【学习日记2023.4.30】之 MySQL基础架构_数据库操作DML_DQL
文章目录
- 1. MYSQL基础架构
-
- 1.1 连接器
- 1.2 查询缓存
- 1.3 解析SQL
- 1.4 执行SQL
-
- 1.4.1 预处理器
- 1.4.2 优化器
- 1.4.3 执行器
- 1.5.总结
- 2. 数据库操作-DML
-
- 2.1 增加(insert)
- 2.2 修改(update)
- 2.3 删除(delete)
- 3. 数据库操作-DQL
-
- 3.1 介绍
- 3.2 语法
- 3.3 基本查询
- 3.4 条件查询
- 3.5 聚合函数
- 3.6 分组查询
- 3.7 排序查询
- 3.8 分页查询
- 3.9 案例
-
- 3.9.1 案例一
- 3.9.2 案例二
- 3.10 查询语句总结
-
1. MYSQL基础架构
(转载至:原文链接)
- 连接器:建立连接、管理链接、校验用户身份
- 查询缓存: 查询语句如果命中查询缓存则直接返回,否则继续往下执行。(MYSQL8.0已删除该模块)
- 解析器:通过对SQL查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型。
- 预处理器:检查表或字段是否存在,将select * 中的*扩展为表上的所有列。
- 优化器:基于查询成本的考虑,选择查询成本最小的执行计划。
- 执行器:根据执行计划执行SQL语句,从存储引擎读取记录,返回给客户端。
可以将MYSQL的架构分为两层:server层和存储引擎层
- Server层:负责建立连接、分析和执行SQL。MySQL 大多数的核心功能模块都在这实现,主要包括连接器,查询缓存、解析器、预处理器、优化器、执行器等。另外,所有的内置函数(如日期、时间、数学和加密函数等)和所有跨存储引擎的功能(如存储过程、触发器、视图等。)都在 Server 层实现。
- 存储引擎层:负责数据的存储和提取。支持 InnoDB、MyISAM、Memory 等多个存储引擎,不同的存储引擎共用一个 Server 层。现在最常用的存储引擎是 InnoDB,从 MySQL 5.5 版本开始, InnoDB 成为了 MySQL 的默认存储引擎。我们常说的索引数据结构,就是由存储引擎层实现的,不同的存储引擎支持的索引类型也不相同,比如 InnoDB 支持索引类型是 B+树 ,且是默认使用,也就是说在数据表中创建的主键索引和二级索引默认使用的是 B+ 树索引。
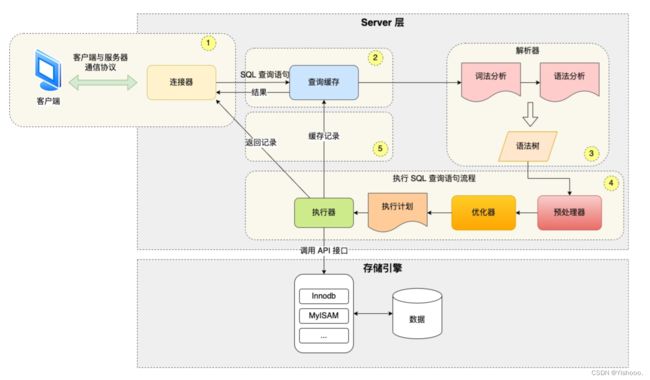
1.1 连接器
- 与客户端进行 TCP 三次握手建立连接;
- 校验客户端的用户名和密码,如果用户名或密码不对,则会报错;
- 如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限;即使在连接的过程中权限被管理员修改了,权限在连接结束之前也不会改变。
1.2 查询缓存
MySQL服务收到SQL语句后,就会解析出SQL语句的第一个字段,看是什么类型的语句
如果是查询语句(select 语句),MySQL就先去查询缓存里查找缓存数据,看看之前有没有执行过这个命令,这个查询缓存是以key - value 形式来保存的,key 为 SQL 查询语句, value 为 SQL语句查询的结果
如果查询语句命中查询缓存,那么就会直接返回给 value 给客户端。如果查询的语句没有命中查询缓存,那么就要继续往下执行,等执行完后,查询的结果就会存入查询缓存中。
但是这个查询缓存的效果并不是很好,对于更新比较频繁的表,查询缓存的命中率很低的,因为只要一个表有更新操作那么这个表的查询缓存就会被清空,如果刚缓存了一个查询结果很大的数据,还没被使用的时候,刚好这个表有更新操作,查询缓冲就被清空了,相当于缓存了个寂寞。
所以,MySQL 8.0 版本直接将查询缓存删掉了,也就是说 MySQL 8.0 开始,执行一条 SQL 查询语句,不会再走到查询缓存这个阶段了。
1.3 解析SQL
- 词法分析:MySQL根据输入的字符串识别出关键字来构建 SQL 语法树,方便后续模块获取 SQL 类型、表名、字段名、where条件等等
- 语法分析:根据词法分析的结果,语法解析器会根据语法规则,判断输入的SQL语句是否满足语法。
1.4 执行SQL
经过解析器后,接着就要进入执行 SQL 查询语句的流程了,每条SELECT 查询语句流程主要可以分为下面这三个阶段:
- prepare 阶段,也就是预处理阶段;
- optimize 阶段,也就是优化阶段;
- execute 阶段,也就是执行阶段;
1.4.1 预处理器
- 检查 SQL 查询语句中的表或字段是否存在
- 将select 中的符号扩展为表上的所有列。
1.4.2 优化器
经过预处理阶段后,还需要为 SQL 查询语句先制定一个执行计划,这个工作交由优化器来完成的。
优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
1.4.3 执行器
当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
1.5.总结
执行一条 SQL 查询语句,期间发生了什么?
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。
- 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
2. 数据库操作-DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
2.1 增加(insert)
insert语法:
向指定字段添加数据
insert into 表名 (字段名1, 字段名2) values (值1, 值2);全部字段添加数据
insert into 表名 values (值1, 值2, ...);批量添加数据(指定字段)
insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2);批量添加数据(全部字段)
insert into 表名 values (值1, 值2, ...), (值1, 值2, ...);案例1:向tb_emp表的username、name、gender字段插入数据
-- 因为设计表时create_time, update_time两个字段不能为NULL,所以也做为要插入的字段 insert into tb_emp(username, name, gender, create_time, update_time) values ('wuji', '张无忌', 1, now(), now());案例2:向tb_emp表的所有字段插入数据
insert into tb_emp(id, username, password, name, gender, image, job, entrydate, create_time, update_time) values (null, 'zhirou', '123', '周芷若', 2, '1.jpg', 1, '2010-01-01', now(), now());案例3:批量向tb_emp表的username、name、gender字段插入数据
insert into tb_emp(username, name, gender, create_time, update_time) values ('weifuwang', '韦一笑', 1, now(), now()), ('fengzi', '张三疯', 1, now(), now());图形化操作:双击tb_emp表查看数据
Insert操作的注意事项:
- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中。
- 插入的数据大小,应该在字段的规定范围内。

2.2 修改(update)
update语法:
update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ;案例1:将tb_emp表中id为1的员工,姓名name字段更新为’张三’
update tb_emp set name='张三',update_time=now() where id=1;案例2:将tb_emp表的所有员工入职日期更新为’2010-01-01’
update tb_emp set entrydate='2010-01-01',update_time=now();注意事项:
- 修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
- 在修改数据时,一般需要同时修改公共字段update_time,将其修改为当前操作时间。
2.3 删除(delete)
delete语法:
delete from 表名 [where 条件] ;案例1:删除tb_emp表中id为1的员工
delete from tb_emp where id = 1;案例2:删除tb_emp表中所有员工
delete from tb_emp;注意事项:
DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。
当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute即可。
3. 数据库操作-DQL
DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
3.1 介绍
查询关键字:SELECT
查询操作是所有SQL语句当中最为常见,也是最为重要的操作。在一个正常的业务系统中,查询操作的使用频次是要远高于增删改操作的。当我们打开某个网站或APP所看到的展示信息,都是通过从数据库中查询得到的,而在这个查询过程中,还会涉及到条件、排序、分页等操作。

3.2 语法
DQL查询语句,语法结构如下:
SELECT 字段列表 FROM 表名列表 WHERE 条件列表 GROUP BY 分组字段列表 HAVING 分组后条件列表 ORDER BY 排序字段列表 LIMIT 分页参数上面的完整语法拆分为以下几个部分学习:
- 基本查询(不带任何条件)
- 条件查询(where)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
准备一些测试数据用于查询操作:
create database db02; -- 创建数据库 use db02; -- 切换数据库 -- 员工管理(带约束) create table tb_emp ( id int unsigned primary key auto_increment comment 'ID', username varchar(20) not null unique comment '用户名', password varchar(32) default '123456' comment '密码', name varchar(10) not null comment '姓名', gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女', image varchar(300) comment '图像', job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管', entrydate date comment '入职时间', create_time datetime not null comment '创建时间', update_time datetime not null comment '修改时间' ) comment '员工表'; -- 准备测试数据 INSERT INTO tb_emp (id, username, password, name, gender, image, job, entrydate, create_time, update_time) VALUES (1, 'jinyong', '123456', '金庸', 1, '1.jpg', 4, '2000-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:35'), (2, 'zhangwuji', '123456', '张无忌', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:37'), (3, 'yangxiao', '123456', '杨逍', 1, '3.jpg', 2, '2008-05-01', '2022-10-27 16:35:33', '2022-10-27 16:35:39'), (4, 'weiyixiao', '123456', '韦一笑', 1, '4.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:41'), (5, 'changyuchun', '123456', '常遇春', 1, '5.jpg', 2, '2012-12-05', '2022-10-27 16:35:33', '2022-10-27 16:35:43'), (6, 'xiaozhao', '123456', '小昭', 2, '6.jpg', 3, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:45'), (7, 'jixiaofu', '123456', '纪晓芙', 2, '7.jpg', 1, '2005-08-01', '2022-10-27 16:35:33', '2022-10-27 16:35:47'), (8, 'zhouzhiruo', '123456', '周芷若', 2, '8.jpg', 1, '2014-11-09', '2022-10-27 16:35:33', '2022-10-27 16:35:49'), (9, 'dingminjun', '123456', '丁敏君', 2, '9.jpg', 1, '2011-03-11', '2022-10-27 16:35:33', '2022-10-27 16:35:51'), (10, 'zhaomin', '123456', '赵敏', 2, '10.jpg', 1, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:53'), (11, 'luzhangke', '123456', '鹿杖客', 1, '11.jpg', 2, '2007-02-01', '2022-10-27 16:35:33', '2022-10-27 16:35:55'), (12, 'hebiweng', '123456', '鹤笔翁', 1, '12.jpg', 2, '2008-08-18', '2022-10-27 16:35:33', '2022-10-27 16:35:57'), (13, 'fangdongbai', '123456', '方东白', 1, '13.jpg', 1, '2012-11-01', '2022-10-27 16:35:33', '2022-10-27 16:35:59'), (14, 'zhangsanfeng', '123456', '张三丰', 1, '14.jpg', 2, '2002-08-01', '2022-10-27 16:35:33', '2022-10-27 16:36:01'), (15, 'yulianzhou', '123456', '俞莲舟', 1, '15.jpg', 2, '2011-05-01', '2022-10-27 16:35:33', '2022-10-27 16:36:03'), (16, 'songyuanqiao', '123456', '宋远桥', 1, '16.jpg', 2, '2010-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:05'), (17, 'chenyouliang', '12345678', '陈友谅', 1, '17.jpg', null, '2015-03-21', '2022-10-27 16:35:33', '2022-10-27 16:36:07'), (18, 'zhang1', '123456', '张一', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:09'), (19, 'zhang2', '123456', '张二', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:11'), (20, 'zhang3', '123456', '张三', 1, '2.jpg', 2, '2018-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:13'), (21, 'zhang4', '123456', '张四', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:15'), (22, 'zhang5', '123456', '张五', 1, '2.jpg', 2, '2016-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:17'), (23, 'zhang6', '123456', '张六', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:19'), (24, 'zhang7', '123456', '张七', 1, '2.jpg', 2, '2006-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:21'), (25, 'zhang8', '123456', '张八', 1, '2.jpg', 2, '2002-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:23'), (26, 'zhang9', '123456', '张九', 1, '2.jpg', 2, '2011-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:25'), (27, 'zhang10', '123456', '张十', 1, '2.jpg', 2, '2004-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:27'), (28, 'zhang11', '123456', '张十一', 1, '2.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:29'), (29, 'zhang12', '123456', '张十二', 1, '2.jpg', 2, '2020-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:31');
3.3 基本查询
在基本查询的DQL语句中,不带任何的查询条件,语法如下:
查询多个字段
select 字段1, 字段2, 字段3 from 表名;查询所有字段(通配符)
select * from 表名;设置别名
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名;去除重复记录
select distinct 字段列表 from 表名;案例1:查询指定字段 name,entrydate并返回
select name,entrydate from tb_emp;案例2:查询返回所有字段
select * from tb_emp;
*号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)案例3:查询所有员工的 name,entrydate,并起别名(姓名、入职日期)
-- 方式1: select name AS 姓名, entrydate AS 入职日期 from tb_emp; -- 方式2: 别名中有特殊字符时,使用''或""包含 select name AS '姓 名', entrydate AS '入职日期' from tb_emp; -- 方式3: select name AS "姓名", entrydate AS "入职日期" from tb_emp;案例4:查询已有的员工关联了哪几种职位(不要重复)
select distinct job from tb_emp;
3.4 条件查询
语法:
select 字段列表 from 表名 where 条件列表 ; -- 条件列表:意味着可以有多个条件学习条件查询就是学习条件的构建方式,而在SQL语句当中构造条件的运算符分为两类:
- 比较运算符
- 逻辑运算符
常用的比较运算符如下:
比较运算符 功能 > 大于 >= 大于等于 < 小于 <= 小于等于 = 等于 <> 或 != 不等于 between … and … 在某个范围之内(含最小、最大值) in(…) 在in之后的列表中的值,多选一 like 占位符 模糊匹配(_匹配单个字符, %匹配任意个字符) is null 是null 常用的逻辑运算符如下:
逻辑运算符 功能 and 或 && 并且 (多个条件同时成立) or 或 || 或者 (多个条件任意一个成立) not 或 ! 非 , 不是 案例1:查询 姓名 为 杨逍 的员工
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where name = '杨逍'; -- 字符串使用''或""包含案例2:查询 id小于等于5 的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where id <=5;案例3:查询 没有分配职位 的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where job is null ;案例4:查询 有职位 的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where job is not null ;案例5:查询 密码不等于 ‘123456’ 的员工信息
-- 方式1: select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where password <> '123456'; -- 方式2: select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where password != '123456';案例6:查询 入职日期 在 ‘2000-01-01’ (包含) 到 ‘2010-01-01’(包含) 之间的员工信息
-- 方式1: select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where entrydate>='2000-01-01' and entrydate<='2010-01-01'; -- 方式2: between...and select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where entrydate between '2000-01-01' and '2010-01-01';案例7:查询 入职时间 在 ‘2000-01-01’ (包含) 到 ‘2010-01-01’(包含) 之间 且 性别为女 的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2;案例8:查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
-- 方式1:使用or连接多个条件 select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where job=2 or job=3 or job=4; -- 方式2:in关键字 select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where job in (2,3,4);案例9:查询 姓名 为两个字的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where name like '__'; # 通配符 "_" 代表任意1个字符案例10:查询 姓 ‘张’ 的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where name like '张%'; # 通配符 "%" 代表任意个字符(0个 ~ 多个)
3.5 聚合函数
之前做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
语法:
select 聚合函数(字段列表) from 表名 ;注意 : 聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
函数 功能 count 统计数量 max 最大值 min 最小值 avg 平均值 sum 求和 count :按照列去统计有多少行数据。
- 在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中。
sum :计算指定列的数值和,如果不是数值类型,那么计算结果为0
max :计算指定列的最大值
min :计算指定列的最小值
avg :计算指定列的平均值
案例1:统计该企业员工数量
# count(字段) select count(id) from tb_emp;-- 结果:29 select count(job) from tb_emp;-- 结果:28 (聚合函数对NULL值不做计算) # count(常量) select count(0) from tb_emp; select count('A') from tb_emp; # count(*) 推荐此写法(MySQL底层进行了优化) select count(*) from tb_emp;案例2:统计该企业最早入职的员工
select min(entrydate) from tb_emp;案例3:统计该企业最迟入职的员工
select max(entrydate) from tb_emp;案例4:统计该企业员工 ID 的平均值
select avg(id) from tb_emp;案例5:统计该企业员工的 ID 之和
select sum(id) from tb_emp;
3.6 分组查询
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];案例1:根据性别分组 , 统计男性和女性员工的数量
select gender, count(*) from tb_emp group by gender; -- 按照gender字段进行分组(gender字段下相同的数据归为一组)案例2:查询入职时间在 ‘2015-01-01’ (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
select job, count(*) from tb_emp where entrydate <= '2015-01-01' -- 分组前条件 group by job -- 按照job字段分组 having count(*) >= 2; -- 分组后条件注意事项:
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
执行顺序:where > 聚合函数 > having
where与having区别(面试题)
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
3.7 排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法:
select 字段列表 from 表名 [where 条件列表] [group by 分组字段 ] order by 字段1 排序方式1 , 字段2 排序方式2 … ;
排序方式:
ASC :升序(默认值)
DESC:降序
案例1:根据入职时间, 对员工进行升序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp order by entrydate ASC; -- 按照entrydate字段下的数据进行升序排序 select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp order by entrydate; -- 默认就是ASC(升序)注意事项:如果是升序, 可以不指定排序方式ASC ,默认就是ASC(升序)
案例2:根据入职时间,对员工进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp order by entrydate DESC; -- 按照entrydate字段下的数据进行降序排序案例3:根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp order by entrydate ASC , update_time DESC;注意事项:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
3.8 分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,日常我们在网站中看到的各种各样的分页条,后台也都需要借助于数据库的分页操作。
分页查询语法:
select 字段列表 from 表名 limit 起始索引, 查询记录数 ;案例1:从起始索引0开始查询员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp limit 0 , 5; -- 从索引0开始,向后取5条记录案例2:查询 第1页 员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp limit 5; -- 如果查询的是第1页数据,起始索引可以省略,直接简写为:limit 条数案例3:查询 第2页 员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp limit 5 , 5; -- 从索引5开始,向后取5条记录案例4:查询 第3页 员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp limit 10 , 5; -- 从索引10开始,向后取5条记录注意事项:
- 起始索引从0开始。 计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT
- 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数

3.9 案例
3.9.1 案例一
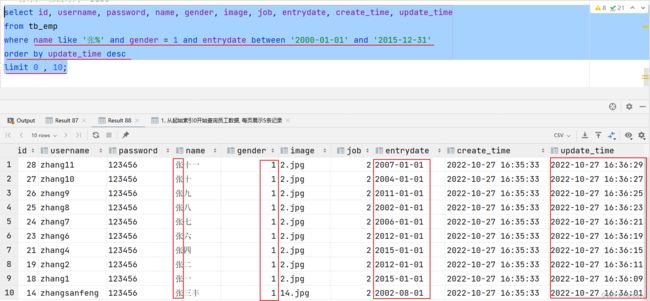
案例:根据需求完成员工管理的条件分页查询
分析:根据输入的条件,查询第1页数据
在员工管理的列表上方有一些查询条件:员工姓名、员工性别,员工入职时间(开始时间~结束时间)
- 姓名:张
- 性别:男
- 入职时间:2000-01-01 ~ 2015-12-31
除了查询条件外,在列表的下面还有一个分页条,这就涉及到了分页查询
- 查询第1页数据(每页显示10条数据)
基于查询的结果,按照修改时间进行降序排序
结论:条件查询 + 分页查询 + 排序查询
SQL语句代码:
-- 根据输入条件查询第1页数据(每页展示10条记录) -- 输入条件: -- 姓名:张 (模糊查询) -- 性别:男 -- 入职时间:2000-01-01 ~ 2015-12-31 -- 分页: 0 , 10 -- 排序: 修改时间 DESC select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp where name like '张%' and gender = 1 and entrydate between '2000-01-01' and '2015-12-31' order by update_time desc limit 0 , 10;

3.9.2 案例二
案例:根据需求完成员工信息的统计
分析:以上信息统计在开发中也叫图形报表(将统计好的数据以可视化的形式展示出来)
- 员工性别统计:以饼状图的形式展示出企业男性员人数和女性员工人数
- 只要查询出男性员工和女性员工各自有多少人就可以了
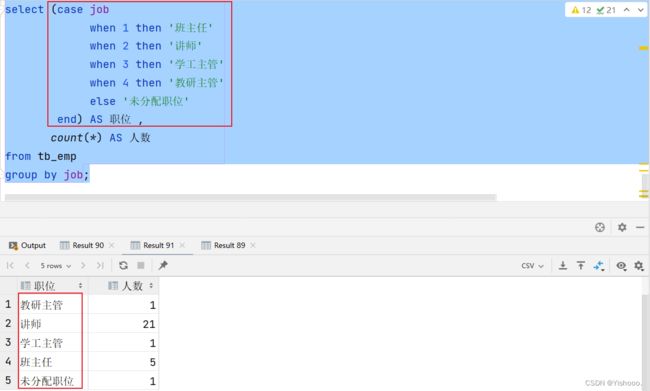
- 员工职位统计:以柱状图的形式展示各职位的在岗人数
- 只要查询出各个职位有多少人就可以了
员工性别统计:
-- if(条件表达式, true取值 , false取值) select if(gender=1,'男性员工','女性员工') AS 性别, count(*) AS 人数 from tb_emp group by gender;
if(表达式, tvalue, fvalue) :当表达式为true时,取值tvalue;当表达式为false时,取值fvalue
员工职位统计:
-- case 表达式 when 值1 then 结果1 when 值2 then 结果2 ... else result end select (case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研主管' else '未分配职位' end) AS 职位 , count(*) AS 人数 from tb_emp group by job;
case 表达式 when 值1 then 结果1 [when 值2 then 结果2 …] [else result] end


3.10 查询语句总结
select 字段列表 from 表明列表 where 条件语句 group by 分组字段 having 分组后的条件 order by 排序字段 排序方式 limit 起始索引,显示记录数sql关键字的执行顺序
from...where...group by...select...having...order by...limit
- where是在分组前对数据进行筛选,不满足条件的数据不会参与分组,where后不能跟聚合函数条件
- group by在数据已经完成基础筛查后,进行分组
- having是在分组后对数据进行进一步筛选,having后可以跟聚合函数条件
- order by是数据已经完成筛选后选择某列或者某几列数据进行排序
- limit是对排序后的数据选择显示多少条数据出来