操作系统之页面置换算法
汇总:Android小白成长之路_知识体系汇总【持续更新中…】
目录
- 最优页面置换算法
- 最近未使用页面置换算法
- 先进先出页面置换算法
- 第二次机会页面置换算法
- 时钟页面置换算法
- 最近最少使用页面置换算法
- 老化算法
- 工作集页面置换算法
- 工作集时钟页面置换算法
最优页面置换算法
在缺页中断发生时,有些页面很快被访问,有一些则可能在几十几百条指令后才会被访问,每个页面可以用这个首次被访问前所需要执行的指令数作为标记。最优页面置换算法规定应该置换标记最大的页面,因为它将在最长的时间后才被访问。这个算法唯一的问题就在于它是无法实现的 ,因为操作系统无法得知缺页中断后面的页面何时会被访问,但可以通过这种算法来对其他置换算法性能进行比较。
最近未使用页面置换算法
在大部分的虚拟内存计算机中,系统为每一个页面设置了两个状态位,当页面被访问(读或写)时设置R位,当页面被写入(修改)时设置M位,包含在每一个表项中。当启动一个进程时,它的所有页面的两个位都由系统设置为0,R位被定时清零,以区别最近没有被访问的页面和被访问的页面。
当发生缺页中断时,操作系统检查所有的页面并根据它们当时的R位和M位的值,把它们分为四类:
- 第0类:没有被访问,没有被修改
- 第1类:没有被访问,已被修改
- 第2类:已被访问,没有被修改
- 第3类:已被访问,已被修改
NRU(最近未使用)算法随机从类编号最小的非空类中挑选一个页面淘汰,也就是,在最近的一个时钟滴答中淘汰一个没有被访问的已修改页面要比淘汰一个被频繁使用的页面好。
先进先出页面置换算法
由操作系统维护一个所有当前在内存中的页面的链表,最新进入的页面放在表尾,最早进入的页面放在表头,当发生缺页中断时,淘汰表头的页面并把新调入的页面加到表尾,这个算法成为FIFO(先进先出)算法
第二次机会页面置换算法
FIFO会把经常使用的页面置换出去,为了避免这一问题,先检查最老页面的R位,如果R位是0,说明这个页面又老又没有被使用,可以立刻置换掉,如果是1,就将R位清0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续搜索。
时钟页面置换算法
第二次机会算法经常需要在链表中移动页面,既降低了效率又不是很有必要,一个更好的办法是把所有的页面都保存在一个类似钟面的环形链表中,一个表针指向最老的页面,当发生中断时,算法首先检查指针指向的页面,如果它的R位为0就淘汰该页面,并把新的页面插入这个位置,然后把指针前移一位,如果R位是1则清除R位并把表针向前移一位,重复这个过程直到找到了一个R位为0的页面为止。
最近最少使用页面置换算法
频繁使用的页面很可能在后面仍然会被使用到,长期未使用的页面很有可能在未来较长的一段时间里都不会被使用。因此,在发生缺页中断时,置换未使用时间最长的页面,这个策略成为LRU(最近最少使用)页面置换算法。
老化算法
NFU(最不常用)算法:将每个页面与一个软件计数器相关联,计数器的初值为0,每次时钟中断时,由操作系统扫描内存中所有页面,将每个页面的R位加到它的计数器上,这个计数大体上跟踪了各个页面被访问的频繁程度,发生缺页中断时,置换计数器数值最小的页面。
存在的问题:如果第一次扫描的执行时间恰好是各次扫描时间中最长的,含有以后各次扫描代码的页面的计数器可能总是比含有第一次扫描代码的页面的计数器小,结果是操作系统将置换有用的页面而不是不再使用的页面。
老化算法:在NFU的基础上,在R位被加进之前先将计数器右移一位,然后将R位加到计数器最左端的位而不是最右端的位。
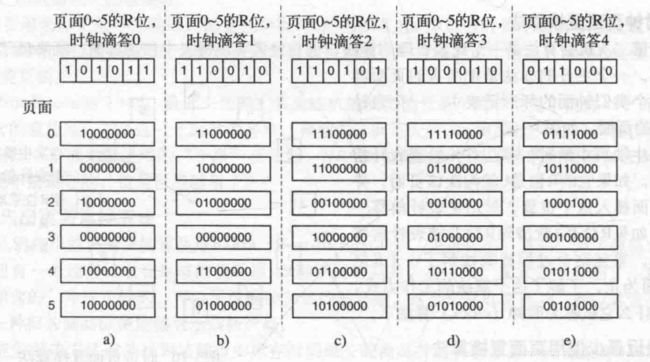
假设第一个时钟滴答后,页面0~5的R位值分别为1、0、1、0、1、1,对应的6个计数器在经过移位并把R位插入其左端后的值如图a所示,后面几个图是在4个时钟滴答后的6个计数器的值。
发生页面中断时,将置换计数器值最小的页面。如果一个页面在前面几个时钟滴答都没有被访问过,则它的计数器前几位都是0,因此它的值肯定要比其他被访问过的页面的计时器值小。
老化算法和LRU的区别:
- 图e中的页面3和页面5,它们都有两次时钟滴答没被访问过,使用LRU出现的问题是,我们不知道在时钟滴答1到时钟滴答2期间它们中的哪一个页面是后被访问到的,因为在每个时钟滴答中只记录了一位。而根据老化算法,我们应该置换页面3,因为页面5在更早去之前的两个时钟滴答中也被访问过,但页面3没有
- 老化算法的计数器只有有限位数,这就限制了其对以往页面的记录,不过实际上,如果时钟滴答是20ms,8位一般是够用的,因为如果一个页面已经160ms没有被访问过了,那么置换掉它也没什么问题。
工作集页面置换算法
一个进程当前正在使用的页面的集合称为它的工作集,如果整个工作集都被装入到内存中,那么进程在进行到下一运行阶段之前,不会产生很多缺页中断。若内存太小而无法容纳下整个工作集,则运行过程中会产生大量的缺页中断,导致运行速度也会变得缓慢。
不少分页系统都会设法跟踪进程的工作集,以确保在让进程运行以前,它的工作集就已在内存中了,该方法称为工作集模型,其目的在于大大减少缺页中断率,在进程运行前预先装入其工作集页面也称为预先调页。因为工作集随时间变化很慢,那么当程序重新开始时,就有可能根据它上次结束时的工作集对要用到的页面做一个合理的推测,预先调页就是在程序继续运行之前预先装入推测出的工作集的页面。
当发生缺页中断时,淘汰一个不再工作集中的页面。为了实现该算法,就需要一种精确的方法来确定哪些页面在工作集中。根据定义,工作集就是最近k次内存访问所使用过的页面的集合,因此必须预先选定k的值,一旦选定某个值,每次内存访问之后,最近k次内存访问所使用过的页面的集合就是唯一确定的了。
一种近似的方法计算工作集:不向后查找最近k次的内存访问,而是考虑其执行时间。可以定义为:工作集即是过去r秒钟的内存访问所使用到的页面集合。

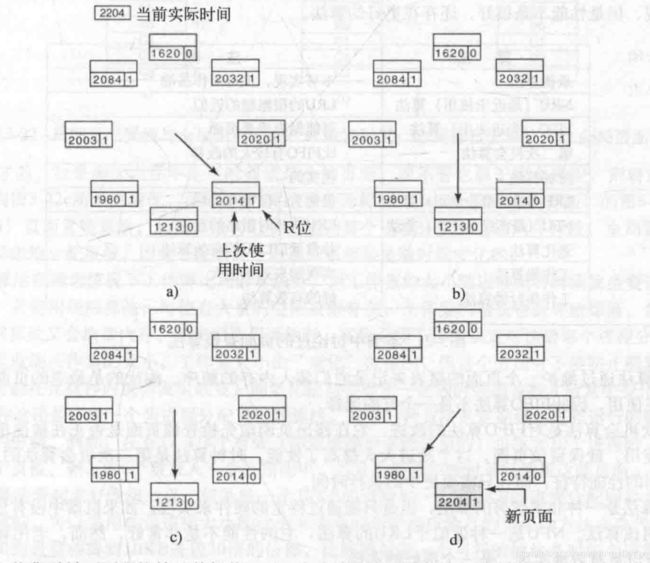
一个进程从开始执行到当前所实际使用的CPU时间总数称为当前实际运行时间,上图显示某台机器的部分页表,因为只有在内存中的页面才可以被置换,因此忽略了不再内存的页面。每个表项至少包含两条消息:上次使用该页面的近似时间和R位,空白的矩形表示其他域。在处理每个表项时,需要检查R位,如果是1,则把当前实际时间写进上次使用时间的区域里,以表示缺页中断发生时该页面正在被使用,因此不应该被淘汰。如果R是0,则表示该页面没有被访问过,则它就可以作为候选者被置换。为了知道它是否真的应该被置换,需要计算它的生存时间,即当前实际运行时间减去上次使用时间,然后与过去的r秒做比较,如果它的生存时间大于r,那么这个页面就不再在工作集中,可以用新的页面置换它。如果它的生存时间小于r秒,则该页面仍然在工作集中,临时保存下来,记录这些临时保存的页面的生存时间最长(上次使用时间的最小值)的页面,如果扫描完整个页表都没合适的被淘汰页面,意味着所有页面都在工作集中,那么就淘汰生存时间最长的那个页面。
工作集时钟页面置换算法
当缺页中断发生后,扫描整个页表才能确定被淘汰的页面,因此基本工作集算法是比较耗时的。提出一种基于时钟算法的改进算法,称为WSClock(工作集时钟)算法,需要一个以页框为元素的循环表:
最初,该表是空的,当第一个页面被装入后,把它加到该表中,随着更多的页面的加入,形成一个环,每个表项包括上次使用时间,以及R位和M位。每次缺页中断时,首先检查指针指向的页面,如果R位被置为1,该页面在当前时钟滴答中被使用过,那么该页面就不适合淘汰,把该页面R位置0,然后把指针指向下一个页面。当R位为0时,如果该页面的生存时间大于r并且没被修改过,它就不在工作集中了,并且在磁盘上有一份有效的副本,可以被置换。如果被修改过,就不能立刻申请这个页框了,因为磁盘上没有对应的有效副本,为了避免由于调度写磁盘操作引起的进程切换,指针继续向前走,对下一个页面进行判断。如果指针经过一圈返回起始点,会有两种情况:
- 至少调度了一次写操作:最终会有某个写操作完成,它的页面被标记为干净,置换遇到的第一个干净的页面。
- 没有调度过写操作:随便置换一个干净的页面来使用,扫描中需要记录下干净页面的位置。如果不存在干净页面,就选定当前页面并把它写回磁盘。