使用ResNet18对kaggle官网state farm数据集中的distracted driver detection数据集进行分类
一、写在前面
最近在阅读文献的时候刚好看到了kaggle比赛中有驾驶分心的数据集,于是又想到了前段时间刚学过ResNet18网络算法的搭建,又于是萌生了使用ResNet18对kaggle比赛中state farm数据集中的Distracted Driver Detection数据集进行分类测试的想法,又又于是……
二、数据集介绍
State Farm Distracted Driver Detection数据集是几年前kaggle举办的有关图像分类的比赛,该数据集中主要是有关驾驶员在驾驶汽车的过程中会出现的几种驾驶分心所采集的图片,随着汽车工业的发展,单拿中国来说,2021年中国汽车保有量达到3.95亿辆;2021年我国发生的交通事故达到211074起,驾驶分心导致的交通事故可占重大事故的14%~33%。该数据集主要采集了驾驶分心中几种典型的驾驶分心动作:左/右手玩手机、左/右手持通电话、调节多媒体、喝水、向后座伸手拿东西、化妆、和其他乘客交谈。
详细数据可参考官网:
State Farm Distracted Driver Detection | Kaggle https://www.kaggle.com/datasets/rightway11/state-farm-distracted-driver-detection
https://www.kaggle.com/datasets/rightway11/state-farm-distracted-driver-detection
 正常驾驶
正常驾驶  右手玩手机
右手玩手机
 伸手向后座拿东西
伸手向后座拿东西  喝水
喝水
三、算法实现
1、数据加载算法模块
该数据集中图片大小为320*240,由于数据加载算法使用之前写的一个程序,之前输入是32*32的正方形图片,这里为了方便,直接将resize设置成320,把长方形图片当成正方形图片输入,也可以将图片先进行正方形裁剪,然后再输入算法中。
具体程序代码如下:
from cProfile import label
from re import X
from turtle import st
from matplotlib.pyplot import title
import torch
import os,glob
import random,csv
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
from PIL import Image
class Kaggle(Dataset):
def __init__(self,root,resize,mode) -> None:
super(Kaggle,self).__init__()
self.root=root
self.resize=resize
self.name2label={}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root,name)):
continue
self.name2label[name]=len(self.name2label.keys())
#print(self.name2label)
self.images,self.labels=self.Load_csv('images.csv')
#划分数据集
if mode=='train': #60% train
self.images=self.images[:int(0.6*len(self.images))]
self.labels=self.labels[:int(0.6*len(self.labels))]
elif mode=='val': #20% val
self.images=self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels=self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else: #20% test
self.images=self.images[int(0.8*len(self.images)):]
self.labels=self.labels[int(0.8*len(self.labels)):]
#image ,label
def Load_csv(self,filename):
if not os.path.exists(os.path.join(self.root,filename)):
images=[]
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root,name,'*.png'))
images += glob.glob(os.path.join(self.root,name,'*.jpg'))
images += glob.glob(os.path.join(self.root,name,'*.jpeg'))
print(len(images))
random.shuffle(images)
with open(os.path.join(self.root,filename),mode='w',newline='') as f:
write=csv.writer(f)
for img in images:
name=img.split(os.sep)[-2]
label=self.name2label[name]
write.writerow([img,label])
print("writen into csv file: ",filename)
#读取每条数据
images,labels=[],[]
with open(os.path.join(self.root,filename)) as f:
reader=csv.reader(f)
for row in reader:
img,label=row
label=int(label)
images.append(img)
labels.append(label)
assert len(images)==len(labels)
return images,labels
def __len__(self):
return len(self.images)
def denormalize(self,x_hat):
mean=[0.485,0.456,0.406]
std=[0.229,0.224,0.225]
mean=torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std=torch.tensor(std).unsqueeze(1).unsqueeze(1)
x=x_hat*std+mean
return x
def __getitem__(self, idx):
img,label=self.images[idx],self.labels[idx]
tf=transforms.Compose([
lambda x:Image.open(x).convert('RGB'),
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
img=tf(img)
label=torch.tensor(label)
return img,label2、ResNet18神经网络搭建模块
ResNet18神经网络的搭建仍然采用之前搭建的一个网络,这里只是简单搭建一个18层深度的网络,想要得到更好的训练结果可以搭建更深层的网络。具体程序代码如下:
from audioop import lin2adpcm
from cgitb import reset
from msilib import sequence
from pickletools import optimize
from turtle import circle, forward, shape
import torch
import torch.nn as nn
from torch.nn import functional as F
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision import transforms
from torch import optim
# class Lenet5(nn.Module):
# def __init__(self) -> None:
# super(Lenet5,self).__init__()
# self.conv_unit=nn.Sequential(
# #[b,3,32,32]->[b,6,,]
# nn.Conv2d(3,6,kernel_size=5,stride=1,padding=0),
# nn.AvgPool2d(kernel_size=2,stride=2,padding=0),
# #
# nn.Conv2d(6,16,kernel_size=5,stride=1,padding=0),
# nn.AvgPool2d(kernel_size=2,stride=2,padding=0)
# )
# #flatten
# #fc_unit
# self.fc_unit=nn.Sequential(
# nn.Linear(16*5*5,120),
# nn.ReLU(),
# nn.Linear(120,84),
# nn.ReLU(),
# nn.Linear(84,10)
# )
# def forward(self,x):
# batchsz=x.size(0)
# #[b,3,32,32]->[b,16,5,5]
# x=self.conv_unit(x)
# #[b,16,5,5]->[b,16*5*5]
# x=x.view(batchsz,16*5*5)
# #[b,16*5*5]->[b,10]
# logits=self.fc_unit(x)
# return logits
class Resblk(nn.Module):
def __init__(self,ch_in,ch_out,stride=1) -> None:
super(Resblk,self).__init__()
self.conv1=nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=stride,padding=1)
self.bn1=nn.BatchNorm2d(ch_out)
self.conv2=nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1)
self.bn2=nn.BatchNorm2d(ch_out)
self.extro=nn.Sequential()
if ch_in !=ch_out:
self.extro=nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self,x):
out=F.relu(self.bn1(self.conv1(x)))
out=self.bn2(self.conv2(out))
#shortcut
out=self.extro(x)+out
out=F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self,num_class) -> None:
super(ResNet18,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(3,16,kernel_size=3,stride=3,padding=0),
nn.BatchNorm2d(16)
)
#follow 4 block
#[b,64,h,w]->[b,128,h,w]
self.blk1=Resblk(16,32,stride=3)
#[b,128,h,w]->[b,256,h,w]
self.blk2=Resblk(32,64,stride=3)
#[b,256,h,w]->[b,512,h,w]
self.blk3=Resblk(64,128,stride=2)
#[b,512,h,w]->[b,1024,h,w]
self.blk4=Resblk(128,256,stride=2)
self.outlayer=nn.Linear(256*3*3,num_class)
def forward(self,x):
x=F.relu(self.conv1(x))
x=self.blk1(x)
x=self.blk2(x)
x=self.blk3(x)
x=self.blk4(x)
#print(x.shape)
x=x.view(x.size(0),-1)
x=self.outlayer(x)
return x3、主程序模块
该部分主要是将前面写好的数据加载程序和ResNet18网络加载进来,并且优化器选用Adam,学习率为1 e-3,batch_size设置为128,epoch设置为20,损失函数采用CrossEntropyLoss(交叉熵损失),并且使用visdom画出每个批次的损失和交叉验证集的准确率,做出折线图。
具体程序代码实现如下:
#完美运行!
#train val and test
from multiprocessing.spawn import import_main_path
from pyexpat import model
from matplotlib.pyplot import title
from numpy import corrcoef
import torch
from torch import logit, nn,optim
import visdom
import torchvision
from torch.utils.data import DataLoader
from zmq import device
from kaggle import Kaggle
from ResNet18 import ResNet18
batchsz=128
lr=1e-3
epochs=20
device=torch.device('cuda')
torch.manual_seed(1234)
train_db=Kaggle('./imgs/train',resize=320,mode='train')
val_db=Kaggle('./imgs/train',resize=320,mode='val')
test_db=Kaggle('./imgs/train',resize=320,mode='test')
train_loader=DataLoader(train_db,batch_size=batchsz,shuffle=True,num_workers=0)
val_loader=DataLoader(val_db,batch_size=batchsz,shuffle=True,num_workers=0)
test_loader=DataLoader(test_db,batch_size=batchsz,shuffle=True,num_workers=0)
viz=visdom.Visdom()
def evalute(model,loader):
correct=0
total=len(loader.dataset)
for x,y in loader:
x,y=x.to(device),y.to(device)
with torch.no_grad():
logits=model(x)
pred=logits.argmax(dim=1)
correct +=torch.eq(pred,y).sum().float().item()
return correct/total
def main():
model=ResNet18(10).to(device)
optimizer=optim.Adam(model.parameters(),lr=lr)
criteon=nn.CrossEntropyLoss()
best_acc,best_epoch=0,0
global_step=0
viz.line([0],[-1],win="loss",opts=dict(title='loss'))
viz.line([0],[-1],win="val_acc",opts=dict(title='val_acc'))
for epoch in range(epochs):
for step,(x,y) in enumerate(train_loader):
x,y=x.to(device),y.to(device)
logits=model(x)
loss=criteon(logits,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()],[global_step],win="loss",update='append')
global_step +=1
if epoch%1==0:
val_acc=evalute(model,val_loader)
if val_acc>best_acc:
best_epoch=epoch
best_acc=val_acc
torch.save(model.state_dict(),'best.mdl')
viz.line([val_acc],[global_step],win="val_acc",update='append')
print("best acc: ",best_acc,"best epoch: ",best_epoch)
model.load_state_dict(torch.load("best.mdl"))
print("loader from ckpt!")
test_acc=evalute(model,test_loader)
print("test acc: ",test_acc)
if __name__=='__main__':
main()运行结果如下所示:
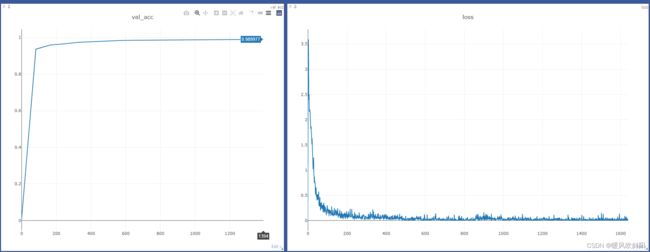 交叉验证集准确率和训练集交叉熵损失
交叉验证集准确率和训练集交叉熵损失
 测试集准确率
测试集准确率
四、总结
本次测试只使用了数据集中的train训练集,将train训练集图片按6:2:2分为训练集、交叉验证集和测试集。经过测试,ResNet18对该数据集中交叉验证集准确率最高可达98.9977%,测试集中的准确率达到98.31%。后期还需测试是否可以通过堆叠更深层次的网络、增加数据集的大小、调节参数等方法继续提高准确率。总的来说,ResNet18的结果还是很满意的!
有什么问题可以评论出来一起交流学习,希望我们能够共同学习、共同进步!