3. scrapy另一种登录方式
-
- 3.1 创建项目
- 3.2 设置项目
- 3.3 scrapy.FormRequest.from_response方法
- 3.4 运行结果
- 4. middlewares文件的讲解
-
- 4.1 设置随机请求头
-
- 4.1.1 设置随机user-agent
- 4.1.2 fake-useragent
- 4.1.3 用fake-useragent设置随机请求头
- 4.2 设置代理IP
-
- 4.2.1 普通方法设置ip
- 4.2.2 在scrapy里面设置
第二十章 scrapy登录与middlewares
以前我们登录网站有两种方式:
一个是:直接携带cookie来请求页面
另一个:发送post请求携带数据进行模拟登录
当然selenium也能模拟登录(找到对应的input标签)。
1. scrapy携带cookie模拟登录
下面我们通过登录人人网案例来学习scrapy携带cookies登录方法。
1.1 创建项目
我们创建一个新的scrapy项目叫login
D:\work\爬虫\Day22>scrapy startproject login
New Scrapy project 'login', using template directory 'd:\python38\lib\site-packages\scrapy\templates\pro
ject', created in:
D:\work\爬虫\Day22\login
You can start your first spider with:
cd login
scrapy genspider example example.com
D:\work\爬虫\Day22>
然后我们cd 到login
D:\work\爬虫\Day22>cd login
D:\work\爬虫\Day22\login>
我们先放一下。下面我们要操作的是携带cookie登录人人网。http://www.renren.com/
这是一个社交平台。下面我们创建spider项目:
D:\work\爬虫\Day22\login>scrapy genspider renren renren.com
Created spider 'renren' using template 'basic' in module:
login.spiders.renren
D:\work\爬虫\Day22\login>
1.2 修改代码
现在我们可以打开查看我们刚刚创建的项目:

第一步我们先把start_url改了,改成详情页面的url
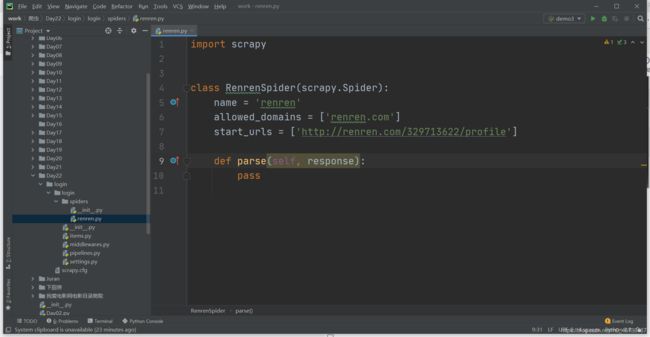
如果我们添加一个cookie值就能登录了,但是怎么添加呢?添加到什么地方呢?
response是已经拿到的响应结果,所以我们添加在parse这个方法的下面是没有意义的。
1.3 查看spider的源码
所以,我们一定要在请求地址的时候就携带cookie。下面我们分析一下spider的源码,Ctrl+点击spider
我们看到里面的代码:
"""
Base class for Scrapy spiders
See documentation in docs/topics/spiders.rst
"""
import logging
import warnings
from typing import Optional
from scrapy import signals
from scrapy.http import Request
from scrapy.utils.trackref import object_ref
from scrapy.utils.url import url_is_from_spider
from scrapy.utils.deprecate import method_is_overridden
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
"""
name: Optional[str] = None
custom_settings: Optional[dict] = None
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError(f"{type(self).__name__} must have a name")
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = []
@property
def logger(self):
logger = logging.getLogger(self.name)
return logging.LoggerAdapter(logger, {'spider': self})
def log(self, message, level=logging.DEBUG, **kw):
"""Log the given message at the given log level
This helper wraps a log call to the logger within the spider, but you
can use it directly (e.g. Spider.logger.info('msg')) or use any other
Python logger too.
"""
self.logger.log(level, message, **kw)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = cls(*args, **kwargs)
spider._set_crawler(crawler)
return spider
def _set_crawler(self, crawler):
self.crawler = crawler
self.settings = crawler.settings
crawler.signals.connect(self.close, signals.spider_closed)
def start_requests(self):
cls = self.__class__
if not self.start_urls and hasattr(self, 'start_url'):
raise AttributeError(
"Crawling could not start: 'start_urls' not found "
"or empty (but found 'start_url' attribute instead, "
"did you miss an 's'?)")
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead "
f"(see {cls.__module__}.{cls.__name__}).",
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
def make_requests_from_url(self, url):
""" This method is deprecated. """
warnings.warn(
"Spider.make_requests_from_url method is deprecated: "
"it will be removed and not be called by the default "
"Spider.start_requests method in future Scrapy releases. "
"Please override Spider.start_requests method instead."
)
return Request(url, dont_filter=True)
def _parse(self, response, **kwargs):
return self.parse(response, **kwargs)
def parse(self, response, **kwargs):
raise NotImplementedError(f'{self.__class__.__name__}.parse callback is not defined')
@classmethod
def update_settings(cls, settings):
settings.setdict(cls.custom_settings or {}, priority='spider')
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
@staticmethod
def close(spider, reason):
closed = getattr(spider, 'closed', None)
if callable(closed):
return closed(reason)
def __str__(self):
return f"<{type(self).__name__} {self.name!r} at 0x{id(self):0x}>"
__repr__ = __str__
# Top-level imports
from scrapy.spiders.crawl import CrawlSpider, Rule
from scrapy.spiders.feed import XMLFeedSpider, CSVFeedSpider
from scrapy.spiders.sitemap import SitemapSpider
1.4 重写start_requests(self)方法
我们看到里面有一个方法叫start_requests(self)
def start_requests(self):
cls = self.__class__
if not self.start_urls and hasattr(self, 'start_url'):
raise AttributeError(
"Crawling could not start: 'start_urls' not found "
"or empty (but found 'start_url' attribute instead, "
"did you miss an 's'?)")
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead "