calcite 校验层总结
1、校验的作用
1)完善语义信息
例如在SQL语句中,如果碰到select * 这样的指令,在SQL的语义当中,“*” 指的是取出对应数据源中所有字段的信息,因此就需要根据元数据信息来展开。
2)结合元数据信息来纠偏
例如查询引擎需要查看SQL语句中对应的数据源、函数、字段是否能够根据元数据信息找到。
3)SqlNode->RelNode
在Calcite中,将解析层转换的SqlNode结合元数据信息,转换成RelNode信息。
2、元数据定义
1)Calcite中元数据的基本概念
当前很多单一数据管理系统,只能够支持单一的数据模型。
为了支持多种数据模型,Calcite对不同的数据模型进行组织,以Model(数据模型)、Schema(数据模式)、Table(表)的结构将其管理的数据进行了规约
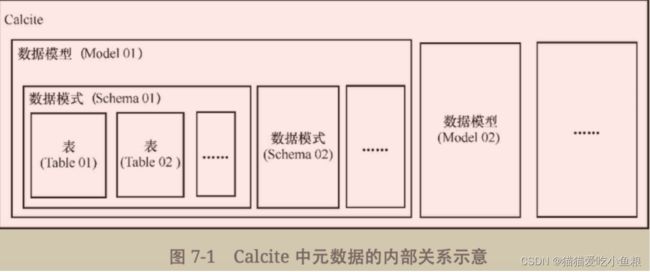
1.Model
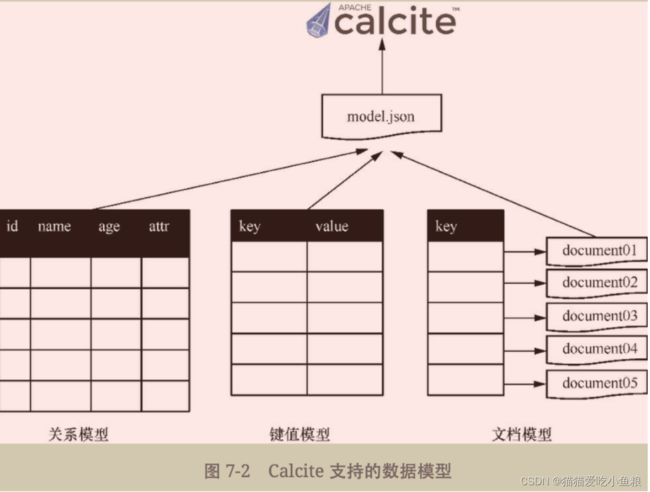
在Calcite当中,Model对应管理的数据模型,主要是关系模型,对部分NoSQL也提供了支持,例如支持键值模型的Cassandra,支持文档模型的MongoDB等。
Calcite支持多种数据模型的注册,将不同模型的数据拉取到内存当中,统一成关系模型,并用统一的函数进行操作,统一呈现给用户。
Calcite目前还不支持图模型以及图数据库:
一方面,图数据库目前还没有业界通用的查询语言,很多时候图数据库都是使用编程的形式来管理的,因此这方面支持的成本会比较高。
另一方面,当前Calcite内部的数据类型以通用的关系数据库的数据类型为主,辅以一些空间数据类型,图数据类型的兼容性较难实现,而且操作图的操作符也与关系代数的数据操作符相差较大。
2.Schema
Schema被定义成描述符的持久命名集合,它包含表、列、数据类型、视图、存储过程、关系、主键、外键等概念。
很多数据库都对Schema进行了拆分,并将Schema与数据库等同。
在Calcite当中,可以建立一个权限Schema,里面包含用户、权限、角色等实体表。
同样,可以用Schema来定义表和函数的命名空间。
为了保证Schema的功能完善和使用灵活,Calcite中的Schema还可以嵌套。
3.Table
在Calcite当中,Table对应的是表的概念,用来存储数据的基本数据结构。
在Calcite当中,其核心采用了关系模型,因此表是关系代数中的表格——由一些约束条件进行约束的二维数组数据集。
4.Function
在Calcite中,Function对应函数的概念。
在关系数据库中,除了关系代数本身对数据的操作方法,函数也是对数据进行操作的重要补充,往往会作为数据库的一个对象,是独立的程序单元。
Calcite支持函数,也支持用户对函数的自定义操作,用户可以用代码实现自定义函数,然后在数据模型配置文件当中注册。
5.数据类型(Type)
在Calcite中,可以自定义数据类型和名称,比如将 VARCHAR(10) 重命名为t_name,那么建表时就可以直接用t_name代表VARCHAR(10)。
2)数据模型定义
在Calcite中,定义数据模型默认采用配置文件的方式,只需要准备一个JSON或者YAML文件,由于JSON和YAML都可以完成参数配置的工作,因此它们之间可以互相转换。
采用以下JSON文件,将其命名为“model.json”,其中定义了3个配置信息,即表示版本号的“version”、表示Schema默认名称的“defaultSchema” 以及表示具体数据模式的“schemas”。
数据模型用JSON文件方式定义的结构 :
{
"version": "1.0",
"defaultSchema": "mongo",
"schemas": [...]
}
数据模型用YAML文件方式定义的结构:
version: 1.0
defaultSchema: mongo
schemas:
-[Schema...]
在这两个配置文件中,重点在Schema的定义上,Calcite定义了3种类型,即MAP、JDBC、CUSTOM,虽然在实现上它们都有统一的接口,但具体的属性有些差别,可以参考Calcite源码 org.apache.calcite.model 包下的实现类。
1.Schema定义分类
a)MAP类型
MAP是默认类型,在一个结构中定义了所有的表、函数和数据类型,MAP的本意是映射,数据模型的定义可以看作各种元数据的映射组合。
MAP类型的定义方式:
{
"name": "MAP_SCHEMA",
"type": "map",
"tables": [...],
"functions": [...],
"types": [...]
}
b)JDBC类型
JDBC 类型的 Schema 是给遵循 JDBC 规范的数据库的特权,这个 Schema 直接对应一个数据库。
而在 JDBC 当中,需要配置下面几个参数:
用于指定数据连接驱动的 “jdbcDriver”
用于指定数据源位置的“jdbcUrl”(这里要根据不同数据源的JDBC规则来进行配置,有一些数据源支持配置多个节点信息)
用于指定用户名和密码的“jdbcUser”和“jdbcPassword”
JDBC类型的定义方式:
{
"name": "JDBC_SCHEMA",
"type": "jdbc",
"jdbcDriver": "com.mysql.jdbc.Driver",
"jdbcUrl": "jdbc:mysql://localhost:3306/db_cdm",
"jdbcUser": "root",
"jdbcPassword": "root123",
}
c)CUSTOM类型
CUSTOM 类型是用来给用户自定义数据源的参数,可扩展、自由度大,使用最广泛。
“factory” 的值对应自己写的 SchemaFactory 工厂接口的实现,表示这是用户自己创建的数据模式;
“operand”是一个映射关系,利用Map这种类型来进行封装,代表用户自定义的参数。
以注册MySQL Schema作为示例,对应的配置信息:
{
"name": "MYSQL",
"type": "custom",
"factory": "cn.com.ptpress.cdm.schema.mysql.MysqlSchemaFactory",
"operand": {
"url": "jdbc:mysql://localhost:3306/db_cdm",
"user": "root",
"pass": "password"
}
}
通过对Schema的定义,完成了对数据库实体的定义,对视图、函数、数据类型这几种实体的元数据同样需要进行指定。
2.视图的元数据定义
在数据库中,视图一般是基于一张或者几张基本表导出的虚拟表,作用是使用户在执行同样的查询逻辑时,不必反复书写同样的查询语句。
视图也可以像表一样查询,所以定义其元数据时也可以采用类似的模板,只是核心是构成视图的SQL语句。
视图的元数据定义示例:
{
"name": "V_SYS_ROLE",
"type": "view",
"sql": " select * from sys_role limit 10",
"modifiable": false
}
其中各个参数的含义如下:
name:视图名称。
type:元数据类型为视图。
sql:构成视图的SQL语句。
modifiable:是否可通过视图修改原始数据,如果设为null或不设置,Calcite会自己推导,不能修改的视图会报错。
3.函数定义
函数在Calcite中是一个非常重要的组成部分,支持用户自行定义函数的方法。
这个过程主要分为两个步骤:定义函数配置文件和定义函数实体类。
定义函数配置文件指用户需要在JSON文件中指定函数的名称“name”、对应实体类的全路径名“className”,以及在实体类内对应的函数名称“methodName”。
“name”和“methodName”不一致,因为“name”是在Calcite元数据体系内的名称,而“methodName”是这个函数调用时采用的函数名称。
"functions": [
{
"name": "my_len",
"className": "cn.com.ptpress.cdm.schema.function.MyFunction",
"methodName": "myLen"
}
]
在定义函数的实体类时,由于Calcite内部会采用动态代码生成技术调用相关的函数,相关的调用逻辑会拼接成字符串动态编译和调用,因此只要能够保证Calcite运行时找得到这个实体类就可以正常调用。
函数实体类的定义示例:
/**
* 自定义函数的实体类
*/
public class MyFunction {
/**
* 计算二进制数中1的个数
*/
public int myLen(int permission) {
int c = 0;
for (; permission > 0; c++) {
permission &= (permission - 1);
}
return c;
}
}
4.数据类型定义
可以在 JSON 文件当中配置 types 来对列及其数据类型进行指定。
指定一个数据类型的属性,名称为“vc”,类型为“varchar”,也为这个数据类型指定了别名——“C”,同时声明了“type”为“boolean”。
在这个配置文件中,同时出现了attributes和type,如果二者出现冲突,最终生效的是type。
数据类型的定义示例:
"types": [
{
"name": "C",
"type": "boolean",
"attributes": [{
"name": "vc",
"type": "varchar"
}
]
}
]
3)自定义表元数据实现
1.Schema 创建
Schema在Calcite中是由对应的实体类定义的,Calcite已经提供了相关的接口——AbstractSchema,只需要实现这个接口和其中的get TableMap方法。
其中 MysqlSchema 继承 AbstractSchema,重写的 getTableMap 方法返回的是一个Map映射,键为表名,值为Table实例,代码中的tables 列表通过构造方法传入。
这种情况是一次性加载所有元数据的情况,如果想要更加灵活地实现Schema,可以直接从接口层开始实现。
Schema的实现:
import cn.com.ptpress.cdm.schema.common.CdmTable;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import org.apache.calcite.schema.impl.AbstractSchema;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
这个类是用来封装MySQL的Schema信息的
*/
@Data
@EqualsAndHashCode(callSuper = true)
@AllArgsConstructor
public class MysqlSchema extends AbstractSchema {
// Schmea名称
private String name;
// Schema下的表
private List tables;
@Override
protected Map getTableMap() {
return tables.stream().collect(Collectors.toMap(CdmTable::getName, t -> t));
}
}
实现对应的工厂类——MysqlSchemaFactory,这个类的主要作用就是基于配置文件传来的参数,构造Schema对象,也就是创建MysqlSchema实例。
Calcite提供了对应的接口——SchemaFactory,只需要实现这个接口并实现它的方法——create即可。
create方法需要获取MySQL的所有表,然后封装到MysqlSchema里,通过直接查询MySQL元数据来获取。
构造Schema对象主要分成4步:
- 根据参数获取连接
- 查询表元数据信息
- 查询每张表的列信息并封装Table信息
- 构造Schema对象并返回
构造Schema对象的具体过程:
import cn.com.ptpress.cdm.schema.common.CdmColumn;
import cn.com.ptpress.cdm.schema.common.CdmTable;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaFactory;
import org.apache.calcite.schema.SchemaPlus;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 构造MySQL的Schema对象的核心方法
* 其中包含3个参数
parentSchema:封装了父级别的Schema信息
name:Schema的信息
operand:从配置文件传来的配置信息,JSON文件中的operand配置
*/
public class MysqlSchemaFactory implements SchemaFactory {
@Override
public Schema create(SchemaPlus parentSchema, String name, Map operand) {
// 1. 根据参数获取链接
try (final Connection conn = DriverManager.getConnection(String.valueOf(operand.get("url")),
String.valueOf(operand.get("user")), String.valueOf(operand.get("pass")))) {
// 2. 查询表元数据信息
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("SHOW TABLES");
// 3. 查询表信息-show tables,查询列信息-desc table
List tables = new ArrayList<>(8);
while (rs.next()) {
final String table = rs.getString(1);
tables.add(new CdmTable(table, getColumns(conn, table)));
}
// 4. 构造 Schema 对象返回
return new MysqlSchema(name, tables);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
// 获取列信息
private List getColumns(Connection conn, String table) throws SQLException {
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("DESC " + table);
List columns = new ArrayList<>();
while (rs.next()) {
columns.add(new CdmColumn(rs.getString("Field"),
typeMap(pureType(rs.getString("Type")))));
}
return columns;
}
/**
* mysql 有的类型和 calcite不一样,需要修改下别名
*/
private String typeMap(String type) {
switch (type.toLowerCase()) {
case "int":
return "integer";
default:
return type;
}
}
/**
* 传入的type含有类型长度,如 bigint(20), varchar(258)
* 需要去掉括号
*/
private String pureType(String type) {
final int i = type.indexOf('(');
return i > 0 ? type.substring(0, i) : type;
}
}
2.表元数据创建
创建Schema下面的表元数据,对表元数据,Calcite也提供了对应的实体——Table,可以继承其子类——AbstractTable,只需要重写其getRowType方法,返回表的字段名和类型映射。
CdmColumn 包含列名和列类型的封装。
需要构造的是RelDataType,可以通过RelDataTypeFactory创建,这里使用SQL类型,此外使用Java类型也可以构造RelDataType。
表元数据的创建示例:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rel.type.RelDataTypeFactory;
import org.apache.calcite.schema.impl.AbstractTable;
import org.apache.calcite.sql.type.SqlTypeName;
import org.apache.calcite.util.Pair;
import java.util.ArrayList;
import java.util.List;
/**
* 表元数据内部信息的实现逻辑
*/
@Data
@EqualsAndHashCode(callSuper = true)
@AllArgsConstructor
@NoArgsConstructor
public class CdmTable extends AbstractTable {
/**
* 表名
*/
private String name;
/**
* 表的列
*/
private List columns;
@Override
public RelDataType getRowType(RelDataTypeFactory typeFactory) {
List names = new ArrayList<>();
List types = new ArrayList<>();
for (CdmColumn c : columns) {
names.add(c.getName());
RelDataType sqlType = typeFactory.createSqlType(SqlTypeName.get(c.getType().toUpperCase()));
types.add(sqlType);
}
return typeFactory.createStructType(Pair.zip(names, types));
}
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.calcite.sql.type.SqlTypeName;
/**
* 列元数据的创建逻辑
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class CdmColumn {
/**
* 列名
*/
private String name;
/**
* 列类型,可以使用calcite扩展的sql类型:{@link SqlTypeName}
*/
private String type;
}
定义好 Table 对象,需要将其和 Schema 关联起来,这一步在定义 MysqlSchema 时已经完成了,而 CdmTable 的构建,是在MysqlSchemaFactory 里完成的。
既然Schema是通过SchemaFactory创建的,为什么Table不是通过TableFactory创建的呢?
对表“sys_role”的内部元数据信息进行定义:
- “name”指定了表名
- “type”指定了表的类型(此处的“custom”同样表示这张表是用户自定义的)
- “factory”指定了封装表内部元数据信息的工厂类的全路径名
- “operand”指定自定义参数,定义了2个参数来指定表内列的元数据信息路径和数据路径。
对表内部的元数据信息进行定义:
{
"name": "sys_role",
"type": "custom",
"factory": "cn.com.ptpress.cdm.schema.csv.CsvTableFactory",
"operand": {
"colPath": "src/main/resources/sys_role/col_type.json",
"dataPath": "src/main/resources/sys_role/data.csv"
}
}
这2个文件很简单,定义表内列的元数据和数据。
定义表内列的元数据和数据:
// col_type.json
[
{
"name": "role",
"type": "varchar"
},
{
"name": "permission",
"type": "integer"
}
]
// data.csv
role,permission
admin,111111
user,000011
nobody,000000
dev,000111
test,001011
CsvTableFactory是表对象创建工厂类,与前述的SchemaFactory类似,Calcite提供的接口是TableFactory,需要实现这个接口,并且实现它的create方法。
这里的执行逻辑主要分为两步:
首先利用JSON解析器来对配置文件中传来的参数进行解析,获取相关的列信息。
然后将这些列信息以及数据信息封装到CsvTable对象中并回传。
import cn.com.ptpress.cdm.schema.common.CdmColumn;
import com.fasterxml.jackson.core.type.TypeReference;
import lombok.SneakyThrows;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.schema.TableFactory;
import java.io.File;
import java.util.List;
import java.util.Map;
import static cn.com.ptpress.cdm.schema.util.JsonUtil.JSON_MAPPER;
/**
* 创建表的工厂类
*/
public class CsvTableFactory implements TableFactory {
/**
* 构造对应的表对象——CsvTable
*/
@Override
@SneakyThrows
public CsvTable create(SchemaPlus schema, String name, Map operand, RelDataType rowType) {
// 1. 获取列信息
final String colTypePath = String.valueOf(operand.get("colPath"));
final List columns = JSON_MAPPER.readValue(new File(colTypePath),
new TypeReference>() {
});
// 2. 将列信息和数据信息封装到CsvTable对象中并回传
return new CsvTable(name, columns, String.valueOf(operand.get("dataPath")));
}
}
CsvTable仅仅是对CdmTable的扩展,dataPath需要保留下来,供后面查询数据使用。
import cn.com.ptpress.cdm.schema.common.CdmColumn;
import cn.com.ptpress.cdm.schema.common.CdmTable;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
import java.util.List;
/**
* CsvTable的扩展实现
*/
@Data
@EqualsAndHashCode(callSuper = true)
@NoArgsConstructor
public class CsvTable extends CdmTable {
/**
* 数据路径
*/
private String dataPath;
/**
* 构造方法
*/
public CsvTable(String name, List columns, String dataPath) {
super(name, columns);
this.dataPath = dataPath;
}
}
4)解析数据模型
创建了model.json文件,也声明了想要的元数据结构,但不知道是否正确,需要检验。
该文件最终会被ModelHandler处理,解析JSON文件只需要使用Jackson反序列化,得到的JsonRoot就是整个数据模型结构。
如果是YAML文件,使用YAMLMapper对象解析即可。
数据模型配置文件解析流程:
// 构建JSON的解析对象
final ObjectMapper JSON_MAPPER = new ObjectMapper()
.configure(JsonParser.Feature.ALLOW_UNQUOTED_FIELD_NAMES, true)
.configure(JsonParser.Feature.ALLOW_SINGLE_QUOTES, true)
.configure(JsonParser.Feature.ALLOW_COMMENTS, true);
// 获取JSON文件的根节点
final JsonRoot jsonRoot =
JSON_MAPPER.readValue(
new File("src/main/resources/model.json"),
JsonRoot.class);
// 输出Schema对象到控制台
System.out.println(jsonRoot.schemas);
将对应的配置传入 Calcite ,在获取连接时,直接将相关的文件传入即可。
在Calcite中传入数据模型配置文件:
DriverManager.getConnection("jdbc:calcite:model=src/main/resources/model.json")
model参数会被解析,后面的值会传入ModelHandler,ModelHandler通过访问者模式解析出Schema、Table等元数据信息,构造出Calcite能够使用的对象,初始化声明的工厂类,创建Schema和Table实例,并将其保存在内存中,供校验器调用。
3、校验流程
1)Calcite校验过程中的核心类
1.SqlOperatorTable
SqlOperatorTable是用来定义查找SQL算子(SqlOperator)和函数的接口,这里的SQL算子是SQL解析树节点的类型,是SqlNode节点的必要组成部分,设定了SqlNode的类型。
它内部设定的查询操作也是与关系代数相关联的,比如描述一个查询节点的算子,名字叫SELECT,参数包括查询的字段、查询的数据源、过滤条件以及数据组织和分析的参数。
2.SqlValidatorCatalogReader
SqlValidatorCatalogReader用来给SqlValidator提供目录(Catalog)信息,也就是获得表、类型和Schema信息,它的实现类为CalciteCatalogReader,是元数据和校验器的连接桥梁。
其初始化过程需要依赖上下文,所以在创建数据连接(Connection)时,会从Connection对象里拿到上下文对象(Context),获取Schema信息,Connection里的Schema信息就来自model.json文件。
3.RelDataTypeFactory
RelDataTypeFactory是处理数据类型的工厂类,它负责SQL类型、Java类型和集合类型的创建和转化。
针对不同的接口形式,Calcite支持SQL和Java两种实现(SqlTypeFactoryImpl和JavaTypeFactoryImpl),当然这里用户可以针对不同的情况自行扩展。
4.SqlValidator
Calcite的校验过程核心对象是SqlValidator,它要承担查询计划的校验过程。
除了要依赖上述的几个核心类对象,还会有本身的配置信息,比如是否允许类型隐式转换、是否展开选择的列,等等。
SqlValidator的构造和工作过程:
// 构造SqlValidator实例
Connection connection = DriverManager.getConnection("jdbc:calcite:model=src/main/resources/model.json");
CalciteServerStatement statement = connection.createStatement().unwrap(CalciteServerStatement.class);
CalcitePrepare.Context prepareContext = statement.createPrepareContext();
SqlTypeFactoryImpl factory = new SqlTypeFactoryImpl(RelDataTypeSystem.DEFAULT);
// SqlValidatorCatalogReader用来给SqlValidator提供目录(Catalog)信息,也就是获得表、类型和Schema信息,
// 它的实现类为CalciteCatalogReader,是元数据和校验器的连接桥梁。
CalciteCatalogReader calciteCatalogReader = new CalciteCatalogReader(
prepareContext.getRootSchema(),
prepareContext.getDefaultSchemaPath(),
factory,
new CalciteConnectionConfigImpl(new Properties()));
final SqlStdOperatorTable instance = SqlStdOperatorTable.instance();
// Calcite的校验过程核心对象是SqlValidator,它要承担查询计划的校验过程。
SqlValidator validator = SqlValidatorUtil.newValidator(SqlOperatorTables.chain(instance, calciteCatalogReader),
calciteCatalogReader, factory, SqlValidator.Config.DEFAULT.withIdentifierExpansion(true));
为了更为直观地展示 SqlValidator 的作用,一条尚未校验的SQL语句,可以看到其中包含多种查询子句,有过滤条件、排序操作等。
其中最重要的是在查询的字段内有一个“ * ”,它表示需要查询“u”表的所有字段。
校验前的SQL语句:
SELECT
'u'.*,
'r'.'permission'
FROM
'MYSQL'.'sys_user' AS 'u',
'CSV'.'sys_role' AS 'r'
WHERE
'u'.'role' = 'r'.'role'
ORDER BY
'id'
校验后得到的SQL语句,最明显的变化就是原先“*”的位置已经被拆解开,将“u”表中所有的字段都展开来看。
除了这个作用,SqlValidator也完成了对所有子句中涉及的库表关系的校验,包括表是否存在、字段是否正确、字段类型是否合法、表的别名是否呼应。
校验后的SQL语句:
SELECT
'u'.'id',
'u'.'user_name',
'u'.'password',
'u'.'is_admin',
'u'.'role',
'u'.'created_date',
'u'.'modified_date',
'r'.'permission'
FROM
'MYSQL'.'sys_user' AS 'u',
'CSV'.'sys_role' AS 'r'
WHERE
'u'.'role' = 'r'.'role'
ORDER BY
'id'
5.作用域
Calcite内的作用域(SqlValidatorScope)指SQL每个子查询的解析范围,可以是解析树中的任何位置或者任何含有列的节点。
在这里,一条SQL语句会被拆分成两个作用域,它们之间可能存在依赖关系,但是每个作用域都是一个完整的查询。

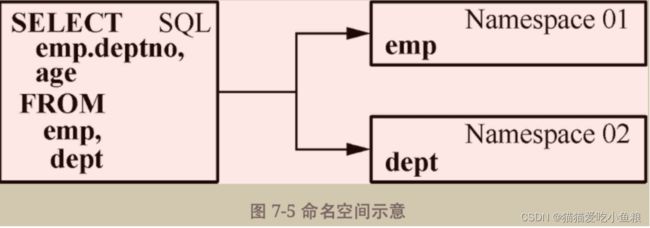
6.命名空间
Calcite中的命名空间(Namespace)指一个SQL查询所用的数据源,这些数据源可能是表、视图、子查询等。
使用一条SQL语句同时对两张表进行查询,此处就会分化出两个命名空间,分别指代两个数据源“emp”和“dept”。
2)校验流程
示例SQL语句:
select *
from
(select u.*
,r.permission
from sys_user u, CSV.sys_role r
where u.role=r.role
order by id)
1.标准化SQL语句
为了简化后面的逻辑,Calcite会把节点重写为标准格式,具体包括SqlOrderBy、SqlDelete、SqlUpdate、SqlMerge和Values等。
SqlOrderBy和Values会被重写成SqlSelect,而SqlDelete和SqlUpdate所删除和更新的数据会被封装在SqlSelect中,方便后面执行。
此处也是SqlSelect算子,里面也包含SqlOrderBy子查询,看起来结果没什么变化,但在代码层面,SQL节点已经被重写了。
标准化后的SQL语句:
SELECT
*
FROM
(
SELECT
*
FROM
'sys_user'
ORDER BY
'id'
)
2.注册命名空间和作用域
注册命名空间和作用域也就是将SQL语句中的命名空间和作用域提取出来,存储在临时变量中。
这里会得到3个命名空间(1个是sys_user这张原表,另外2个是Select-Namespace,表示数据来自子查询)、2个作用域(表示列分别出现在2个作用域范围)。
这一步完成后会得到下面的SQL语句,可以看到作用域已经被重写,同时生成了一个变量名来代替子查询表的别名。
使用命名空间和作用域之后的SQL语句:
SELECT
*
FROM
(
SELECT
*
FROM
'sys_user' AS 'sys_user'
ORDER BY
'id'
) AS 'EXPR$0'
3.执行校验逻辑
执行校验逻辑需要调用元数据的内容,通过调用各个SqlNode节点的 validate方法,最终还是回到 SqlValidatorImpl 类,利用上面得到的命名空间和作用域,结合元数据进行校验。
对于查询语句的命名空间校验,会对各个部分单独校验。
SQL语句校验的流程:
// 校验数据源
validateFrom(select.getFrom(), fromType, fromScope);
// 校验过滤条件
validateWhereClause(select);
// 校验分组条件
validateGroupClause(select);
// 校验Having条件
validateHavingClause(select);
// 校验窗口函数
validateWindowClause(select);
// 校验查询条件
validateSelectList(selectItems, select, targetRowType);
根据配置,最终SQL语句会被展开和替换。
SQL语句被展开和替换:
SELECT
'EXPR$0'.'id',
'EXPR$0'.'user_name',
'EXPR$0'.'password',
'EXPR$0'.'is_admin',
'EXPR$0'.'role',
'EXPR$0'.'created_date',
'EXPR$0'.'modified_date'
FROM
(
SELECT
'sys_user'.'id',
'sys_user'.'user_name',
'sys_user'.'password',
'sys_user'.'is_admin',
'sys_user'.'role',
'sys_user'.'created_date',
'sys_user'.'modified_date'
FROM
'MYSQL'.'sys_user' AS 'sys_user'
ORDER BY
'id'
) AS 'EXPR$0'
4.校验失败
如果语句引用的对象有误,那么错误会被直接抛出来。
通过异常信息非常容易定位错误,常见的错误有:找不到字段、找不到UDF以及找不到表或Schema。
比如使用SQL语句 select len from sys_user,在找不到表中字段 len 时,通过异常链可以很清楚地看到调用过程和代码行数,可以确定是因为在展开Select投影字段(expandSelectExpr)时找不到对应的列而失败的。
at org.apache.calcite.sql.SqlIdentifier.accept(SqlIdentifier.java:320)
at .validate.SqlValidatorImpl.expandSelectExpr(SqlValidatorImpl.java:5600)
at .validate.SqlValidatorImpl.expandSelectItem(SqlValidatorImpl.java:411)
at .validate.SqlValidatorImpl.validateSelectList(SqlValidatorImpl.java:4205)
at .validate.SqlValidatorImpl.validateSelect(SqlValidatorImpl.java:3474)
at .validate.SelectNamespace.validateImpl(SelectNamespace.java:60)
at .validate.AbstractNamespace.validate(AbstractNamespace.java:84)
at .validate.SqlValidatorImpl.validateNamespace(SqlValidatorImpl.java:1067)
at .validate.SqlValidatorImpl.validateQuery(SqlValidatorImpl.java:1041)
at .SqlSelect.validate(SqlSelect.java:232)
at .validate.SqlValidatorImpl.validateScopedExpression(SqlValidatorImpl.java:1016)
at .validate.SqlValidatorImpl.validate(SqlValidatorImpl.java:724)
Caused by: .validate.SqlValidatorException: Column 'len' not found in any table
但是,有的问题并不能在校验阶段被发现。
比如,使用SQL语句select * from sys_ user where id=‘a’,明明知道id是int类型,执行肯定会报错,但SQL校验的结果,仅仅将字符a的类型转换为bigint,做了一次SQL语句重写,这样只有到执行时才能发现类型不匹配。
通过校验但是仍然会存在问题的SQL语句:
SELECT
'sys_user'.'id',
'sys_user'.'user_name',
'sys_user'.'password',
'sys_user'.'is_admin',
'sys_user'.'role',
'sys_user'.'created_date',
'sys_user'.'modified_date'
FROM
'MYSQL'.'sys_user' AS 'sys_user'
WHERE
'sys_user'.'id' = CAST('a' AS BIGINT)
4、元数据DDL
之前是通过文件的形式来声明元数据的,这种声明方式在使用过程中非常不方便。
一般来说,数据管理系统会设定DDL来对元数据进行操作,这样就能够通过SQL语句来控制元数据。
然而Calcite专注的是查询和优化,核心依赖里只包含查询相关的SQL语法,DDL部分的功能单独写在了calcite-server模块中,在calcite-core模块中包含DDL相关的SqlNode子类,比如SqlDrop、SqlCreate,calcite-server模块实际上是扩展了语法文件,支持了部分DDL。
首先要引入calcite-server模块依赖,如果使用Maven来管理,可以直接在pom.xml文件中添加对应的依赖坐标信息。
org.apache.calcite
calcite-server
${calcite-version}
然后在创建连接时指定新的语法解析工厂类,这个工厂类写在了ServerDdlExecutor类里,可以通过指定“PARSER_FACTORY”参数来修改使用的语法。
final Properties p = new Properties();
// 在配置信息中添加语法解析工厂信息
p.put(CalciteConnectionProperty.PARSER_FACTORY.camelName(),
ServerDdlExecutor.class.getName() + "#PARSER_FACTORY");
// 获取数据库连接对象,并进行进一步的操作
try (final Connection conn =
DriverManager.getConnection("jdbc:calcite:", p)){...}
经过配置,就可以用SQL创建数据模式、表、视图、函数和数据类型等实体信息。
用SQL创建实体信息:
final Statement s = conn.createStatement();
// 创建数据模式
s.execute("CREATE SCHEMA s");
// 创建表
s.executeUpdate("CREATE TABLE s.t(age int, name varchar(10))");
// 插入数据
s.executeUpdate("INSERT INTO s.t values(18,'jimo'),(20,'hehe')");
ResultSet rs = s.executeQuery("SELECT count(*) FROM s.t");
rs.next();
assertEquals(2, rs.getInt(1));
// 创建视图
s.executeUpdate("CREATE VIEW v1 AS select name from s.t");
rs = s.executeQuery("SELECT * FROM v1");
rs.next();
assertEquals("jimo", rs.getString(1));
// 创建数据类型
s.executeUpdate("CREATE TYPE vc10 as varchar(10)");
s.executeUpdate("CREATE TABLE t1(age int, name vc10)");
// 删除视图和注销数据类型
s.executeUpdate("DROP VIEW v1");
s.executeUpdate("DROP TYPE vc10");
不过Calcite对这部分并不重视,这几个DDL语法并不完善。
5、示例:配置文件定义元数据并解析校验
1)配置文件-Model.json
resources/model.json
{
"version": "1.0",
"defaultSchema": "MYSQL",
"schemas": [{
"name": "MYSQL",
"type": "custom",
"factory": "cn.com.ptpress.cdm.schema.mysql.MysqlSchemaFactory",
"operand": {
"url": "jdbc:mysql://localhost:3306/db_cdm?useSSL=false",
"user": "root",
"pass": "root"
},
"functions": [{
"name": "test",
"className": "cn.com.ptpress.cdm.schema.function.MyFunction",
"methodName": "test"
}],
"tables": [{
"name": "v_num",
"type": "view",
"sql": "select 1+2*3",
"path": [
"MYSQL"
],
"modifiable": false
}]
},
{
"name": "JDBC_MYSQL",
"type": "jdbc",
"jdbcDriver": "com.mysql.jdbc.Driver",
"jdbcUrl": "jdbc:mysql://localhost:3306/db_cdm?useSSL=false",
"jdbcUser": "root",
"jdbcPassword": "root",
"jdbcSchema": "db_cdm"
},
{
"name": "CSV",
"type": "map",
"tables": [{
"name": "sys_role",
"type": "custom",
"factory": "cn.com.ptpress.cdm.schema.csv.CsvTableFactory",
"operand": {
"colPath": "src/main/resources/sys_role/col_type.json",
"dataPath": "src/main/resources/sys_role/data.csv"
}
},
{
"name": "v_user_role",
"type": "view",
"sql": "select 1+2*3",
"path": [
"CSV"
],
"modifiable": false
}
],
"functions": [{
"name": "test",
"className": "cn.com.ptpress.cdm.schema.function.MyFunction",
"methodName": "test"
}],
"types": [{
"name": "C",
"type": "varchar",
"attributes": [{
"name": "vc",
"type": "varchar"
}]
}]
}
]
}
2)CSV 数据文件和元数据文件
1.元数据文件:resources/sys_role/col_type.json
[
{
"name": "role",
"type": "varchar"
},
{
"name": "permission",
"type": "integer"
}
]
2.数据文件:resources/sys_role/data.csv
role,permission
admin,111111
user,000011
nobody,000000
dev,000111
test,001011
3)CSV Schema 和 解析工厂
1.CsvTableFactory
import cn.com.ptpress.cdm.schema.common.CdmColumn;
import com.fasterxml.jackson.core.type.TypeReference;
import lombok.SneakyThrows;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.schema.TableFactory;
import java.io.File;
import java.util.List;
import java.util.Map;
import static cn.com.ptpress.cdm.schema.util.JsonUtil.JSON_MAPPER;
/**
* 创建表的工厂类
*/
public class CsvTableFactory implements TableFactory {
/**
* 构造对应的表对象——CsvTable
*/
@Override
@SneakyThrows
public CsvTable create(SchemaPlus schema, String name, Map operand, RelDataType rowType) {
// 1. 获取列信息
final String colTypePath = String.valueOf(operand.get("colPath"));
final List columns = JSON_MAPPER.readValue(new File(colTypePath),
new TypeReference>() {
});
// 2. 将列信息和数据信息封装到CsvTable对象中并回传
return new CsvTable(name, columns, String.valueOf(operand.get("dataPath")));
}
}
2.CsvTable
package cn.com.ptpress.cdm.schema.csv;
import cn.com.ptpress.cdm.schema.common.CdmColumn;
import cn.com.ptpress.cdm.schema.common.CdmTable;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
import java.util.List;
/**
* CsvTable的扩展实现
*/
@Data
@EqualsAndHashCode(callSuper = true)
@NoArgsConstructor
public class CsvTable extends CdmTable {
/**
* 数据路径
*/
private String dataPath;
/**
* 构造方法
*/
public CsvTable(String name, List columns, String dataPath) {
super(name, columns);
this.dataPath = dataPath;
}
}
3.CdmTable
package cn.com.ptpress.cdm.schema.common;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rel.type.RelDataTypeFactory;
import org.apache.calcite.schema.impl.AbstractTable;
import org.apache.calcite.sql.type.SqlTypeName;
import org.apache.calcite.util.Pair;
import java.util.ArrayList;
import java.util.List;
/**
* 表元数据内部信息的实现逻辑
*/
@Data
@EqualsAndHashCode(callSuper = true)
@AllArgsConstructor
@NoArgsConstructor
public class CdmTable extends AbstractTable {
/**
* 表名
*/
private String name;
/**
* 表的列
*/
private List columns;
@Override
public RelDataType getRowType(RelDataTypeFactory typeFactory) {
List names = new ArrayList<>();
List types = new ArrayList<>();
for (CdmColumn c : columns) {
names.add(c.getName());
RelDataType sqlType = typeFactory.createSqlType(SqlTypeName.get(c.getType().toUpperCase()));
types.add(sqlType);
}
return typeFactory.createStructType(Pair.zip(names, types));
}
}
4.CdmColumn
package cn.com.ptpress.cdm.schema.common;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.calcite.sql.type.SqlTypeName;
/**
* 列元数据的创建逻辑
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class CdmColumn {
/**
* 列名
*/
private String name;
/**
* 列类型,可以使用calcite扩展的sql类型:{@link SqlTypeName}
*/
private String type;
}
4)MySQL Schema 和 解析工厂
1.MysqlSchema
package cn.com.ptpress.cdm.schema.mysql;
import cn.com.ptpress.cdm.schema.common.CdmTable;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import org.apache.calcite.schema.impl.AbstractSchema;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
这个类是用来封装MySQL的Schema信息的
*/
@Data
@EqualsAndHashCode(callSuper = true)
@AllArgsConstructor
public class MysqlSchema extends AbstractSchema {
// Schmea名称
private String name;
// Schema下的表
private List tables;
@Override
protected Map getTableMap() {
return tables.stream().collect(Collectors.toMap(CdmTable::getName, t -> t));
}
}
2.MysqlSchemaFactory
package cn.com.ptpress.cdm.schema.mysql;
import cn.com.ptpress.cdm.schema.common.CdmColumn;
import cn.com.ptpress.cdm.schema.common.CdmTable;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaFactory;
import org.apache.calcite.schema.SchemaPlus;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 构造MySQL的Schema对象的核心方法
*/
public class MysqlSchemaFactory implements SchemaFactory {
@Override
public Schema create(SchemaPlus parentSchema, String name, Map operand) {
// 1. 使用try with表达式来获取数据连接,以保证try结构体结束时,数据连接自动关闭
try (final Connection conn = DriverManager.getConnection(String.valueOf(operand.get("url")),
String.valueOf(operand.get("user")), String.valueOf(operand.get("pass")))) {
// 2. 利用数据连接对象,构建表达式对象
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("SHOW TABLES");
// 3. 使用循环的方式,将获取的数据相关信息放置到表元数据列表中
List tables = new ArrayList<>(8);
while (rs.next()) {
final String table = rs.getString(1);
tables.add(new CdmTable(table, getColumns(conn, table)));
}
// 4. 最终将获取的Schema信息返回
return new MysqlSchema(name, tables);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
// 获取列信息
private List getColumns(Connection conn, String table) throws SQLException {
final Statement stmt = conn.createStatement();
final ResultSet rs = stmt.executeQuery("DESC " + table);
List columns = new ArrayList<>();
while (rs.next()) {
columns.add(new CdmColumn(rs.getString("Field"),
typeMap(pureType(rs.getString("Type")))));
}
return columns;
}
/**
* mysql 有的类型和 calcite不一样,需要修改下别名
*/
private String typeMap(String type) {
switch (type.toLowerCase()) {
case "int":
return "integer";
default:
return type;
}
}
/**
* 传入的type含有类型长度,如 bigint(20), varchar(258)
* 需要去掉括号
*/
private String pureType(String type) {
final int i = type.indexOf('(');
return i > 0 ? type.substring(0, i) : type;
}
}
5)自定义函数
1.MyFunction
package cn.com.ptpress.cdm.schema.function;
public class MyFunction {
public MyFunction() {
}
/**
* 计算1的个数
*/
public int myLen(int permission) {
int c = 0;
for (; permission > 0; c++) {
permission &= (permission - 1);
}
return c;
}
public String test(String in) {
return "hh";
}
}
6)JSON 工具类
package cn.com.ptpress.cdm.schema.util;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JsonUtil {
public final static ObjectMapper JSON_MAPPER = new ObjectMapper()
.configure(JsonParser.Feature.ALLOW_UNQUOTED_FIELD_NAMES, true)
.configure(JsonParser.Feature.ALLOW_SINGLE_QUOTES, true)
.configure(JsonParser.Feature.ALLOW_COMMENTS, true);
}