Flink:从业务实践角度聊聊Checkpoint、Savepoint、容错机制和业务升级
接着状态缓存和内存管理后,再聊聊容错机制
上文:Flink:从业务实践角度聊聊状态缓存和内存管理
多说一句,说实话个人之前研究这部分内容时,有时也会百度,但是很烦的就是,不知道是搜索引擎问题还是大家都喜欢粘贴复制,,,,粘贴复制也就算了,标题好歹统一下吧,可是可是,明明就是找别人的文章粘贴复制的或者直接官网文档粘贴复制,甚至连格式错别字都不管不顾,,,标题好像很牛皮,点进去,文档内容一样,再点下一个,内容一样,再点,还一样,,,搜出来的前几页的,文章标题有点区别,但是居然内容一摸一样,都是官方文档的内容,相似度200%铁证,,,,吐槽下搜索引擎,都2022年了,没点过滤去重机制吗!!再吐槽下,明明就是copy别人或者官方文档的一字不差的没点自己理解的,还偏要加点自己理解的标题。。。。标题党
说实话,copy借鉴没啥问题,但是有点自己的见解才好点,至少你搞点自己测试代码或者自己理解呀,我都怀疑你是不是正真看完过整篇内容(如有不适,见谅,主要是搜索引擎的锅!)
主要是真正要查资料时,看到连续几页的一摸一样的内容,真的是想把搜索给干掉,,,这不浪费我时间吗
本文基于V1.11
Flink实现Exactly-once
从flink实现exactly-once一致性语义逐步聊到容错机制
这是一个经典面试问题,基本流计算必问,而且必须得答好。
首先,Flink编程模型:source–>operator–>sink
那么就得满足全链路的Exactly-once
-
Source端(Kafka、Pulsar):状态缓存记录offset --> checkpoint时把offset提交保存到状态后端并同时Commit给Source如Kafka(此时不管job是否真的处理完这几条commit的数据,Kafka已经当作已经处理完了)–> 重启任务时,可以从状态中获取到offset,然后从对应offset重新消费数据
-
Operator:算子依靠状态缓存,中间计算结果都在状态数据里,并checkpoint保存到了状态后端,所以重启任务时,可以从状态后端中读取当时的中间计算结果,重新恢复计算状态
-
Sink:由于Source端有重置到状态缓存记录的Offset,所以会存在部分数据重复计算,所以需要Sink的存储支持幂等或事务即可实现。一般的存储如HBase、Mysql等都支持,那么Kafka呢?Kafka也支持幂等和事务(0.11及以后版本),Kafka实现Exactly-Once主要依赖事务,并且通过2PC(two phase commit)两阶段提交方式实现
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
- jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了。
核心一点,未提交的数据不能够被下游消费,下游消费者要有个事务隔离级别参数:read_committed
以上就是Flink实现exactly-once的简述了,如上可知,实现exactly-once有个不可或缺的过程:状态缓存–checkpoint–状态后端
关于状态缓存和状态后端已经在上文中聊过了,那么就接着聊checkpoint
Flink的Checkpoint和Savepoint
面试必问,实践中也及其重要的东西. 而且Checkpoint和Savepoint都是一起出现的,所以一起聊
官方文档位置:Checkpoints
几个小结(教科书式的讲解请参考官方文档)
-
Savepoint是手动的Checkpoint
-
RocksDB状态后端时,Checkpoint可以增量,Savepoint不可以
-
任务手动可以指定从Savepoint和Checkpoint启动,任务自动重启只会从最近一次Checkpoint启动
-
Checkpoint的目的是把数据快照(状态、Offset)保存到状态后端,注意,RocksDB的状态后端,checkpoint也是将RocksDB本地数据保存到配置的文件系统目录下
Flink的Checkpoint与Kafka Offset提交配置
关于开启checkpoint:https://www.bookstack.cn/read/flink-1.11.1-zh/8c2c9d36457a28b4.md
-
Kafka的offset提交有三种情况(开启了checkpoint后,KafkaSource的offset提交方式配置就失效,此时在kafkaSouce处设置提交方式)
-
开启checkpoint时:在checkpoint完成后提交(FlinkKafkaConsumerBase.notifyCheckpointComplete)
-
开启 checkpoint,禁用 checkpoint 提交:不依靠Flink提交,需要手动提交
-
不开启 checkpoint,依赖KafkaSouce配置自动提交或者手动提交
Properties properties = new Properties(); properties.setProperty("bootstrap.servers","192.168.31.201:9092"); properties.setProperty("group.id", "consumer-group"); properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty("auto.offset.reset", "latest"); properties.setProperty("enable.auto.commit", "true"); FlinkKafkaConsumer011<String> consumer = new FlinkKafkaConsumer011<>("sensor", new SimpleStringSchema(), properties); // 若开启了checkpoint,那properties中的enable.auto.commit参数就会失效 consumer.setCommitOffsetsOnCheckpoints(true);
-
-
默认情况,checkpoint是禁用的,但是有状态的编程是一定要开启的
如下是官方文档中的示例代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 每 1000ms 开始一次 checkpoint env.enableCheckpointing(1000); // 高级选项: // 设置模式为精确一次 (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 开启在 job 中止后仍然保留的 externalized checkpoints env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 允许在有更近 savepoint 时回退到 checkpoint env.getCheckpointConfig().setPreferCheckpointForRecovery(true);Flink的Checkpoint过程与配置
有如下几个重要的配置,在图中描述
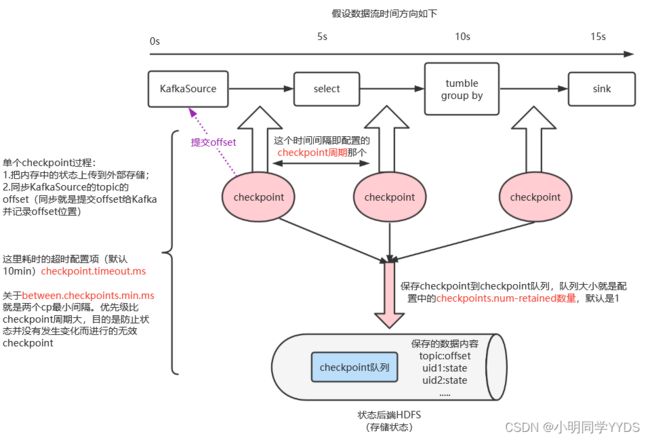
checkpoint详细配置项参看上述给的文档里的说明,这里聊聊业务实践过程中如何配置
首先几个配置参考原则
-
1.checkpoint不宜过于频繁,因为它的目的是记录状态,如果间隔太小,可能一段时间内状态并没有发生变化,会无意义浪费资源,影响性能
-
2.checkpoint目的是保存状态和offset,状态过大会导致checkpoint耗时过长,占用网络IO
-
3.状态大小跟业务的窗口大小,吞吐量,以及无窗口groupby和regular join(与时间间隔无关的join)配置的min和max保留时长有关
几个重要配置项的配置思路参考(其他配置项请参考官方文档按需配置)
-
1.checkpoint周期:不宜频繁,一般在分钟级别,1~10分钟,不建议超过10分钟。出于的考虑是:如果任务失败(没有savepoint),重新恢复任务肯定只能从checkpoint恢复,那么周期越短,需要重新处理的数据越少,实时性恢复的越快。
-
2.耗时超时配置项checkpoint.timeout.ms:一般不动,至少大于checkpoint周期,可配置为最大能接受checkpoint周期间隔即可,默认是10分钟
-
3.between.checkpoints.min.ms:是两个cp最小间隔,目的是防止checkpoint积压:由于状态过大导致checkpoint耗时很长,上一个还没结束,下一个就已经开始这样积压起来。
-
4.checkpoints.num-retained:checkpoint保留数,默认值1.如果希望任务失败时可以重跑更长时间的数据,那么可以根据需要增加此保留数,无非是增加磁盘存储
-
5.其中还有个:任务取消后保留Checkpoint目录:这个涉及checkpoint保留策略,生产上按需设置,个人建议是取消作业仍然保留检查点:业务升级时如果改动了算子逻辑,需要重跑一段时间数据时可以指定从前几个checkpoint重启;但是要注意手动清理,尤其配置保留多个checkpoint时,会占用磁盘空间,savepoint同理
CheckpointConfig config = env.getCheckpointConfig(); // ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION: 取消作业时保留检查点。请注意,在这种情况下,您必须在取消后手动清理检查点状态。 // ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 取消作业时删除检查点。只有在作业失败时,检查点状态才可用。 config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); -
较为详细的有参考价值的配置示例代码,其中8项都是比较重要的配置项,文章原文:Flink DataStream Checkpoint和Savepoint
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); CheckpointConfig checkpointConfig = env.getCheckpointConfig(); // 1、开启Checkpoint // 默认情况下,不开启Checkpoint // 设置Checkpoint间隔(单位毫秒)大于0,即开启Checkpoint // 如果State比较大,建议增大该值 checkpointConfig.setCheckpointInterval(10L * 1000); // 2、设置Checkpoint状态管理器 // 默认MemoryStateBackend 支持MemoryStateBackend、FsStateBackend、RocksDBStateBackend三种 // MemoryStateBackend: 基于内存的状态管理器,状态存储在JVM堆内存中。一般不应用于生产。 // FsStateBackend: 基于文件系统的状态管理器,文件系统可以是本地文件系统,或者是HDFS分布式文件系统。 // RocksDBStateBackend: 基于RocksDB的状态管理器,需要引入相关依赖才可使用。 // true: 是否异步 env.setStateBackend((StateBackend) new FsStateBackend("CheckpointDir", true)); // 3、设置Checkpoint语义 // EXACTLY_ONCE: 准确一次,结果不丢不重 // AT_LEAST_ONCE: 至少一次,结果可能会重复 // 注意: 如果要实现端到端的准确一次性语义(End-To-End EXACTLY_ONCE),除了这里设置EXACTLY_ONCE语义外,也需要Source和Sink支持EXACTLY_ONCE checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 4、任务取消后保留Checkpoint策略 checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 5、设置要保留的Checkpoint数量 // 在conf/flink-conf.yaml中设置 // 默认是1,只保留最新的一份Checkpoint // 如果需要从历史某个时刻恢复,这个参数很有用,可以根据Checkpoint间隔,设置成多个 state.checkpoints.num-retained=20 // 6、设置Checkpoint超时时间 // Checkpoint超时时间,默认10分钟。当Checkpoint执行时间超过该值,Flink会丢弃此次Checkpoint并标记为失败,可从Flink WebUI Checkpoints上看到 checkpointConfig.setCheckpointTimeout(long checkpointTimeout); // 7、设置Checkpoint之间的最小间隔 // 两次Checkpoint之间的最小间隔,默认是0,单位毫秒。State太大,Checkpoint时间太长,而间隔又很短,则会导致大量Checkpoint任务积压,占用大量计算资源,进而影响任务性能 checkpointConfig.setMinPauseBetweenCheckpoints(30000); // 8、设置同一时间点最多进行Checkpoint的数量,默认是1个 checkpointConfig.setMaxConcurrentCheckpoints(1);flink-conf.yaml全局配置// 设置 checkpoint全局设置保存点 state.checkpoints.dir: hdfs:///checkpoints/ // 设置checkpoint 默认保留 数量 state.checkpoints.num-retained: 20
来,官网文档的checkpoint调优思路:大状态与 Checkpoint 调优
- 监控状态和checkpoint是通过UI界面,很清晰哈
- 调优:两个checkpoint之间的最小间隔设置要合理,别叠加和累积checkpoint任务在那里
- 大状态建议用RocksDB
- RocksDB的性能跟调优有关:超大状态时开启增量检查点、手动配置RocksDB的各个配置项(这个个人不专业,就不展开了,文档中有链接指导如何调整,不过实际业务中如果没有特别优化RocksDB的需求,一般不会去手动单个RocksDB参数调整,早期版本RocksDB参数是开放了,现在是默认关闭的,统一配置个托管内存而后Flink内部有比较通用的RocksDB参数使用)
- 关于容量的预设:这个文档中是一大堆讲述合适容量对任务的必要性,业务实践中就是多给一些资源,一是出现某个TM失败时,有富余的TM立即启动去接替;一是适应高峰期。重点还是实时性的保证,如果任务对实时性没过多要求,那么只要做好监控和配置重启计划(这些得监控平台或者跟运维去计划好)即可。越是实时性要求高,越是资源冗余要求多点。并且TableAPI和SQL对于资源使用目前就是无法精细化的,就是冗余的(部分牛皮团队正二次开发意图优化这些,可以关注下每年的Flink-Forward Asia大会 )。
- 快照压缩,正在持续优化中(我们实际业务正在探索),各位可以试试
- 配置状态本地恢复
state.backend.local-recoveryorCheckpointingOptions.LOCAL_RECOVERY,这项文档中很大篇幅描述了原因和操作思路,就是状态特别大的时候,从网络上加载状态很慢,会影响恢复时间,影响实时性,解决方法就是在本地也保存一份状态,恢复时读本地的
Flink的Savepoint过程与应用
Savepoint一定是手动停止任务时生成,也需要手动清理,作用仍然是保存任务快照,方便重启时从上一次计算时间点开始连续的继续计算
先上官方文档关于savepoint位置(有关于详细的savepoint操作示例和用法,之前也查过百度的关于savepoint资料,大部分文章都是copy或者照抄官方文档内容,说明官方文档信息很足):Savepoints
几个业务实践上的注意点
- Savepoint就是一陀文件,可以移动位置,但,一定要JM和TM可访问并且配置好路径
- 任何一个任务都可以使用任何一个Savepoint去启动,无论是不是第一次启动,只是不一定能成功从Savepoint恢复里面的状态数据,如果任务的Source一致,那么即使状态数据不能恢复,也可以拿到对应的Offset接续着进行数据处理,checkpoint同理,只是只要是状态数据不能恢复,那么启动会报错,报错信息会提示你需要加个参数
--allowNonRestoredState或-n,意思是忽略掉不能恢复的状态 - Savepoint不会自动清理,需要手动清理策略
- 业务实践中基本都会配置停止任务自动保存一个Savepoint
- Savepoint正常启停不会有啥问题,往往在业务升级时会出问题:状态不可用、offset不能恢复等等,后面章节深入聊这部分
Flink的容错机制
Flink一个很亮眼的功能就是容错机制,加上它的分布式扩展特点,Flink+ML也是逐步的在业界探索中
容错容错,就是允许你发生错误,并能够自动恢复。Flink的容错依赖的是Checkpoint和Savepoint。自动恢复依赖的是Checkpoint,发生错误导致任务失败时会根据重启策略进行尝试重启。需要手动重启时就用到Savepoint或指定Checkpoint进行重启
来,上文档位置:Task 故障恢复
重启策略(Restart Strategy):flink-conf.yaml或通过ExecutionEnvironment对象调用setRestartStrategy配置
-
固定延时重启策略:固定N次尝试重启,每次间隔一定延时时间,超过次数则失败
restart-strategy.fixed-delay.attempts: 3 restart-strategy.fixed-delay.delay: 10 sExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3, // 尝试重启的次数 Time.of(10, TimeUnit.SECONDS) // 延时 )); -
失败率重启策略:固定时间内,失败超过多少次就认定失败
restart-strategy.failure-rate.max-failures-per-interval: 3 restart-strategy.failure-rate.failure-rate-interval: 5 min restart-strategy.failure-rate.delay: 10 sExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.failureRateRestart( 3, // 每个时间间隔的最大故障次数 Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔 Time.of(10, TimeUnit.SECONDS) // 延时 )); -
直接失败不重启
restart-strategy: noneExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.noRestart()); -
备用重启策略(Fallback Restart Strategy):使用集群定义的重启策略,也就是启用了checkpoint但是你又没配置其他重启策略,那么集群默认使用固定延时重启策略,并尝试Integer.MAX_VALUE次重启
-
以上其实是3种,业务实践上建议配置固定延时重启策略或者失败率重启策略,不要一点都不配置。
-
以上Flink内部的重启策略,仍然可能失败,业务实践上建议配合运维系统定义好Flink外部的监控报警和调度重启机制,避免意外
-
流计算是一直无限的运行的,所以一定要监控好日志和Metric,如果运维强大可以配合制定好闲时重启机制的策略,如果有和外部系统交互的比如Kafka、Redis、Hbase等,也要做好相应的读写监控,尤其Kafka的流量峰值、Redis和Hbase的QPS等(个人业务实践时,维表使用的HBase,高峰流量时,HBase压力巨大(这个优化后面开文章好好聊,细节很多),曾一度拒绝FlinkJob链接或间断性的读数据慢的异常情况,导致Flink任务背压和挂掉并且自动重启失败,此时挂掉就依赖外部的重启机制了)。
恢复策略(Failover Strategies):flink-conf.yaml中配置jobmanager.execution.failover-strategy,配置值说明如下:
- 全图重启:full:job的所有task全部重启
- 基于 Region 的局部重启:region:job的所有task会被flink内部根据某种逻辑依赖,划分成一个个逻辑上的region,当有task故障时,会把task所在的region和下游的region进行重启,如果有依赖上游数据流,则关联的region也会被重启,目的是保证数据一致性。这种形式
业务实践中如何选择呢,一般会优先配置为region,保证实时性,快速恢复处理数据。本地测试时可以full
Flink的状态机制与业务升级
这个话题,个人见解,有不严谨的地方,请指出,可以多加讨论,适用于业务
任务临时暂停,然后重启继续运行,这基本不会有啥问题,很顺畅。但是,比如生产上报错了或者需求更新,我得改,改了业务逻辑,再上线,会不会和checkpoint或者savepoint冲突不兼容?肯定的,那咋搞,怎么解决?
来,贴文档:Savepoints
DataStreamAPI
如果是DataStreamAPI开发的话,一定记得每个算子都设置一个OperatorID,文档里也是强烈建议。
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID
-
这个OperatorID,也叫UID,有啥讲究呢,没啥讲究。随便给个唯一值就行,但不能改。为啥?有用
-
还记得状态缓存吗,有状态的编程,状态数据在checkpoint或者savepoint后存在状态后端里,那重启时,状态数据怎么给到对应算子呢,到这里肯定就有思路了,就是根据uid给,存的时候也会与uid有个mapping关系。
-
所以uid一定要设置。如果不设置那怎么状态恢复给对应算子呢?你不设置,系统自动帮你生成一个,而且是根据flink运行的DAG图关系和其他一些信息组合起来生成一个hash值。所以你不动程序,直接重启,肯定能恢复。但是如果动了,导致DAG图也改了,那必然hash值会改,那么所有状态都无法恢复了。。。直接GG
-
设置了uid,但是状态数据结构改了咋办?也会恢复失败,但是你可以先保留旧的数据结构,然后开新的数据结构用来兼容过渡就可以解决这个问题。所以说,DataStreamAPI不存在无法恢复状态问题,只要好好设计uid,然后兼容好状态的数据结构即可。
TableAPI&SQL
坑就在这里,流批一体流批一体,重SQL的使用。Flink迅速火热,各个大厂都构建自己的FlinkSQL开发平台,实现了几乎不用一行代码,纯SQL,就能解决大部分场景需求。SQL开发迅速易上手,大大提升业务开发效率,这也是Flink后起之秀越来越代替Storm和SparkStreaming的原因。未来SQL肯定会越来越成熟和覆盖更多业务场景的开发(部分场景SQL可能无法处理或者很复杂所以还是会DataStreamAPI去搞),所以,未来Flink的使用,尤其流批一体的架构设计,SQL必须的熟悉使用!
上文说到uid解决状态恢复对应关系,TableAPI和SQL却无法手动设置uid,只能依靠自动生成,所以业务更新升级就无法避免会有状态无法恢复的情况
如下情况肯定可以恢复状态
- 有状态的计算里增加where条件
- 无状态的计算里可以随便改动
如下情况肯定无法恢复状态
-
增减sql流程:比如额外加个sql3,无论sql3是否是有状态的计算,因为算子的执行图会作为uid生成的一部分
-
有状态的计算里对group by或者聚合指标做了更改:你分组key(group by)都改了或者状态数据结构(聚合指标,比如增加个sum)都改了,肯定无法恢复。不过这种情况只有这个算子无法恢复,但是它无法恢复,是不是最终结果会被影响呢。。。。对吧
比较重要的一点:状态无法恢复,但是offset可以恢复,只要topic没变
补充下小结:
(1)每个算子都有个uid
(2)savepoint保存的是当前的offset和各个算子对应的state
(3)DataStreamAPI可手动设置算子uid,进行精细化管理state和savepoint恢复
(4)TableAPI&SQL不可以手动设置uid,系统自动生成
(5)uid生成跟jobDAG等等有关,故新增、删除节点都会重新分配
(6)新增、删除SQL节点时,DAG里所有节点都会重新分配uid,savepoint里的state无法恢复,需加参数 --allowNonRestoredState (忽略不能映射到uid的state),Job方可重新启动
(7)修改有状态的计算SQL节点,只要不改group by相关计算,就可以正常从Savepoint恢复,否则状态恢复失败,需加参数 --allowNonRestoredState可忽略失败的状态是的算子继续启动
(8)修改无状态的计算SQL节点,无影响
(9)关于状态能不能恢复总结下:改了DAG必然无法恢复,原因是uid对应不上了;改了有状态计算的状态key(group by部分)和value的数据结构(sum、count这些)部分,只该节点状态无法恢复,不影响其他节点恢复情况。原因是uid能对上,但是新旧状态数据结构不一样导致无法恢复。
(10)只要必须加–allowNonRestoredState才能启动时,一定是存在部分或所有的节点状态不能恢复,可以用这点去检测是否会状态恢复失败
咋个解决呢?下面列举下可行的方案,因业务场景和实时性要求而做不同选择
-
(1)长窗口或累计计算等情况,第三方存储保存中间结果【部分场景可以解决】
-
(2)从较早checkpoint开始启动,允许状态恢复失败,但可以重复跑一段时间段数据来保证不丢失,需要下游支持幂等【推荐】
-
(3)流批混跑(流负责实时+批闲时替换流实时或批闲时重跑),批兜底【T+1报表之类的可以考虑:资源冗余、需要实现流批一体否则两套代码】
-
(4)闲时升级【推荐:重实时性、重数据准确或一致性】
-
(5)由于流计算实时性特点,部分业务实时准确性在升级逻辑时确实难以保证,与下游业务方沟通告知,且保证能接续offset继续计算。【推荐:重实时性、轻数据准确或一致性】
-
(6)重点逻辑DataStreamAPI开发并设置uid来保证此逻辑节点的状态恢复【重实时性、轻数据准确或一致性、但是难以预测业务的变更】

以上,个人愚见,若有表述错误的,还请指出,避免误导!