回溯算法总结点睛
一、基本概念
1、什么是回溯法?
又称回溯搜索法,说白了就是一种搜索方式。
其实回溯是递归的副产品,只要有递归就会有回溯。
回溯函数也可以称之为递归函数。
2、回溯法的效率
回溯法本质是穷举,因此并不高效
可以通过一些剪枝的操作稍微提高一些效率,但仍是比较低效的算法
3、回溯法解决的问题
经常用来解决以下 5 种问题:
* 1)组合问题:**不强调**元素的顺序,N个数里按照一定的规则找出K个数的集合
* 2)排列问题:**强调**元素的顺序,N个数按一定的规则全排列,求有多少排列方式
* 3)切割问题:一个字符串按照一定规则有几种切割方式
* 4)子集问题:一个N个数的集合中有多少个符合条件的子集
* 5)棋盘问题:N皇后,解数独 等等。
4、如何理解回溯法
所有回溯法解决的问题,都可以抽象为树形结构。
因为递归法解决的都是在集合中 递归查找子集,集合的大小就构成了树的宽度,递归的深度就构成了树的深度。
递归就要有终止条件,所以必然是一棵高度有限的N叉树。
5、回溯法模板
void backtracking(参数)
{
if (终止条件)
{
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小))
{
处理节点;
backtracking(路径,选择列表); // 递归,也就是到下一层咯
回溯,撤销处理结果
}
}
-
回溯函数模板返回值以及参数
- 名字通常记为 backtracking
- 返回值一般为void
- 参数不像二叉树那样一次性基本就可以确定,因此一般是先写逻辑,然后需要什么参数就填什么参数
-
回溯函数终止条件
-
什么时候达到了终止条件,树中就可以看出,一般来说搜到了叶子节点了,也就是找到了满足条件的一条答案,把这个答案存起来,并结束本层递归
-
if (终止条件) { 存放结果; return; }
-
-
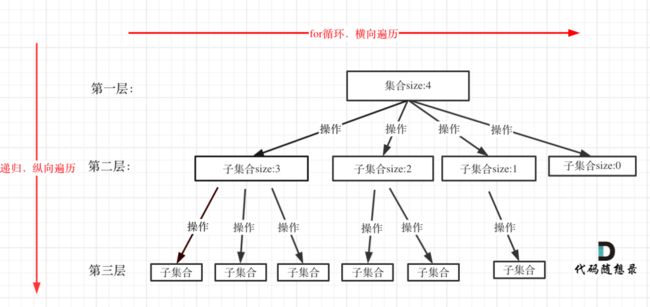
回溯搜索的遍历过程
-
回溯 : 在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成了树的深度
-
-
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表); // 递归 回溯,撤销处理结果 }- 图中,集合大小和孩子的数量是相等的
- for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
- backtracking这里自己调用自己,实现递归。
- for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
-
6、剪枝:
不要想的太复杂了 ,其实嘛~ 可以剪枝的地方就是在递归中每一层的for循环所选择的起始位置,所以 如果 for 循环选择的起始位置之后的元素个数 已经不足 我们需要的元素的个数,那么就没必要搜索啦啦啦~~~,也就是控制一下 for 循环的遍历终止条件
* 已经选择的元素的个数 **path.size()**
* 还需要的元素个数 **k - path.size()**
* 在集合n中,从 **n - (k - path.size()) + 1** 位置开始 往后的遍历均为无效遍历,因此就剪掉他
* 剪枝后的最终版本 **for(int i = 1; i <= (n - (k - path.size() + 1); i++)**
7、做题感想
其实,你得心里明白,for 循环中,就是横向走,递归呢,就是纵向走,
把握
回溯函数的参数决定了你这个代码的复杂程度,参数设定的比较合理的话,整个程序就可以得到简化,
就比如 字母+数字组合 ,这道题的 下标有两个,一个是字母字符串的下标,一个是输入的数字字符串的下标,怎么有机的联合起来是需要斟酌的问题
8、时间复杂度
主要分为几种题型来总结
n 表示数组的大小
- 组合问题
- 时间复杂度为 O(2^n) :相当于一棵二叉树,每个节点有两个孩子(一个是往下一层的递归,一个是往右走的for循环),所以时间复杂度是
- 排列问题
- 时间复杂度为 O(n!) :这里的for每一层都是要从 第1个元素开始,但是递归往下的时候不会重复已经用过的元素,所以时间复杂度是O(n!)
二、做题
第39题 & 第40题 组合问题
40与39的区别主要有两点:
1、40题中 给定数据集中的每个数字在组合中只能使用一次,而39题可以重复使用
2、40题中 给定的数据集中的元素本身有可能是重复的,而39题是无重复的
首先第一步想到的可以是把所有组合求出来,在用 set 或者 map 去重,但是呢这么做很容易超时,所以最好的是在搜索的过程中就去掉重复的组合。
这里的重复其实是有两个层面的理解,一个是同一树枝上重复,一个是同一树层上重复,
第40题,是允许同一树枝重复,但是不允许同一树层重复的结构,
去重的概念有两种,树枝的去重与树层的去重
第131题 分割回文串
这里:
横向表示在不同的位置切
纵向表示切几刀,每往下一层就表示多切一刀
终止就是切到了最后一个元素后面
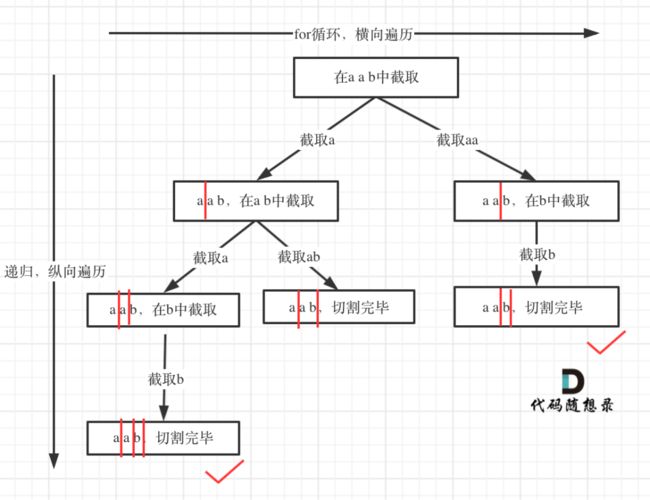
本题是挺难的呢~
- 难点一:切割问题如何抽象为组合问题
- 难点二:如何模拟那些切割线(组合直接放进path,但切割需要通过下标,来对字符串进行分割)
- 难点三:切割问题中的递归如何终止,是要靠传入的 startIndex下标来完成对终止条件的判断
- 难点四:在递归中如何截取子串,通过下标
- 难点五:如何判断回文串,双指针法,一个从前往后,一个从后往前,判断指向的元素是否相等
// 截取的过程,真的没有想到哇~边截取,边判断是否为回文串
if(isPalindrome(s, startIndex, i))
{
// 获取区间内的子串是回文串,则截取这段子串放进 path 中
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
}
debug 报错超时的查错思路:
1、一般大规模用例的话,那就是代码写的不够精简,用时比较就
2、一般小规模用例的话,那一定就是代码有bug,一般在while循环中找错误,这种通常在while循环中会犯错
3、如果是有递归太深的话,会报错 stack overflow 栈溢出
第46题 全排列
处理排列问题是需要一个 used 数组,就不需要 startIndex ,这个used数组是用来记录是否用过这个元素
取的是叶子节点。
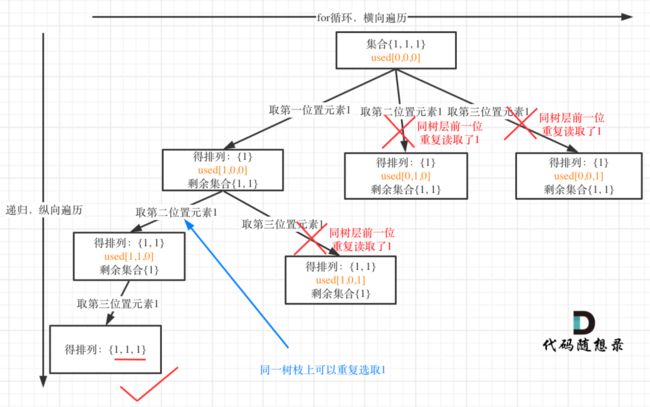
第47题 全排列V2
used[i-1] == true 说明同一树枝 nums[i-1] 使用过
used[i-1] == false 说明同一树层 nums[i-1] 使用过
如果同一树层 nums[i-1] 使用过,则直接跳过
这里used[i-1] == true 或者used[i-1] == false 都是可以通过的
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!
树层上对前一位去重非常彻底,效率很高,
树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索
used[i-1] == false 树层去重的树形结构
used[i-1] == true 树枝去重的树形结构
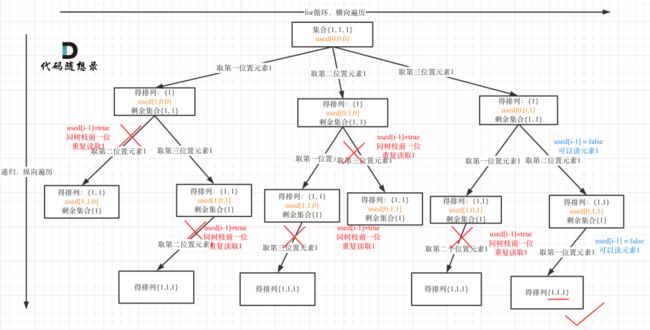
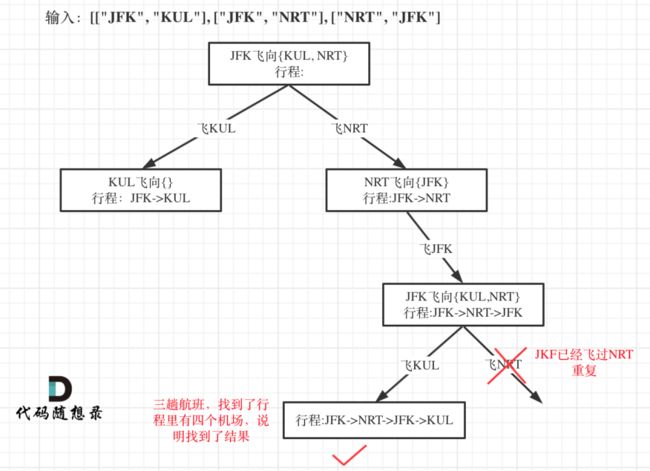
第332题 重新安排行程
题解思路:
1、有点类似于 图论中的深度优先搜索 dfs
2、的确是有用到深搜,在查找路径的时候,也有用到回溯,因为找路径嘛,不回溯怎么找路径呢?
其实深搜一般也都是用回溯法的思路。
难点:
1、一个行程中,如果航班处理不好,有可能成为一个圈,变成死循环 (一张机票不是只能用一张嘛,用完一张弃之应该就可以了吧)
2、要求按字母排序 取得最终的结果,思考该怎么记录映射关系呢 (母鸡哦~)
答:按字母排序,就可以用 std::map 或者std::set 或者 std::multimap
3、使用回溯法,那么终止条件是什么呢? (每张机票都使用一遍吗?)
4、搜索的过程中,如何遍历一个机场所对应的所有机场呢? (也是母鸡的)
答:一个机场映射多个机场,可以用 map ,注意 std::unordered_map 效率相对是高的
剖析:
1、这道题是第一次用 关联容器 嵌套一个 关联容器 ,可以有两种选择,
// 但是这个有一个缺点,当使用set容器来存储时,一旦删除其中的元素,迭代器就会失效。。。为什么要删除呢?因为用过的机票不删除的话,可能会出现死循环
unordered_map> targets // 含义::unordered_map<出发机场,到达机场的集合>
// 使用map来存储多个机场的集合,用 “航班次数” int值 来标记是否使用过这个机场,就无需对集合做删除或者增加元素的操作
unordered_map> targets // 含义::unordered_map<出发机场, 航班次数>
2、通常说回溯函数的返回值类型都是 void ,这道题把递归函数设定为 bool ,
因为只需要找到一条符合条件的行程即可返回,无需遍历全部,所以找到一个符合题意的,也就是一个到达叶子节点的树枝,就控制函数 return
3、终止条件分析
机场个数 等于 机票个数+1,就说明找到了一个行程,把整条航班串起来了。
4、单层递归逻辑
可以说本题是需要找到一个数据进行排序的容器,而且还要容易增删元素,且迭代器还不能失效
5、这道题真的不简单哦~
其实,感觉,很大程度上,难是因为对容器的操作并不是很熟练,看到这种容器的嵌套,就觉得恐惧,但是~~不要怂!冲冲冲!!!~ 先看会,再写对!
map容器嵌套一个map容器的用法,很妙,但是很难想得到,可太难了~
不过理解了一个点,其实一个关联容器,也就是哈希映射,就把它理解为数组,对于set容器也是一样的理解,
数组的下标就是 key,数组中存放的元素就是 value
map 的 key 根据选择的容器类型不同,可以是有序或者无序,map 的 value 就是对应着 key 的一个元素
set 的 key 根据选择的容器类型不同,可以是有序或者无序,
这里再复习一下

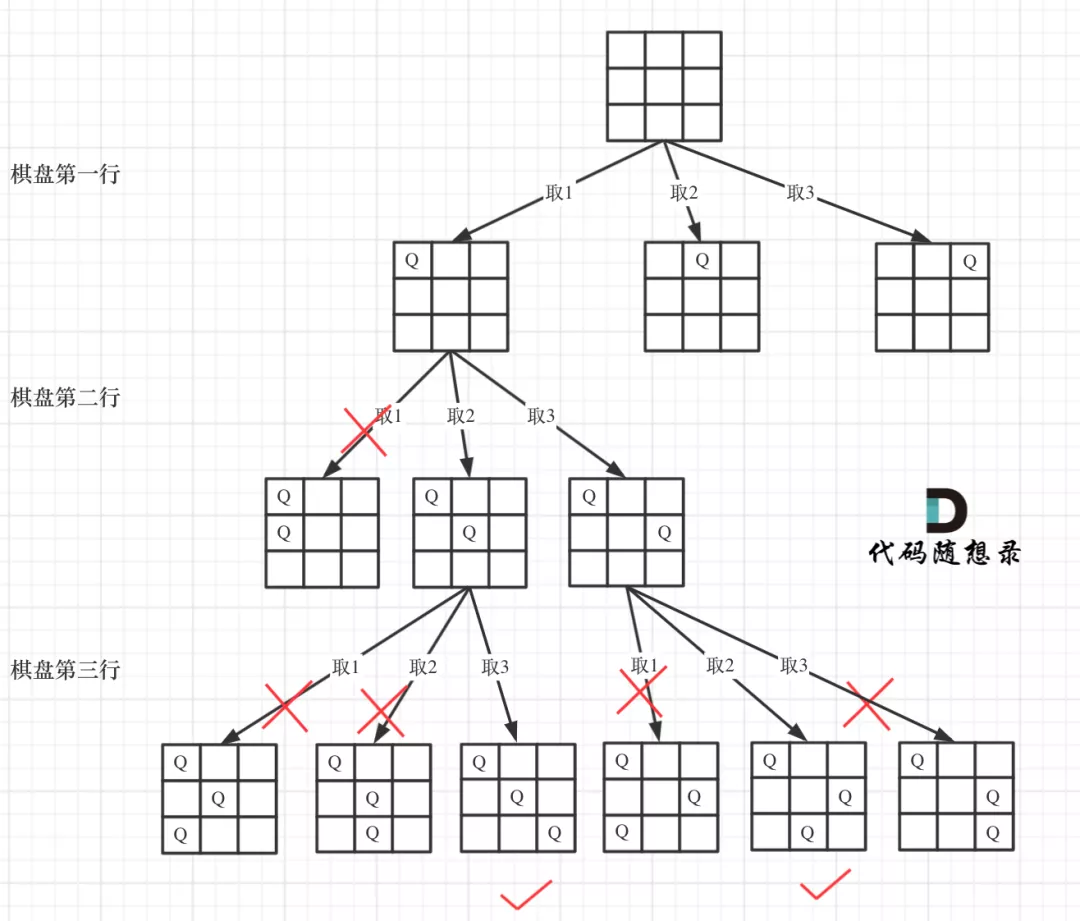
第51题 棋盘问题–N皇后
N皇后问题是回溯算法解决的经典问题,同上一题相似,又是用到二维矩阵。
首先,先理清 皇后们 的约束条件:
1、不能同行
2、不能同列
3、不能同斜线
把整个棋盘初始化为一个 N * N 的点点组成的矩阵,找到合法位置就将其覆盖为 Q 代表把皇后放置在那里
// 这里的初始化属于打死我也想不到的,一个一维的 vector 容器,硬生生初始化为一个二维方阵,很妙,但是我想不到哇
vector chessboard = (n, string(n, '.'))
第37题 解数独
数独的规则:
1、定数独 永远是 9*9 的形式
2、给定的数独序列只包含数字 1-9 和 ’ . ’ ( ’ . '表示空白格 )
3、可以假设给定的数独只有唯一解
4、游戏规则: 同行同列不可重复,且每一个以粗实线分隔的3*3的宫内只能出现一次,
数独问题 需要用 二维递归 的回溯暴力搜索,之前做的题目都是一维递归,包括N皇后,因为N皇后虽然是一个矩阵,但是它每一行每一列只放一个皇后,
只需要一层 for 循环遍历一行,递归来遍历列,然后一行一列来确定皇后的唯一位置。
数独的棋盘中,每一个位置都要放置一个数字,并且检查数字是否合法,解数独的树形结构要比N皇后的更宽更深。
回溯三部曲:
- 1、递归函数以及参数
- 递归函数的返回值需要是 bool 类型,因为解数独找到一个符合的条件就可以立即返回,相当于找到从根节点到叶子节点的一条路径。
- 2、递归终止条件
- 无需终止条件,因为解数独需要遍历整个树形结构,寻找可能的叶子节点,就立即返回。
- 分析一下,没有终止条件,要么就是不符合条件继续往下或者往右搜索,要么就是填满了整个棋盘,这时候就表明正好是符合我们的预期,就是我们要的结果咯~
- 3、递归单层搜索逻辑