Hadoop学习总结(搭建Hadoop集群(伪分布式模式))
如果前面有搭建过Hadoop集群完全分布式模式,现在搭建Hadoop伪分布式模式可以选择直接克隆完全分布式模式中的主节点(hadoop001)。以下是在搭建过完全分布式模式下的Hadoop集群的情况进行
伪分布式模式下的Hadoop功能与完全分布式模式下的Hadoop功能相同。
一、克隆主节点为hadoop0
对完全分布式模式下的Hadoop集群主节点(hadoop001)进行克隆



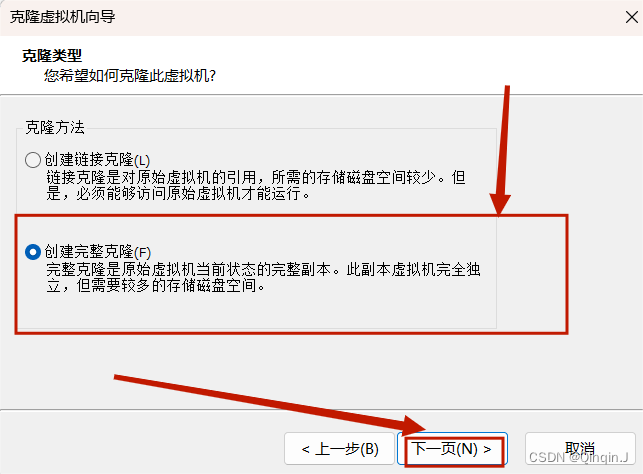

点击完成后等待克隆

克隆完毕
二、修改主机名和hosts、宿主电脑的hosts
IP不用修改,还是使用hadoop001的IP,所以可以使用远程连接工具(Xshell或者SecurityCRT)进行修改
1、修改主机名为hadoop0
vi /etc/hostname
2、修改主机hosts
vi /etc/hosts
修改完成后进行重启,可以看到主机名为hadoop0

3、修改宿主机的hosts
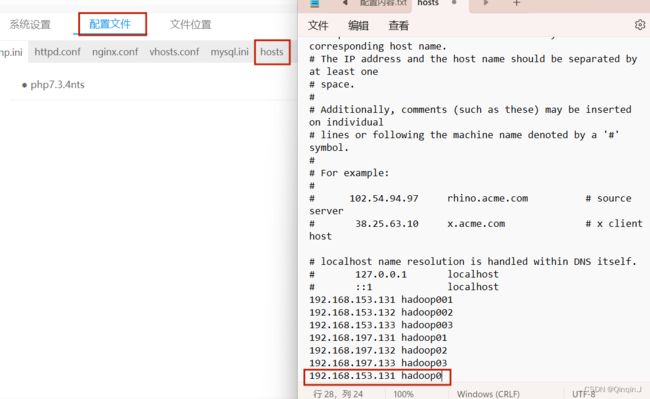
通过win+R进入命令提示符页面,然后ping通虚拟机

三、重做免密登录
使用远程连接工具(Xshell或者SecurityCRT)
因为是通过对完全分布式模式下的Hadoop集群主节点(hadoop001)克隆的hadoop0,原来已经进行过免密登录了,可以删除原来生成的密钥重新生成新密钥再进行发密钥

以下删除原来生成的密钥重新生成新密钥再进行发密钥
删除原来的密钥
rm -rf .ssh
重新生成密钥
ssh-keygen -t rsa一直回车

查看

进入 .ssh
cd .ssh发密钥:ssh-copy-id hadoop0
ssh-copy-id hadoop0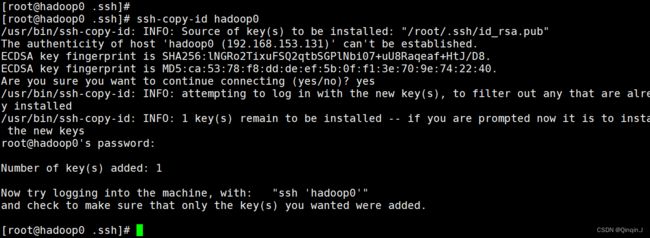
进行查看是否生成
cat authorized_keys
四、修改Hadoop集群节点
进入Hadoop里
cd $HADOOP_HOME/etc/hadoop1、修改 core-site.xml 文件
vi core-site.xml该文件是Hadoop的核心配置文件,其目的是配置 HDFS 地址、端口号,以及临时文件目录。配置文件中配置了 HDFS 的主进程NameNode运行主机(也就是此次Hadoop集群的主节点位置)同时配置了Hadoop运行时生成数据的临时文件。
添加以下内容
fs.defaultFS
hdfs://hadoop0:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.4/data

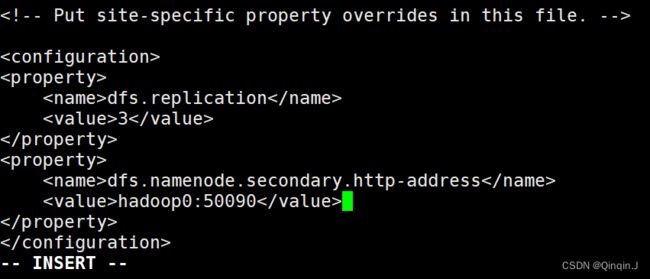
2、修改 hdfs-site.xml 文件
vi hdfs-site.xml 该文件作用于设置 HDFS 的NameNode 和 DataNode 两大进程。
添加以下内容
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop0:50090
3、修改 yarn-site.xml 文件
vi yarn-site.xml本文件是 YARN 框架的核心配置文件,需要指定 YARN 集群的管理者。 在配置文件中配置 YARN 的主进程 ResourceManager 运行主机为hadoop0,同时配置了 NodeManager 运行时的附属服务,需要配置为 mapreduce_shuffle 才能正常运行 MapReduce 默认程序。
添加以下内容
yarn.resourcemanager.hostname
hadoop0
yarn.nodemanager.aux-services
mapreduce_shuffle

4、修改 slaves 文件
vi slaves该文件用于记录 Hadoop 集群所有从节点(HDFS 的 DataNode 和 YARN 的 NodeManager 所在主机)的主机名,用来配合一键启动集群从节点(并且还需要验证关联节点配置了 SSH 免密登录)。打开该配置,先文件删除里面的内容,然后修改为 hadoop0

5、 mapred-site.xml 文件
该文件不需要修改,因为是通过对完全分布式模式下的Hadoop集群主节点(hadoop001)克隆的hadoop0,在搭建hadoop001集群配置文件已经修改过了
五、格式化文件系统
通过 Hadoop 集群的安装和配置。此时还不能直接启动集群,因为在初次启动 HDFS 集群时,必须对主节点进行格式化处理
hdfs namenode -format或者
hadoop namenode -format执行上述任意一条都可以对 Hadoop 集群进行格式化。执行命令后,必须出现有 successfully formatted 信息才表示格式化成功

如果没有出现请检查一下Hadoop 安装和配置文件是否正确 ,如果都正确,则需要删除所有主机的 /hadoop-2.7.4 目录下的 tmp文件夹,重新执行格式化命令,对 Hadoop 集群进行格式化。
注意:格式化只能进行一次,如果多此进行可能会导致服务器运行的java进程不完全
六、启动集群服务
start-all.shjps 进行查看

访问HDFS集群状态 http://hadoop0:50070/(集群服务IP + 端口号)
访问YARN集群状态 http://hadoop0:8088/(集群服务IP + 端口号)

如果集群启动不成功可以去看完全分布式模式的搭建文章,里面有解决办法