Python Day4 爬虫-selenium滚动和常见反爬
Day4 selenium滚动和常见fanpa
文章目录
- Day4 selenium滚动和常见fanpa
-
- 1. zhi网页面数据分析
- 2. 页面滚动
- 3. requests的自动登录
- 4. selenium获取cookie
- 5. selenium使用cookie
- 6. requests使用代理IP
- 7. request使用代理IP实际用法
1. zhi网页面数据分析
'''
Author:KathAmy
Date:2022/8/16 9:15
键盘敲烂,共同进步!
'''
from selenium.webdriver import Chrome
from time import sleep
from bs4 import BeautifulSoup
def analysis_data(html: str): # 分析数据
soup = BeautifulSoup(html, 'lxml')
title = soup.select_one('.wx-tit>h1')
if title:
title = title.text
author = soup.select_one('#authorpart a')
if author:
author = author.text
organization = soup.select_one('.wx-tit>h3:nth-child(3) a')
if organization:
organization = organization.text
print(title)
print(author)
print(organization)
print('-----------------------------------华丽的分割线-----------------------------------')
def get_paper(key_word='数据分析'):
# 1.创建浏览器打开中国知网,输入搜索关键字
global b
b = Chrome()
b.get('https://www.cnki.net/')
b.find_element_by_id('txt_SearchText').send_keys(f'{key_word}\n')
sleep(1)
# 2.获取搜索结果
for x in range(5):
# 获取一页的数据
all_a = b.find_elements_by_css_selector('.result-table-list .name>a')
for a in all_a:
a.click()
sleep(1)
b.switch_to.window(b.window_handles[-1])
analysis_data(b.page_source)
b.close()
b.switch_to.window(b.window_handles[0])
# 点击下一页
print('-----------------------------------第一页数据获取完成-----------------------------------')
b.find_element_by_id('PageNext').click()
sleep(1)
if __name__ == '__main__':
get_paper()
2. 页面滚动
'''
Author:KathAmy
Date:2022/8/16 10:08
键盘敲烂,共同进步!
'''
from time import sleep
from selenium.webdriver import Chrome
from bs4 import BeautifulSoup
b = Chrome()
b.get('https://www.jd.com')
b.find_element_by_id('key').send_keys('键盘\n')
sleep(1)
# 1.执行滚动操作 - 执行js中滚到代码:window.scrollBy(x方向偏移量代表左右滚动,y方向偏移量代表上下滚动)
# b.execute_script('window.scrollBy(0, 700')
for x in range(8000):
b.execute_script('window.scrollBy(0, 1)')
sleep(1)
soup = BeautifulSoup(b.page_source, 'lxml')
goods_li = soup.select('#J_goodsList>ul>li')
print(len(goods_li))
input('关闭:')
b.close()
3. requests的自动登录
自动登录原理:人工在浏览器上完成登录操作,获取登录后的cookie信息(登录信息),再通过代码发送请求的时候携带登录后的cookie
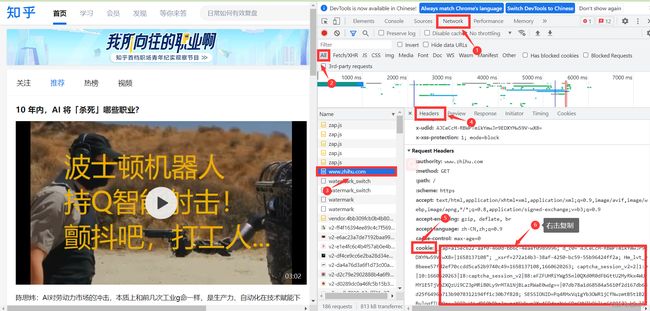
'''
Author:KathAmy
Date:2022/8/16 11:05
键盘敲烂,共同进步!
'''
import requests
URl = 'https://www.zhihu.com'
Headers = {
'cookie': '_zap=a15ec622-aaf0-460d-bb6c-4eaef0989996; d_c0="AJCeCcM-RBWPTmikYmwJr9EDXYMw59V-wX8=|1658137108"; _xsrf=272a14b3-38af-4250-bc59-55b96424ff2a; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1658137108,1660620263; captcha_session_v2=2|1:0|10:1660620263|18:captcha_session_v2|88:eFZFUHRiYWg5Snl0QXd0R0dFbGttU2MyRkx4WUJMY1E5TjVmZXQzUi9CZ3pMRi80Ly9rMTA1NjBLazRWaE0wdg==|07db78a1d68584a5610f2d167db68d25f6496a713b9078312194ff1c30b7f828; SESSIONID=Pq4RMxVq1gYb3OWR1jCfNwzmtB5t1B2zBuloqfIUPQe; JOID=UVwdBE0hBhoJpvzqXSWkwn2Xx4FDdnshWu6DsCMVZk9klLa6A80I72-k9-lT7z7zRGB4GGvyn4R6HOkTWnWpMzw=; osd=UVsSB08hARUKpPztUiamwnqYxINDcXQiWO6EvyAXZkhrl7S6BMIL7W-j-OpR7zn8R2J4H2TxnYR9E-oRWnKmMD4=; __snaker__id=TpKCrf27Kdkvg4DT; gdxidpyhxdE=sLhXT7ecdTbPkCGaH\C6Qvpxi4hs+GezCAsOXuMeSa1H4eXgd8tQLOoa21Q7uf4z\2qHXCh1RYy/B4/55fV99hvx6JYZ7OdLVZue7SPle1xOWc6MBMK0Otz3cV0Rgf/Lz2YDuIREHo9uK3c6zva0lDj93IVnuSK3DHXb0AYo7aguZLZy:1660621164350; _9755xjdesxxd_=32; YD00517437729195:WM_NI=34AU5Ce2ma3vodZaMbp9jEPu9vJ9ZVB52oi9ACHcQmZmJO9Ny49vkT+FEJG3ApWzfGJJH0VyZIaSafjbeNOr29BdRhJKs8gtsuOZ4eJXntKrN+1G9IwduQErC3IS3+pBVmk=; YD00517437729195:WM_NIKE=9ca17ae2e6ffcda170e2e6eeaacc6bf1a9a9d8c461988a8ba2c45e879e8bb0c5508ba8a88be164aa878685f42af0fea7c3b92af1ec8fb6b849a7eea382b27eadbc9682d06ab4e7a6a6d37ffbaa86dad95e82ebfe90ec33839d8884d4679ab386b0bc46bbecf797ea60e99a8babc63983b0999be54d8a9688d1d5739a97afb4e46eaabeabafce7af2e78e85d1648a95bdd9e680b1ab81bbb76f8a88a295ca7a8ef5ffa8bc43b5bcbbb2c87a81ed87b4b221b49e9a8eea37e2a3; YD00517437729195:WM_TID=n4Auv+cpeFZBVFBUEQOQGcl0ibkmddJ+; o_act=login; ref_source=other_https://www.zhihu.com/signin?next=/; expire_in=15551999; z_c0=2|1:0|10:1660620272|4:z_c0|92:Mi4xUGlxZ0V3QUFBQUFBa0o0Snd6NUVGUmNBQUFCZ0FsVk43MXZvWXdEX0xZMzctbnJDRGdPakZIM3JuRE1uaGxPUndR|0b02163e5ed78c015e8c1cbc19f070c5906b9dc9a1db276791c3b5aee47ca839; q_c1=af1638edd82f46c69e45e541c154e75c|1660620272000|1660620272000; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1660620274; tst=r; NOT_UNREGISTER_WAITING=1; KLBRSID=b5ffb4aa1a842930a6f64d0a8f93e9bf|1660620325|1660620262',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
response = requests.get(url=URl, headers=Headers)
print(response.text)
4. selenium获取cookie
'''
Author:KathAmy
Date:2022/8/16 11:43
键盘敲烂,共同进步!
'''
from selenium.webdriver import Chrome
from json import dumps
b = Chrome()
# 1.打开需要完后才能自动登录的网站(需要获取cookie的网站)
b.get('https://www.taobao.com/')
# 2.给足够长的时间让人工完成自动登录并且人工刷新出登录后的页面
# 强调:一定要把第一个页面刷新出登录之后的状态
input('已经完成登录:') # 手动操作
# 3.获取登录后的cookie并且将获取到的cookie保存到本地文件
cookies = b.get_cookies()
print(cookies)
with open('taobao.txt', 'w', encoding='utf-8') as f:
f.write(dumps(cookies))
5. selenium使用cookie
'''
Author:KathAmy
Date:2022/8/16 11:43
键盘敲烂,共同进步!
'''
from selenium.webdriver import Chrome
from json import loads
b = Chrome()
# 1.打开需要自动登录的网页
b.get('https://www.taobao.com')
# 2.添加cookie
with open('taobao.txt', encoding='utf-8') as f:
content = f.read()
cookies = loads(content)
for x in cookies:
b.add_cookie(x)
# 3.重新打开需要登录的网页
b.get('https://www.taobao.com')
6. requests使用代理IP
'''
Author:KathAmy
Date:2022/8/16 15:21
键盘敲烂,共同进步!
'''
import requests
# import csv
# from bs4 import BeautifulSoup
URL = 'https://movie.douban.com/top250'
Headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54'
}
proxies = {
'http': '119.7.144.222:4531',
'https': '119.7.144.222:4531'
}
response = requests.get(url=URL, headers=Headers, proxies=proxies)
print(response.text)
7. request使用代理IP实际用法
'''
Author:KathAmy
Date:2022/8/16 17:03
键盘敲烂,共同进步!
'''
import requests
from time import sleep
def get_ip():
url = 'http://d.jghttp.alicloudecs.com/getip?num=1&type=1&pro=&city=0&yys=0&port=11&time=2&ts=0&ys=0&cs=0&lb=4&sb=0&pb=4&mr=1®ions='
while True:
response = requests.get(url)
if response.text[0] == '{':
print('提取IP失败,重试一下吧!')
sleep(1)
continue
return response.text
def get_douban_film():
Headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54'
}
ip = get_ip()
print(ip)
proxies = {
'http': ip,
'https': ip
}
response = requests.get('https://movie.douban.com/top250', headers=Headers, proxies=proxies)
print(response.text)
if __name__ == '__main__':
get_douban_film()