C语言系统化精讲(四):C语言变量和数据类型-下篇
文章目录
- 一、C语言中的小数
-
- 1.1 小数的输出
- 1.2 小数的后缀
- 1.3 小数和整数相互赋值
- 二、在C语言中使用英文字符
-
- 2.1 字符的表示
- 2.2 字符的输出
- 2.3 字符与整数
- 2.4 C语言转义字符
- 四、C语言布尔类型(_BOOL)
- 五、补充:C语言中的几个重要概念
-
- 5.1 标识符
- 5.2 关键字
- 5.3 注释
- 5.4 表达式(Expression)和语句(Statement)
一、C语言中的小数
小数分为整数部分和小数部分,它们由点号 . 分隔,例如 0.0,75.0,4.023,0.27,-937.198,-0.27 等都是合法的小数,这是最常见的小数形式,我们将它称为 十进制形式。 此外,小数也可以采用指数形式,例如 7.25×102、0.0368×105、100.22×10-2、-27.36×-3 等。任何小数都可以用指数形式来表示。C语言同时支持以上两种形式的小数。但是在书写时,C语言中的指数形式和数学中的指数形式有所差异。C语言中小数的指数形式为:
aEn 或 aen
a 为尾数部分,是一个十进制数;n 为指数部分,是一个十进制整数;E或e是固定的字符,用于分割尾数部分和指数部分。整个表达式等价于 a×10n。指数形式的小数举例:
- 2.1E5 = 2.1×105,其中 2.1 是尾数,5 是指数。
- 3.7E-2 = 3.7×10-2,其中 3.7 是尾数,-2 是指数。
- 0.5E7 = 0.5×7,其中 0.5 是尾数,7 是指数。
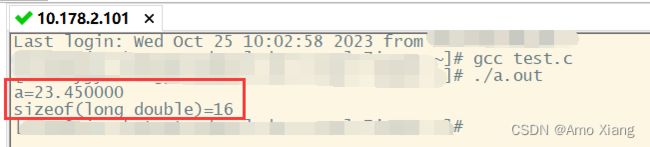
C语言提供了 3 种小数类型,分别是 float、double 和 long double,前两种用的最多。float 称为 单精度浮点型,double 称为 双精度浮点型,long double 称为 长双精度浮点型。
float 和 double 类型的长度是固定的,float 始终占用 4 个字节,double 始终占用 8 个字节。C语言只规定了 long double 的长度至少和 double 相同,实际测试的结果是,该类型在 Windows 环境中占用 8 个字节,在 64 位 Linux 环境中占用 16 个字节。
#include 程序运行结果如下图所示:

Linux 下测试:
1.1 小数的输出
小数也可以使用 printf 函数输出,包括十进制形式和指数形式,它们对应的格式控制符分别是:
%f 以十进制形式输出 float 类型
%lf 以十进制形式输出 double 类型
%Lf 以十进制形式输出 long double 类型
%e 以指数形式输出 float 类型,输出结果中的 e 小写
%E 以指数形式输出 float 类型,输出结果中的 E 大写
%le 以指数形式输出 double 类型,输出结果中的 e 小写
%lE 以指数形式输出 double 类型,输出结果中的 E 大写
%Le 以指数形式输出 long double 类型,输出结果中的 e 小写
%LE 以指数形式输出 long double 类型,输出结果中的 E 大写
下面的代码演示了小数的表示以及输出:
#include 程序运行结果如下图所示:

对代码的说明:
- %f、%lf 和 %Lf 默认保留六位小数,不足六位以 0 补齐,超过六位按四舍五入截断。
- 将整数赋值给浮点型变量时会变成小数。
- 以指数形式输出小数时,输出结果为科学计数法;也就是说,尾数部分的取值为:0 ≤ 尾数 < 10。
- a 的输出结果让人费解,才三位小数,为什么不能精确输出,而是输出一个近似值呢?这和小数在内存中的存储形式有关,很多简单的小数压根不能精确存储,所以也就不能精确输出,笔者将在 计算机组成原理之数据的表示和运算(二) 中详细讲解。
另外,小数还有一种更加智能的输出方式,就是使用 %g,%g 会对比小数的十进制形式和指数形式,以最短的方式来输出小数,让输出结果更加简练。所谓最短,就是输出结果占用最少的字符。%g 使用示例:
#include 程序运行结果如下图所示:

对各个小数的分析:
- a 的十进制形式是 0.00001,占用七个字符的位置,a 的指数形式是 1e-05,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
- b 的十进制形式是 30000000,占用八个字符的位置,b 的指数形式是 3e+07,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
- c 的十进制形式是 12.84,占用五个字符的位置,c 的指数形式是 1.284e+01,占用九个字符的位置,十进制形式较短,所以以十进制的形式输出。
- d 的十进制形式是 1.22934,占用七个字符的位置,d 的指数形式是 1.22934e+00,占用十一个字符的位置,十进制形式较短,所以以十进制的形式输出。
读者需要注意的两点是:
%g 默认最多保留六位有效数字,包括整数部分和小数部分;%f 和 %e 默认保留六位小数,只包括小数部分
%g 不会在最后强加 0 来凑够有效数字的位数,而 %f 和 %e 会在最后强加 0 来凑够小数部分的位数
总之,%g 要以最短的方式来输出小数,并且小数部分表现很自然,不会强加零,比 %f 和 %e 更有弹性,这在大部分情况下是符合用户习惯的。除了 %g,还有 %lg、%Lg、%G、%lG、%LG:
%g、%lg 和 %Lg 分别用来输出 float、double 和 long double 类型,并且当以指数形式输出时,e小写
%G、%lG 和 %LG 分别用来输出 float、double 和 long double 类型,只是当以指数形式输出时,E大写
1.2 小数的后缀
在 C 语言中,小数的类型默认是 double。请看下面的例子:
float x = 52.55;
double y = 18.6;
52.55 和 18.6 这两个数字默认都是 double 类型的,将 52.55 赋值给 x,必须先从 double 类型转换为 float 类型,而将 18.6 赋值给 y 就不用转换了。如果不想让小数使用默认的类型,那么可以给小数加上后缀,手动指明类型:
小数后面紧跟 f 或者 F(不区分大小写),表明它是 float 类型
小数后面紧跟 l 或者 L(不区分大小写),表明它是 long double 类型
请看下面的代码:
float x = 52.55f;
double y = 18.6F;
float z = 0.02;
加上后缀,虽然小数的类型变了,但这并不意味着小数只能赋值给对应的类型,它仍然能够赋值给其他的类型,只要进行一下类型转换就可以了。对于初学者,很少会用到数字的后缀,加不加往往没有什么区别,也不影响实际编程,但是既然学了C语言,还是要知道这个知识点的,万一看到别人的代码这么用了,而你却不明白怎么回事,那就尴尬了。关于数据类型的转换,我们将在本文后面的小节《C语言数据类型转换》一节中深入探讨。
1.3 小数和整数相互赋值
在C语言中,整数和小数之间可以相互赋值:
- 将一个整数赋值给小数类型,在小数点后面加 0 就可以,加几个都无所谓。
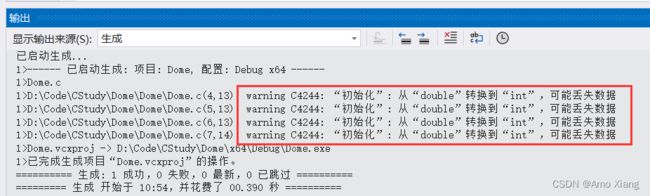
- 将一个小数赋值给整数类型,就得把小数部分丢掉,只能取整数部分,这会改变数字本来的值。注意是直接丢掉小数部分,而不是按照四舍五入取近似值。
举例:
#include 程序运行结果如下图所示:

由于将小数赋值给整数类型时会 失真, 所以编译器一般会给出警告,让大家引起注意,如下图所示:
二、在C语言中使用英文字符
初学者经常用到的字符类型是 char, 它的长度是 1,只能容纳 ASCII 码表中的字符,也就是英文字符。要想处理汉语、日语、韩语等英文之外的字符,就得使用其他的字符类型,char 是做不到的。
2.1 字符的表示
字符类型由单引号 ' ' 包围,字符串由双引号 " " 包围。下面的例子演示了如何给 char 类型的变量赋值:
//正确的写法
char a = '1';
char b = '$';
char c = 'X';
char d = ' '; // 空格也是一个字符
//错误的写法
char x = '中'; //char 类型不能包含 ASCII 编码之外的字符
char y = 'B'; //B 是一个全角字符
char z = "t"; //字符类型应该由单引号包围
说明:在字符集中,全角字符和半角字符对应的编号(或者说编码值)不同,是两个字符;ASCII 编码只定义了半角字符,没有定义全角字符。
2.2 字符的输出
输出 char 类型的字符有两种方法,分别是:
- 使用专门的字符输出函数 putchar
- 使用通用的格式化输出函数 printf,char 对应的格式控制符是 %c
举例:
#include 程序运行结果如下图所示:
putchar 函数每次只能输出一个字符,输出多个字符需要调用多次。
2.3 字符与整数
我们知道,计算机在存储字符时并不是真的要存储字符实体,而是存储该字符在字符集中的编号(也可以叫编码值)。对于 char 类型来说,它实际上存储的就是字符的 ASCII 码。无论在哪个字符集中,字符编号都是一个整数;从这个角度考虑,字符类型和整数类型本质上没有什么区别。我们可以给字符类型赋值一个整数,或者以整数的形式输出字符类型。反过来,也可以给整数类型赋值一个字符,或者以字符的形式输出整数类型。请看下面的例子:
#include 程序运行结果如下图所示:

在 ASCII 码表中,字符 'E'、'F'、'G'、'H' 对应的编号分别是 69、70、71、72。以整数形式输出字符类型,C99 标准建议使用 %hhd 作为格式控制符,如果读者的编译器不支持 C99 标准,可以用 %d 代替。a、b、c、d 实际上存储的都是整数:
- 当给 a、d 赋值一个字符时,字符会先转换成 ASCII 码再存储;
- 当给 b、c 赋值一个整数时,不需要任何转换,直接存储就可以;
- 当以 %c 输出 a、b、c、d 时,会根据 ASCII 码表将整数转换成对应的字符;
- 当以 %d 输出 a、b、c、d 时,不需要任何转换,直接输出就可以。
可以说,是 ASCII 码表将英文字符和整数关联了起来。
什么是ASCII码?
本小节一直在提有关 ASCII 码的内容,那么 ASCII 是什么呢?ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一套电脑编码系统,标准的 ASCII 码一共有128个,包括数字、控制符号、大小写字母、标点符号、运算符等。在C语言中,所使用的字符被一一映射到一个表中,这个表被称为 ASCII 码表,通过点击链接 https://tool.oschina.net/commons?type=4 可以查看 ASCII 码表
一秒记住52个ASCII码
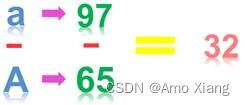
ASCII 码大小写字母之间是有规律的,只要记住规律和一个字母的值,就能记住 52 个 ASCII 码值,接下来就介绍一下这字母大小写的 ASCII 值的小秘密。这里我们用 a、A 和 B 来说明一下。a 和 A 的 ASCII 码值关系如下图所示:
a 的 ASCII 码值是 97,A 的 ASCII 码值是 65,这2个值相差 32,也就是已知小写字母的 ASCII 值,在这个值的基础上减去 32 就是对应的大写字母。A 和 B 的 ASCII 码值的关系如下图所示:
A 的 ASCII 码值是 65,B 的 ASCII 码值是 66,A 和 B 的 ASCII 码值相差 1,同样 B 和 C 的 ASCII 码值也相差1,此次类推;也就是已知一个字母的 ASCII 码值,就知道 26 个大写字母的 ASCII 码值。通过这两条小秘密,我们只要记住一个字母的 ASCII 码值,就能记住共 52 个大小写字母的 ASCII 码值。

2.4 C语言转义字符
字符集(Character Set) 为每个字符分配了唯一的编号,我们不妨将它称为编码值。在C语言中,一个字符除了可以用它的实体(也就是真正的字符)表示,还可以用编码值表示。这种使用编码值来间接地表示字符的方式称为 转义字符(Escape Character)。
转义字符以 \ 或者 \x 开头,以 \ 开头表示后跟八进制形式的编码值,以 \x 开头表示后跟十六进制形式的编码值。对于转义字符来说,只能使用八进制或者十六进制。字符 1、2、3、a、b、c 对应的 ASCII 码的八进制形式分别是 61、62、63、141、142、143,十六进制形式分别是 31、32、33、61、62、63。下面的例子演示了转义字符的用法:
char a = '\61'; //字符1
char b = '\141'; //字符a
char c = '\x31'; //字符1
char d = '\x61'; //字符a
char *str1 = "\x31\x32\x33\x61\x62\x63"; //字符串"123abc" 字符串的定义后面再说
char *str2 = "\61\62\63\141\142\143"; //字符串"123abc"
char *str3 = "The string is: \61\62\63\x61\x62\x63" //混用八进制和十六进制形式
转义字符既可以用于单个字符,也可以用于字符串,并且一个字符串中可以同时使用八进制形式和十六进制形式。举例:
#include程序运行结果如下图所示:
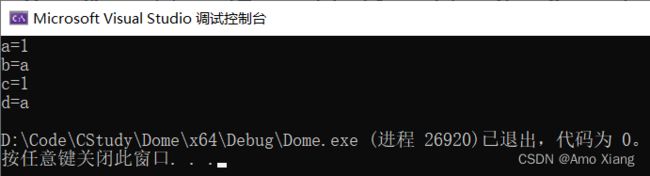
转义字符的初衷是用于 ASCII 编码,所以它的取值范围有限:
- 八进制形式的转义字符最多后跟三个数字,也即
\ddd,最大取值是\177 - 十六进制形式的转义字符最多后跟两个数字,也即
\xdd,最大取值是\x7f
超出范围的转义字符的行为是未定义的,有的编译器会将编码值直接输出,有的编译器会报错。对于 ASCII 编码,0~31(十进制) 范围内的字符为控制字符,它们都是看不见的,不能在显示器上显示,甚至无法从键盘输入,只能用转义字符的形式来表示。不过,直接使用 ASCII 码记忆不方便,也不容易理解,所以,针对常用的控制字符,C语言又定义了简写方式,完整的列表如下:

\n 和 \t 是最常用的两个转义字符:
\n用来换行,让文本从下一行的开头输出,前面的章节中已经多次使用;\t用来占位,一般相当于四个空格,或者 tab 键的功能。
单引号、双引号、反斜杠是特殊的字符,不能直接表示:
- 单引号是字符类型的开头和结尾,要使用
\'表示,也即'\'' - 双引号是字符串的开头和结尾,要使用
\"表示,也即"abc\"123" - 反斜杠是转义字符的开头,要使用
\\表示,也即'\\',或者"abc\\123"
四、C语言布尔类型(_BOOL)
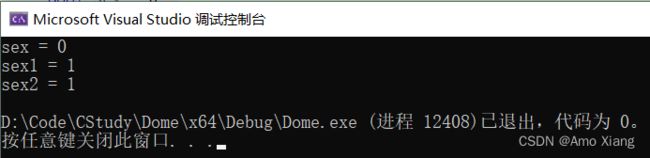
在一些场景中,变量的取值只存在两种情况。比如用变量 sex 表示人的性别,它的值只有 '男' 和 '女',不存在其它的可能。通过前面的学习,读者已经掌握了很多种数据类型,比如 char、short、int、long、float、double 等。那么,对于只有两种取值的变量,它的类型应该是什么呢?在 C99 标准发布之前,对于只有两种取值的变量,没有完全适配的数据类型。退而求其次,通常选择 int 作为变量的类型。int 类型的取值范围是 [-2147483648,2147483647], 将这些值分为 0 和非 0 数两大类,就可以模拟出 "变量只有两种取值" 的情况。例如,用 int 类型的变量 sex 表示人的性别,sex 的值为 0 时表示女性;sex 的值为非 0 数时表示男性。为了解决这个历史遗留问题,C99 标准新引入了 _Bool 类型,中文叫做布尔类型。布尔类型定义的变量,只能存储 0 或者 1,如果赋值其它的非 0 数,那么变量的值会被设定为 1。例如:
#include 程序运行结果如下图所示:
printf() 输出 bool 类型的值,格式控制符用 %d 或者 %hd 都可以,它们都能容纳得下 _Bool 类型的两个值(0 和 1)。_Bool 类型的长度和 char 相同,只占用 1 个字节。大家也可以用 sizeof 操作符查看 _Bool 类型的长度:
#include 程序运行结果如下图所示:

布尔类型 (_Bool) 以下划线 _ 开头,首字母还要大写,这和我们之前掌握的类型 char,float,int,float 相比,写法上有较大的出路,初学者多少会觉得别扭。其实除了 C 语言,很多编程语言都提供了布尔类型,比如 C++,Java,C# 等,它们中的绝大部分都采用 bool/boolean 作为布尔类型的名称,并且布尔类型的两种取值分别用 假(false) 和 真(true) 表示,false 代指 0,true 代指 1。或许是受其它编程语言的影响,又或许是考虑到初学者的感受,C语言标准委员会决定引入 _Bool 类型的同时,添加 bool 作为 _Bool 类型的别名,并且布尔类型的取值可以用 true 和 false 表示。也就是说在 C 语言程序中,布尔类型可以用 _Bool 表示,也可以用 bool 表示。需要注意的点,使用 bool 类型之前,必须先引入
#include 程序运行结果如下图所示:

小结:对于仅有两个值的变量,C99 标准建议将变量的类型设定为布尔类型,可以用 _Bool 或者 bool 表示。如果编译器不支持布尔类型,退而求其次,通常选用 int 类型。在 C99 标准中,想用 bool 表示布尔类型,想用 true 和 false 表示布尔类型的两种取值,必须先引入
五、补充:C语言中的几个重要概念
5.1 标识符
定义变量时,我们使用了诸如 a、abc、mn123 这样的名字,它们都是程序员自己起的,一般能够表达出变量的作用,这叫做 标识符(Identifier)。 标识符就是程序员自己起的名字,除了变量名,后面还会讲到函数名、宏名、结构体名等,它们都是标识符。不过,名字也不能随便起,要遵守规范;C语言规定,标识符只能由 字母(A~Z, a~z)、 数字(0~9) 和 下划线(_) 组成,并且第一个字符必须是字母或下划线,不能是数字。举例:
a, x, x3, BOOK_1, sum5 //合法的标识符
//以下是非法的标识符:
3s 不能以数字开头
s*T 出现非法字符*
-3x 不能以减号(-)开头
bowy-1 出现非法字符减号(-)
在使用标识符时还必须注意以下几点:
- C语言虽然不限制标识符的长度,但是它受到不同编译器的限制,同时也受到操作系统的限制。例如在某个编译器中规定标识符前128位有效,当两个标识符前128位相同时,则被认为是同一个标识符。
- 在标识符中,大小写是有区别的,例如 BOOK 和 book 是两个不同的标识符。
- 标识符虽然可由程序员随意定义,但标识符是用于标识某个量的符号,因此,命名应尽量有相应的意义,以便于阅读和理解,作到
见名知意。int a; //长方体的长 int b; //长方体的宽 int c;//长方体的高 // 相比之下,iLong、iWidth、iHeight这样的标识符更清晰、明了,推荐大家采用 int iLong; //长方体的长 int iWidth; //长方体的宽 int iHeight; //长方体的高
5.2 关键字
所谓关键字,它是指电脑语言中事先定义好并包含着特殊意义的单词,就如下图所示程序中出现的 int,return:

关键字的英文单词都是小写的,尤其是首字母也需要小写。不要少写或者错写英文字母,如 return 写成 retrun,或 double 写成 duoble。我们定义的标识符不能与关键字相同,否则会出现错误。
你也可以将关键字理解为具有特殊含义的标识符,它们已经被系统使用,我们不能再使用了。
下面为大家列举了C语言中的关键字,带有标志的是C程序中出现频率较高的关键字,读者朋友可以在具体使用时再逐渐学习。

说明: 在开发环境编写代码,所有关键字都会显示为 特殊字体(例如变成蓝色,不同编辑器颜色不一样), 今后的学习中将会逐渐接触到这些关键字的具体使用方法,不需要死记硬背这些关键字,可以在以后的学习中慢慢积累。
5.3 注释
刚学认识英文单词的时候,每个同学都会有一本字典,当我们遇到一个陌生的单词时会查询字典进行解惑,字典中会给出详细的中文含义和具体解释。而编程语言也具有这样一个贴心的功能,即代码程序中的 注释, 它是一种对代码程序进行解释和说明的标注性文字,可以为用户提升程序的可读性,也扩大了程序的传播。C语言中的注释多数显示为绿色字体,当然也有特殊例外(主要看你使用的编辑器)。但注释的内容会被C语言编译器忽略,并不会在执行结果中体现出来。C语言主要提供了3种代码注释,分别为单行注释、多行注释和文档注释,下面分别进行介绍。
① 单行注释。 单行注释有两种形式:
----------第一种形式:----------
//这里是注释
"//" 为单行注释标记,从符号 "//" 开始直到换行为止的所有内容均作为注释而被编译器忽略
//以下代码为printf()语句添加注释
// ① 在控制台输出sex
printf("%d", sex); // ② 在控制台输出sex
----------第二种形式:----------
/*这里是注释*/ ⇒ 符号 "/*" 与 "*/" 之间的所有内容均为注释内容
/* ① 在控制台输出sex */
printf("%d", sex); /* ② 在控制台输出sex */
② 多行注释。
/*
注释内容1
注释内容2
…
*/
"/* */" 为多行注释标记,符号 "/*" 与 "*/" 之间的所有内容均为注释内容。注释中的内容可以换行
举例:
/*
* 版权所有:dream公司
* 文件名:Dome.c
* 文件功能描述: 多行注释测试
* 创建日期:2023年10月
* 创建人:AmoXiang
*/
③ 文档注释。 C语言中,还有文档注释。它的格式如下:
/**
注释声明
*/
/**…*/ 为文档注释标记,符号 /** 与 */ 之间的内容均为文档注释内容。文档注释与一般注释的最大区别在于起始符号是 /** 而不是 /* 或 //。例如,下面使用文档注释对 main() 函数进行注释:
/**
* 主方法,程序入口
* args、argv-主函数参数
*/
int main(){
语句;
return 0;
}
说明:多行注释和文档注释有如下区别:
- 文档注释一般放在代码的最开始位置,而多行注释可以放在语句的末端位置。
- 可以用多行注释,注释掉不需要的代码进行调试程序,而文档注释不能这样做。
注释是代码的说明书,说明 这个代码是做什么的?/使用这个代码要注意什么 之类的内容。不要写垃圾注释,例如下面三个注释就属于垃圾注释:
int a = 1; // int a
int c = a; // 让c等于a
c=a+a; //计算a+a的值赋给c
需要注意的是,多行注释不能嵌套使用。例如下面的注释是错误的:
/*我/*爱*/你*/
//正确的
/*我爱你*/ /*I Love You!*/
5.4 表达式(Expression)和语句(Statement)
表达式(Expression) 和 语句(Statement) 的概念在C语言中并没有明确的定义:
- 表达式可以看做一个计算的公式,往往由数据、变量、运算符等组成,例如
3*4+5,a=c=d等,表达式的结果必定是一个值; - 语句的范围更加广泛,不一定是计算,不一定有值,可以是某个操作、某个函数、选择结构、循环等。
赶紧划重点:
- 表达式必须有一个执行结果,这个结果必须是一个值,例如
3*4+5的结果17,a=c=d=10的结果是 10,printf("hello")的结果是 5(printf 的返回值是成功打印的字符的个数)。 - 以分号
;结束的往往称为语句,而不是表达式,例如3*4+5;/a=c=d;等。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习C语言的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!