IO多路复用之epoll模型
epoll接口是为解决Linux内核处理大量文件描述符而提出的方案。该接口属于Linux下多路I/O复用接口中select/poll的增强。其经常应用于Linux下高并发服务型程序,特别是在大量并发连接中只有少部分连接处于活跃下的情况 (通常是这种情况),在该情况下能显著的提高程序的CPU利用率。
epoll采用的是事件驱动,并且设计的十分高效。在用户空间获取事件时,不需要去遍历被监听描述符集合中所有的文件描述符,而是遍历那些被内核I/O事件异步唤醒之后加入到就绪队列并返回到用户空间的描述符集合。
epoll提供了两种触发模式,水平触发(LT)和边沿触发(ET)。当然,涉及到I/O操作也必然会有阻塞和非阻塞两种方案。目前效率相对较高的是 epoll+ET+非阻塞I/O 模型,在具体情况下应该合理选用当前情形中最优的搭配方案。
接下来的讲解顺序为:
(1) epoll接口的一般使用
(2) epoll接口 + 非阻塞
(3) epoll接口 + 非阻塞 + 边沿触发
(4) epoll反应堆模型 (重点,Libevent库的核心思想)
一、epoll接口的基本思想概述
epoll的设计:
(1)epoll在Linux内核中构建了一个文件系统,该文件系统采用红黑树来构建,红黑树在增加和删除上面的效率极高,因此是epoll高效的原因之一。有兴趣可以百度红黑树了解,但在这里你只需知道其算法效率超高即可。
(2)epoll红黑树上采用事件异步唤醒,内核监听I/O,事件发生后内核搜索红黑树并将对应节点数据放入异步唤醒的事件队列中。
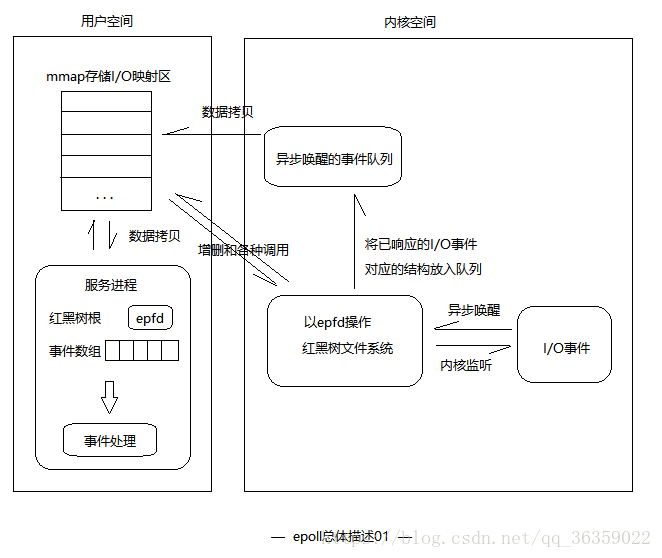
(3)epoll的数据从用户空间到内核空间采用mmap存储I/O映射来加速。该方法是目前Linux进程间通信中传递最快,消耗最小,传递数据过程不涉及系统调用的方法。
epoll接口相对于传统的select/poll而言,有以下优点:
(1)支持单个进程打开大数量的文件描述符。受进程最大打开的文件描述符数量限制,而不是受自身实现限制。而select单个进程能够打开的文件描述符的数量存在最大限制,这个限制是select自身实现的限制。通常是1024。poll采用链表,也是远超select的。
(2)Linux的I/O效率不会随着文件描述符数量的增加而线性下降。较之于select/poll,当处于一个高并发时(例如10万,100万)。在如此庞大的socket集合中,任一时间里其实只有部分的socket是“活跃”的。select/poll的处理方式是,对用如此庞大的集合进行线性扫描并对有事件发生的socket进行处理,这将极大的浪费CPU资源。因此epoll的改进是,由于I/O事件发生,内核将活跃的socket放入队列并交给mmap加速到用户空间,程序拿到的集合是处于活跃的socket集合,而不是所有socket集合。
(3)使用mmap加速内核与用户空间的消息传递。select/poll采用的方式是,将所有要监听的文件描述符集合拷贝到内核空间(用户态到内核态切换)。接着内核对集合进行轮询检测,当有事件发生时,内核从中集合并将集合复制到用户空间。 再看看epoll怎么做的,内核与程序共用一块内存,请看epoll总体描述01这幅图,用户与mmap加速区进行数据交互不涉及权限的切换(用户态到内核态,内核态到用户态)。内核对于处于非内核空间的内存有权限进行读取。
更多关于mmap可以看看我的另一篇博客了进行了解。
https://blog.csdn.net/qq_36359022/article/details/79992287
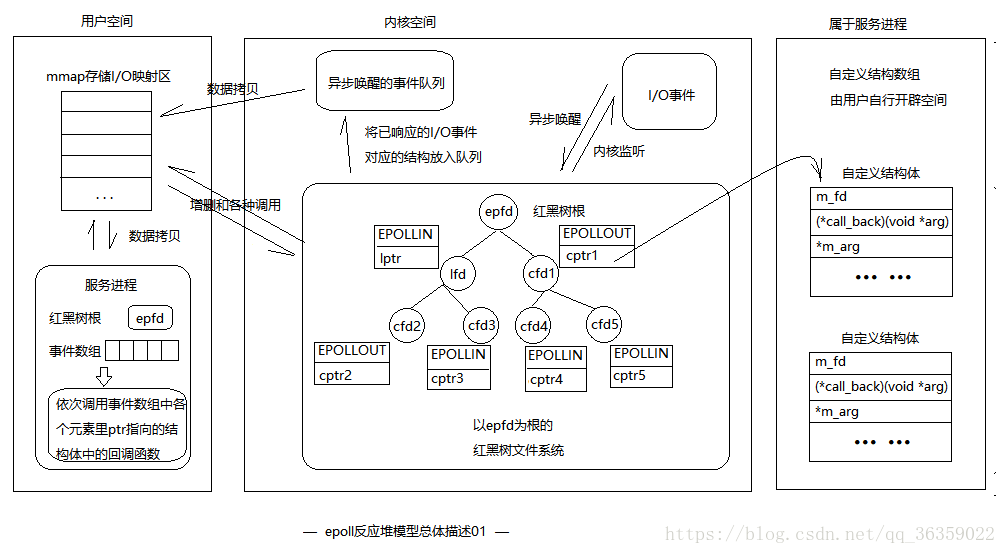
接下来我们结合epoll总体描述01与上述的内容,将图示进行升级为epoll总体描述02。

让我们来看看图的红黑树文件系统。以epfd为根,挂载了一个监听描述符和5个与客户端建立连接的cfd。fd的增删按照红黑树的操作方式,每一个文件描述符都有一个对应的结构,该结构为
/*
* -[ epoll结构体描述01 ]-
*/
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在epoll总体描述02中,每个fd上关联的即是结构体epoll_event。它由需要监听的事件类型和一个联合体构成。一般的epoll接口将传递自身fd到联合体。
因此,使用epoll接口的一般操作流程为:
(1)使用epoll_create()创建一个epoll对象,该对象与epfd关联,后续操作使用epfd来使用这个epoll对象,这个epoll对象才是红黑树,epfd作为描述符只是能关联而已。
(2)调用epoll_ctl()向epoll对象中进行增加、删除等操作。
(3)调用epoll_wait()可以阻塞(或非阻塞或定时) 返回待处理的事件集合。
(3)处理事件。
/*
* -[ 一般epoll接口使用描述01 ]-
*/
int main(void)
{
/*
* 此处省略网络编程常用初始化方式(从申请到最后listen)
* 并且部分的错误处理省略,我会在后面放上所有的源码,这里只放重要步骤
* 部分初始化也没写
*/
// [1] 创建一个epoll对象
ep_fd = epoll_create(OPEN_MAX); /* 创建epoll模型,ep_fd指向红黑树根节点 */
listen_ep_event.events = EPOLLIN; /* 指定监听读事件 注意:默认为水平触发LT */
listen_ep_event.data.fd = listen_fd; /* 注意:一般的epoll在这里放fd */
// [2] 将listen_fd和对应的结构体设置到树上
epoll_ctl(ep_fd, EPOLL_CTL_ADD, listen_fd, &listen_ep_event);
while(1) {
// [3] 为server阻塞(默认)监听事件,ep_event是数组,装满足条件后的所有事件结构体
n_ready = epoll_wait(ep_fd, ep_event, OPEN_MAX, -1);
for(i=0; i.data.fd;
if(ep_event[i].events & EPOLLIN){
if(temp_fd == listen_fd) { //说明有新连接到来
connect_fd = accept(listen_fd, (struct sockaddr *)&client_socket_addr, &client_socket_len);
// 给即将上树的结构体初始化
temp_ep_event.events = EPOLLIN;
temp_ep_event.data.fd = connect_fd;
// 上树
epoll_ctl(ep_fd, EPOLL_CTL_ADD, connect_fd, &temp_ep_event);
}
else { //cfd有数据到来
n_data = read(temp_fd , buf, sizeof(buf));
if(n_data == 0) { //客户端关闭
epoll_ctl(ep_fd, EPOLL_CTL_DEL, temp_fd, NULL) //下树
close(temp_fd);
}
else if(n_data < 0) {}
do {
//处理数据
}while( (n_data = read(temp_fd , buf, sizeof(buf))) >0 ) ;
}
}
else if(ep_event[i].events & EPOLLOUT){
//处理写事件
}
else if(ep_event[i].events & EPOLLERR) {
//处理异常事件
}
}
}
close(listen_fd);
close(ep_fd);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
二、epoll水平触发(LT)、epoll边沿触发(ET)
(1) epoll水平触发, 此方式为默认情况。
当设置了水平触发以后,以可读事件为例,当有数据到来并且数据在缓冲区待读。即使我这一次没有读取完数据,只要缓冲区里还有数据就会触发第二次,直到缓冲区里没数据。
(2) epoll边沿触发,此方式需要在设置
listen_ep_event.events = EPOLLIN | EPOLLET; /*边沿触发 */
- 1
当设置了边沿触发以后,以可读事件为例,对“有数据到来”这件事为触发。

总结:
1.用高低电平举例子就是
水平触发:0为无数据,1为有数据。缓冲区有数据则一直为1,则一直触发。
边沿触发:0为无数据,1为有数据,只要在0变到1的上升沿才触发。
2.
缓冲区有数据可读,触发 ⇒ 水平触发
缓冲区有数据到来,触发 ⇒ 边沿触发
那么,为什么说边沿触发(ET) 的效率更高呢?
(1) 边沿触发只在数据到来的一刻才触发,很多时候服务器在接受大量数据时会先接受数据头部(水平触发在此触发第一次,边沿触发第一次)。
(2) 接着服务器通过解析头部决定要不要接这个数据。此时,如果不接受数据,水平触发需要手动清除,而边沿触发可以将清除工作交给一个定时的清除程序去做,自己立刻返回。
(3) 如果接受,两种方式都可以用while接收完整数据。
三、epoll + 非阻塞I/O
在第一大部分中的 一般epoll接口使用描述01代码中,我们使用的读取数据函数为read函数,在默认情况下此类函数是阻塞式的,在没有数据时会一直阻塞等待数据到来。
(1)数据到来100B,在epoll模式下调用read时,即使read()是阻塞式的也不会在这里等待,因为既然运行到read(),说明数据缓冲区已经有数据,因此这处无影响。
(2)在服务器开发中,一般不会直接用采用类似read()函数这一类系统调用(只有内核缓冲区),会使用封装好的一些库函数(有内核缓冲区+用户缓冲区)或者自己封装的函数。
例如:使用readn()函数,设置读取200B返回,假设数据到来100B,可读事件触发,而程序要使用readn()读200B,那么此时如果是阻塞式的,将在此处形成死锁
流程是:100B ⇒ 触发可读事件 ⇒ readn()调用 ⇒ readn()都不够200B,阻塞 ⇒ cfd又到来200B ⇒ 此时程序在readn()处暂停,没有机会调用epoll_wait() ⇒ 完成死锁
解决:
将该cfd在上树前设置为非阻塞式
/* 修改cfd为非阻塞读 */
flag = fcntl(cfd, F_GETFL);
flag |= O_NONBLOCK;
fcntl(connect_fd, F_SETFL, flag);
- 1
- 2
- 3
- 4
四、epoll + 非阻塞I/O + 边沿触发
/*
* -[ epoll+非阻塞+边沿触发 使用描述01 ]-
*/
/* 其他情况不变,与*一般epoll接口使用描述01*描述一致
* 变化的仅有第二大部分和第三大部分的这两段代码即可
*/
/* ... ... */
listen_ep_event.events = EPOLLIN | EPOLLET; /*边沿触发 */
/* ... ... */
/* 修改cfd为非阻塞读 */
flag = fcntl(cfd, F_GETFL);
flag |= O_NONBLOCK;
fcntl(connect_fd, F_SETFL, flag);
/* ... ... */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
五、epoll反应堆模型 (Libevent库核心思想)
- 第一步,epoll反应堆模型雏形 —— epoll模型
我们将epoll总体描述02进行升级为epoll反应堆模型总体描述01
这里和一般的epoll接口不同的是,现在正式称之为epoll模型(epoll+ET+非阻塞+自定义结构体)
(1) 还记得每一个在红黑树上的文件描述符所对应的结构体吗?它的结构描述在第一大部分的 epoll结构体描述01中。在epoll接口使用代码中,我们在该结构体中的联合体上传入的是文件描述符本身,那么epoll模型和epoll接口最本质的区别在于epoll模型中,传入联合体的是一个自定义结构体指针,该结构体的基本结构至少包括
struct my_events {
int m_fd; //监听的文件描述符
void *m_arg; //泛型参数
void (*call_back)(void *arg); //回调函数
/*
* 你可以在此处封装更多的数据内容
* 例如用户缓冲区、节点状态、节点上树时间等等
*/
};
/*
* 注意:用户需要自行开辟空间存放my_events类型的数组,并在每次上树前用epoll_data_t里的
* ptr指向一个my_events元素。
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
根据该模型,我们在程序中可以让所有的事件都拥有自己的处理函数,你只需要使用ptr传入即可。
(2) epoll_wait()返回后,epoll模型将不会采用一般epoll接口使用描述01代码中的事件分类处理的办法,而是直接调用事件中对应的回调函数,就像这样
/*
* -[ epoll模型使用描述01 ]-
*/
while(1) {
/* 监听红黑树, 1秒没事件满足则返回0 */
int n_ready = epoll_wait(ep_fd, events, MAX_EVENTS, 1000);
if (n_ready > 0) {
for (i=0; icall_back(/* void *arg */);
}
else
/*
* (3) 这里可以做很多很多其他的工作,例如定时清除没读完的不要的数据
* 也可以做点和数据库有关的设置
* 玩大点你在这里搞搞分布式的代码也可以
*/
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 第二步,epoll反应堆模型成型
到了这里,也将是epoll的最终成型,如果从前面到这里你都明白了,epoll的知识你已经十之七八了
让我们先回想以下epoll模型的那张图,我们来理一理思路。
(1) 程序设置边沿触发以及每一个上树的文件描述符设置非阻塞
(2) 调用epoll_create()创建一个epoll对象
(3) 调用epoll_ctl()向epoll对象中进行增加、删除等操作
上树的文件描述符与之对应的结构体,该结构体应该满足填充事件与自定义结构体ptr,此时,监听的事件与回调函数已经确定了对吧?
(4) 调用epoll_wait()(定时检测) 返回待处理的事件集合。
(5) 依次调用事件集合中的每一个元素中的ptr所指向那个结构体中的回调函数。
以上为雏形版本,那么epoll反应堆模型还要比这个雏形版本多了什么呢?
请看第三步的粗体字,当我们把描述符和自定义结构体上树以后,如果放的是监听可读事件并做其对应的回调操作。也就是说,它将一直作为监听可读事件而存在。
其流程是:
监听可读事件(ET) ⇒ 数据到来 ⇒ 触发事件 ⇒ epoll_wait()返回 ⇒ 处理回调 ⇒ 继续epoll_wait() ⇒ 直到程序停止前都是这么循环
那么接下来升级为成型版epoll反应堆模型
其流程是:
监听可读事件(ET) ⇒ 数据到来 ⇒ 触发事件 ⇒ epoll_wait()返回 ⇒
读取完数据(可读事件回调函数内) ⇒ 将该节点从红黑树上摘下(可读事件回调函数内) ⇒ 设置可写事件和对应可写回调函数(可读事件回调函数内) ⇒ 挂上树(可读事件回调函数内) ⇒ 处理数据(可读事件回调函数内)
⇒ 监听可写事件(ET) ⇒ 对方可读 ⇒ 触发事件 ⇒ epoll_wait()返回 ⇒
写完数据(可写事件回调函数内) ⇒ 将该节点从红黑树上摘下(可写事件回调函数内) ⇒ 设置可读事件和对应可读回调函数(可写读事件回调函数内) ⇒ 挂上树(可写事件回调函数内) ⇒ 处理收尾工作(可写事件回调函数内) ⇒ 直到程序停止前一直这么交替循环
至此,结束
(1) 如此频繁的增加删除不是浪费CPU资源吗?
答:对于同一个socket而言,完成收发至少占用两个树上的位置。而交替只需要一个。任何一种设计方式都会有浪费CPU资源的时候,关键看你浪费得值不值,此处的耗费能否换来更大的收益才是衡量是否浪费的标准。和第二个问题综合来看,这里不算浪费
(2) 为什么要可读以后设置可写,然后一直交替?
答:服务器的基本工作无非数据的收发,epoll反应堆模型准从TCP模式,一问一答。服务器收到了数据,再给与回复,是目前绝大多数服务器的情况。
(2-1) 服务器能收到数据并不是一定能写数据
假设一 :服务器接收到客户端数据,刚好此时客户端的接收滑动窗口满,我们假设不进行可写事件设置,并且客户端是有意让自己的接收滑动窗口满的情况(黑客)。那么,当前服务器将随客户端的状态一直阻塞在可写事件,除非你自己在写数据时设置非阻塞+错误处理
假设二 :客户端在发送完数据后突然由于异常原因停止,这将导致一个FIN发送至服务器,如果服务器不设置可写事件监听,那么在接收数据后写入数据会引发异常SIGPIPE,最终服务器进程终止。
细节部分可以看看我的这篇关于SIGPIPE信号的博客
https://blog.csdn.net/qq_36359022/article/details/78851178
以上为网络高并发服务器epoll接口、epoll反应堆模型详解及代码实现,下面是源码
链接:https://pan.baidu.com/s/1u99U2xEnbXE3sPQ6o2GcUg 密码:gc7k